目录
文章目录
- 目录
- 操作系统虚拟化(容器技术)的发展历程
- Chroot
- Cgroups
- Cgroup Subsystems
- Cgroup Filesystem
- Cgroup Hierarchy
- Cgroups 的操作规则
- Cgroups 的代码实现
- Namespaces
- UTS namespace
- PID namespace
- IPC namespace
- Mount namespace
- Network namespace
- User namespace
- Docker 对 Cgroups 和 Namespaces 的应用
- 参考文档
操作系统虚拟化(容器技术)的发展历程
1979 年,UNIX 的第 7 个版本引入了 Chroot 特性。Chroot 现在被认为是第一个操作系统虚拟化(Operating system level virtualization)技术的原型,本质是一种操作系统文件系统层的隔离技术。
2006 年,Google 发布了在 Linux 上运行的 Process Container(进程容器)技术,其目标是提供一种类似于 Virtual Mahine(计算机虚拟化技术)的、但主要针对 Process 的操作系统级别资源限制、优先级控制、资源审计能力和进程控制能力。
2007 年,Google 推动 Process Container 代码合入 Linux Kernel。同时由于 Container 这一命名在 Kernel 具有许多不同的含义,所以为了避免代码命名的混乱,就将 Process Container 更名为了 Control Groups,简称:Cgroups。
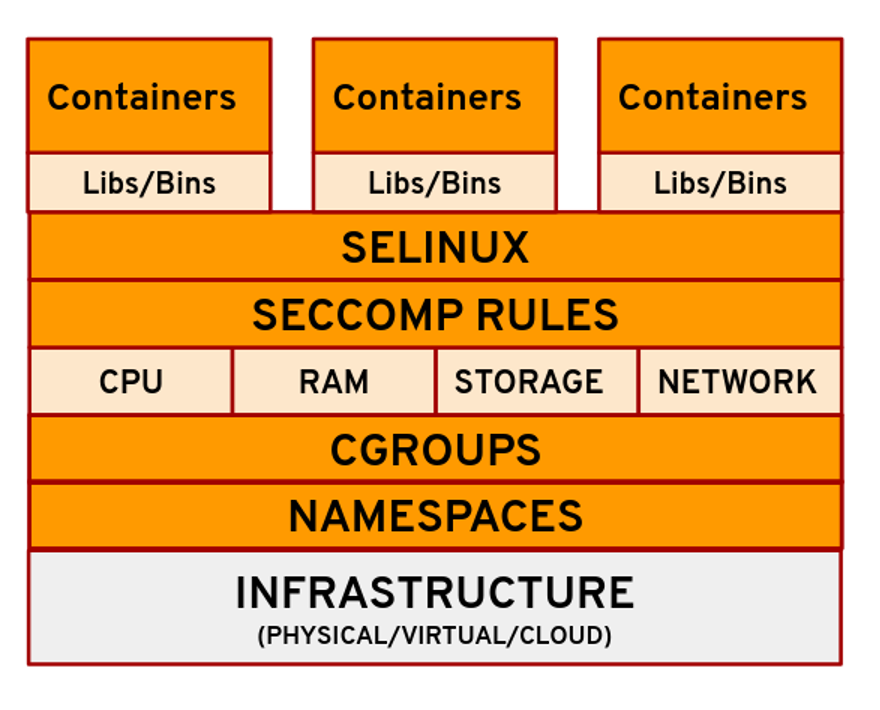
2008 年,Linux 社区整合了 Chroot、Cgroups、Namespaces、SELinux、Seccomp 等多种技术并发布了 LXC(Linux Container)v0.1.0 版本。LXC 通过将 Cgroups 的资源配额管理能力和 Namespace 的资源视图隔离能力进行组合,实现了完备的轻量级操作系统虚拟化。
2013 年 3 月 15 日,在加利福尼亚州圣克拉拉召开的 Python 开发者大会上,DotCloud 的创始人兼首席执行官 Solomon Hvkes 在一场仅 5 分钟的微型演讲中,首次发布了基于 LXC 封装的 Docker Container,并于会后将其源码开源并托管到 Github。
Chroot
Chroot 是一个可供 User Process 调用的 System Call 接口,可以让一个 Process 把指定的目录作为根目录(Root Directory),随后 Process 所有的文件系统操作都只能在这个指定目录中进行。故称之为 Change Root。
chroot() 的函数原型非常简单:
- 调用权限:Root 用户。
- 形参列表:
- path:一个指向字符串的指针,是一个绝对路径,表示将 Process 的根目录更改为的该目录路径。
- 函数返回:
- 成功:返回 0;
- 失败:返回 -1。
#include <unistd.h>
int chroot(const char *path);
需要注意的是,在更改了 Process 的根目录后,Process 只能访问新的根目录以及其子目录中的文件和资源。因此,在调用 chroot() 后,应确保 Process 所需要访问的所有文件和资源都存在于新的根目录下。
chroot() 目前主要主要用于:
- 安全隔离场景:限制将 Process 的访问范围,以此提高系统的安全性。
- 调试环境场景:创建一个与主系统隔离的环境,用于调试、测试和运行 Process。
- 系统救援场景:在 Linux 操作系统损坏或遭受攻击时,可以使用 chroot 将 Process 切换到受损系统的根目录中,以便进行修复和救援操作。
可见,chroot() 确实在 Linux File System(文件系统)层面提供了针对 Process 的隔离性,但并不提供完全的安全隔离,无法阻止其他方式的攻击。因此,要想实现 Processes 之间的安全隔离,还需要需采取其他安全措施。
