如标题所示,本文旨在记录这次分词实验,将主要从以下四点展开:
1、新闻文本的获取(完整爬虫过程)
爬取新闻网站中多个板块的新闻,这里建议可以多爬一些板块,保证新闻内容主题丰富,分词后有多样性。大致过程分三步,就是“手动(不累)获取含有新闻链接的网页源码—正则表达式提取新闻链接—爬虫逐个访问新闻链接获取新闻文本”。
如果你不想爬取新闻数据,可以直接用我的两个新闻文本,每个里边都有接近2000条新闻,中文字数在250-350万。下载链接:
链接:https://pan.baidu.com/s/18ZPBtQhPqbu-Tz2Sil5CIg?pwd=q6ms
提取码:q6ms
2、文本预处理
由于有的链接不含有新闻文本,爬取结果对应着空行,所以要对空行去除,并且对去空行后的新闻文本再做一次去重。
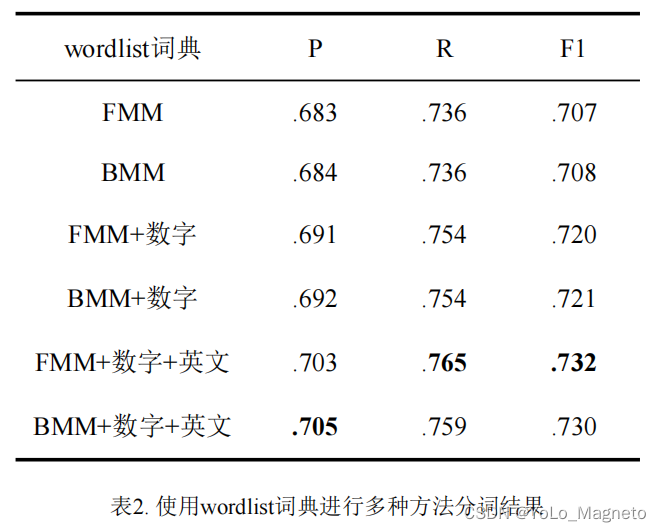
3、进行正向、逆向最大匹配算法进行分词,使用P、R、F1值进行分词评估(以jieba分词结果为基准)
正向最大匹配算法和逆向最大匹配算法原理很简单,网上找个例子就能看懂,这里不再赘述。由于目前分词的三种主流方式分别为基于规则的分词、基于统计的分词、基于深度学习的分词,而正向、逆向最大匹配算法属于基于规则的分词,比较老套,分词准确性极大地依赖给定的词典,本文共用到三个词典,下载链接:
链接:https://pan.baidu.com/s/1KrCzDpQbWg1WOZ2Lmv-pHA?pwd=1w90
提取码:1w90
P、R、F1值分别是准确率、召回率、F1指标值。
P准确率:分词后的文本中被正确分词的词语占所有分了词的词语的比例×100%。譬如我分了100个词,其中有80个词是正确的,那么正确率P就是80%。
R召回率:分词后的文本中被正确分词的词语占jieba分词(这里以jieba分词结果为正确分词结果)结果的比例×100%。譬如我分的词有100个,有70个词语正好可以和jieba分词的结果中对上,那么召回率就是70%。
F值:是一种P和R的综合考量,通常用F1值。F1值的计算公式就是2PR/P+R,在P、R尽可能大的情况下,F1值越接近1越好。
4、采用多种方式对分词结果进行优化并对比
新闻中会有很多数字日期,或者年份、号码、小数等等,也有掺杂着一些英语单词。由于我们的词典不可能把所有的数字和英语单词全部收录,只是一个中文词典。所以基于正向和逆向的最大匹配就不会把连续的数字和英文单词分开,大大降低分词准确性,如下面两个例子所示,分词结果以**为分隔符:
南都**讯**近日**,**一则**“**珠海**停车**3**1**小时**1**0**分钟**收费**6**4**0**元**”**的**1**2**秒**视频**引发**数千**人**转发**评论**
连续性**肾脏**替代**治疗**(**c**o**n**t**i**n**u**o**u**s** **r**e**n**a**l** **r**e**p**l**a**c**e**m**e**n**t** **t**h**e**r**a**p**y**,**C**R**R**T**)
相比jieba分词,数字和英语单词会被正确分词,所以我们的优化点将从连续的数字+连续的字母出发。
南**都**讯**近日**,**一则**“**珠海**停车**31**小时**10**分钟**收费**640**元**”**的**12**秒**视频**引发**数千**人**转发**评论**
连续性**肾脏**替代**治疗**(**continuous** **renal** **replacement** **therapy**,**CRRT**)
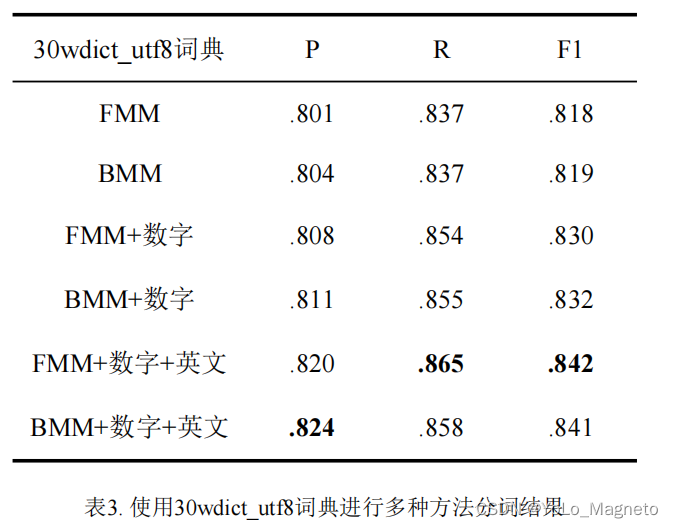
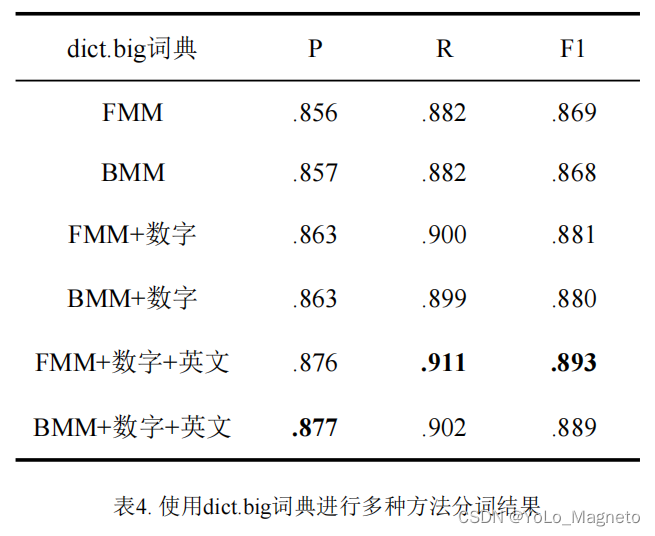
同时,更换更大的词典是提高分词准确率最直接有效的方式,所以我们会尝试两个规模更大的词典。
一、新闻文本获取
浏览新闻网站,页面如下所示,我们想要爬取红框中的新闻文本:

右键–检查–可以看到每个新闻对应的链接在右侧呈现,由于网页是动态加载,新闻链接也会随着页面的滚动而在右侧加载出来,这时候可以直接点一下鼠标滚轮实现快速翻页,这样可以快速滑动页面,更多的新闻链接也会加载出来。

首页的话可能翻一会儿就翻不动了,可以点击上边“财经”、“科技”、“娱乐”等板块故技重施,获取更多链接。待翻到底之后,收起下图红框部分,右键copy–copy element。

这时候打开我们的IDE,直接新建个txt文档,一股脑粘贴进去就行,如下图所示:
多去弄些这样的包含新闻链接的网页源码,粘贴进来就行,不用管是不是在一行,直接拉到最底下新一行粘贴进去,一会儿会用正则表达式对所有新闻链接进行抓取。
