大家好,我是Mr数据杨。今天,我们要踏上一场探索Python的旅程,途中我们将讲解算术运算、NumPy和SciPy函数的应用、DataFrame的排序、过滤、统计和遍历等技巧。想象一下如果《三国演义》中的诸葛亮有了Python的帮助,他将如何更有效地指挥战事。
想象《三国演义》中的诸葛亮,通过Python的算术运算预估兵力、粮草,而后使用NumPy和SciPy函数计算最优的行军路线和时间。这将使他的军队更具优势。
而在战场上,诸葛亮需要不断掌握形势变化,这就需要像DataFrame进行排序一样,按优先级排序重要情报,通过DataFrame过滤数据将无关的信息筛选掉,让军情明了。
诸葛亮就如同运用DataFrame数据统计一样,评估自己和敌方的实力对比,预测战争结果。有了这些数据,他可以找到战争的转折点。
就像DataFrame数据遍历一样,诸葛亮需要逐一查看各个战况,决定是否需要调动兵力,或者是否有必要改变策略。
在这个旅程中,我们将一起学习如何使用Python处理数据,像诸葛亮一样明察秋毫,让我们一起开始吧!
文章目录
- 应用算术运算
- 应用NumPy和SciPy函数
- DataFrame进行排序
- DataFrame过滤数据
- DataFrame数据统计
- DataFrame数据遍历
应用算术运算
我们首先介绍如何应用基本的算术运算。下面是一个示例,演示了如何对DataFrame中的列进行加减乘除运算:
df['没年'] - df['生年']
这段代码将计算"没年"列和"生年"列之间的差值,并返回一个新的Series对象。
另一个示例是对"寿命"列进行除法运算:
df['寿命'] / 100
这段代码将"寿命"列中的每个元素除以100,并返回一个新的Series对象。
除了基本的算术运算,我们还可以使用线性组合公式计算汇总数据。下面的代码演示了如何使用线性组合公式计算汇总数据并将其添加到DataFrame中:
df['total'] = 0.4 * df['商業'] + 0.3 * df['農業'] + 0.3 * df['文化']
这段代码将根据给定的权重,对"商業"、"農業"和"文化"三列进行线性组合计算,并将结果添加到名为"total"的新列中。
应用NumPy和SciPy函数
接下来,我们将介绍如何使用NumPy和SciPy函数在Pandas的Series或DataFrame对象上进行操作。下面的代码演示了如何使用NumPy的numpy.average()函数计算考生的总考试成绩:
import numpy as np
data = df.iloc[:, 13:16]
np.average(data.astype(np.float), axis=1, weights=[0.4, 0.3, 0.3])
这段代码首先从DataFrame中提取出包含考试成绩的三列数据,然后使用numpy.average()函数计算加权平均值。其中,axis=1表示按行进行计算,weights=[0.4, 0.3, 0.3]指定了每个列的权重。
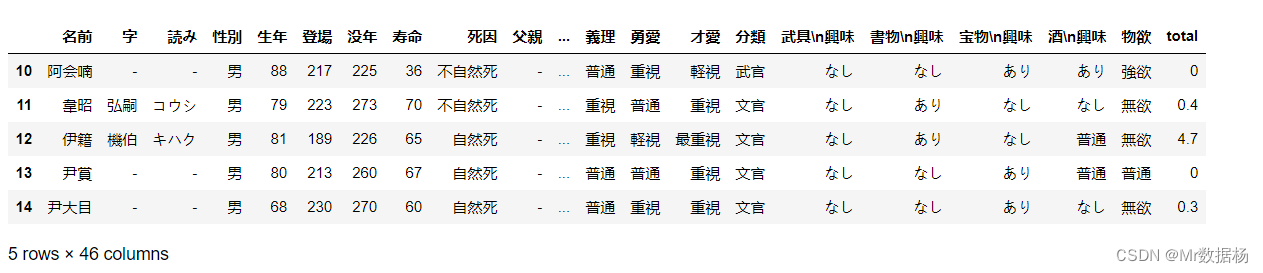
另外,我们还可以直接在DataFrame中添加计算结果列。下面的代码演示了如何将加权平均值添加到DataFrame中:
del df['total']
df['total'] = np.average(df.iloc[:, 13:16].astype(np.float), axis=1, weights=[0.4, 0.3, 0.3])
这段代码
先删除原有的"total"列(如果存在),然后将新的加权平均值计算结果添加到"total"列中。
DataFrame进行排序
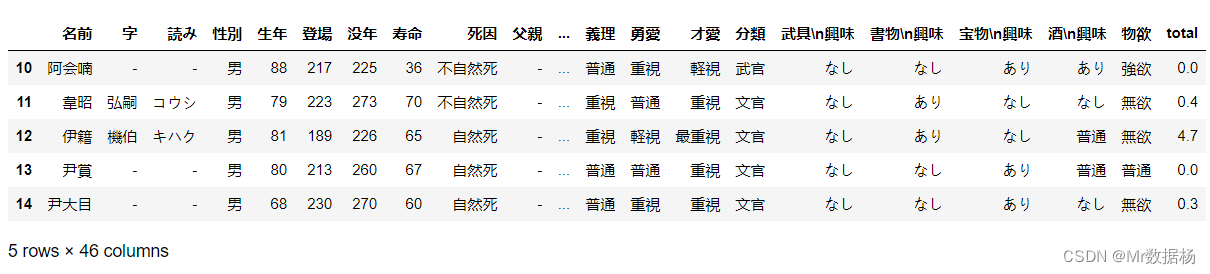
