一、API 设计原则
将 REST 映射到 DDD 模式
实体、聚合和值对象等模式旨在对领域模型中的对象施加特定的约束。 在 DDD 的许多介绍文章中,模式是使用构造函数或属性 getter 和 setter 等面向对象的 (OO) 语言概念建模的。
设计 API 时,请考虑这些 API 如何表达领域模型。不仅要考虑到模型中的数据,而且还要考虑业务运营以及对数据的约束。
| DDD 概念 | REST 等效项 | 示例 |
|---|---|---|
| 聚合 | 资源 | { “1”:1234, “status”:“pending”… } |
| 标识 | URL | https://delivery-service/deliveries/1 |
| 子实体 | 链接 | { “href”: “/deliveries/1/confirmation” } |
| 更新值对象 | PUT 或 PATCH | PUT https://delivery-service/deliveries/1/dropoff |
| 存储库 | 集合 | https://delivery-service/deliveries?status=pending |
API 版本控制
API 是服务与客户端之间的协定,或该服务的使用者。 如果某个 API 发生更改,依赖于该 API 的客户端存在中断的风险,不管是外部客户端还是其他微服务。 因此,最好是尽量减少对 API 的更改次数。 通常,基础实现中发生更改并不需要对 API 进行任何更改。 但实际上,在某个时候,我们需要添加新功能,这就需要更改现有的 API。
请尽量使 API 更改可向后兼容。 例如,避免从模型中删除字段,因为这可能会中断预期需要该字段的客户端。 添加字段不会破坏兼容性,因为客户端应该忽略响应中它们无法识别的任何字段。 但是,服务必须应对旧式客户端在请求中省略新字段的情况。
支持 API 协定中的版本控制。 如果做了重大的 API 更改,请推出新的 API 版本。 继续支持以前的版本,并让客户端选择要调用哪个版本。 可通过多种方法实现此目的。 一种简单的方法是在同一个服务中公开两个版本。 另一种方法是同时运行服务的两个版本,并根据 HTTP 路由规则,将请求路由到其中一个版本。
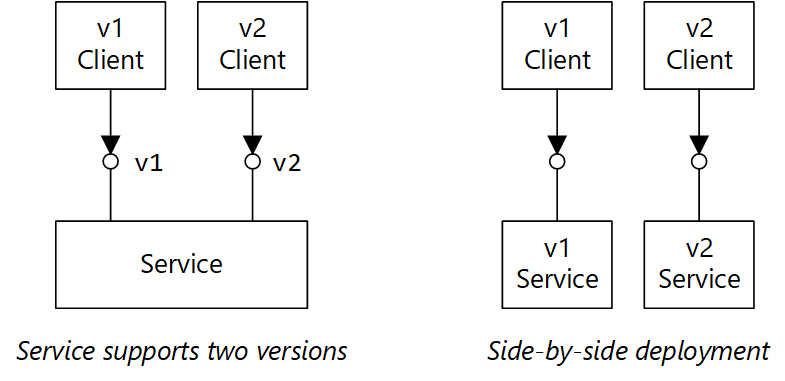
显示用于支持版本控制的两个选项的示意图。
此图包含两个部分。 “服务支持两个版本”显示 v1 客户端和 v2 客户端均指向一个服务。 “并行部署”显示 v1 客户端指向 v1 服务,而 v2 客户端指向 v2 服务。
支持多个版本会在开发人员时间、测试和运营开销方面产生成本。 因此,最好尽快淘汰旧版本。 对于内部 API,拥有该 API 的团队可与其他团队协作,帮助他们迁移到新版本。 此时,跨团队调控过程非常有用。 对于外部(公共)API,可能很难淘汰 API 版本,当 API 由第三方或本机客户端应用程序使用时尤其如此。
当服务实施更改时,使用版本来标记更改会很有用。 排查错误时,版本可提供重要信息。 执行根本原因分析时,版本可能十分有帮助,因为可以确切地知道调用了哪个服务版本。 考虑对服务版本使用语义版本控制。 语义版本控制使用 MAJOR.MINOR.PATCH 格式。 但是,客户端仅应根据主要版本号选择 API;如果次要版本之间发生重要(但非重大)的更改,则可以根据次要版本选择 API。 换而言之,客户端在 API 版本 1 与版本 2 之间做出选择是合理的做法,但不能选择版本 2.1.3。 如果允许这种粒度级,则可能存在必须为大量增生版本提供支持的风险。
幂等操作
如果某个操作可以调用多次,且在首次调用后不会产生其他副作用,则该操作是幂等的。 幂等性可以是一种有用的复原能力策略,因为它允许上游服务安全地多次调用某个操作。 有关这一点的讨论,请参阅分布式事务。
HTTP 规范中规定,GET、PUT 和 DELETE 方法必须是幂等的。 无法保证 POST 方法是幂等的。 如果 POST 方法创建新资源,则通常无法保证此操作是幂等的。 该规范对幂等的定义如下:
如果使用某个请求方法的多个相同请求对服务器造成的预期影响与单个此类请求所造成的影响相同,则认为该方法是“幂等的”。 (RFC 7231)
创建新实体时,必须了解 PUT 与 POST 语义之间的区别。 在这两种情况下,客户端都会在请求正文中发送实体的表示形式。 但 URI 的含义有所不同。
- 对于 POST 方法,URI 表示新实体的父资源,例如集合。 例如,若要创建新的交付项,URI 可能是 /api/deliveries。 服务器将创建实体并为其分配新 URI,例如 /api/deliveries/39660。 此 URI 将在响应的 Location 标头中返回。 每当客户端发送请求时,服务器都会创建一个具有新 URI 的新实体。
- 对于 PUT 方法,URI 标识实体。 如果已存在具有该 URI 的实体,则服务器会将现有实体替换为请求中的版本。 如果不存在具有该 URI 的实体,则服务器会创建一个实体。 例如,假设客户端向 api/deliveries/39660 发送了 PUT 请求。 此外,假设不存在具有该 URI 的交付项,则服务器会创建一个新的交付项。 现在,如果客户端再次发送相同的请求,则服务器会替换现有实体。
大多数请求预期会创建新实体,因此,该方法将对存储库对象乐观调用 CreateAsync,然后通过更新资源来处理任何重复资源异常。
二、谷歌健康API设计
Create a data source
This example demonstrates how to create a new data source named “MyDataSource” that provides step count increments.
HTTP method
POST
Request URL
https://www.googleapis.com/fitness/v1/users/me/dataSources
Request body
{
"dataStreamName": "MyDataSource",
"type": "derived",
"application": {
"detailsUrl": "http://example.com",
"name": "Foo Example App",
"version": "1"
},
"dataType": {
"field": [
{
"name": "steps",
"format": "integer"
}
],
"name": "com.google.step_count.delta"
},
"device": {
"manufacturer": "Example Manufacturer",
"model": "ExampleTablet",
"type": "tablet",
"uid": "1000001",
"version": "1.0"
}
}
Response
If the data source is created successfully, the response is a 200 OK status code. The response body contains a JSON representation of the data source, including a datasource.dataStreamId property that you can use as the data source ID for subsequent requests.
Curl command
$ curl --header "Authorization: Bearer ya29.yourtokenvalue" -X POST \
--header "Content-Type: application/json;encoding=utf-8" -d @createds.json \
"https://www.googleapis.com/fitness/v1/users/me/dataSources"
Get a particular data source
This example demonstrates how to retrieve the data source (“MyDataSource”) that you created in the previous example. When you create a new data source, the dataStreamId includes a unique identifier (shown as “1234567890” in these examples). This is your developer project number, and it will be the same for all requests made using that particular developer account. Be sure to use the dataStreamId from the data source you created.
HTTP method
GET
Request URL
https://www.googleapis.com/fitness/v1/users/me/dataSources/derived:com.google.step_count.delta:1234567890:Example%20Manufacturer:ExampleTablet:1000001:MyDataSource
Request body
None
Response
If the data source exists, the response is a 200 OK status code. The response body contains a JSON representation of the data source.
Curl command
$ curl --header "Authorization: Bearer ya29.yourtokenvalue" -X GET
--header "Content-Type: application/json;encoding=utf-8"
"https://www.googleapis.com/fitness/v1/users/me/dataSources/derived:com.google.step_count.delta:1234567890:Example%20Manufacturer:ExampleTablet:1000001:MyDataSource"
Get aggregated data
This example demonstrates how to query a specific data source for aggregated data, in this case estimated_steps, which is the data source used to show step count in the Google Fit app. Note that timestamps in the JSON request body are in milliseconds.
HTTP method
POST
Request URL
https://www.googleapis.com/fitness/v1/users/me/dataset:aggregate
Request body
{
"aggregateBy": [{
"dataSourceId":
"derived:com.google.step_count.delta:com.google.android.gms:estimated_steps"
}],
"bucketByTime": { "durationMillis": 86400000 },
"startTimeMillis": 1454284800000,
"endTimeMillis": 1455062400000
}
Response
If the data source(s) exist, the response is a 200 OK status code. The response body contains a JSON representation of the data source.