多选几个板块进行网页源代码的获取,这个过程就是自动翻滚页面,不断获得网页链接的过程。
接下来观察网页源码中新闻链接的形式(直接在网页中观察也行),如下图所示:
红框所示就是新闻链接的一般格式,接下来对“网页源码.txt”中的链接进行提取,代码如下:
"""从网页源码中提取出新闻链接,以便后续将链接内的新闻爬取"""
import re
# 打开原始文本文件和目标文本文件
with open('网页源码.txt', 'r', encoding='utf-8') as input_file, open('新闻链接.txt', 'a', encoding='utf-8') as output_file:
# 逐行读取原始文件
for line in input_file:
# 使用正则表达式提取链接
# links = re.findall(r'<a\s+href="(https?:\/\/new\.qq\.com\/rain\/a\/\w+)".*?>', line)
links = re.findall(r'<a\s+href="(https?:\/\/new\.qq\.com\/rain\/a\/\w+|https?:\/\/new\.qq\.com\/omn\/\d{8}\/\w+\.html)".*?>', line)
# 如果这一行包含符合要求的链接,则将所有链接合成一个字符串,并写入输出文件中
if links:
for link in links:
output_file.write(link + '\n')
这段代码会自动从“网页源码.txt”中利用正则表达式进行新闻链接的提取,并保存到一个新的txt文件中,名为“新闻链接.txt”。
提取过程非常的迅速,一瞬间就提取出3677条新闻链接。
接下来对链接进行去重,去掉重复链接,代码如下:
"""上一步提取出的新闻链接有少许重复,需要对新闻链接进行去重"""
def remove_duplicates(path):
with open(path, 'r', encoding = 'utf-8') as f:
lines = f.readlines()
unique_lines = set(lines)
with open(path, 'w', encoding = 'utf-8') as f:
f.writelines(list(unique_lines))
remove_duplicates("新闻链接.txt")
OK,去掉重复新闻链接250条左右。
接下来用爬虫代码逐个访问新闻链接,并将其中的新闻内容爬取下来,代码如下(注意,这里如果科学上网的话应该会报错,需要关掉。然后可能会受到反爬反制,我这里用了校园网,并没有被反爬限制,当然也需要随机sleep0-1秒,不然也会被封):
import requests
import urllib3
from bs4 import BeautifulSoup
import random
import time
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Referer': 'https://www.baidu.com/'
}
# 关闭 SSL 验证
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 打开新闻链接文件,并读取其中的每一行链接
with open('新闻链接.txt', 'r', encoding='utf-8') as f:
urls = f.readlines()
# 循环遍历每一个链接
for url in urls:
# 随机延时 0~1 秒
time.sleep(random.random())
# 发送 GET 请求并获取网页内容
response = requests.get(url.strip(), headers=headers, verify=False, timeout=10)
html = response.content
# 使用 Beautiful Soup 解析 HTML 内容
soup = BeautifulSoup(html, 'html.parser')
content_div = soup.find('div', attrs={'class': 'content-article'})
if content_div:
# 提取新闻正文中的所有段落
paragraphs = content_div.find_all('p', attrs={'class': 'one-p'})
