p6:Eureka简介与依赖导入
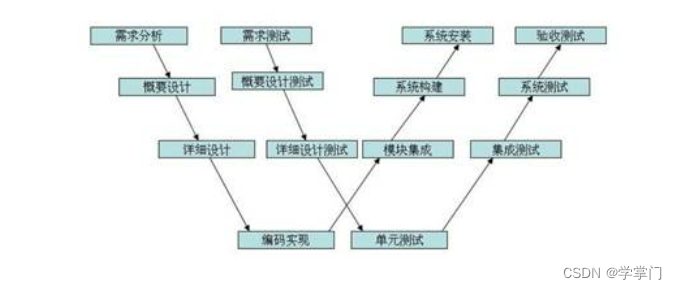
前面我们了解了如何对单体应用进行拆分,并且也学习了如何进行服务之间的相互调用,但是存在一个问题,就是虽然服务拆分完成,但是没有一个比较合理的管理机制,如果单纯只是这样编写,在部署和维护起来,肯定是很麻烦的。可以想象一下,如果某一天这些微服务的端口或是地址大规模地发生改变,我们就不得不将服务之间的调用路径大规模的同步进行修改,这是多么可怕的事情。我们需要削弱这种服务之间的强关联性,因此我们需要一个集中管理微服务的平台,这时就要借助我们这一部分的主角了。
Eureka能够自动注册并发现微服务,然后对服务的状态、信息进行集中管理,这样当我们需要获取其他服务的信息时,我们只需要向Eureka进行查询就可以了。
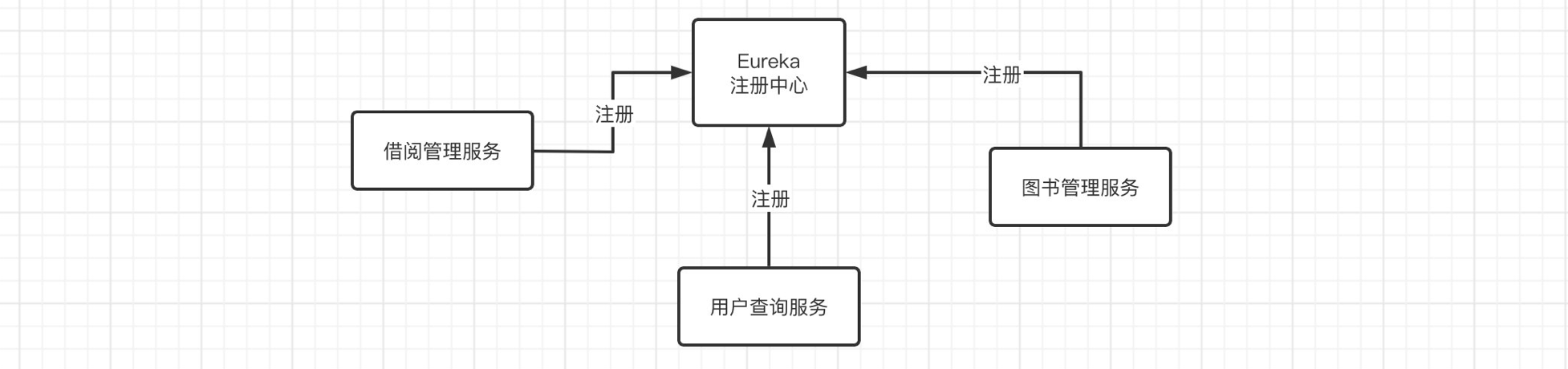
image-20230306225607857
像这样的话,服务之间的强关联性就会被进一步削弱。
那么现在我们就来搭建一个Eureka服务器,只需要创建一个新的Maven项目即可,然后我们需要在父工程中添加一下SpringCloud的依赖(注意在版本管理那里加入即可!),这里选用2021.0.1版本(Spring Cloud 最新的版本命名方式变更了,现在是 YEAR.x 这种命名方式,具体可以在官网查看:https://spring.io/projects/spring-cloud#learn):