Cgroups
Cgroups(Control Groups)是 Linux Kernel 提供的一种针对 User Process 或 Kernel Thread 的操作系统资源配额与管理技术,主要包括以下 4 个方面:
- 资源配额:限制进程对某一系统资源的用量配额。
- 优先级:当发生资源竞争时,优先保障哪些进程的资源使用。
- 审计:监控及报告进程对资源限制及使用。
- 控制:控制进程的状态,例如:运行、挂起、恢复。
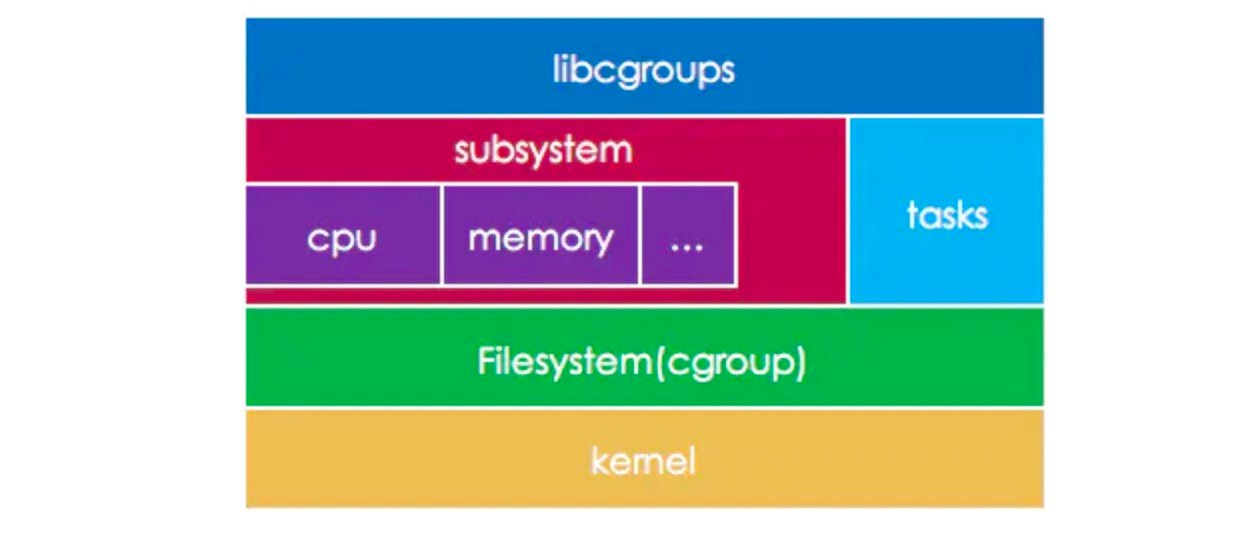
Cgroups 设计与实现的核心概念如下图所示,包括:
- libcgroups:提供了一组编程接口库和应用程序。
- Tasks:User Process 和 Kernel Thread 的统一抽象。因为在 Kernel 中 User Process 或 Kernel Thread 实际上只通过 clone() SCI 传递的参数不同来进行区分,它们都使用了 task_struct 描述。
- Subsystems:可控资源的类型定义。
- Control Group(cgroup):是一个用于关联若干 Tasks 和 Subsystems 的资源控制组描述。下文中使用小写的 cgroup 来表述一个特定的 Control Group。
- Cgroup Filesystem:通过 VFS(虚拟文件系统)统一文件接口的方式向 Userspace 提供 cgroup 的配置入口。
Cgroup Subsystems
Cgroups 将多种可被管控的系统资源类型定义为 Subsystems(子系统),包括有:
- cpu:限制 Task 的单颗 CPU Core 使用率。
- cpuset:限制 Task 使用的 CPU Core 集合。
- cpuacct:统计 Task 的 CPU 使用报告(Accounting)。
- memory:限制 Task 使用的 Memory 容量。
- hugetlb:限制 Task 的大页内存容量。
- devices:限制 Task 能够访问的设备。
- blkio:限制 Task 的 Block I/O 使用率。
- net_cls:限制 Task 的网络数据包类型(Network Classifier)和 Net I/O 使用率。
- net_prio:设置 Task 的网络流量(Network Traffic)处理优先级。
- namespace:限制 Task 使用不同的 Namespaces。
- freezer:挂起或者恢复指定的 Task。
- perf_event:允许使用 perf 工具来进行监控。
- pids:限制 cgroup 关联的 Tasks 数量。
- 等等。
这些 Subsystems 的定义主要是为了提供相应的配置入口,而具体对系统资源进行限制的实现则是充分复用了 Kernel 自身的多种功能模块来完成,例如:
- cpu Subsystem 依赖 Kernel Process Scheduler 实现。
- memory Subsystem 依赖 Kernel Memory Manager 实现。
- net_cls Subsystem 依赖 Kerne Traffic Control 实现。
- 等等。
通过 CLI 可以查看系统中支持的 Cgroup Subsystems:
$ sudo yum install libcgroup-tools
$ lssubsys -a
cpuset
cpu,cpuacct
blkio
memory
devices
freezer
net_cls,net_prio
perf_event
hugetlb
pids
rdma
Cgroup Filesystem
Cgroups 通过 Kernel VFS(Virtual File System,虚拟文件系统)文件接口的方式向 Userspace 提供了统一的 cgroup 配置入口。
通过 CLI 可以查看当前 Cgroup Filesystem 的挂载路径与内容:
$ df -h
Filesystem Size Used Avail Use% Mounted on
...