# 处理每个段落,提取其中的文本内容并写入文件
with open('TX新闻.txt', 'a', encoding='utf-8') as f:
text_lines = []
for p in paragraphs:
text = p.text.strip()
if text.startswith('(来源:'):
break
text_lines.append(text)
# 每次爬取的多行内容整合到一起写在txt文本的一行中
text_to_write = ' '.join(text_lines)
f.write(text_to_write + '\n')
爬取新闻文本的时间可能较长,这里我先贴出来爬取文本后的大概内容:

能看到这里3412-3414行全是空白的,这样的是因为这几个链接进去之后要么是纯视频要么是纯图片,新闻网页中没有文字,所以就不会获得到新闻文本。
二、文本预处理
这步比较简单,由于我们在上边的爬虫代码最后两行中对爬取到的文本格式做了点小要求,所以一行就是一个链接的新闻。但是由于有的链接不含有新闻文本,爬取结果对应着空行,所以要对空行去除,并且对去空行后的新闻文本再做一次去重。代码如下,原始文本是含有空行的“TX新闻.txt”,这里我们新建一个“TX新闻V1.txt”,原始的“TX新闻.txt”当做备份,在“TX新闻V1.txt”中进行接下来去空行并去重的操作:
"""因为有的新闻链接是纯视频,这会导致提取不到新闻文本,所以会有空行,下面对空行进行去除"""
# 打开文件进行读写
with open('TX新闻v1.txt', 'r+', encoding = 'utf-8') as file:
# 读取文件内容并以每一行为单位进行处理
lines = file.readlines()
file.seek(0)
file.truncate()
for line in lines:
# 如果该行不是空白行,则将其写入新文件中
if line.strip():
file.write(line)
"""对重复新闻进行去重"""
def remove_duplicates(path):
with open(path, 'r', encoding = 'utf-8') as f:
lines = f.readlines()
unique_lines = set(lines)
with open(path, 'w', encoding = 'utf-8') as f:
f.writelines(list(unique_lines))
remove_duplicates("TX新闻v1.txt")
三、使用正向、逆向最大匹配算法进行分词并使用P、R、F1值进行分词准确率的评估
首先,3423条新闻链接的新闻文本已经被我们全部获取到了,如下图所示:
这里边不乏许多空行,用上一节文本预处理中的方法进行去空行和去重复新闻的操作。
可以看到新闻文本提取了2022篇。
接下来进行实验,实验代码如下所示:
import jieba
import time
import re
# 正向最大匹配算法
# def forward_max_match(text, max_word_len, dic):
# result = []
# index = 0
# text_len = len(text)
# while index < text_len:
# matched = False
# for word_len in range(max_word_len, 0, -1):
# word = text[index:index + word_len]
# if word in dic:
# result.append(word)
# index += word_len
# matched = True
# break
# if not matched:
# result.append(text[index])
# index += 1
# return result
# # 逆向最大匹配算法
# def backward_max_match(text, max_word_len, dic):
# result = []
# index = len(text)
# while index > 0:
# matched = False
# for word_len in range(max_word_len, 0, -1):
# word = text[index - word_len:index]
# if word in dic:
# result.append(word)
# index -= word_len
# matched = True
# break
# if not matched:
# result.append(text[index - 1])
# index -= 1
# return result[::-1]
# 改进正向最大匹配算法,连续数字不进行拆分
# def forward_max_match(text, max_word_len, dic):
# result = []
# index = 0
# text_len = len(text)
# while index < text_len:
# # 连续数字判断
# if text[index].isdigit():
# num_end = index + 1
# while num_end < text_len and text[num_end].isdigit():
# num_end += 1
# result.append(text[index:num_end])
# index = num_end
# continue
# matched = False
# for word_len in range(max_word_len, 0, -1):
# word = text[index:index + word_len]
# if word in dic:
# result.append(word)
# index += word_len
# matched = True
# break
# if not matched:
# result.append(text[index])
# index += 1
# return result
# # 改进逆向最大匹配算法,连续数字不进行拆分
# def backward_max_match(text, max_word_len, dic):
# result = []
# index = len(text)
# while index > 0:
# # 连续数字判断
# if text[index - 1].isdigit():
# num_start = index - 1
# while num_start > 0 and text[num_start - 1].isdigit():
# num_start -= 1
# result.append(text[num_start:index])
# index = num_start
# continue
# matched = False
# for word_len in range(max_word_len, 0, -1):
# word = text[index - word_len:index]
# if word in dic:
# result.append(word)
# index -= word_len
# matched = True
# break
# if not matched:
# result.append(text[index - 1])
# index -= 1
# return result[::-1]
# 连续英文正则表达式
eng_pattern = re.compile(r'[a-zA-Z]+')
# 继续改进FMM和BMM,使得对于连续的英文字母,也不再进行拆分
def forward_max_match(text, max_word_len, dic):
result = []
index = 0
text_len = len(text)
while index < text_len:
# 连续数字判断
if text[index].isdigit():
num_end = index + 1
while num_end < text_len and text[num_end].isdigit():
num_end += 1
result.append(text[index:num_end])
index = num_end
continue
# 连续英文判断
eng_match = eng_pattern.match(text[index:])
if eng_match and (index == 0 or not text[index-1].isalnum()):
eng_word = eng_match.group()
result.append(eng_word)
index += len(eng_word)
continue
matched = False
for word_len in range(max_word_len, 0, -1):
word = text[index:index + word_len]