Curl command
$ curl --header "Authorization: Bearer ya29.yourtokenvalue" -X POST \
--header "Content-Type: application/json;encoding=utf-8" -d @aggregate.json \
"https://www.googleapis.com/fitness/v1/users/me/dataset:aggregate"
Update a data source
This example demonstrates how to update the name and device version for a data source.
HTTP method
PUT
Request URL
https://www.googleapis.com/fitness/v1/users/me/dataSources/derived:com.google.step_count.delta:1234567890:Example%20Manufacturer:ExampleTablet:1000001:MyDataSource
Request body
{
"dataStreamId": "derived:com.google.step_count.delta:1234567890:Example Manufacturer:ExampleTablet:1000001:MyDataSource",
"dataStreamName": "MyDataSource",
"type": "derived",
"application": {
"detailsUrl": "http://example.com",
"name": "Foo Example App",
"version": "1"
},
"dataType": {
"field": [
{
"name": "steps",
"format": "integer"
}
],
"name": "com.google.step_count.delta"
},
"device": {
"manufacturer": "Example Manufacturer",
"model": "ExampleTablet",
"type": "tablet",
"uid": "1000001",
"version": "2.0"
}
}
Response
If the data source is updated successfully, the response is a 200 OK status code. The response body contains a JSON representation of the data source.
Curl command
$ curl --header "Authorization: Bearer ya29.yourtokenvalue" -X PUT \
--header "Content-Type: application/json;encoding=utf-8" -d @updateds.json \
"https://www.googleapis.com/fitness/v1/users/me/dataSources/derived:com.google.step_count.delta:1234567890:Example%20Manufacturer:ExampleTablet:1000001:MyDataSource"
Delete a data source
This example demonstrates how to delete a data source.
HTTP method
DELETE
Request URL
https://www.googleapis.com/fitness/v1/users/me/dataSources/derived:com.google.step_count.delta:1234567890:Example%20Manufacturer:ExampleTablet:1000001:MyDataSource
Request body
None
Response
If the data source is deleted successfully, the response is a 200 OK status code. The response body contains a JSON representation of the data source that was deleted.
Curl command
$ curl --header "Authorization: Bearer ya29.yourtokenvalue" -X DELETE \
--header "Content-Type: application/json;encoding=utf-8" \
"https://www.googleapis.com/fitness/v1/users/me/dataSources/derived:com.google.step_count.delta:1234567890:Example%20Manufacturer:ExampleTablet:1000001:MyDataSource"
Was this helpful?
Add points to a dataset
This example demonstrates how to add ten new step count delta points to a previously empty dataset. This example assumes that you created a data source as described in Managing Data Sources.
HTTP method
PATCH
Request URL
https://www.googleapis.com/fitness/v1/users/me/dataSources/
derived:com.google.step_count.delta:1234567890:Example%20Manufacturer:ExampleTablet:1000001
/datasets/1397513334728708316-1397515179728708316
Request body
{
"dataSourceId":
"derived:com.google.step_count.delta:1234567890:Example Manufacturer:ExampleTablet:1000001",
"maxEndTimeNs": 1397515179728708316,
"minStartTimeNs": 1397513334728708316,
"point": [
{
"dataTypeName": "com.google.step_count.delta",
"endTimeNanos": 1397513365565713993,
"originDataSourceId": "",
"startTimeNanos": 1397513334728708316,
"value": [
{
"intVal": 8
}
]
},
{
"dataTypeName": "com.google.step_count.delta",
"endTimeNanos": 1397513675197854515,
"originDataSourceId": "",
"startTimeNanos": 1397513530098955298,
"value": [
{
"intVal": 3
}
]
},
{
"dataTypeName": "com.google.step_count.delta",
"endTimeNanos": 1397513764101240710,
"originDataSourceId": "",
"startTimeNanos": 1397513817073528237,
"value": [
{
"intVal": 6
}
]
},
{
"dataTypeName": "com.google.step_count.delta",
"endTimeNanos": 1397513938674093579,
"originDataSourceId": "",
"startTimeNanos": 1397514015761859752,
"value": [
{
"intVal": 5
}
]
},
{
"dataTypeName": "com.google.step_count.delta",
"endTimeNanos": 1397514106400006675,
"originDataSourceId": "",
"startTimeNanos": 1397514181893785805,
"value": [
{
"intVal": 4
}
]
},
{
"dataTypeName": "com.google.step_count.delta",
"endTimeNanos": 1397514304850163634,
"originDataSourceId": "",
"startTimeNanos": 1397514356883524220,
"value": [
{
"intVal": 16
}
]
},
{
"dataTypeName": "com.google.step_count.delta",
"endTimeNanos": 1397514518794639297,
"originDataSourceId": "",
"startTimeNanos": 1397514526864527756,
"value": [
{
"intVal": 13
}
]
},
{
"dataTypeName": "com.google.step_count.delta",
"endTimeNanos": 1397514741275742506,
"originDataSourceId": "",
"startTimeNanos": 1397514626480314270,
"value": [
{
"intVal": 18
}
]
},
{
"dataTypeName": "com.google.step_count.delta",
"endTimeNanos": 1397514813435152213,
"originDataSourceId": "",
"startTimeNanos": 1397514839292833196,
"value": [
{
"intVal": 17
}
]
},
{
"dataTypeName": "com.google.step_count.delta",
"endTimeNanos": 1397515179728708316,
"originDataSourceId": "",
"startTimeNanos": 1397515170565969137,
"value": [
{
"intVal": 11
}
]
}
]
}
Response
The response is a 200 OK status code. The response body contains an array with JSON representations of all the points that were inserted successfully.
Curl command
$ curl --header "Authorization: Bearer ya29.1.yourtokenvalue" -X PATCH \
--header "Content-Type: application/json;encoding=utf-8" -d @addpoints.json \
"https://www.googleapis.com/fitness/v1/users/me/dataSources/derived:com.google.step_count.delta:1234567890:Example%20Manufacturer:ExampleTablet:1000001/datasets/1397513334728708316-1397515179728708316"
Get a dataset
This example demonstrates how to get the contents of a dataset.
HTTP method
GET
Request URL
https://www.googleapis.com/fitness/v1/users/me/dataSources/
derived:com.google.step_count.delta:1234567890:Example%20Manufacturer:ExampleTablet:1000001
/datasets/1397513334728708316-1397515179728708316
Request body
None.
Response
If the dataset exists, the response is a 200 OK status code. The response body contains a JSON representation of the dataset.
Curl command
$ curl --header "Authorization: Bearer ya29.1.yourtokenvalue" -X GET \
--header "Content-Type: application/json;encoding=utf-8" \
"https://www.googleapis.com/fitness/v1/users/me/dataSources/derived:com.google.step_count.delta:1234567890:Example%20Manufacturer:ExampleTablet:1000001/datasets/1397513334728708316-1397515179728708316"
Insert a session
This example demonstrates how to insert a session.
HTTP method
PUT
Request URL
https://www.googleapis.com/fitness/v1/users/me/sessions/someSessionId
Request body
{
"id": "someSessionId",
"name": "My example workout",
"description": "A very intense workout",
"startTimeMillis": 1396710000000,
"endTimeMillis": 1396713600000,
"version": 1,
"lastModifiedToken": "exampleToken",
"application": {
"detailsUrl": "http://example.com",
"name": "Foo Example App",
"version": "1.0"
},
"activityType": 1
}
Response
The response is a 200 OK status code. The response body contains a JSON representation of the session.
Curl command
$ curl --header "Authorization: Bearer ya29.1.yourtokenvalue" -X PUT \
--header "Content-Type: application/json;encoding=utf-8" -d @createsession.json \
"https://www.googleapis.com/fitness/v1/users/me/sessions/someSessionId"
List existing sessions
This example demonstrates how to list existing sessions from April 2014.
HTTP method
GET
Request URL
https://www.googleapis.com/fitness/v1/users/me/sessions?startTime=2014-04-01T00:00:00.000Z&endTime=2014-04-30T23:59:59.999Z
Request body
None.
Response
The response is a 200 OK status code. The response body contains JSON representations of all existing sessions that match the start and end times provided in the query parameters.