tmpfs 16G 0 16G 0% /sys/fs/cgroup
$ ll /sys/fs/cgroup/
总用量 0
drwxr-xr-x. 4 root root 0 6月 1 16:22 blkio
lrwxrwxrwx. 1 root root 11 6月 1 16:22 cpu -> cpu,cpuacct
lrwxrwxrwx. 1 root root 11 6月 1 16:22 cpuacct -> cpu,cpuacct
drwxr-xr-x. 4 root root 0 6月 1 16:22 cpu,cpuacct
drwxr-xr-x. 2 root root 0 6月 1 16:22 cpuset
drwxr-xr-x. 4 root root 0 6月 1 16:22 devices
drwxr-xr-x. 2 root root 0 6月 1 16:22 freezer
drwxr-xr-x. 2 root root 0 6月 1 16:22 hugetlb
drwxr-xr-x. 4 root root 0 6月 1 16:22 memory
lrwxrwxrwx. 1 root root 16 6月 1 16:22 net_cls -> net_cls,net_prio
drwxr-xr-x. 2 root root 0 6月 1 16:22 net_cls,net_prio
lrwxrwxrwx. 1 root root 16 6月 1 16:22 net_prio -> net_cls,net_prio
drwxr-xr-x. 2 root root 0 6月 1 16:22 perf_event
drwxr-xr-x. 4 root root 0 6月 1 16:22 pids
drwxr-xr-x. 4 root root 0 6月 1 16:22 systemd
可以看见,默认的情况下,Cgroups 会为 Subsystems 创建好它们各自的 Cgroup Filesytem,内含了用于设定资源配额、以及用于关联到若干个 Tasks 所需要的文件。如下所示。
$ ll /sys/fs/cgroup/memory/
总用量 0
-rw-r--r--. 1 root root 0 6月 1 16:22 cgroup.clone_children
--w--w--w-. 1 root root 0 6月 1 16:22 cgroup.event_control
-rw-r--r--. 1 root root 0 6月 1 16:22 cgroup.procs
-r--r--r--. 1 root root 0 6月 1 16:22 cgroup.sane_behavior
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.failcnt
--w-------. 1 root root 0 6月 1 16:22 memory.force_empty
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.failcnt
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.limit_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.max_usage_in_bytes
-r--r--r--. 1 root root 0 6月 1 16:22 memory.kmem.slabinfo
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.tcp.failcnt
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.tcp.limit_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.kmem.tcp.max_usage_in_bytes
-r--r--r--. 1 root root 0 6月 1 16:22 memory.kmem.tcp.usage_in_bytes
-r--r--r--. 1 root root 0 6月 1 16:22 memory.kmem.usage_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.limit_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.max_usage_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.memsw.failcnt
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.memsw.limit_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.memsw.max_usage_in_bytes
-r--r--r--. 1 root root 0 6月 1 16:22 memory.memsw.usage_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.move_charge_at_immigrate
-r--r--r--. 1 root root 0 6月 1 16:22 memory.numa_stat
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.oom_control
----------. 1 root root 0 6月 1 16:22 memory.pressure_level
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.soft_limit_in_bytes
-r--r--r--. 1 root root 0 6月 1 16:22 memory.stat
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.swappiness
-r--r--r--. 1 root root 0 6月 1 16:22 memory.usage_in_bytes
-rw-r--r--. 1 root root 0 6月 1 16:22 memory.use_hierarchy
-rw-r--r--. 1 root root 0 6月 1 16:22 notify_on_release
-rw-r--r--. 1 root root 0 6月 1 16:22 release_agent