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
复制代码接着我们为新创建的项目添加依赖:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
复制代码下载内容有点多,首次导入请耐心等待一下。
----------------------------------------------------------------------------------------------------
p7:Eureka服务注册与发现
接着我们来创建主类,还是一样的操作:
@EnableEurekaServer
@SpringBootApplication
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
复制代码别着急启动!!!接着我们需要修改一下配置文件:
server:
port: 8888
eureka:
# 开启之前需要修改一下客户端设置(虽然是服务端
client:
# 由于我们是作为服务端角色,所以不需要获取服务端,改为false,默认为true
fetch-registry: false
# 暂时不需要将自己也注册到Eureka
register-with-eureka: false
# 将eureka服务端指向自己
service-url:
defaultZone: http://localhost:8888/eureka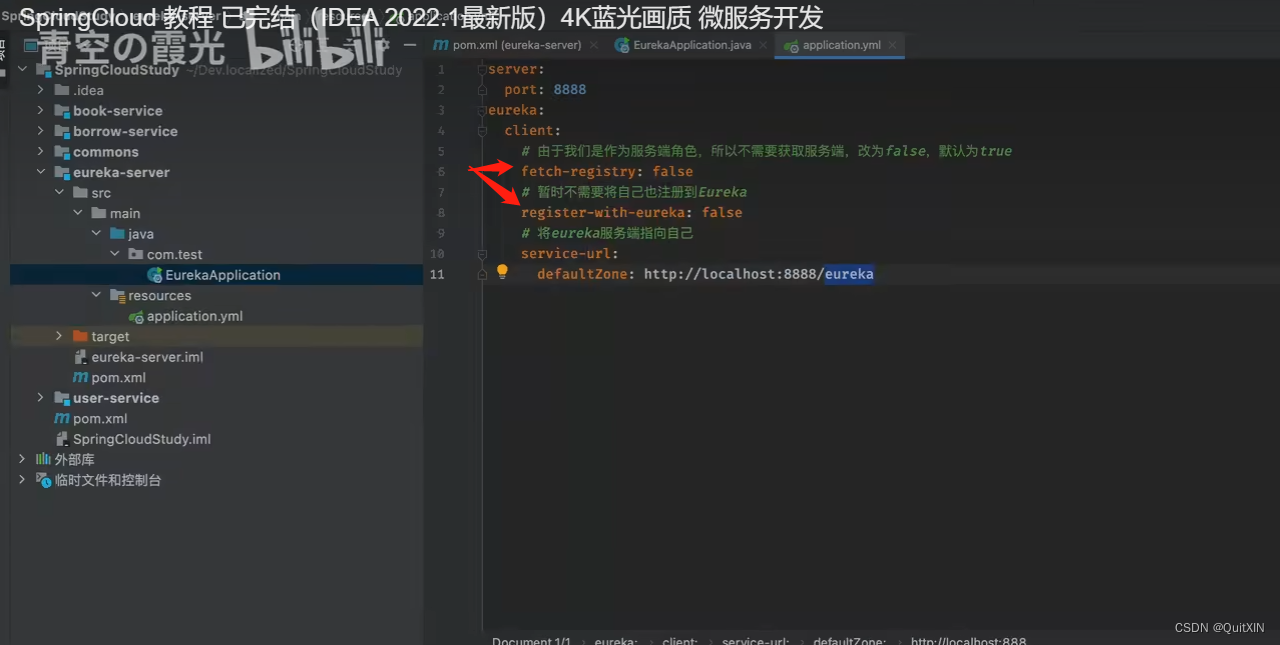
好了,现在差不多可以启动了,启动完成后,直接输入地址+端口(到8888即可,后面的不用)即可访问Eureka的管理后台:

image-20230306225619725
可以看到目前还没有任何的服务注册到Eureka,我们接着来配置一下我们的三个微服务,首先还是需要导入Eureka依赖(注意别导错了,名称里面有个starter的才是):
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
复制代码然后修改配置文件:
eureka:
client:
# 跟上面一样,需要指向Eureka服务端地址,这样才能进行注册
service-url:
defaultZone: http://localhost:8888/eureka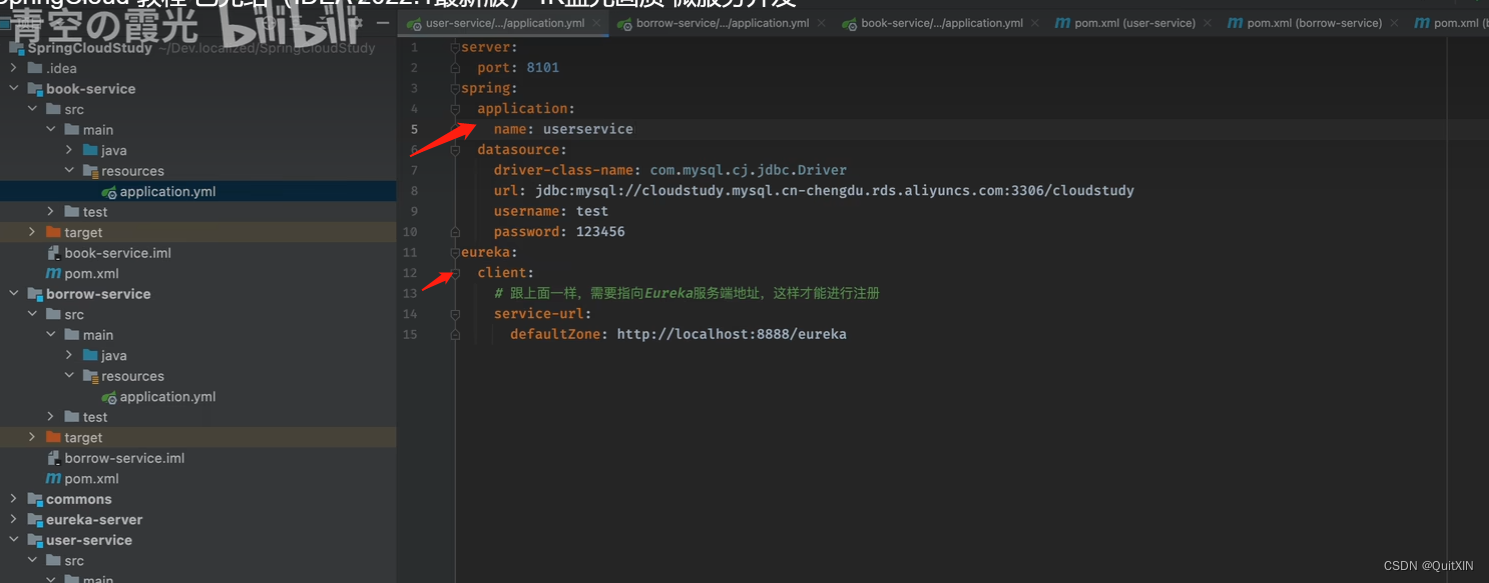
OK,无需在启动类添加注解,直接启动就可以了,然后打开Eureka的服务管理页面,可以看到我们刚刚开启的服务:

image-20230306225630173
可以看到8082端口上的服务器,已经成功注册到Eureka了,但是这个服务名称怎么会显示为UNKNOWN,我们需要修改一下:
spring:
application:
name: userservice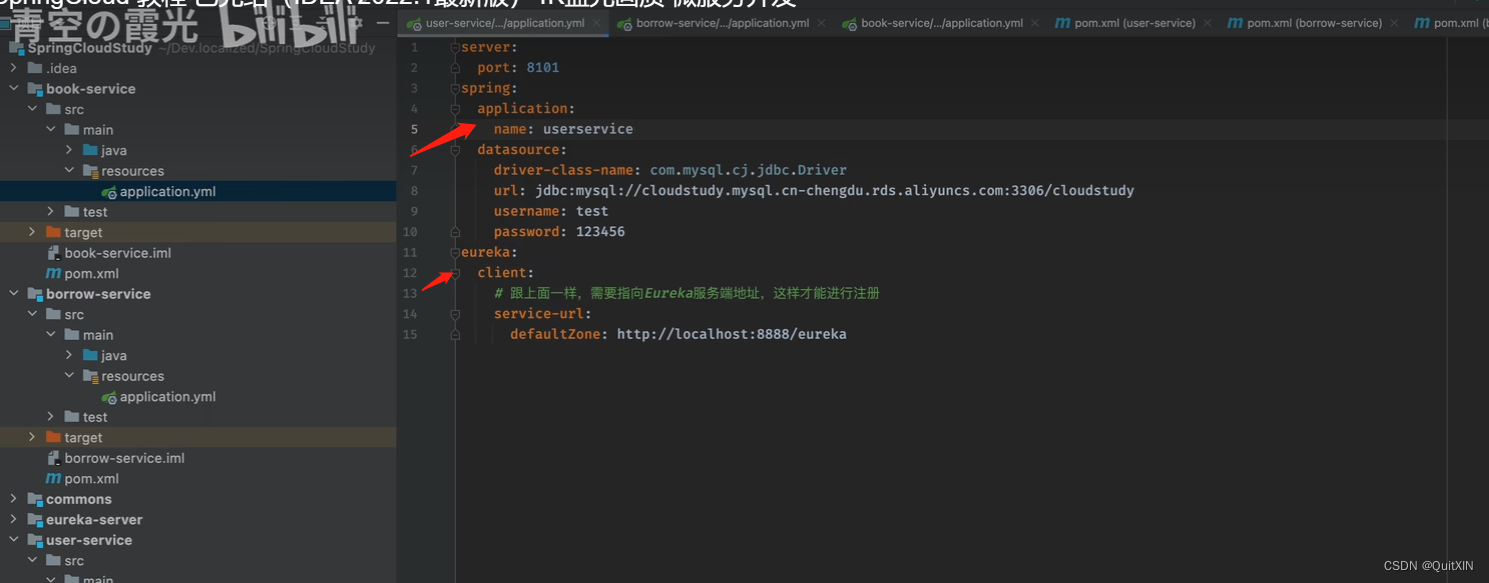

