MobileViT详解:轻型,通用,移动友好的视觉变压器
- 0. 引言
- 1. 网络结构
- 2. 模型详解
- 2.1 MobileViT Block
- 2.1.1 Local representations
- 2.1.2 Transformers as Convolutions (global representations)
- 2.1.3 Fusion
- 2.2 MV2
- 3. 简化版理解
- 4. 总结
0. 引言
轻量级卷积神经网络(CNN) 在图像领域得到了广泛的应用。他们的空间归纳偏差使他们能够在不同的视觉任务中学习参数更少的表征。然而,这些网络在空间上是局部的。为了学习全局表征,采用了基于自注意的视觉变换(ViTs)。与CNN不同,ViT 是重量级的。
因此,作者提出了MobileViT网络,将 CNN 和 ViT 的优势结合起来。在轻量的基础上具有可以处理全局信息的能力。
实验结果表明:在不同的任务和数据集上,MobileViT明显优于基于cnn和viti的网络。在ImageNet-1k数据集上,MobileViT在约600万个参数下达到了78.4%的前1准确率,在相同数量的参数下,比MobileNetv3(基于CNN)和 DeIT (基于ViT)的准确率分别提高了3.2%和6.2%。在MS-COCO目标检测任务上,对于相似数量的参数,MobileViT比MobileNetv3的准确率高5.7%。
论文名称:MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
论文地址:https://arxiv.org/abs/2110.02178
代码地址:https://github.com/apple/ml-cvnets
注意:CNN的空间归纳偏差内容如下:
CNN 的 归纳偏差(Inductive Bias) 是 局部性 (Locality) 和 空间不变性 (Spatial Invariance) / 平移等效性 (Translation Equivariance),即空间位置上的元素 (Grid Elements) 的联系/相关性近大远小,以及空间 平移的不变性 (Kernel 权重共享)。
1. 网络结构
标准 ViT 的网络结构如下图所示。关于ViT的更详细的介绍在 文章:DeiT详解中有所介绍。整体而言:在 ViT 中将图片数据(2D 数据)变为 Transformer 接受的数据(1D数据)。

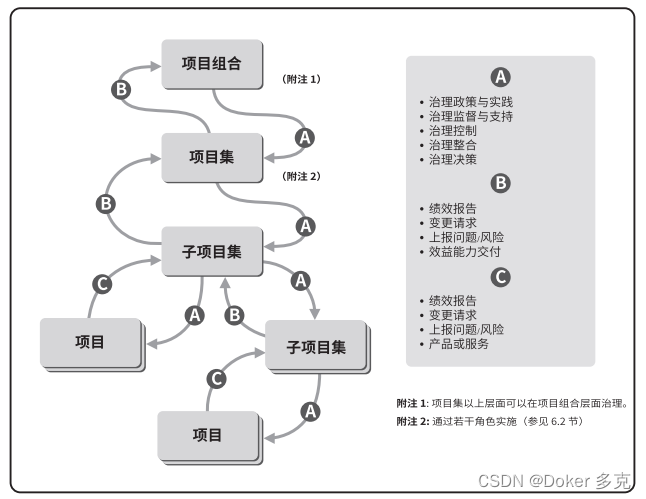
MobileViT 的网络结构如下图所示。核心思想是学习用变压器作为卷积的全局表示,在网络中隐式地合并卷积类属性(例如,空间偏差)。

在 MobileViT Block 中, Conv-n x n 表示一个标准的 n x n的卷积; MV2 表示 MobileNetv2 block;
↓
2
\downarrow 2
↓2 表示下采样。
表4展示了不同参数预算下MobileViT的整体架构,可以帮助大家更清晰地理解 MobileViT 网络到底由哪些块组成。