Curl command
$ curl --header "Authorization: Bearer ya29.1.yourtokenvalue" -X GET \
--header "Content-Type: application/json;encoding=utf-8" \
"https://www.googleapis.com/fitness/v1/users/me/sessions?startTime=2014-04-01T00:00:00.000Z&endTime=2014-04-30T23:59:59.999Z"
三、谷歌API设计指南
面向资源的设计
传统的 RPC 接口设计面向的是操作,各个接口之间是孤立的,没有明确的关联;不同系统的接口也有着不同的设计风格,存在着一定的学习和使用成本。
而面向资源的设计则将系统抽象为一系列资源,开发者则通过有限的几个标准方法来操作资源,从而实现对系统的修改。对于 RESTful 接口来说,有限的几个标准方法对应的就是 HTTP 请求方法中的 POST,GET,PUT,PATCH 和 DELETE。另一方面,由于遵循了统一的设计,当开发者调用不同系统的接口时,能够自然的假定各个系统都支持相同的标准方法,从而降低了开发者学习的成本。
不管是面向资源的设计还是其他的设计标准,统一的标准胜过百花齐放,开发者应当将更多的精力放在自身系统的业务实现上,而不是耗费时间学习和调试其他系统的接口。
该指南建议按照如下的步骤设计面向资源的接口:
- 确定接口所提供的资源类型
- 确定资源间的关系
- 根据资源类型和资源间的关系确定资源命名模式
- 确定资源体系
- 为每个资源设计最小限度的操作方法
在面向资源的设计体系下,各接口一般会按照资源的层级结构进行组织,层级结构中的每个节点可能是单一的资源,也可能是一个资源集合:
- 一个资源集合包含了一系列相同类型的资源,例如,一个用户拥有一个联系人资源集合
- 一个资源包含了若干的状态,同时也包含了0个或者多个子资源。每个子资源可以是一个单一资源或者是资源集合
以创建邮件接口为例,传统的接口设计可能是如下的方式:
POST /createMail
{
"userId": 123,
"title:" "Title",
"from": "from@example.com"
"to": "to@example.com",
"body": "Body"
}
而面向资源的接口设计则可能为:
POST /users/{userId}/mails
{
"title:" "Title",
"from": "from@example.com"
"to": "to@example.com",
"body": "Body"
}
可以看到,面向资源的接口设计体现了资源间的层级关系。一般而言,对于 RESTful 接口来说,请求 URL 中只会包含资源的名称(名词),而不会包含对资源的操作(动词),HTTP 的请求方法就对应了资源的标准操作方法。而该指南讨论的是通用的面向资源的设计,其对应的资源标准操作方法为:List,Get,Create,Update 和 Delete。
资源名称
在面向资源的设计下,资源是一个命名实体,每个资源都有一个唯一的名称作为其标识符。一个资源的名称由三部分组成:
- 资源的 ID
- 所有父资源的 ID
- API 服务名,如 gmail.googleapis.com
资源集合被视为一种特殊的资源,它包含了一组相同类型的子资源,例如一个目录可以被视为一个资源集合,它包含了一组文件资源。同时,资源集合也有相应的 ID。
资源名称由资源 ID 和资源集合 ID 组成,其定义也体现了资源的层级结构关系,各层级之间使用 / 进行分隔。例如,对于某个对象存储服务中的对象来说,其资源名称可能为 //storage.googleapis.com/buckets/bucket-123/objects/object-123,其中最顶层为服务名,即 //storage.googleapis.com,然后是一个资源集合,即 buckets,对象存储服务一般以 bucket 为维度来管理对象;接下来为了要定位到某个对象,需要先定位到具体的 bucket,bucket-123 就是某个 bucket 的资源 ID,而每个 bucket 下包含了多个对象,进而产生了一个资源集合 objects,最后的 object-123 就是实际对象的资源 ID。
一般来说,一个资源在实现上很可能对应一张数据库的表,所以可以用表的主键来作为资源的 ID。而由于使用了 / 来分隔资源的层级,因此只有最底层的资源才允许资源 ID 中包含 /,从而避免层级歧义。
如果资源 ID 中包含了 /,则必须在 API 文档中明确声明。
资源集合更多的是一种层级上的逻辑概念,所以其 ID 命名需要有意义,以及符合以下的规范:
- 必须是以小驼峰形式命名的英文单词复数,如果对应单词没有复数,则应当使用单词的单数形式
- 必须使用简洁明了的英文单词
- 避免使用过于宽泛的英文单词,例如,rowValues 优于 values。同时应当避免无条件的使用如下的英文单词:
- elements
- entries
- instances
- items
- objects
- resources
- types
- values
对于 Google 的服务来说,资源集合 ID 还会经常出现在自动生成的客户端类库代码中,所以它们的命名也必须是合法的 C/C++ 标识符。
完整的资源名称是协议无关的,虽然它看起来像 RESTful 服务的 HTTP 接口请求路径,但本质上这是两个东西。实际的资源请求还需要附带版本号,协议等信息,例如对于资源名称 //calendar.googleapis.com/users/john smith/events/123 来说,实际的 RESTful 请求路径可能是 https://calendar.googleapis.com/v3/users/john%20smith/events/123,和原本的资源名称相比有三点不同:
- 指明了具体的协议,HTTPS
- 指明了版本号,v3
- 对资源名称进行了 URL 转义
Google 的 API 服务要求资源名称必须是字符串,除非有后向兼容的问题,资源名称在跨模块间传递时必须确保没有任何数据丢失。对于资源定义来说,第一个字段应该命名为 name,类型为字符串,用于表示资源的名称,以下是 gRPC 服务的定义示例:
// 图书馆服务
service LibraryService {
// 获取一本书
rpc GetBook(GetBookRequest) returns (Book) {
option (google.api.http) = {
get: "/v1/{name=shelves/*/books/*}"
};
};
// 创建一本书
rpc CreateBook(CreateBookRequest) returns (Book) {
option (google.api.http) = {
post: "/v1/{parent=shelves/*}/books"
body: "book"
};
};
}
// 资源定义
message Book {
// 资源名称,必须以 "shelves/*/books/*" 的形式。
// 例如,"shelves/shelf1/books/book2"。
string name = 1;
// ... 其他属性
}
// 获取书籍请求
message GetBookRequest {
// 资源名称,例如 "shelves/shelf1/books/book2"。
string name = 1;
}
// 创建书籍请求
message CreateBookRequest {
// 父资源的名称,例如 "shelves/shelf1"。
string parent = 1;
// 需要创建的资源实体,客户端不允许设置 `Book.name` 属性。
Book book = 2;
}
为什么这里资源的名称字段要定义为 name 而不是 id?首先从命名上来说 name 本身要比 id 更适合作为 名称 一词的命名。其次,name 也是一个较为宽泛的词语,例如文件资源的 name 代表的是文件的名称还是完整的路径?通过将 name 作为标准字段,使得开发人员必须要选择更适合的命名,例如 display_name,title 或者 full_name。
为什么不直接使用资源 ID 来定位资源?一个系统中往往有多个资源,单纯的资源 ID 不具有辨识度以及缺少上下文信息。例如,如果使用数据库表的自增主键作为资源 ID,则无法简单的通过数字来定位资源。如果想要通过资源 ID 来定位资源,则势必要扩展资源 ID 的定义,例如使用元组来表示资源 ID,如 (bucket, object) 用于定位某个对象存储服务的对象。不过,这也带来了几个问题:
- 对开发人员不友好,需要额外理解和记忆(例如不同资源 ID 的元组元素个数不同,每个元组元素代表的含义是什么)
- 解析元组比解析字符串更为困难
- 对基础设施组件不友好,例如日志和访问控制系统无法直接理解元组
- 限制了 API 设计的灵活性,如提供可复用的 API 接口
标准方法
标准方法的作用在于为大多数的服务场景提供统一、易用的接口,超过 70% 的 Google APIs 都是标准方法。Google APIs 设计了5种标准方法:
- List
- Get
- Create
- Update
- Delete
下表是标准方法和 HTTP 请求方法的映射:
| 标准方法 | HTTP 请求方法映射 | HTTP 请求体 | HTTP 响应体 |
|---|---|---|---|
| List | Get <资源集合 URL> | 无 | 资源集合 |
| Get | GET <资源 URL> | 无 | 资源 |
| Create | POST <资源集合 URL> | 资源 | 资源 |
| Update | PUT 或者 PATCH <资源 URL> | 资源 | 资源 |
| Delete | DELETE <资源 URL> | 无 | 空 |
HTTP 响应体返回的资源可能不会包含资源的全部字段,例如客户端请求时可以指定只返回需要的字段。 如果 Delete 操作不是立即删除资源,例如只是更新资源的某个字段标记删除或者是创建一个 长时间运行任务 来删除资源,则 HTTP 响应体应该包含修改后的资源或者任务信息。
List
List 方法用于返回一系列同类的资源,同时该接口支持额外的参数从而允许只返回匹配的资源。它适合用于获取有限大小、未缓存的单一资源集合,对于更复杂的场景则可以考虑使用自定义方法中的 Search 接口。
如果想要批量获取资源,例如入参一组资源 ID 来返回每个资源 ID 所对应的资源,则应该考虑实现 BatchGet 的自定义方法,而不是在 List 方法上扩展。
List 方法和 HTTP 请求的映射关系如下:
- List 方法必须对应 HTTP 的 GET 请求
- List 方法的 RPC 请求消息体的 name 字段(也就是资源集合名称)应该和 HTTP 的请求路径匹配,如果相匹配,则 HTTP 请求路径的最后一个段必须是字面量(即资源集合 ID)
