文章目录
- 0. 前言
- 1. ResponseMode: tree_summarize (总结摘要-最优)
- 2. ResponseMode: generation
- 3. ResponseMode: no_text
- 4. ResponseMode: simple_summarize (最省token)
- 5. ResponseMode: refine (基于关键词询问-最优)
- 6. ResponseMode: compact (较省token)
0. 前言
在使用llama_index进行内容提炼、文章总结时,我们可以通过设置不同的ResponseMode来控制生成响应的结果。
在上篇“使用langchain及llama_index实现基于文档(长文本)的相似查询与询问”博客中,我们给出了如下代码(部分):
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name=model_name,max_tokens=1800))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
query_str = "美女蛇的故事是什么?"
response_mode = "compact"
"""
REFINE = "refine"
COMPACT = "compact"
SIMPLE_SUMMARIZE = "simple_summarize"
TREE_SUMMARIZE = "tree_summarize"
GENERATION = "generation"
NO_TEXT = "no_text"
"""
documents = fileToDocuments("./data")
index = GPTListIndex.from_documents(documents,service_context=service_context)
query_engine = index.as_query_engine(
response_mode=response_mode
)
response = query_engine.query(query_str)
print(response)
其中列举了6种response_mode:
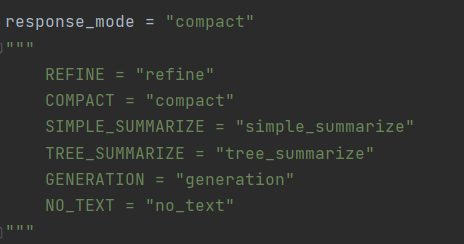
我们也可以通过导入如下代码来观察其中的值:ResponseMode.xx
from llama_index.indices.response.type import ResponseMode
在研究源码及实践后,本篇将介绍这几种不同的response_mode的意义。
在代码中,我们可以找到相应的响应器responseBuilder,其源码位置为llama_index/indices/response/response_builder.py。下面我们将介绍几种常用的ResponseMode及其意义。
1. ResponseMode: tree_summarize (总结摘要-最优)
当设置ResponseMode为tree_summarize时,ChatGPT会对每一段文本进行最大长度的分割,并进行连续的读取和询问。这种模式的优点是可以保证对文本的完整理解和回答,但如果没有正确处理分割段落的情况,可能会导致错误的生成结果。我们可以通过下面这幅图来理解它的执行流程:

理解:选择这种模式比较适合做文章总结,但是不适合做基于关键词的查询或询问。
2. ResponseMode: generation
当设置ResponseMode为generation时,生成的回答不依赖于文档的内容,只基于提供的问题进行生成。这种模式适用于纯粹的问题回答场景,不考虑文档的影响。
理解:与文档割裂,纯粹只是普通问答。
3. ResponseMode: no_text
当设置ResponseMode为no_text时,生成的回答中不包含任何内容,仅作为占位符使用。
理解:目前暂时未发现其他用途。
4. ResponseMode: simple_summarize (最省token)
当设置ResponseMode为simple_summarize时,ChatGPT会截取每段文本的相关句子(通常是第一句),并进行提炼生成回答。这种模式适用于对结果要求不高的场景。我们可以通过下面这幅图来理解它的执行流程:

理解:因为只需要进行一次API调用,所以也比较省费用。但是由于提炼过程可能会不精确,所以上下文的丢失情况有时比较严重。
5. ResponseMode: refine (基于关键词询问-最优)
当设置ResponseMode为refine时,如果只有一个文本块(text_chunk),则会正常生成回答。但如果存在多个文本块,则会以类似轮询的方式迭代生成回答。这种模式可以对多个文本块进行迭代式的回答生成,逐步完善回答内容。我们可以通过下面这幅图来理解它的执行流程:

理解:非常适合用于关键词的询问。如果某段文本与提问的关键词无关,则会保留原本的答案,如果有关系,则会进一步的更新回答。
6. ResponseMode: compact (较省token)
当设置ResponseMode为compact时,生成的回答会将多个文本块(text_chunk)压缩到设定的最大长度,并生成一次回答。然后,根据后续内容对以往的答案进行改进和完善(即进行多次迭代)。这种模式实际上是Compact And Refine的方式。
理解:refine的升级版,可以更加节约token。