image-20230306225638109
当我们的服务启动之后,会每隔一段时间跟Eureka发送一次心跳包,这样Eureka就能够感知到我们的服务是否处于正常运行状态。
现在我们用同样的方法,将另外两个微服务也注册进来:

image-20230306225648063
那么,现在我们怎么实现服务发现呢?
也就是说,我们之前如果需要对其他微服务进行远程调用,那么就必须要知道其他服务的地址:
User user = template.getForObject("http://localhost:8082/user/"+uid, User.class);
复制代码而现在有了Eureka之后,我们可以直接向其进行查询,得到对应的微服务地址,这里直接将服务名称替换即可:
@Service
public class BorrowServiceImpl implements BorrowService {
@Resource
BorrowMapper mapper;
@Resource
RestTemplate template;
@Override
public UserBorrowDetail getUserBorrowDetailByUid(int uid) {
List<Borrow> borrow = mapper.getBorrowsByUid(uid);
//这里不用再写IP,直接写服务名称userservice
User user = template.getForObject("http://userservice/user/"+uid, User.class);
//这里不用再写IP,直接写服务名称bookservice
List<Book> bookList = borrow
.stream()
.map(b -> template.getForObject("http://bookservice/book/"+b.getBid(), Book.class))
.collect(Collectors.toList());
return new UserBorrowDetail(user, bookList);
}
}
复制代码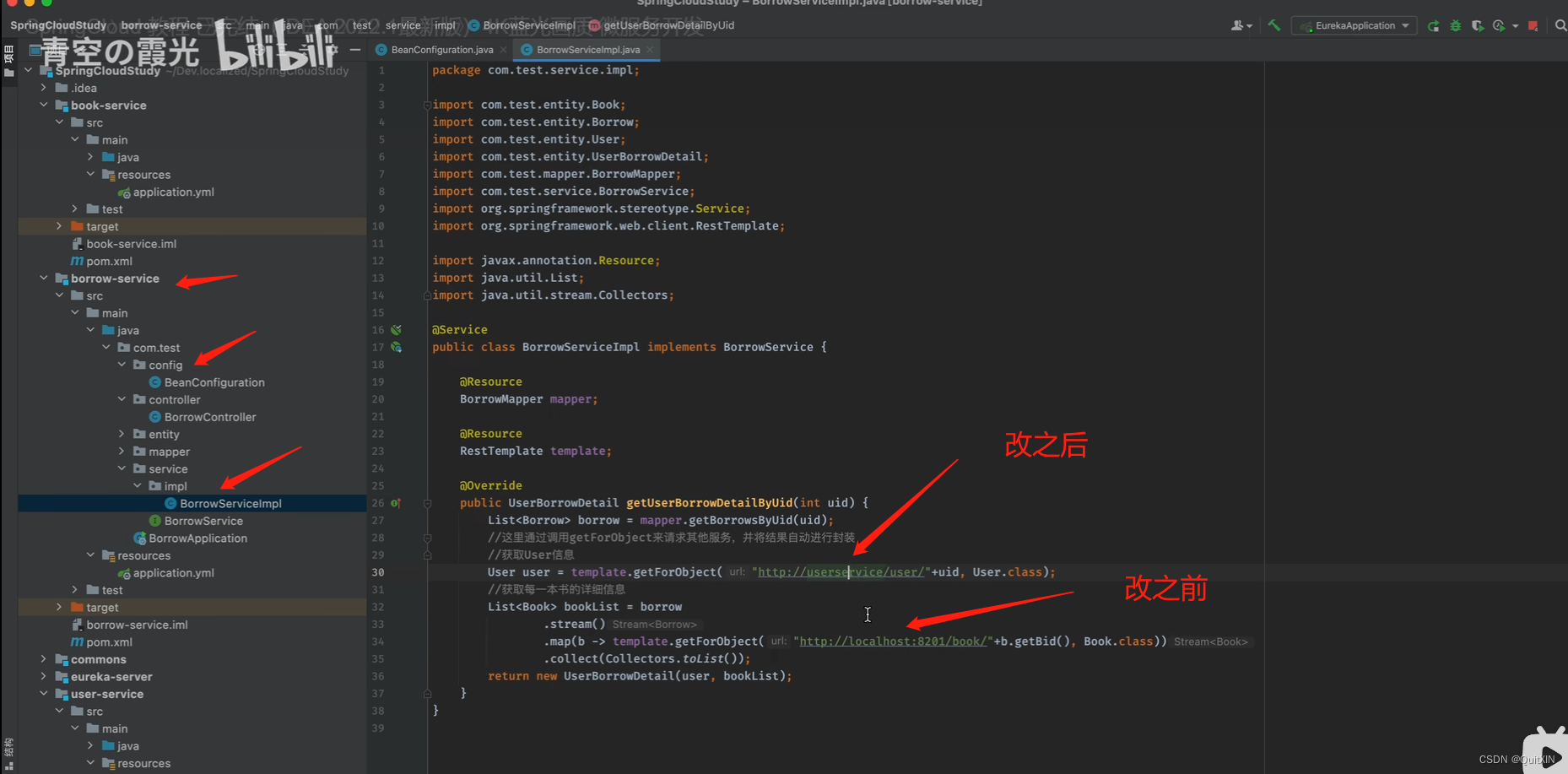
接着我们手动将RestTemplate声明为一个Bean,然后添加@LoadBalanced注解,这样Eureka就会对服务的调用进行自动发现,并提供负载均衡:
@Configuration
public class BeanConfig {
@Bean
@LoadBalanced
RestTemplate template(){
return new RestTemplate();
}
}
复制代码现在我们就可以正常调用了:

image-20230306225713484

![CodeForces..走路的男孩.[简单].[时间间隔]](https://img-blog.csdnimg.cn/bce3a017ce52454387bc53fa7f822a3f.png)