- List 方法的 RPC 请求消息体的其他字段应该和 HTTP 请求路径的查询参数相匹配
- 对应的 HTTP 请求无请求体;List 方法的 API 定义中不允许声明 body 语句
- HTTP 响应体应该包含一组资源及可选的元数据信息
接口定义示例:
// 获取书架上的书
rpc ListBooks(ListBooksRequest) returns (ListBooksResponse) {
// List 方法映射为 HTTP GET 请求
option (google.api.http) = {
// parent 对应父资源的名称,如 shelves/shelf1
get: "/v1/{parent=shelves/*}/books"
};
}
// 获取书籍集合请求
message ListBooksRequest {
// 父资源的名称,如shelves/shelf1
string parent = 1;
// 返回资源的最大个数
int32 page_size = 2;
// 返回第几页的资源集合,其值为前一个 List 请求返回的 next_page_token 字段
string page_token = 3;
}
// 获取书籍集合响应
message ListBooksResponse {
// 返回的书籍资源集合,该字段名应该和方法名中的 Books 相匹配。其数量上限由 ListBooksRequest 中的 page_size 决定
repeated Book books = 1;
// 下一页资源集合的页码信息,用于获取下一页的资源集合;没有下一页时为空
string next_page_token = 2;
}
Get
Get 方法接收一个资源名称及其他参数来返回某个指定的资源。
Get 方法和 HTTP 请求的映射关系如下:
- Get 方法必须对应 HTTP 的 GET 请求
- Get 方法的 RPC 请求消息体的 name 字段(也就是资源名称)应该和 HTTP 的请求路径匹配
- Get 方法的 RPC 请求消息体的其他字段应该和 HTTP 请求路径的查询参数相匹配
- 对应的 HTTP 请求无请求体;Get 方法的 API 定义中不允许声明 body 语句
- Get 方法返回的资源实体应该和 HTTP 的整个响应体相匹配
接口定义示例:
// 获取一本书
rpc GetBook(GetBookRequest) returns (Book) {
// Get 方法映射为 HTTP GET 请求,资源名称映射到请求路径,无请求体
option (google.api.http) = {
// 所请求的资源名称,如 shelves/shelf1/books/book2
get: "/v1/{name=shelves/*/books/*}"
};
}
// 获取单个书籍请求
message GetBookRequest {
// 所请求的资源名称,如 shelves/shelf1/books/book2
string name = 1;
}
Create
Create 方法接收一个父资源名称,一个资源实体,以及其他的参数来在指定的父资源下创建一个新的资源,并返回创建的资源。
如果某个 API 服务支持创建资源,则应当为每一类的资源创建对应的 Create 方法。
Create 方法和 HTTP 请求的映射关系如下:
- Create 方法必须对应 HTTP 的 POST 请求
- Create 方法的 RPC 请求消息体应当包含一个 parent 字段用于表示所创建的资源的父资源的名称
- Create 方法的 RPC 请求消息体中表示资源实体的各字段应当和 HTTP 请求体中的字段相对应。如果 Create 方法定义中标注了 google.api.http,则必须声明 body: “<resource_field>” 语句
- Create 方法的 RPC 请求消息体可能包含一个 _id 字段来允许调用方指定所创建的资源的 id。这个字段可能会包含在资源字段实体内
- Create 方法的其余参数应当和 URL 的查询参数相匹配
- Create 方法返回的资源实体应该和 HTTP 的整个响应体相匹配
如果 Create 方法允许由调用方指定所创建的资源的名称,并且该资源已经存在,则该请求应当作失败处理并返回错误码 ALREADY_EXISTS;或者由服务端重新生成一个资源名称,并返回创建的资源,同时接口文档应当清晰的标注最终创建的资源的名称有可能和调用方传入的资源名称不同。
Create 方法的 RPC 请求消息体中必须包含资源实体,这样当资源实体的定义发生变更时,就无需同时变更请求消息体的定义。如果资源实体中的某些字段无法由客户端设置,则必须将其标注为 Output only 字段。
接口定义示例:
// 在书架上创建一本书
rpc CreateBook(CreateBookRequest) returns (Book) {
// Create 方法对应 HTTP 的 POST 请求,URL 请求路径为资源集合名称
// HTTP 请求体中包含需要创建的资源
option (google.api.http) = {
// parent 对应父资源的名称,如 shelves/1
post: "/v1/{parent=shelves/*}/books"
body: "book"
};
}
// 创建书籍请求
message CreateBookRequest {
// 父资源名称
string parent = 1;
// 资源 id
string book_id = 3;
// 需要创建的资源
// 字段名称需要和 RPC 方法中的名词对应,即 book -> Book
Book book = 2;
}
// 创建一个书架
rpc CreateShelf(CreateShelfRequest) returns (Shelf) {
option (google.api.http) = {
post: "/v1/shelves"
body: "shelf"
};
}
// 创建书架请求
message CreateShelfRequest {
Shelf shelf = 1;
}
Update
Update 方法接收一个资源实体,以及其他的参数来更新指定的资源及其属性,并返回更新后的资源。
资源的可变属性应当能够通过 Update 方法修改,除非该属性包含资源的名称或父资源的名称。资源重命名或者将资源移动到另一个父资源下都不允许在 Update 方法中实现,而应当由自定义方法来实现。
Update 方法和 HTTP 请求的映射关系如下:
- 标准的 Update 方法应该能够支持更新资源的部分属性,并通过 update_mask 字段来指明需要更新的属性,对应的 HTTP 请求方法为 PATCH。资源实体中标注为 Output only 的属性应该在资源更新时忽略
- 如果要求 Update 方法实现更为高级的局部更新语义则应当将其作为自定义方法来实现,例如追加新值到资源的某个列表类型的属性上
- 如果 Update 方法不支持局部属性更新,则对应的 HTTP 请求方法必须是 PUT。不过不建议 Update 方法仅支持全局更新,因为后续如果为资源添加新的属性则可能会有后向兼容问题
- Update 方法的 RPC 请求消息体中表示资源名称的字段值必须和 URL 中的请求路径相匹配。这个资源名称字段可能包含在资源实体内
- Update 方法的 RPC 请求消息体中表示资源实体的各字段必须和 HTTP 请求体中的字段相对应
- Update 方法的其余参数必须和 URL 的查询参数相匹配
- Update 方法的返回结果必须是更新后的资源实体
既然 URL 中已经有了资源名称,为什么请求体里面还要再传一遍资源名称?关于这一点不同的服务有不同的实现,例如 DigitalOcean 的更新接口就不要求请求体中再传一遍 id:Update an App。
Update 方法的返回结果必须是更新后的资源实体看起来是多此一举,但是某些资源的属性必须由服务端来更新,例如资源的更新时间,或者对于 Git 服务来说文件更新后的版本号等等,这些属性更新后也需要返回给客户端。
如果后端服务允许客户端指定资源名称则 Update 方法允许客户端调用时发送一个不存在的资源名称,然后服务端会自动创建一个新的资源。否则,Update 方法应当作失败处理并返回 NOT_FOUND 的错误码(如果这是唯一的错误的话)。
即使 Update 方法本身支持新建资源也应当提供额外的 Create 方法,否则服务的使用者可能会感到迷惑。
接口定义示例:
// 更新一本书
rpc UpdateBook(UpdateBookRequest) returns (Book) {
// Update 方法对应 HTTP 的 PATCH 请求,资源名称映射到请求路径
// 资源实体包含在 HTTP 请求体中
option (google.api.http) = {
// 请求路径包含了需要更新的资源名称
patch: "/v1/{book.name=shelves/*/books/*}"
body: "book"
};
}
// 更新书籍请求
message UpdateBookRequest {
// 需要更新的书籍
Book book = 1;
// 指定需要更新的书籍属性,具体定义见 https://developers.google.com/protocol-buffers/docs/reference/google.protobuf#fieldmask
FieldMask update_mask = 2;
}
Delete
Delete 方法接受一个资源名称和其他参数来删除或者计划删除某个指定的资源。Delete 方法返回的消息体类型应当为 google.protobuf.Empty。
服务调用方不应该依赖 Delete 方法返回的任何信息,因为 Delete 方法被重复调用时不一定每次都返回相同的信息。
Delete 方法和 HTTP 请求的映射关系如下:
- Delete 方法必须对应 HTTP 的 DELETE 请求
- Delete 方法的 RPC 请求消息体中表示资源名称的字段值应当和 URL 中的请求路径相匹配
- Delete 方法的其余参数应当和 URL 的查询参数相匹配
- 对应的 HTTP 请求无请求体;Delete 方法的 API 定义中不允许声明 body 语句
- 如果 Delete 方法在实现时是立即删除资源则该方法返回的消息体为空
- 如果 Delete 方法在实现时是创建一个 长时间运行任务 来删除资源,则该方法返回的消息体应当为对应的任务信息
- 如果 Delete 方法在实现时仅将资源标记为删除而不是物理删除,则该方法应当返回更新后的资源
Delete 方法应当是幂等的,但并不要求每次都返回相同的信息。对同一个资源的多个 Delete 请求应当使得该资源(最终)被删除,不过只有第一个成功删除资源的请求应当返回相应的成功信息,其余的请求应当返回 google.rpc.Code.NOT_FOUND 错误码。
接口定义示例:
// 删除一本书