我们可以使用.sort_values()方法对DataFrame进行排序。下面的代码演示了如何按照"寿命"列进行降序排序:
df.sort_values(by='寿命', ascending=False)
这段代码将按照"寿命"列的值进行降序排序,并返回一个排序后的DataFrame。
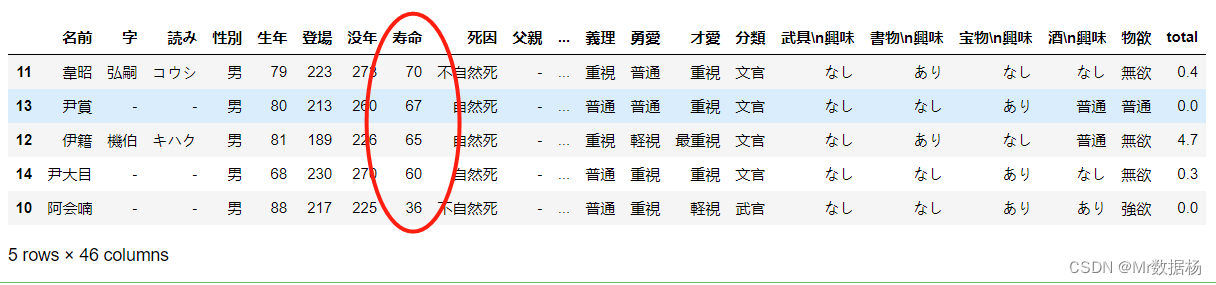
除了单列排序,我们还可以指定多个列和多个排序方式进行排序。下面的代码演示了如何先按照"生年"列进行降序排序,然后再按照"寿命"列进行降序排序:
df.sort_values(by=['生年', '寿命'], ascending=[False, False])
这段代码将先按照"生年"列进行降序排序,对于生年相同的数据再按照"寿命"列进行降序排序。
DataFrame过滤数据
Pandas的过滤功能类似于在NumPy中使用布尔数组进行索引。下面的代码演示了如何根据条件过滤DataFrame中的数据:
filter_ = df['寿命'] >= 50
df[filter_]
这段代码首先根据条件"寿命大于等于50"生成一个布尔数组,并赋值给filter_变量。然后,使用df[filter_]返回满足条件的行数据。

我们还可以使用逻辑运算符进行多条件筛选。下面的代码演示了如何筛选出"生年大于等于80"且"寿命大于等于65"的数据:
df[(df['生年'] >= 80) & (df['寿命'] >= 65)]
这段代码使用&运算符对两个条件进行逻辑与操作,并返回满足条件的行数据。

此外,我们还可以使用.where()方法替换不满足条件的位置的值。下面的代码演示了如何将"登場"列中不满足条件"登場
大于等于220"的位置替换为0.0:
df['登場'].where(cond=df['登場'] >= 220, other=0.0)
这段代码使用.where()方法将不满足条件的位置的值替换为指定的other值。
DataFrame数据统计
我们可以使用.describe()方法获取DataFrame的基本统计信息。下面的代码演示了如何获取DataFrame的基本统计信息:
df.describe()
这段代码将返回DataFrame的基本统计信息,包括计数、均值、标准差、最小值、25%分位数、50%分位数、75%分位数和最大值等。
另外,我们还可以直接调用相应的方法获取特定统计信息。例如,可以使用.mean()方法获取DataFrame的均值:
df.mean()
这段代码将返回DataFrame的每列的均值。
也可以针对特定的列进行统计,例如:
df['total'].mean()
这段代码将返回"total"列的均值。
同样地,使用.std()方法可以获取DataFrame或特定列的标准差。
df.std()
df['total'].std()
DataFrame数据遍历
在遍历DataFrame时,我们可以使用.items()和.iteritems()方法遍历DataFrame的列。每次迭代都会产生一个以列名和列数据作为Series对象的元组。
下面的代码演示了如何使用.items()方法遍历DataFrame的列:
for col_label, col in df.iteritems():
print(col_label, col, sep='\n', end='\n\n')
这段代码将依次打印出每列的列名和列数据。
同样地,我们还可以使用.iterrows()方法遍历DataFrame的行。下面的代码演示了如何使用.iterrows()方法遍历DataFrame的行:
for row_label, row in df.iterrows():
print(row_label, row, sep='\n', end='\n\n')
这段代码将依次打印出每行的行索引和行数据。