drwxr-xr-x. 55 root root 0 6月 1 16:23 system.slice
-rw-r--r--. 1 root root 0 6月 1 16:22 tasks
drwxr-xr-x. 2 root root 0 6月 1 16:23 user.slice
其中 cgroup 的 Core 接口文件以 cgroup 为前缀:
- cgroup.clone_children:标识 Child cgroup 是否会继承 Parent cgroup。默认值为 0,表示不继承。
- cgroup.procs:当是 Root cgroup 时,会记录该 Hierarchy 中所有的 PIDs。
- 等等。
而 memory 为前缀的则为 Controller 接口文件,是 Cgroups 资源分配模型设计的控制器,包括:
- 权重(weight):按照权重比率来分配资源。
- 限制(max):限制资源被过度使用。
- 保护:可以是硬保护,也可能是软保护。
- 分配:资源分配参数。
其余还有一个管理接口文件,例如:
- notify_on_release:标识当这个 cgroup 最后一个 Task 退出的时候是否执行 release_agent。
- release_agent:是一个路径,用作 Task 退出后自动清理掉不再使用的 cgroup。
- tasks:记录了关联到这个 cgroup 的 Tasks 列表。
Cgroup Hierarchy
Cgroups 使用 Filesystem 的方式来提供操作入口,所带来的另一个好处就是支持 Cgroup Hierarchy(层次化)组织形式,表现为一棵树状的结构。
当用户在 Parent cgroup 中创建了一个 Child cgroup 之后,Child cgroup 同样会自动创建所需要的配置文件,并可以配置是否继承 Parent cgroup 的相关配置。如下图所示。
$ mkdir /sys/fs/cgroup/memory/cgrp1/
$ ls /sys/fs/cgroup/memory/cgrp1/
cgroup.clone_children memory.kmem.limit_in_bytes memory.kmem.tcp.usage_in_bytes memory.memsw.max_usage_in_bytes memory.soft_limit_in_bytes tasks
cgroup.event_control memory.kmem.max_usage_in_bytes memory.kmem.usage_in_bytes memory.memsw.usage_in_bytes memory.stat
cgroup.procs memory.kmem.slabinfo memory.limit_in_bytes memory.move_charge_at_immigrate memory.swappiness
memory.failcnt memory.kmem.tcp.failcnt memory.max_usage_in_bytes memory.numa_stat memory.usage_in_bytes
memory.force_empty memory.kmem.tcp.limit_in_bytes memory.memsw.failcnt memory.oom_control memory.use_hierarchy
memory.kmem.failcnt memory.kmem.tcp.max_usage_in_bytes memory.memsw.limit_in_bytes memory.pressure_level notify_on_release

最后,在每个 cgroup 的 Filesystem 中都包含了一个 tasks 文件,用于保存关联到当前 cgroup 的 Tasks 列表。如果我们想向某个 cgroup 添加一个 User Process 时,就可以把它的 PID 写入到 tasks 文件中。如下:
$ cd /sys/fs/cgroup/memory/cgrp1 # 进入 cgrp1
$ echo 1029 > tasks # 将 PID 1029 的 Process 添加到 cgrp1 的 tasks 列表
Cgroups 的操作规则
用户在使用 Cgroups 时,必须按照一定的操作规则,否则会出现错误。操作规则的目的是为了避免资源配额的配置存在冲突。
-
一个 Hierarchy 可以 Attach 多个 Subsystems,如下图将 cpu 和 memory Subsystems Attached 到了同一个 Hierarchy。
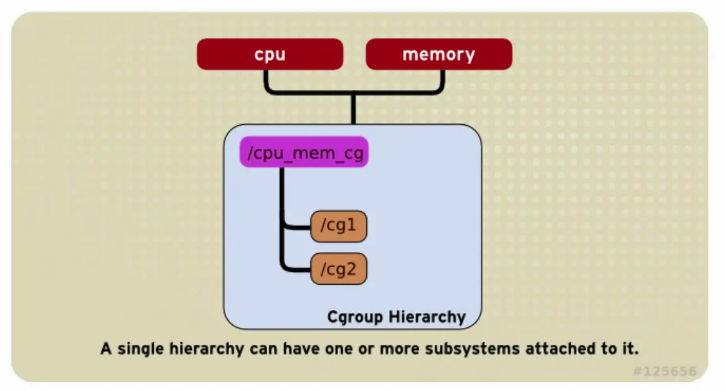
-
一个已经被 Attached 的 Subsystem 只能被再次 Attach 在一个空的 Hierarchy 上,不能 Attach 到一个已经 Attached 了其他 Subsystems 的 Hierarchy 上,如下图 cpu Subsystem 已经 Attached 到了 Hierarchy A,并且 memory Subsystem 已经附加到了 Hierarchy B。因此 cpu Subsystem 不能再 Attach 到 Hierarchy B,只能 Attach 另一个空的 Hierarchy C 上。
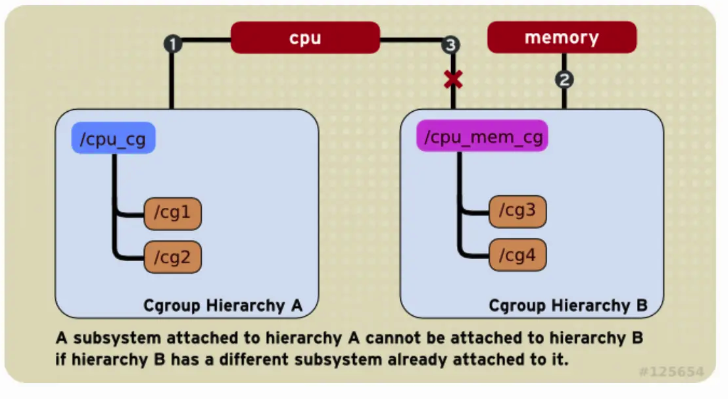
-
每个 Task 只能在同一个 Hierarchy 的唯一一个 cgroup tasks 里,并且可以在多个不同 Hierarchy 的 cgroup tasks 里。如下图,这样保证了对于一个 Task 的同一种 cgroup 配额是唯一的。
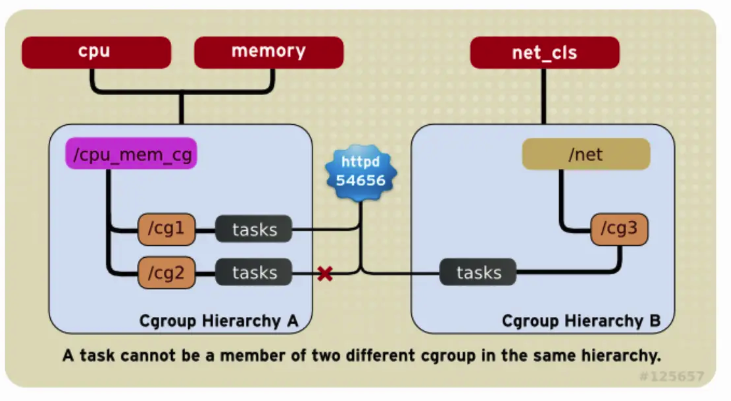
-
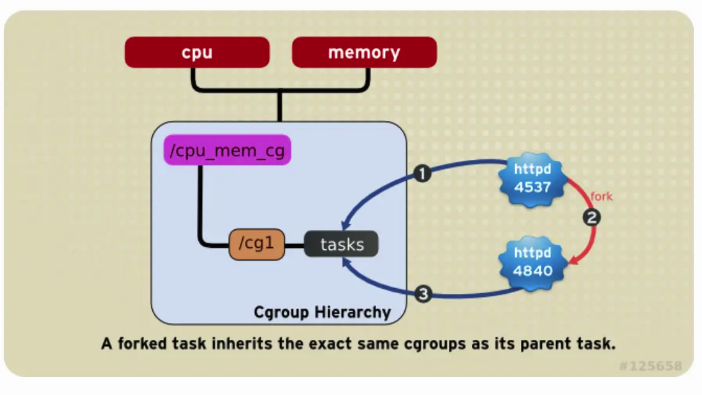
子进程在被 fork 出时自动继承父进程所在 cgroups,但是 fork 之后就可以按需调整到其他 cgroup,如下图:
Cgroups 的代码实现
现在回头再看 Kernel 中对 cgroup 的声明定义,它被设计成了一个树数据结构:
struct cgroup {
...
// 下面 3 个字段把 cgroup 设计成了一个树数据结构
struct list_head sibling; // 兄弟节点
struct list_head children; // 子节点
struct cgroup *parent; // 父节点
struct dentry *dentry; // cgroup 对应的目录对象
// cgroup 关联的 subsystems 对象
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
...