if word in dic:
result.append(word)
index += word_len
matched = True
break
if not matched:
result.append(text[index])
index += 1
return result
def backward_max_match(text, max_word_len, dic):
result = []
index = len(text)
while index > 0:
# 判断当前字符是中文、数字还是英文
is_chinese = False
is_english = False
is_digit = False
for char in text[index - 1]:
if u'\u4e00' <= char <= u'\u9fff':
is_chinese = True
elif u'\u0041' <= char <= u'\u005a' or u'\u0061' <= char <= u'\u007a':
is_english = True
elif char.isdigit():
is_digit = True
if is_chinese: # 处理中文字符
matched = False
for word_len in range(max_word_len, 0, -1):
word = text[index - word_len:index]
if word in dic:
result.append(word)
index -= word_len
matched = True
break
if not matched:
result.append(text[index - 1])
index -= 1
elif is_english: # 处理英文字符
alpha_start = index - 1
while alpha_start > 0 and any(char.isalpha() for char in text[alpha_start - 1]):
alpha_start -= 1
result.append(text[alpha_start:index])
index = alpha_start
elif is_digit: # 处理数字字符
num_start = index - 1
while num_start > 0 and text[num_start - 1].isdigit():
num_start -= 1
result.append(text[num_start:index])
index = num_start
else: # 处理其他字符(如标点符号)
result.append(text[index - 1])
index -= 1
return result[::-1]
# 计算准确率、召回率和F1值
def evaluate(golden, predict):
golden_set = set(golden)
predict_set = set(predict)
correct = len(golden_set & predict_set)
precision = correct / len(predict_set)
recall = correct / len(golden_set)
f1 = 2 * precision * recall / (precision + recall)
return precision, recall, f1
"""加载其他词典dict.big.txt"""
def load_dict(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
dic = set(line.strip().split()[0] for line in f)
return dic
"""加载给定的词典wordlist.Dic"""
# def load_dict(file_path):
# with open(file_path, 'r', encoding='gbk') as f:
# dic = set(line.strip().split()[1] for line in f if len(line.strip()) > 0 and not line.startswith('#'))
# return dic
"""加载其他词典30wdict_utf8.txt"""