rpc DeleteBook(DeleteBookRequest) returns (google.protobuf.Empty) {
// Delete 方法对应 HTTP 的 DELETE 请求,资源名称映射到请求路径,无 HTTP 请求体
option (google.api.http) = {
// 请求路径包含了需要删除的资源名称,例如 shelves/shelf1/books/book2
delete: "/v1/{name=shelves/*/books/*}"
};
}
// 删除书籍请求
message DeleteBookRequest {
// 需要被删除的资源名称,如 shelves/shelf1/books/book2
string name = 1;
}
自定义方法
标准方法提供了对资源的基础操作功能,它们的职责都较为单一,基本上对应了基础的 CRUD 操作。不过,并不是所有对资源的操作都能或者适合抽象为 CRUD 操作,这也是对于 RESTful 风格的服务经常争论的地方。因此,自定义方法就应运而生。
不过,对于 API 的设计者而言应当尽可能的首选使用标准方法,因为标准方法有着更为统一的语义,对开发者而言更为简单易懂。
自定义方法可以应用于资源,资源集合或者服务。它可能会接收任意类型的输入和返回任意类型的输出,并且支持流式的请求和响应。
HTTP 请求映射
对于自定义方法来说,应当使用如下的 HTTP 请求映射:
https://service.name/v1/some/resource/name:customVerb
这里之所以选择 : 而不是 / 将 name 和 customVerb 分开是为了支持 name 中包含 / 的情况,例如将文件路径作为资源名称时则获取资源的请求可能为 GET /files/a/long/file/name,则撤销对该文件的删除操作所对应的自定义方法可能为 POST /files/a/long/file/name:undelete,如果 undelete 前用 / 分割则无法识别完整的资源名称。
自定义方法和 HTTP 请求的映射关系应当遵循如下规则:
- 自定义方法应当使用 HTTP 请求的 POST 方法,除非该自定义方法是作为标准方法中的 List 或者 Get 方法的扩展,此时可以使用 HTTP 请求的 GET 方法
- 自定义方法不应该使用 HTTP 请求的 PATCH 方法,但是可以使用其他 HTTP 请求方法
- 对于使用 HTTP 请求的 GET 方法的自定义方法来说必须保证接口的幂等性
- 自定义方法的 RPC 请求消息体中表示资源或者资源集合名称的字段值应当和 URL 中的请求路径相匹配
- HTTP 请求的路径必须以 :customVerb 的形式结尾
- 如果自定义方法对应的 HTTP 请求方法允许 HTTP 请求体(如 POST,PUT,PATCH 或者自定义的 HTTP 方法),则该自定义方法的 HTTP 配置中必须声明 body: “*” 语句,并且 RPC 消息体中的剩余字段应当和 HTTP 请求体中的字段相匹配
- 如果自定义方法对应的 HTTP 请求方法不接受 HTTP 请求体(如 GET,DELETE),则该自定义方法的 HTTP 配置中不允许声明 body 语句,并且 RPC 消息体中的剩余字段应当和 URL 的查询参数相匹配
接口定义示例:
// 服务级别的自定义方法
rpc Watch(WatchRequest) returns (WatchResponse) {
// 对应 HTTP 的 POST 请求,所有请求参数都来自于 HTTP 的请求体
option (google.api.http) = {
post: "/v1:watch"
body: "*"
};
}
// 资源集合级别的自定义方法
rpc ClearEvents(ClearEventsRequest) returns (ClearEventsResponse) {
option (google.api.http) = {
post: "/v3/events:clear"
body: "*"
};
}
// 资源级别的自定义方法
rpc CancelEvent(CancelEventRequest) returns (CancelEventResponse) {
option (google.api.http) = {
post: "/v3/{name=events/*}:cancel"
body: "*"
};
}
// 一个批量获取资源的自定义方法
rpc BatchGetEvents(BatchGetEventsRequest) returns (BatchGetEventsResponse) {
// 对应 HTTP 的 GET 请求
option (google.api.http) = {
get: "/v3/events:batchGet"
};
}
使用场景
以下是一些自定义方法比标准方法更适合的场景:
- 重启一台虚拟机:其中一种反直觉的设计是在重启资源集合下创建一个重启资源,这属于生搬硬套;或者为虚拟机增加一个状态字段,重启操作就等价于资源的局部更新操作,即将虚拟机的状态由 RUNNING 改为 RESTARTING,虽然看似合理但是增加了使用人员的心智负担,例如除了这两种状态之外还有其他什么状态?另一方面也增加了接口实现的复杂度,标准方法的 Update 接口需要额外针对状态字段进行逻辑处理,违背了单一职责原则
- 批处理:对于性能敏感的场景而言,提供批处理的自定义方法比一系列独立的标准方法可能有着更好的性能
对于 RESTful 服务的争论中最常提到的例子就是如何使用 RESTful 接口表示注册/登陆?注册/登陆并不适合作为标准方法来实现,使用自定义方法会更好。一般而言,标准方法的实现应当尽量简单直白,一旦需要对标准方法扩展处理额外的逻辑,就需要考虑是否使用自定义方法更合适。
错误处理
错误处理是 RESTful 又一个争论的点,即业务错误可能有很多,HTTP 的状态码根本不够,以及业务的状态码不应该和协议层的状态码相混淆。
错误模型
Google API 将错误统一封装为 google.rpc.Status:
package google.rpc;
// 适用于不同编程环境的统一错误模型,包括 REST 接口和 RPC 接口
message Status {
// 错误码,具体错误码的定义见 google.rpc.Code
int32 code = 1;
// 错误信息,对错误原因的描述以及可能的修复方式
string message = 2;
// 错误的详细信息,开发人员可以通过详细信息找到一些有用的信息
repeated google.protobuf.Any details = 3;
}
由于大部分的 Google APIs 都是面向资源的设计,错误处理同样遵循了这样的设计,即使用一系列的标准错误来应对大多数的资源错误场景。例如使用标准的 google.rpc.Code.NOT_FOUND 错误来统一表示某个资源不存在,而不是为每一个资源定义一个 SOME_RESOURCE_NOT_FOUND 错误。
错误码
Google APIs 必须使用 google.rpc.Code 中定义的错误码,不允许独自额外定义错误码。
错误信息
错误信息应当能够帮助用户简单快速的理解和解决 API 错误。一般而言,描述错误信息可以遵循如下的规则:
- 不要假设用户是你所开发的服务的专家,他们可能是客户端开发者,运维人员,IT 人员以及应用的终端用户
- 不要假设用户知晓你所开发的服务任何的实现细节,或者熟悉错误的上下文
- 尽可能的使得错误信息有助于技术用户(不一定是服务的开发人员)响应错误并修正
- 保持错误信息简洁。如果可能的话在错误信息中提供一个帮助链接,以便于用户能够提问,反馈或者查找一些有用的信息
错误信息可能会随时变动,应用开发人员不应该强依赖错误信息。
错误详情
Google APIs 定义了一些列标准的 错误详情,这些错误详情覆盖了大部分的错误场景,例如配额分配失败以及无效的参数等等。和错误码一样,开发人员应当尽可能的优先使用标准的错误详情。
只有当错误详情有助于应用代码处理错误的情况下才应该考虑引入新的错误详情。如果当前错误只能由人工处理,则应依据错误信息由开发人员处理,而不是引入额外的错误详情。
以下是一些错误详情类型的例子:
- ErrorInfo:提供稳定又可扩展的结构化错误信息
- RetryInfo:告诉客户端什么时候可以对一个失败的请求进行重试,可能随错误码 - Code.UNAVAILABLE 或者 Code.ABORTED 返回
- QuotaFailure:描述为什么配额分配失败了,可能随错误码 Code.RESOURCE_EXHAUSTED 返回
- BadRequest:客户端请求参数非法,可能随错误码 Code.INVALID_ARGUMENT 返回
错误映射
Google APIs 会被不同的编程环境访问,每个环境有自己的错误处理方式,所以需要将前面描述的错误模型对各个编程环境进行适配和映射。
HTTP 映射
对于 HTTP 接口来说,出于后向兼容性的考虑,Google APIs 定义了如下的错误模型:
// 适用于 JSON HTTP 接口的错误模型
message Error {
// 废弃字段,仅用于 v1 格式的错误
message ErrorProto {}
// 和 `google.rpc.Status 有着相同的语义,出于和 Google API Client
// Libraries 后向兼容的考虑多了额外的 status 和 errors 字段
message Status {
// 错误码,同时也是 HTTP 状态码,对应 google.rpc.Status.code
int32 code = 1;
// 错误信息,对应 google.rpc.Status.message
string message = 2;
// 废弃字段,仅用于 v1 格式的错误
repeated ErrorProto errors = 3;
// 错误码的枚举值,对应 google.rpc.Status.code
google.rpc.Code status = 4;
// 错误详情,对应 google.rpc.Status.details
repeated google.protobuf.Any details = 5;
}
// 实际的错误消息体,之所以要额外包一层也是出于和 Google API Client
// Libraries 后向兼容的考虑,同时对于开发人员来说错误信息的可读性更高
Status error = 1;
}
具体示例:
{
"error": {
"code": 400,
"message": "API key not valid. Please pass a valid API key.",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.ErrorInfo",
"reason": "API_KEY_INVALID",
"domain": "googleapis.com",
"metadata": {
"service": "translate.googleapis.com"