};
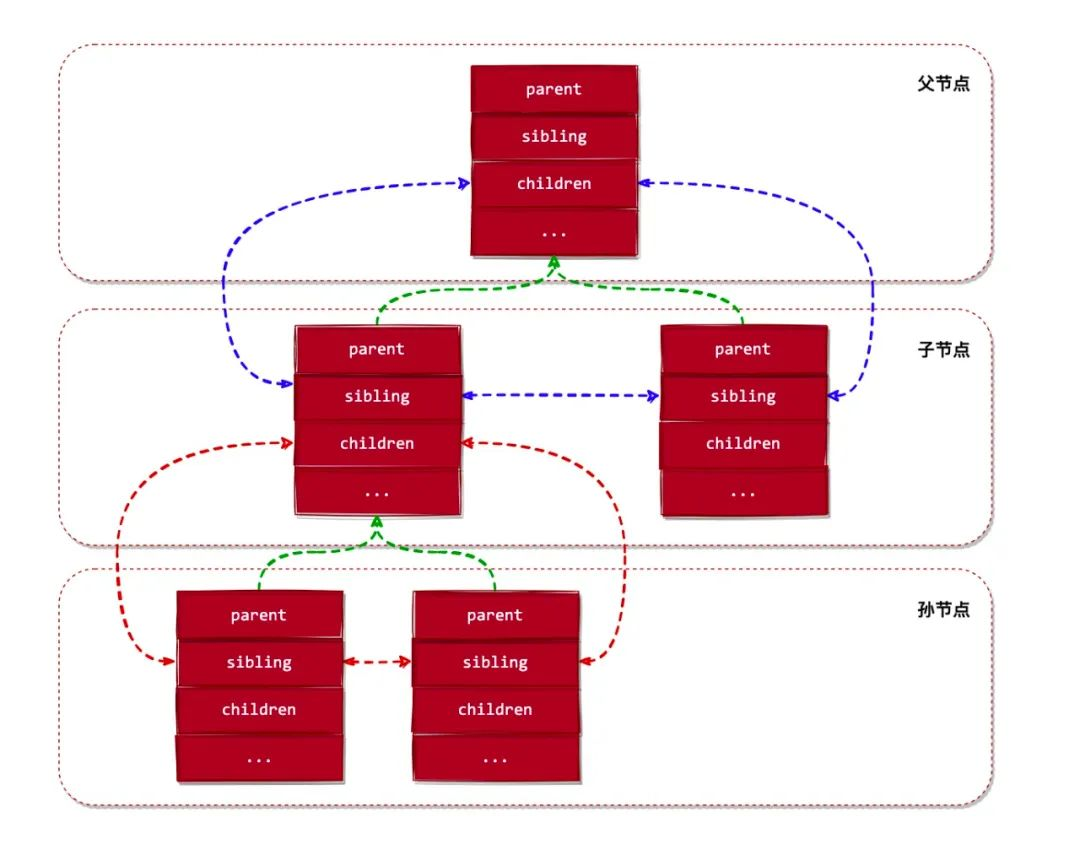
默认情况下,在 Kernel 启动过程中,会自动实例化一个 rootnode(根节点),并将所有 Subsystems 的 cgroup FS 关联到此 rootnode。
static struct cgroupfs_root rootnode;
struct cgroupfs_root {
struct super_block *sb; // Root cgroup FS 的挂载点(VFS 使用)
...
struct list_head subsys_list; // Root cgroup 绑定的 Subsystems 列表
struct cgroup top_cgroup; // Root cgroup 对象
int number_of_cgroups; // Root cgroup 拥有的 cgroups 的数量
...
};
如果用户想手动的把 Subsystems 挂在到其他 cgroup FS,也可以使用 mount 命令来进行挂载,如下命令所示:
$ mount -t cgroup -o memory memory /sys/fs/cgroup/memory1
另外,cgroup 中的 cgroup_subsys_state 字段用于关联到一个 Subsystems State(子系统资源统计结构体)列表,再关联到若干个具体的 Subsystems。
struct cgroup_subsys_state {
struct cgroup *cgroup; // 指向 cgroup 对象
atomic_t refcnt; // 引用计数器
unsigned long flags; // 标志位
};
struct mem_cgroup {
// 资源统计对象通用部分
struct cgroup_subsys_state css;
// 资源统计对象私有部分
struct res_counter res; // 用于统计 tasks 的内存使用情况
struct mem_cgroup_lru_info info;
int prev_priority;
struct mem_cgroup_stat stat;
};
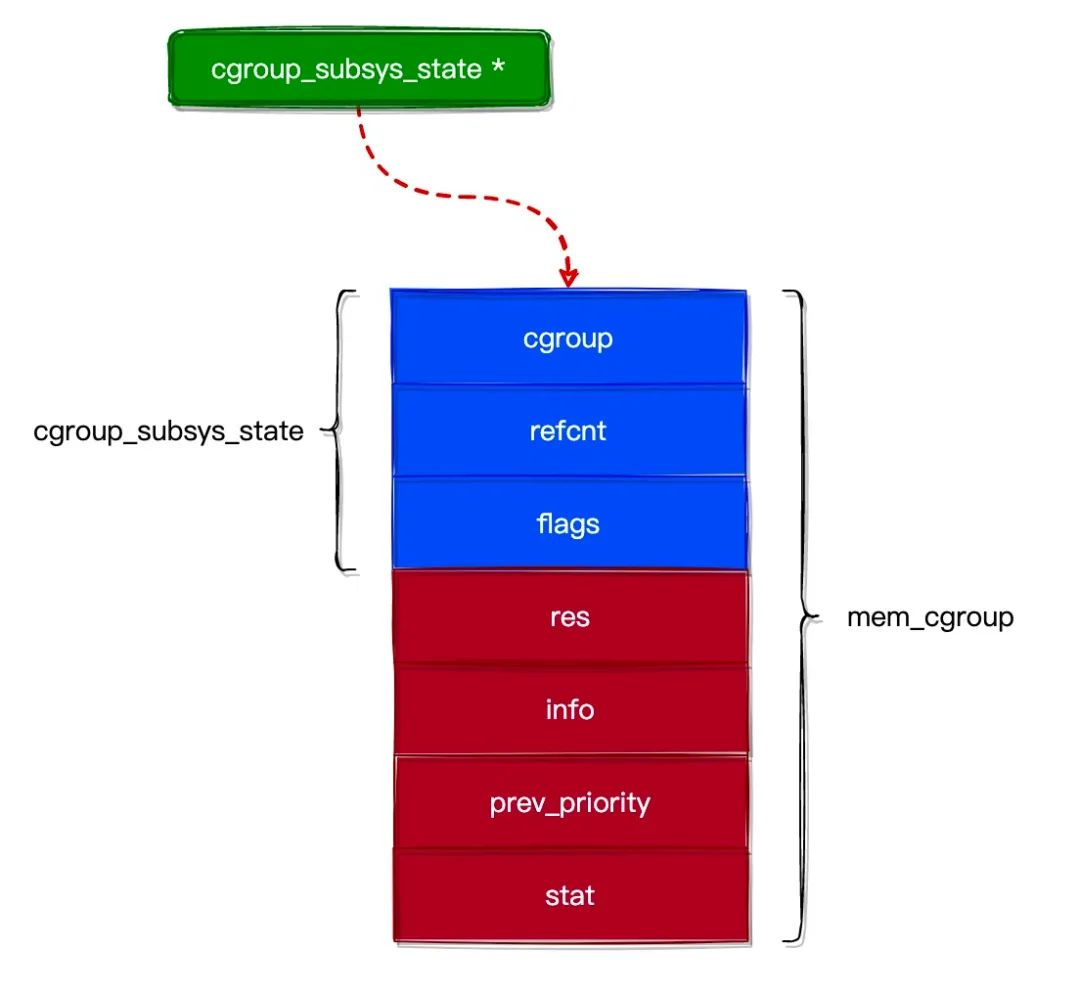
可见 cgroup 和 Subsystems 是一对多的关系,如下图所示。
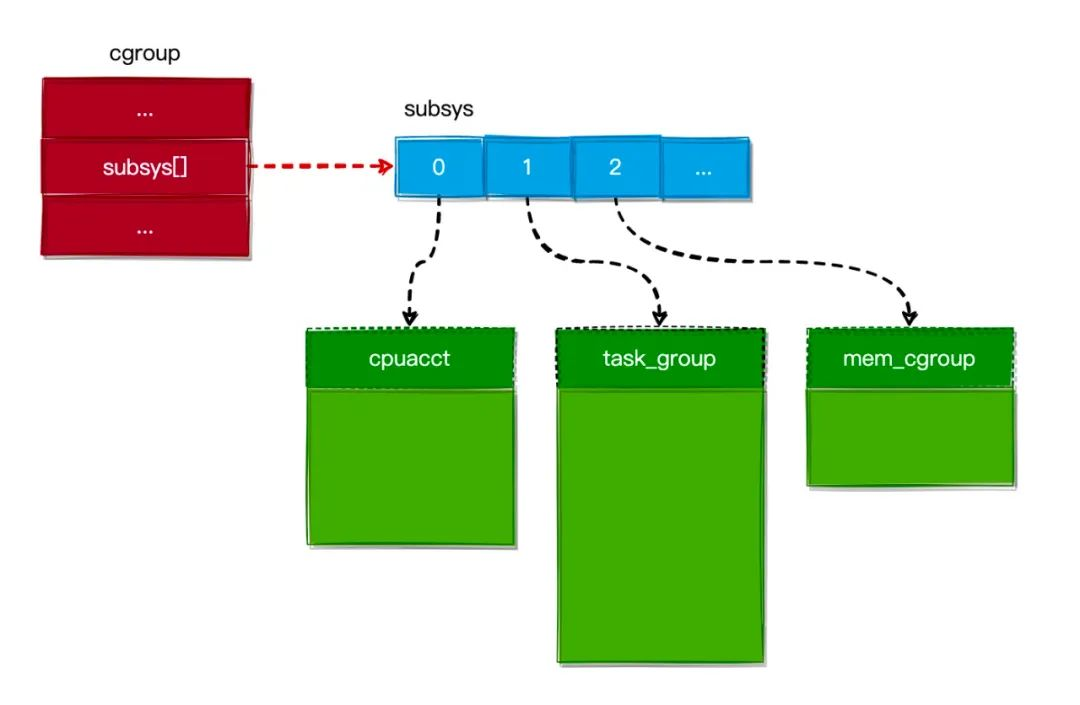
同时又由于一个 Task 可以关联到多个 cgroups 中,最终实现了 Tasks 和 Subsystems 之间的多对多关系。如下图所示:
- ProcessA 属于 /sys/fs/cgroup/memory/cgrp1/cgrp3 和 /sys/fs/cgroup/cpu/cgrp2/cgrp3,所以 ProcessA 就关联了 mem_groupA 和 task_groupA 这两个 Cgroup Subsystems State。
- ProcessB 属于 /sys/fs/cgroup/memory/cgrp1/cgrp4 和 /sys/fs/cgroup/cpu/cgrp2/cgrp3,所以 ProcessB 就关联了 mem_groupB 和 task_groupA 这两个 Cgroup Subsystems State。