# def load_dict(file_path):
# with open(file_path, 'r', encoding='utf-8') as f:
# dic = set(line.strip() for line in f)
# return dic
# 加载并处理待分词文本
def load_data(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
data = f.read().splitlines()
return data
# 主函数
def main():
# 加载词典
dic = load_dict('dict.big.txt')
max_word_len = max(len(word) for word in dic)
# 加载待分词文本
texts = load_data('TX新闻V1.txt')
# 测试正向最大匹配和逆向最大匹配
forward_time = 0
backward_time = 0
jieba_time = 0
forward_precision, forward_recall, forward_f1 = 0, 0, 0
backward_precision, backward_recall, backward_f1 = 0, 0, 0
forward_file = open("dict.big-FMM-数字+英文.txt", "w", encoding='utf-8')
backward_file = open("dict.big-BMM-数字+英文.txt", "w", encoding='utf-8')
jieba_file = open("jieba分词结果.txt", "w", encoding='utf-8')
for text in texts:
# 使用jieba分词
start = time.time()
golden = list(jieba.cut(text))
end = time.time()
jieba_time += (end - start)
# 正向最大匹配
start = time.time()
forward_result = forward_max_match(text, max_word_len, dic)
end = time.time()
forward_time += (end - start)
# 逆向最大匹配
start = time.time()
backward_result = backward_max_match(text, max_word_len, dic)
end = time.time()
backward_time += (end - start)
# 将结果写入文件,以"**"作为分隔符
forward_file.write("**".join(forward_result) + "\n")
backward_file.write("**".join(backward_result) + "\n")
# 将jieba分词结果写入文件
jieba_file.write("**".join(golden) + "\n")
# 计算准确率、召回率和F1值
p, r, f = evaluate(golden, forward_result)
forward_precision += p
forward_recall += r
forward_f1 += f
p, r, f = evaluate(golden, backward_result)
backward_precision += p
backward_recall += r
backward_f1 += f
# 计算平均值
forward_precision /= len(texts)
forward_recall /= len(texts)
forward_f1 /= len(texts)
backward_precision /= len(texts)
backward_recall /= len(texts)
backward_f1 /= len(texts)
# 关闭文件
forward_file.close()
backward_file.close()
jieba_file.close()
# 输出结果
print("Forward Max Match:")
print(f" Time: {forward_time:.4f} s")
print(f" Precision: {forward_precision:.4f}")
print(f" Recall: {forward_recall:.4f}")
print(f" F1 score: {forward_f1:.4f}")