}
}
]
}
}
gRPC 映射
不同的 RPC 协议有着不同的错误处理模式,对于 gRPC 来说,上述的错误模型在各语言自动生成的代码中已经天然支持。
客户端类库映射
不同的编程语言对于错误处理有着不同的准则,客户端类库会尽量去适配这些准则,例如 google-cloud-go 遇到错误时会返回和 google.rpc.Status 实现了同样接口的错误,而 google-cloud-java 则会直接抛出错误。
错误处理
下表列出了 google.rpc.Code 定义的所有错误码:
| HTTP | gRPC |
|---|---|
| 200 | OK |
| 400 | FINVALID_ARGUMENT |
| 400 | FAILED_PRECONDITION |
| 400 | OUT_OF_RANGE |
| 401 | UNAUTHENTICATED |
| 403 | PERMISSION_DENIED |
| 404 | NOT_FOUND |
| 409 | ABORTED |
| 409 | ALREADY_EXISTS |
| 429 | RESOURCE_EXHAUSTED |
| 499 | CANCELLED |
| 500 | DATA_LOSS |
| 500 | UNKNOWN |
| 500 | INTERNAL |
| 501 | NOT_IMPLEMENTED |
| 502 | N/A |
| 503 | UNAVAILABLE |
| 504 | DEADLINE_EXCEEDED |
Google APIs 可能会并发的检查 API 请求是否满足条件,返回某个错误码不代表其他条件都符合要求,应用代码不应该依赖条件检查的顺序。
可以看到,即使是相同的 HTTP 状态码其代表的含义也是不同的,此时就需要 status 字段来进一步区分,类似于将所有错误划分几个大类,然后在每个大类中再细分小类,相比于单纯用 HTTP 状态码来表示不同的错误来说更加灵活,扩展性也更好。
与之相对的非 RESTful 做法则是 HTTP 状态码永远返回200,在返回的消息体中定义错误码和错误信息,例如:
{
"data": "some data",
"code": 123,
"message": "something is wrong"
}
重试错误
对于 503 UNAVAILABLE 错误客户端可以采用 exponential backoff 的方式进行重试,最短重试等待时间应该是1秒,以及默认重试次数应当是1次,除非文档有特别说明。
对于 429 RESOURCE_EXHAUSTED 错误客户端可以等待更长的时间进行重试,不过最短的等待时间应当是30秒。这种重试仅对于长时间运行任务有效。
对于其他的错误,重试可能就不太适合。
错误传播
如果当前服务依赖于其他服务,则不应该直接将其他服务的错误返回给客户端。在进行错误转换时建议:
- 隐藏实现的细节及机密的信息
- 调整负责该错误的一方,例如当前服务从其他服务收到 INVALID_ARGUMENT 错误时则返回 INTERNAL 错误给客户端
错误重现
如果通过日志分析和监控无法解决错误,则应该尝试通过简单、可重复的测试来重现错误。
设计模式
空响应
标准方法中的 Delete 方法应当返回 google.protobuf.Empty,除非 Delete 执行的是软删除,此时应当返回更新后的资源实体。
对于自定义方法来说,应当返回各自的 XxxResponse 消息体,因为即使该方法现在没有数据返回随着时间的推移有很大的可能会增加额外的字段。
范围表示
表示范围的字段应当使用左闭右开的区间,并以 [start_xxx, end_xxx) 的形式命名,例如 [start_key, end_key) 或者 [start_time, end_time)。API 应当避免其他形式的范围表示,如 (index, count) 或者 [first, last]。
资源标签
在面向资源的 API 设计下,资源的模式由 API 决定。为了让客户端能够给资源添加自定义的元数据(例如标记某台虚拟机为数据库服务器),资源定义中应当添加一个 map<string, string> labels 字段,例如:
message Book {
string name = 1;
map<string, string> labels = 2;
}
长时间运行操作
如果某个 API 方法需要很长时间才能完成,则该方法应该设计成返回一个长时间运行操作资源给客户端,客户端可以通过这个资源来跟踪方法的执行进展及获取执行结果。Operation 定义了标准的接口来处理长时间运行操作,各 API 不允许自行定义额外的长时间运行操作接口以避免不一致。
长时间运行操作资源必须以响应消息体的方式返回给客户端,并且该操作的任何直接结果都应该反应到其他 API 中。例如,如果有一个长时间运行操作用于创建资源,即使该资源未创建完成,LIST 和 GET 标准方法也应该返回该资源,只是该资源会被标记为暂未就绪。当长时间操作完成时,Operation.response 字段应当包含该操作的执行结果。
长时间运行操作可以通过 Operation.metadata 字段来反馈其运行进展。API 在实现时应当为 Operation.metadata 定义消息类型,即使在一开始的实现中不会填充 metadata 字段。
List 方法分页
支持 List 方法的资源集合应当支持分页功能,即使该方法返回的结果集很小。
因为如果一开始 List 方法不支持分页,后续增加分页功能就会使得和原有 API 的行为不一致。客户端在不知道 List 方法使用分页的情况下依然会认为该方法返回的是完整的资源集合,而实际上有可能只是返回了第一页的资源。
为了兼容旧的逻辑,只能将分页信息设为非必要字段。
为了支持 List 方法的分页功能,API 应当:
- 在 List 方法的请求消息中定义 string 类型的 page_token 字段。客户端通过该字段来获取指定某页的资源
- 在 List 方法的请求消息中定义 int32 类型的 page_size 字段。客户端通过该字段来指定每页返回的最大数据量。对于服务端来说,可能会为客户端传入的 page_size 大小设置一个上限。如果 page_size 的值为0,则由服务端来决定需要返回多少数据
- 在 List 方法的响应消息中定义 string 类型的 next_page_token 字段。客户端通过该字段来获取下一页的资源,如果 next_page_token 的值为 “”,则表示没有下一页的资源
接口定义示例:
rpc ListBooks(ListBooksRequest) returns (ListBooksResponse);
message ListBooksRequest {
string parent = 1;
int32 page_size = 2;
string page_token = 3;
}
message ListBooksResponse {
repeated Book books = 1;
string next_page_token = 2;
}
所有分页的实现可能会在响应消息中增加一个 int32 类型的 total_size 字段来表示资源的总个数。
查询子资源集合
有时候客户端可能会希望有一个 API 能够在多个子资源集合间查询资源。例如,某个图书馆 API 有一个书架的资源集合,每个书架包含一个书籍资源集合,客户端可能会希望在多个书架之间搜索某本书。这种情况建议对子资源使用标准的 List 方法,并使用通配符 - 来表示父资源集合,例如:
GET https://library.googleapis.com/v1/shelves/-/books?filter=xxx
从子资源集合获取唯一资源
有时候某个子资源集合下的资源在全局父资源下有着唯一的标识符。常规的做法是需要先知道该资源的父资源的名称然后才能获取该资源,这种情况建议对该资源使用标准的 Get 方法,并使用通配符 - 来表示父资源集合。例如,如果某本书在所有的书架上有着唯一的标识符,那么可以使用如下的请求来获取该本书籍:
GET https://library.googleapis.com/v1/shelves/-/books/{id}
另外,该接口返回的资源名称必须是完整的,其父资源名称必须返回实际的值,而不是 -,例如上述的请求应该返回资源名称 shelves/shelf713/books/book8141,而不是 shelves/-/books/book8141。
排序顺序
如果某个 API 允许客户端指定资源的排序顺序,则请求消息体中应该包含一个 order_by 字段:
string order_by = …;
order_by 应当遵循 SQL 语法:即使用逗号分割多个字段,例如 “foo,bar”。默认的排序规则是升序,如果需要降序排序,则应当在字段名后增加 " desc" 后缀,例如 “foo desc,bar”。
同时,字段间额外的空格是无关紧要的,例如 “foo,bar desc” 和 " foo , bar desc " 是等价的。
请求验证
如果某个 API 有副作用并且需要在执行前验证请求是否有效,则请求消息体中应该包含一个 validate_only 字段:
bool validate_only = …;
如果设置为 true,则该 API 收到请求时仅进行验证而不会实际执行。
如果验证通过,则必须返回 google.rpc.Code.OK 给客户端,并且对于任何有着相同参数的请求都不应该返回 google.rpc.Code.INVALID_ARGUMENT 错误。不过该 API 依然有可能返回其他错误例如 google.rpc.Code.ALREADY_EXISTS。
请求去重
对于网络 API 来说首选幂等的 API,因为当发生网络异常时可以安全的重试。不过某些 API 无法轻易的实现幂等,例如创建一个资源,但是又需要避免重复的请求。这种情况下请求消息体应该包含一个唯一的 ID,例如 UUID 使得服务端能够通过这个唯一的 ID 进行去重:
// 服务端根据此唯一的 ID 进行去重
// 该字段应当命名为 request_id
string request_id = ...;
当服务端监测到重复的请求时,服务端应当返回之前成功的相同请求的结果给客户端,因为客户端大概率没有收到之前的返回结果。
枚举默认值
每一个枚举的定义都必须以0作为起始值,当枚举值未明确时应当使用该0值,同时 API 文档必须标注如何处理0值。
枚举0值应当命名为 ENUM_TYPE_UNSPECIFIED。如果 API 有着通用的默认行为,则枚举值未定义时应当使用0值,否则0值应当被拒绝并返回 INVALID_ARGUMENT 错误。
枚举值示例:
enum Isolation {
// 未定义
ISOLATION_UNSPECIFIED = 0;
// 从快照读取数据,如果当前所有的读写操作与并发执行中的事务无法做到逻辑串行执行则发生冲突
SERIALIZABLE = 1;
// 从快照读取数据,如果当前有并发执行中的事务写入到相同的行则发生冲突
SNAPSHOT = 2;
...