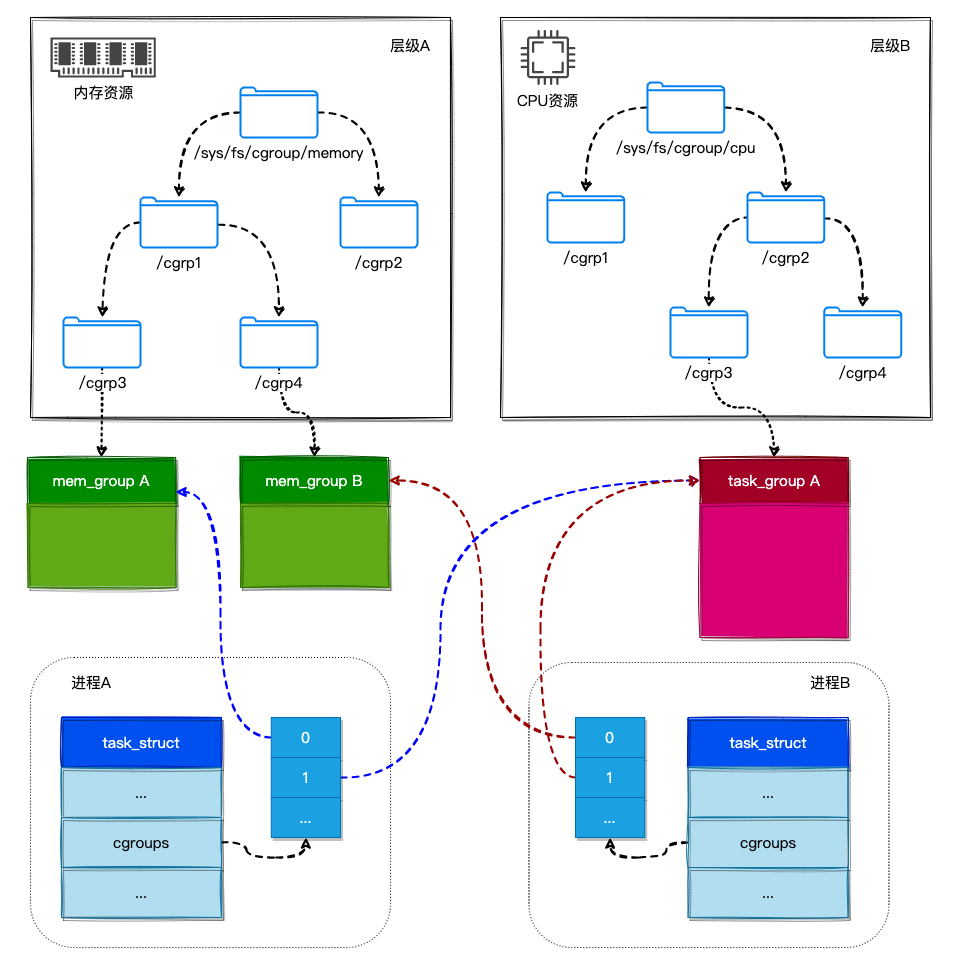
在 Task 的 task_struct 中通过 css_set 字段来记录自己所关联的 Cgroup Subsystems State 列表,如下:
struct task_struct {
...
struct css_set *cgroups;
...
};
struct css_set {
...
// 用于收集不同 cgroup 的资源统计对象
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
};
最终 User Process 和 Cgroups 之间就构成了一个 M×N Linkage 的映射关系结构。如下图所示。

Namespaces
Linux Namespaces(命名空间)是一种操作系统层级的资源视图隔离技术,能够将 Linux 的全局资源,划分为 Namespace 范围内可见的资源。
Namespaces 具有多种类型,基本上涵盖了构成一个操作系统所需要的基本元素:
- UTS namespace(系统主机名)
- Time namespace(系统时间)
- PID namespace(系统进程号)
- IPC namespace(系统进程间通信)
- Mount namespace(系统文件系统)
- Network namespace(系统网络)
- User namespace(系统用户权限)
- Cgroup namespace(系统 Cgroup)
User Process 是 Namespace 的主要服务对象,与之相关的 SCI 主要有 3 个:
- clone():创建一个 Process,同时设置 Namespace Instance 的类型参数。
- setns():把一个 Process 加入到指定的 Namespace Instance。
- unshare():把一个 Process 脱离指定的 Namespace Instance。
如下图所示,每种 Namespaces 都拥有各自的 clone 类型参数:
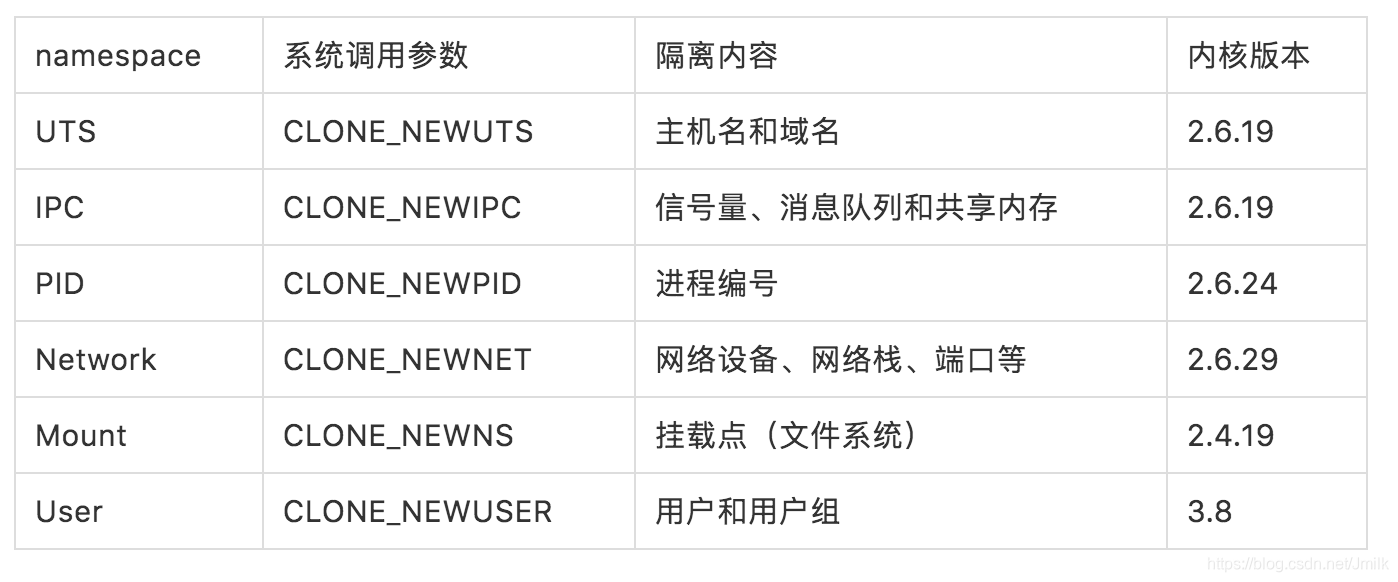
通过 /proc/{pid}/ns 文件可以查看指定 Process 运行在哪些 Namespaces Instance 中,并且每个 Namespace Instance 都具有一个唯一的标识。
$ ls -l --time-style='+' /proc/$$/ns
总用量 0
lrwxrwxrwx. 1 root root 0 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 uts -> uts:[4026531838]
最终,用户可以通过创建多种不同类型的 Namespaces Instance 来提供的操作系统资源的隔离,再结合创建多种不同类型的 cgroups 来提供操作系统的资源配额,就构成了一个最基本的操作系统容器,即:Process Container。
UTS namespace