2. 模型详解
为了帮助大家更好地理解模型中各个块的内容,这个章节分别介绍了 MobileViT Block 的具体内容 以及 MV2 块的结构。
2.1 MobileViT Block
MobileViT Block 旨在用更少的参数对输入张量中的局部和全局信息进行建模。MobileViT Block 整体由三部分组成。分别为:Local representations、Transformers as Convolutions (global representations)、Fusion。
2.1.1 Local representations
Local representations 表示输入信息的局部表达。在这个部分,输入MobileViT Block 的数据会经过一个
n
×
n
n \times n
n×n 的卷积块和一个
1
×
1
1 \times 1
1×1 的卷积块。从上文所述的 CNN 的空间归纳偏差就可以得知:经过
n
×
n
n \times n
n×n 的卷积块的输出获取到了输入模型的局部信息表达(因为卷积块是对一个整体块进行操作,但是这个卷积核的
n
n
n 是远远小于数据规模的,所以是局部信息表达,而不是全局信息表达)。另外,
1
×
1
1 \times 1
1×1 的卷积块是为了线性投影,将数据投影至高维空间。例如:对于
9
×
9
9\times 9
9×9 的数据,使用
3
×
3
3\times 3
3×3 的卷积层,获取到的每个数据都是对
9
×
9
9\times 9
9×9 数据的局部表达
2.1.2 Transformers as Convolutions (global representations)
Transformers as Convolutions (global representations) 表示输入信息的全局表示。在Transformers as Convolutions 中首先通过Unfold 对数据进行转换,转化为 Transformer 可以接受的 1D 数据。然后,将数据输入到Transformer 块中。最后,通过Fold再将数据变换成原有的样子。
具体而言:
- 数据
X
∈
R
H
×
W
×
C
X \in R^{H\times W \times C}
X∈RH×W×C在经过
Local representations后得到数据 X L ∈ R H × W × d X_L \in R^{H\times W \times d} XL∈RH×W×d,其中 d > C d>C d>C。然后,数据被切分为多个patch,patch的长和宽分别为 h , w h,w h,w,patch的总数量为 N = H W P N =\frac{HW}{P} N=PHW,其中 P = w h P=wh P=wh。最终经过Unfold后得到的数据 X U ∈ R P × N × d X_U \in R^{P\times N \times d} XU∈RP×N×d 。注意:此时的数据还是2D数据,在代码中为了处理该数据,将Batch_size 跟P叠加在一起,得到数据: X U ∈ R B P × N × d X_U \in R^{BP\times N \times d} XU∈RBP×N×d,其中 B B B 表示Batch_size 。 - 在对于每一个
p
∈
{
1
,
.
.
.
,
P
}
p\in \{1,...,P\}
p∈{1,...,P},通过
Transformer对patch间关系进行编码,得到 X G ∈ R P × N × d X_G \in R^{P\times N \times d} XG∈RP×N×d
X G ( p ) = T r a n s f o r m e r ( X U ( p ) ) 1 ≤ p ≤ P X_G(p) = Transformer(X_U(p)) \ \ \ \ \ \ \ \ \ \ 1 \leq p \leq P XG(p)=Transformer(XU(p)) 1≤p≤P - 与丢失像素空间顺序的ViTs不同,
MobileViT既不丢失补丁顺序,也不丢失每个补丁内像素的空间顺序。因此,可以重新FoldX G ∈ R P × N × d X_G \in R^{P\times N \times d} XG∈RP×N×d 得到 X F ∈ R H × W × d X_F \in R^{H\times W \times d} XF∈RH×W×d。
请注意,由于
X
U
(
p
)
X_U(p)
XU(p) 使用卷积编码来自
n
×
n
n × n
n×n 区域的局部信息,而
X
G
(
p
)
X_G(p)
XG(p) 对第p个位置的p个补丁编码全局信息,因此
X
G
X_G
XG 中的每个像素都可以编码来自
X
X
X 中所有像素的信息,如下图所示。因此,MobileViT的整体有效接受野为:
H
×
W
H × W
H×W。

如上图所示,蓝色的部分表示经过
n
×
n
n × n
n×n 获取到的局部信息,即周围区域的局部信息用一个蓝色方框表示;红色方框表示 Transformer 部分,获取所有蓝色方框的信息。总的来说:红色方框可以获取到全部方框的信息,因此说:MobileViT的整体有效接受野为:
H
×
W
H × W
H×W。
2.1.3 Fusion
在Fusion中,得到的信息与原始输入信息(
X
∈
R
H
×
W
×
C
X \in R^{H\times W \times C}
X∈RH×W×C)进行合并,然后使用另一个
n
×
n
n × n
n×n 卷积层来融合这些连接的特征。这里,得到的信息指:全局表征
X
F
∈
R
H
×
W
×
d
X_F \in R^{H\times W \times d}
XF∈RH×W×d 经过逐点卷积(
1
×
1
1\times 1
1×1 卷积)得到的输出
X
F
u
∈
R
H
×
W
×
d
X_{Fu} \in R^{H\times W \times d}
XFu∈RH×W×d ,并通过串联操作与
X
X
X 组合。
2.2 MV2
MV2 块指MobileNet v2 block,是一个倒残差结构。 在倒残差结构中,高维信息通过ReLU激活函数后丢失的信息更少(注意倒残差结构中基本使用的都是ReLU6激活函数,但是最后一个1x1的卷积层使用的是线性激活函数)。具体网络结构如下图所示。

3. 简化版理解
可能看了上述的内容,大家对于 MobileViT 的整体还是不太理解。这里对文章内容进行口语式解答来帮助大家理解文章内容。
MobileViT 这篇文章使用CNN和Transformer相融合的方案,在减少模型复杂度的同时,提高了模型的精度和鲁棒性。
具体而言:
- 对于一个模型,如果全都使用 CNN 结构。模型只能获取到数据的
局部信息而获取不到全局信息。 - 对于一个模型,如果全部使用 Transformer 结构。模型可以获取到
全局信息。但是,全都使用 Transformer 结构会带来较大的复杂度,存在训练时间上升,模型容易过拟合等等问题。
因此,基于上述问题。作者先使用CNN获取局部信息,然后使用 Transformer 结构获取全局信息。通过上述的理解可以发现:在MobileViT 中的Transformer 结构中,复杂度相比于 ViT 结构 中复杂度降低了很多(因为输入数据复杂度的降低)。
最终实验结果同时表明:MobileViT 精度更高且鲁棒性更好。
4. 总结
整体而言,MobileViT 通过融合CNN和 Transformer 来得到了不错的效果。同时,也让我们了解:Transformer 虽好,但是也存在一系列的问题,不能强行使用Transformer 。如果有什么疑问欢迎在评论区提出,对于共性问题可能会后续添加到文章介绍中。
到此,有关MobileViT的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
![[NOI2009] 描边](https://img-blog.csdnimg.cn/img_convert/bea20425d2d855aa931211e2cee53f33.png)