}
// 当隔离级别未定义时,服务端可能会采用 SNAPSHOT 或者更优的隔离级别
Isolation level = 1;
在某些情况下可能使用某个惯用名表示枚举0值,例如 google.rpc.Code.OK 是错误码不存在时的默认值,它在语义上等价于 UNSPECIFIED。
语法规则
在某些场景下,需要为特定的数据格式定义简单的语法,例如允许接受的文本输入。为了在各 API 间提供一致的开发体验,API 设计者必须使用如下的 Extended Backus-Naur Form (EBNF) 的变种来定义语法:
Production = name "=" [ Expression ] ";" ;
Expression = Alternative { "|" Alternative } ;
Alternative = Term { Term } ;
Term = name | TOKEN | Group | Option | Repetition ;
Group = "(" Expression ")" ;
Option = "[" Expression "]" ;
Repetition = "{" Expression "}" ;
整数类型
设计 API 时应当避免使用无符号整型例如 uint32 和 fixed32,因为某些重要的编程语言或者系统不能很好的支持无符号整型,例如 Java,JavaScript 和 OpenAPI,并且它们很大可能会造成整型溢出错误。另一个问题是不同的 API 可能将同一个值各自解析为不同的无符号整型或者带符号整型。
在某些场景下类型为带符号整型的字段值如果是负数则没有意义,例如大小,超时时间等等;API 设计者可能会用-1(并且只有-1)来表示特殊的含义,例如文件结束符(EOF),无限的超时时间,无限的配额或者未知的年龄等等。这种用法必须明确的在接口文档中标注以避免迷惑。同时 API 设计者也应当标注当整型数值为0时的系统行为,如果它不是非常直白明了的话。
局部响应
在某些情况下,客户端可能只希望获取资源的部分属性。Google API 通过 FieldMask 来支持这一场景。
对于任意 Google API 的 REST 接口,客户端都可以传入额外的 $fields 参数来表明需要获取哪些字段:
GET https://library.googleapis.com/v1/shelves?$fields=shelves.name
GET https://library.googleapis.com/v1/shelves/123?$fields=name
资源视图
为了减少网络传输,可以允许客户端指定需要返回资源的某个视图而不是完整的资源数据,这需要在请求消息体中增加一个额外的参数,该参数要求:
- 应该是 enum 类型
- 必须命名为 view
枚举类型的每一个值都定义了应当返回资源的哪部分数据。具体返回哪部分数据由实现决定并且应当在文档中标注。
接口定义示例:
package google.example.library.v1;
service Library {
rpc ListBooks(ListBooksRequest) returns (ListBooksResponse) {
option (google.api.http) = {
get: "/v1/{name=shelves/*}/books"
}
};
}
enum BookView {
// 未定义,等同于 BASIC
BOOK_VIEW_UNSPECIFIED = 0;
// 默认视图,仅返回作者,标题,ISBN 和书籍 ID
BASIC = 1;
// 完整视图,返回书籍的全部数据,包括书籍的内容
FULL = 2;
}
message ListBooksRequest {
string name = 1;
// 指定需要返回书籍的哪个视图
BookView view = 2;
}
客户端就可以通过如下的方式调用:
GET https://library.googleapis.com/v1/shelves/shelf1/books?view=BASIC
ETags
ETag 用于客户端进行条件请求,例如客户端获取了某个资源后将其缓存,下次再请求相同的资源时附带上之前服务端返回的 ETag,如果服务端判断 ETag 没有发生变化则无需返回完整的资源实体。为了支持 ETag,应当在资源定义时添加 etag 字段,同时其语义应当同 ETag 的常见用法保持一致。
ETag 支持强校验和弱校验,弱校验时 ETag 的值需要添加前缀 W/。强校验模式下,如果两个资源有着相同的 ETag 则说明这两个资源的每个字节都是相同的,而且有着相同的额外字段(例如 Content-Type)。这表示强校验模式下获取的多个资源局部响应数据可以组合成为一个完整的资源数据。
相反的,弱校验模式下两个资源有着相同的 ETag 并不能说明两个资源的每一个字节都相同,因此不适合用于缓存字节范围的请求响应。
强弱 ETag 示例:
// 强 ETag,包括引号
"1a2f3e4d5b6c7c"
// 弱 ETag,包括前缀和引号
W/"1a2b3c4d5ef"
需要注意的是,引号也是 ETag 的一部分,所以如果 ETag 在 JSON 中表示需要对引号进行转义:
// 强
{ "etag": "\"1a2f3e4d5b6c7c\"", "name": "...", ... }
// 弱
{ "etag": "W/\"1a2b3c4d5ef\"", "name": "...", ... }
输出字段
一个资源的某些字段可能不允许客户端设置而只能由服务端返回,这些字段应当需要额外标注。
需要注意的是如果仅作为输出的字段在请求消息体中设置了,或者包含在了 google.protobuf.FieldMask 中,服务端也必须接受该请求而不是返回错误,只不过服务端在处理时需要忽略这些输出字段。之所以要这么做是因为客户端经常会复用某个接口返回的资源,将其作为另一个接口的输入,例如客户端可能会先请求获取一个 Book 资源,将其修改后再调用 UPDATE 方法。如果服务端对输出字段进行校验,则要求客户端进行额外的处理来删除这些输出字段。
接口示例如下:
import "google/api/field_behavior.proto";
message Book {
string name = 1;
Timestamp create_time = 2 [(google.api.field_behavior) = OUTPUT_ONLY];
}
单例资源
当只有一个资源存在于某个父资源下(或服务,如果没有父资源的话)时,则可以使用单例资源。
标准方法的 Create 和 Delete 方法对单例资源无效,单例资源一般随着父资源的创建而创建, 随着父资源的删除而删除。单例资源必须通过标准方法的 Get 和 Update 方法来访问,以及其他适合的自定义方法。
例如,每一个 User 资源可以有一个单例的 Settings 资源:
rpc GetSettings(GetSettingsRequest) returns (Settings) {
option (google.api.http) = {
get: "/v1/{name=users/*/settings}"
};
}
rpc UpdateSettings(UpdateSettingsRequest) returns (Settings) {
option (google.api.http) = {
patch: "/v1/{settings.name=users/*/settings}"
body: "settings"
};
}
[...]