UTS namespace 为 Container 提供了 Hostname 和 Domain Name 的隔离。
Container 中的 Process 可以根据需要调用 sethostname 和 setdomainname 指令来进行配置,让每个 Container 都可以被视为网络中的一个独立的节点。
PID namespace
PID namespace 为 Container 提供了进程号的隔离。
每个 Containers 都拥有自己的进程环境,Container 的 init Process 都是 PID 1 号进程,它作为所有子进程的父进程。要想做到进程的隔离,首先需要创建出 PID 1 号进程,它具有以下特性:
- 如果某个子进程脱离了父进程(父进程没有 wait 它),那么 init Process 就会负责回收资源并结束这个子进程。
- 如果 init Process 被终止,那么 Kernel 就会调用 SIGKILL 终止此 PID namespace 中的所有进程。
IPC namespace
IPC namespace 为 Container 提供了 IPC(进程间)通信机制的隔离,包括信号量、消息队列、共享内存等机制。
每个 Containers 都拥有以下 /proc 文件接口:
- /proc/sys/fs/mqueue:POSIX Message Queues 接口类型;
- /proc/sys/kernel:System V IPC 接口类型;
- /proc/sysvipc:System V IPC 接口类型。
Mount namespace
Mount namespace 为 Container 提供了 Filesystem 挂载点的隔离,继而实现了 VFS 的隔离。
每个 Containers 都拥有以下 /proc 文件接口,可以构成一个独立的 rootfs(Root 文件系统):
- /proc/[pid]/mounts
- /proc/[pid]/mountinfo
- /proc/[pid]/mountstats
实际上,Mount namespace 是基于 Chroot 的不断改良而开发出来的。为 Container 创建的 rootfs 只是一个操作系统发行版所包含的文件、目录和配置,并不包括 Kernel 的文件。
Network namespace
Network namespace 为 Container 提供了网络资源的隔离,包括:
- Network devices(网络设备)
- IPv4 and IPv6 protocol stacks(IPv4、IPv6 的协议栈)
- IP routing tables(IP 路由表)
- Firewall rules(防火墙规则)
- Sockets 套接字
- /proc/[pid]/net
- /sys/class/net
- /proc/sys/net
需要注意的是,同一个 Network device 只能存在于一个 Namespace Instance 中,所以常常结合虚拟网络设备来使用。

User namespace
User namespace 为 Container 提供了用户权限和安全属性相关的隔离,包括:User ID、User Group ID、Root 目录以及特殊的权限。
