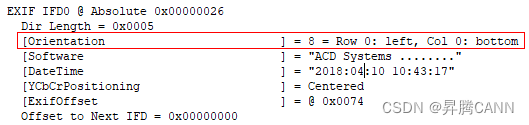
1.Next-vit介绍
论文:https://arxiv.org/pdf/2207.05501.pdf
由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?
主要贡献总结如下:
1)开发了具有部署友好机制的强大卷积块和变换块,即NCB和NTB。Next-ViT堆栈NCB和NTB 构建先进的CNN-Transformer混合架构。
2)从一个新的角度设计了一种创新的CNN Transformer混合策略,该策略可以高效地提高性能。
3)介绍了Next ViT。大量实验证明了Next ViT的优势。它在TensorRT和CoreML上实现了图像分类、目标检测和语义分割的SOTA延迟/精度权衡。
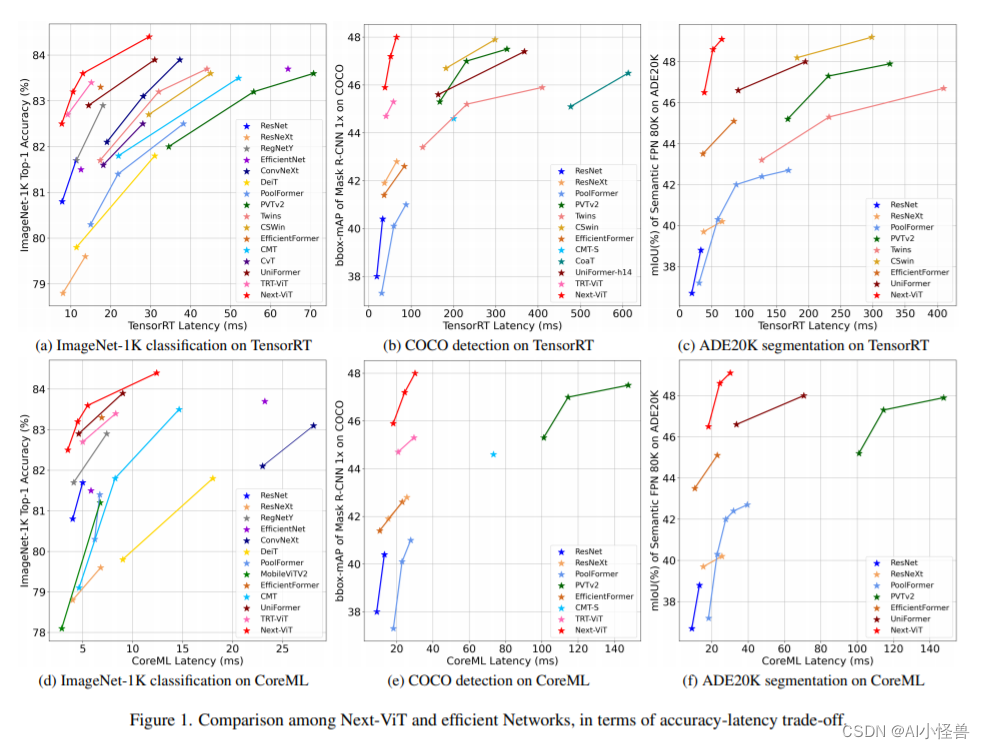 Next-ViT 的研究团队通过开发新型的卷积块(NCB)和 Transformer 块(NTB),部署了友好的机制来捕获局部和全
Next-ViT 的研究团队通过开发新型的卷积块(NCB)和 Transformer 块(NTB),部署了友好的机制来捕获局部和全