print("Backward Max Match:")
print(f" Time: {backward_time:.4f} s")
print(f" Precision: {backward_precision:.4f}")
print(f" Recall: {backward_recall:.4f}")
print(f" F1 score: {backward_f1:.4f}")
print("Jieba:")
print(f" Time: {jieba_time:.4f} s")
if __name__ == "__main__":
main()
在上述代码中,请认真看,三组正向、逆向最大匹配算法分别为无优化、将连续数字作为整体、将连续数字和连续英文字母都作为整体,也就是说,这三组算法是逐渐变优的。
另外,对应着三个词典,这三个词典都是网络获取的,在这里感谢词典的创作者们。
每次在进行实验时,你应该选择一个词典(注释掉另外两个词典的读取方式,由于词典的样式不同,设计了不同的读取方式),再选择一组正向、逆向最大匹配算法(注释掉另外两组共四个函数),然后运行代码,会自动保存分词结果,**你可以在代码中设置分词分隔符,并且自行在代码中更改保存的文件名,**同时,jieba分词的结果也会被保存下来,供参考。
四、分词P、R、F1结果与优化及对比
运行结果如下图所示,会展示出FMM、BMM的分词P、R、F1值以及运行时间。
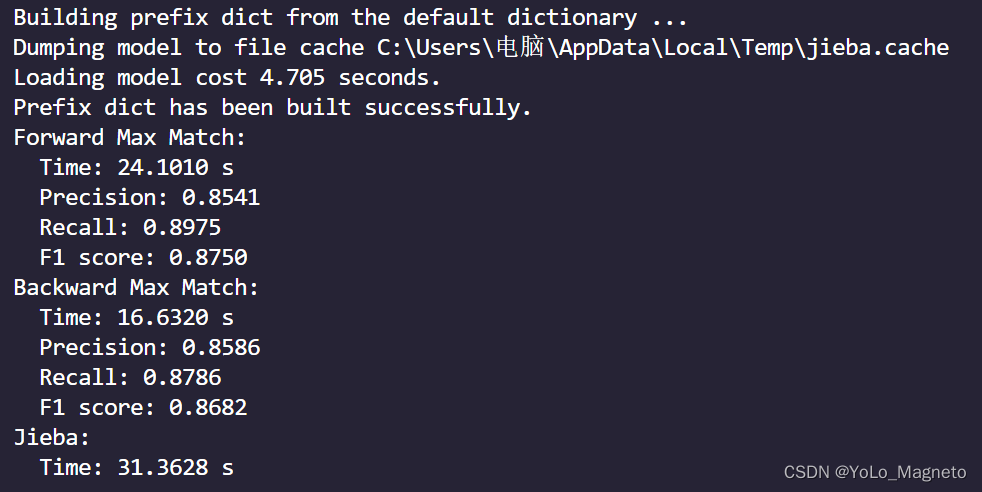
同时我们还可以看一下我们所选的一组分词方式和所用词典与jieba分词的差异,对比之后,可以考虑从其他方面进行优化,本文没有继续更深一步优化,读者可以考虑其他方面的优化(例如,jieba分词的所有词语,如果不存在于我们的词典,那么就将其加入到我们的词典中,有点抄答案的意思,但是确实是优化方案之一)
浅浅对比一下三个文件的分词效果,就随便拿其中一篇文章作对比,分隔符为“<>”,jieba的分词效果一定是这里边最好的。
dict.big-FMM-数字+英文优化:
IT<>之家<> <>6<> <>月<> <>2<> <>日<>消息<>,<>MONTECH<> <>在<> <>2023<> <>台北<>国际<>电脑<>展<>上推<>出<>了<>新款<> <>ATX<> <>3<>.<>0<> <>电源<>和<>散热器<>。<> <>新款<>电源<>为<> <>TITAN<> <>PLA<> <>系列<>,<>功率<>有<> <>750<>W<>、<>850<>W<>、<>1000<>W<> <>和<> <>1200<>W<> <>可选<>,<>支持<> <>ATX<> <>3<>.<>0<> <>和<> <>PCIe<> <>Gen<> <>5<>.<>0<>(<>12<>+<>4<> <>pin<> <>12<>V<> <>HPWR<> <>供电<>接口<>)<>;<>通过<>了<> <>80<> <>Plus<> <>和<> <>Cybernetics<> <>白金<>认证<>。<> <> <>▲<> <>图<>源<> <>techpowerup<>,<>下同<> <> <>电源<>内置<>超<>柔性<>铜合金<>连接器<>,<>增强<>了<>电源<>强度<>和<>导电性<>;<>内部<>带有<> <>1<> <>个<> <>135<>m<>m<> <>的<> <>FDB<> <>风扇<>,<>在<>低<>负载<>条件<>下<>以<>零<>转速<>运行<>。<> <> <> <> <>MONTECH<> <>还<>推出<>了<> <>Metal<> <>DT<>27<> <>和<> <>ST<>12<> <>CPU<> <>散热器<>,<>分别<>为<> <>300<> <>W<> <>TDP<> <>和<> <>230<> <>W<> <>TDP<>;<>支持<> <>LGA<> <>115<>x<> <>/<> <>1200<> <>/<> <>1700<> <>和<> <>AMD<> <>AM<>4<> <>/<> <>AM<>5<> <>接口<>,<>配备<>了<>用于<> <>ST<>12<> <>的<> <>METAL<> <>120<> <>PWM<> <>120<>m<>m<> <>风扇<>和<>用于<> <>ST<>27<> <>的<>两个<>高性能<> <>METAL<> <>Pro<> <>12<> <>风扇<>。
dict.big-BMM-数字+英文优化:
IT<>之家<> <>6<> <>月<> <>2<> <>日<>消息<>,<>MONTECH<> <>在<> <>2023<> <>台北<>国际<>电脑<>展<>上<>推出<>了<>新款<> <>ATX<> <>3<>.<>0<> <>电源<>和<>散热器<>。<> <>新款<>电源<>为<> <>TITAN<> <>PLA<> <>系列<>,<>功率<>有<> <>750<>W<>、<>850<>W<>、<>1000<>W<> <>和<> <>1200<>W<> <>可选<>,<>支持<> <>ATX<> <>3<>.<>0<> <>和<> <>PCIe<> <>Gen<> <>5<>.<>0<>(<>12<>+<>4<> <>pin<> <>12<>V<> <>HPWR<> <>供电<>接口<>)<>;<>通过<>了<> <>80<> <>Plus<> <>和<> <>Cybernetics<> <>白金<>认证<>。<> <> <>▲<> <>图<>源<> <>techpowerup<>,<>下同<> <> <>电源<>内置<>超<>柔性<>铜合金<>连接器<>,<>增强<>了<>电源<>强度<>和<>导电性<>;<>内部<>带有<> <>1<> <>个<> <>135<>mm<> <>的<> <>FDB<> <>风扇<>,<>在<>低<>负载<>条件<>下<>以<>零<>转速<>运行<>。<> <> <> <> <>MONTECH<> <>还<>推出<>了<> <>Metal<> <>DT<>27<> <>和<> <>ST<>12<> <>CPU<> <>散热器<>,<>分别<>为<> <>300<> <>W<> <>TDP<> <>和<> <>230<> <>W<> <>TDP<>;<>支持<> <>LGA<> <>115<>x<> <>/<> <>1200<> <>/<> <>1700<> <>和<> <>AMD<> <>AM<>4<> <>/<> <>AM<>5<> <>接口<>,<>配备<>了<>用于<> <>ST<>12<> <>的<> <>METAL<> <>120<> <>PWM<> <>120<>mm<> <>风扇<>和<>用于<> <>ST<>27<> <>的<>两个<>高性能<> <>METAL<> <>Pro<> <>12<> <>风扇<>。
jieba分词结果:
IT<>之家<> <>6<> <>月<> <>2<> <>日<>消息<>,<>MONTECH<> <>在<> <>2023<> <>台北<>国际<>电脑<>展上<>推出<>了<>新款<> <>ATX<> <>3.0<> <>电源<>和<>散热器<>。<> <>新款<>电源<>为<> <>TITAN<> <>PLA<> <>系列<>,<>功率<>有<> <>750W<>、<>850W<>、<>1000W<> <>和<> <>1200W<> <>可<>选<>,<>支持<> <>ATX<> <>3.0<> <>和<> <>PCIe<> <>Gen<> <>5.0<>(<>12<>+<>4<> <>pin<> <>12V<> <>HPWR<> <>供电<>接口<>)<>;<>通过<>了<> <>80<> <>Plus<> <>和<> <>Cybernetics<> <>白金<>认证<>。<> <> <>▲<> <>图源<> <>techpowerup<>,<>下同<> <> <>电源<>内置<>超<>柔性<>铜合金<>连接器<>,<>增强<>了<>电源<>强度<>和<>导电性<>;<>内部<>带有<> <>1<> <>个<> <>135mm<> <>的<> <>FDB<> <>风扇<>,<>在<>低<>负载<>条件<>下以<>零<>转速<>运行<>。<> <> <> <> <>MONTECH<> <>还<>推出<>了<> <>Metal<> <>DT27<> <>和<> <>ST12<> <>CPU<> <>散热器<>,<>分别<>为<> <>300<> <>W<> <>TDP<> <>和<> <>230<> <>W<> <>TDP<>;<>支持<> <>LGA<> <>115x<> <>/<> <>1200<> <>/<> <>1700<> <>和<> <>AMD<> <>AM4<> <>/<> <>AM5<> <>接口<>,<>配备<>了<>用于<> <>ST12<> <>的<> <>METAL<> <>120<> <>PWM<> <>120mm<> <>风扇<>和<>用于<> <>ST27<> <>的<>两个<>高性能<> <>METAL<> <>Pro<> <>12<> <>风扇<>。
三组算法×三个词典×两个(正向、逆向)算法=18个文件
jieba分词后1个文件
贴一下三个词典的规模对比:

附三个字典对应的三组方法P、R、F1值对比(仅供参考):
第一次写这么长的实验记录,点个赞和收藏支持一下吧~