每个 Containers 都拥有以下 /proc 文件接口:
- /proc/[pid]/uid_map
- /proc/[pid]/gid_map
Docker 对 Cgroups 和 Namespaces 的应用
当我们创建了一个 Docker Container 之后就可以查看这个 Container 所具有的 cgroups 和 namespaces 了。
- 查看 Container 的 ID(cfca1212d140)和 PID(2240)配置。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cfca1212d140 centos:centos7.9.2009 "bash" 18 months ago Up 2 hours vim-ide
$ docker inspect --format='{{.State.Pid}}' cfca1212d140
2240
- 查看 Container 的 cgroups 配置。
$ ll /sys/fs/cgroup/memory/docker/
总用量 0
drwxr-xr-x. 2 root root 0 6月 2 03:40 cfca1212d1407a89632a439e974e246d1f6edd0bbef9079f06addf2613e1d46f
$ cat /sys/fs/cgroup/memory/docker/cfca1212d1407a89632a439e974e246d1f6edd0bbef9079f06addf2613e1d46f/cgroup.procs
2240
$ cat /sys/fs/cgroup/memory/docker/cfca1212d1407a89632a439e974e246d1f6edd0bbef9079f06addf2613e1d46f/memory.limit_in_bytes
9223372036854771712
- 查看 Container 的 namespaces 配置。
$ ls -l --time-style='+' /proc/2240/ns
总用量 0
lrwxrwxrwx. 1 root root 0 ipc -> ipc:[4026532433]
lrwxrwxrwx. 1 root root 0 mnt -> mnt:[4026532431]
lrwxrwxrwx. 1 root root 0 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 pid -> pid:[4026532434]
lrwxrwxrwx. 1 root root 0 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 uts -> uts:[4026532432]
参考文档
- https://mp.weixin.qq.com/s/EdRVEJ0i5j9eHwd8QK-cDg
- https://juejin.cn/post/6921299245685276686
- https://zhuanlan.zhihu.com/p/388101355