message Settings {
string name = 1;
// 省略其他字段
}
message GetSettingsRequest {
string name = 1;
}
message UpdateSettingsRequest {
Settings settings = 1;
// 支持局部更新
FieldMask update_mask = 2;
}
流式半关闭
对于任何的双向或者客户端流式 API,服务端应该依赖由 RPC 系统提供、客户端发起的半关闭来完成客户端流。没有必要额外的定义一个完成的消息。
任何在客户端发起半关闭前想要发送的消息都必须定义为请求消息体的一部分。
Domain-scoped 名称
domain-scoped 名称指的是添加了域名前缀的实体名称,用于避免不同服务的命名冲突。Google APIs 和 Kubernetes APIs 大量使用了 domain-scoped 名称:
- Protobuf 的 Any 类型:type.googleapis.com/google.protobuf.Any
- Stackdriver 的指标类型:compute.googleapis.com/instance/cpu/utilization
- 标签的键:cloud.googleapis.com/location
- Kubernetes 的 API 版本号:networking.k8s.io/v1
- x-kubernetes-group-version-kind 的 OpenAPI 扩展中的 kind 字段
布尔值 vs. 枚举 vs. 字符串
设计 API 时有时候会遇到需要能够启用或者禁用某个功能的场景,从实现上说可以增加一个 bool,enum 或者 string 类型的字段来控制,具体选择哪种类型可以遵循如下规则:
- 如果确定只有两种状态且不希望在未来扩展时使用 bool,例如 enable_tracing 或者 enable_pretty_print
- 如果希望设计更为灵活但是又不希望改动太频繁时使用 enum,一个评估的准则是一旦 enum 的值确定了,那么一年内只会改动一次或者更低频,例如 enum TlsVersion 或者 enum HttpVersion
- string 有着最大的灵活性,适用于可能会频繁修改的场景,其对应的值必须清晰的在文档中标注,例如:
- Unicode regions 对应的 string region_code
- Unicode locales 对应的 string language_code
数据保留
对于某些服务而言,用户数据非常重要,如果用户数据不小心被软件 bug 或者人为错误删除,在缺少数据保留策略和撤销删除功能的情况下,可能对业务造成灾难性的影响。
一般而言,建议为 API 服务设置如下的数据保留策略:
- 对于用户的元数据,用户设置等其他重要的数据,设置30天的数据保留期。例如监控指标,项目的元数据和服务定义
- 对于大容量的用户数据,应该设置7天的数据保留期。例如对象存储和数据库表
- 对于临时的状态数据或者昂贵的存储数据,如果可行的话应该设置1天的数据保留期。例如 memcache 和 Redis 内存中的数据
在数据保留期内,可以执行撤销删除的操作从而不会造成数据丢失。
大型传输载荷
网络 API 依赖分层的网络架构来传输数据,大多数的网络协议层对输入和输出的数据量设置了上限,一般而言,32 MB 是大多数系统中常用的大小上限。
如果某个 API 涉及的传输载荷超过 10 MB,则需要选择合适的策略以确保易用性和未来的扩展的需求。对于 Google APIs 来说,建议使用流式传输或者媒体上传/下载的方式来处理大型载荷,在流式传输下,服务端能够以增量同步的方式处理大量数据,例如 Cloud Spanner API。在媒体传输下,大量的数据流先流入到大型的存储系统中,例如 Google Cloud Storage,然后服务端可以异步的从存储系统中读取数据并处理,例如 Google Drive API。
可选的基本类型字段
Protocol Buffers v3 支持 optional 基本类型字段,在语义上等同于众多编程语言中的 nullable 类型,它可以用于区分空值和未设置的值。
在实践中开发人员难以正确的处理可选字段,大多数的 JSON HTTP 客户端类库,包括 Google API Client Libraries,无法正确区分 proto3 的 int32,google.protobuf.Int32Value 以及 optional int32。如果存在一个方案更清晰而且也不需要可选的基本类型字段,则优先选择该方案。如果不使用可选的基本类型字段会造成复杂度上升或者含义不清晰,则选择可选的基本类型字段。但是不允许可选字段搭配包装类型使用。一般而言,从简洁和一致性考虑,API 设计者应当尽量选择基本类型字段,例如 int32。
版本控制
Google APIs 借助版本控制来解决后向兼容问题。
所有的 Google API 接口都必须包含一个主版本号,这个主版本号会附加在 protobuf 包的最后,以及包含在 REST APIs 的 URI 的第一个部分中。如果 API 要引入一个与当前版本不兼容的变更,例如删除或者重命名某个字段,则必须增加主版本号,从而避免引用了当前版本的用户代码受到影响。
所有 API 的新主版本不允许依赖同 API 的前一个主版本。一个 API 本身可能会依赖其他 API,这要求调用方知晓被依赖的 API 的版本稳定性风险。在这种情况下,一个稳定版本的 API 必须只依赖同样是稳定版本的其他 API。
同一个 API 的不同版本在同一个客户端应用内必须能在一段合理的过渡时期内同时生效。这个过渡时期保障了客户端应用升级到新的 API 版本的平滑过渡。同样的,老版本的 API 也必须在废弃并最终停用之前留有足够的过渡时间。
对于会发布 alpha 或者 beta 版本的 API 来说,必须将 alpha 或者 beta 附加在主版本号之后,并且使用如下其一的策略:
- 基于渠道的版本控制(推荐)
- 基于发布的版本控制
- 基于可见性的版本控制
基于渠道的版本控制
stability channel 是在某个稳定性级别下长期进行更新的版本。每个主版本号下的每个稳定性级别最多只有一个版本。因此,在这个策略下,每个主版本最多只有三个可用的版本:alpha,beta,以及 stable。
alpha 和 beta 版本必须将稳定性级别附加到主版本号后,而 stable 则不需要也不允许。例如,v1 可用作为 stable 版本的版本号,但是 v1beta 和 v1alpha 不是。类似的,v1beta 或者 v1alpha 可用作为对应的 beta 和 alpha 版本,但是 v1 不行。每个版本下会对新功能进行就地更新而不会修改版本号。
beta 版本的功能必须是 stable 版本的功能的超集,同时 alpha 版本的功能必须是 beta 版本的功能的超集。
对于任何版本的 API 来说,其中的元素(字段,消息体,RPC 方法等)都有可能被标记为废弃:
// Represents a scroll. Books are preferred over scrolls.
message Scroll {
option deprecated = true;
// ...
}
废弃的 API 功能不允许从 alpha 版本继续保留到 beta 版本,也不允许从 beta 版本保留到 stable 版本。也就是说某个功能不能在任何版本中预先废弃。
beta 版本的功能可以在废弃后经过合理的时间后删除,建议是180天。对于只存在于 alpha 版本的功能,不一定会标记为废弃,并且删除时也不会通知。
基于发布的版本控制
在该策略下,alpha 或者 beta 版本的功能在合并到 stable 版本之前只会在有限的时间内可用。因此,一个 API 在每个稳定性级别下可能有任意数量的版本发布。
基于渠道的版本控制和基于发布的版本控制都会就地更新 stable 版本。
alpha 和 beta 版本发布时需要在 alpha 或者 beta 之后附加一个递增版本号,例如 v1beta1 或者 v1alpha5。API 应当在文档中记录这些版本的时间顺序。
每个 alpha 或者 beta 版本都有可能就地进行后向兼容的更新。对于 beta 版本来说,如果发布了后向不兼容的版本则应当修改 beta 后的版本号,然后发布新的版本。例如,如果当前版本是 v1beta1,则新版本为 v1beta2。
当 alpha 和 beta 版本中的功能合并到 stable 版本之后就可以终止 alpha 或者 beta 版本。alpha 版本可能会在任一时刻终止,但是 beta 版本在终止前应当给用户留有足够的过渡期,建议是180天。
基于可见性的版本控制
API 可见性 是 Google API 基础架构提供的一项高级功能。它允许 API 发布者将一个 API 对外暴露出多个不同的外部 API 视图,每个视图关联一个 API 可见性的标签,例如:
import "google/api/visibility.proto";
message Resource {
string name = 1;
// 预览功能,勿在生产环境使用
string display_name = 2
[(google.api.field_visibility).restriction = "PREVIEW"];
}
可见性标签是一个区分大小写的字符串,可以绑定到任意 API 元素上。一般来说,可见性标签应当始终使用全大写字母。所有的 API 元素默认绑定 PUBLIC 的可见性标签,除非显式的声明了可见性。
每个可见性标签本质上是一个允许访问的列表,API 生产者需要授权给 API 消费者合适的可见性标签才能使用 API。换句话说,可见性标签类似于 API 的 ACL(Access Control List)。
每个 API 元素可以绑定多个可见性标签,各可见性标签之间用逗号分割(例如 PREVIEW,TRUSTED_TESTER)。多个可见性标签之间是逻辑或的关系,API 消费者只要授权了其中一个可见性标签就可以使用 API。
一个 API 请求只能使用一个可见性标签,默认使用的是授权给当前 API 消费者的可见性标签。客户端可以显式的指定需要用哪个可见性标签:
GET /v1/projects/my-project/topics HTTP/1.1
Host: pubsub.googleapis.com
Authorization: Bearer y29....
X-Goog-Visibilities: PREVIEW
API 生产者可以借助可见性标签来实现版本控制,例如 INTERNAL 和 PREVIEW。API 的新功能从 INTERNAL 可见性标签开始,然后升级到 PREVIEW 可见性标签。当功能稳定可用后,就删除所有的可见性标签,即等同于默认的可见性标签 PUBLIC。
总体来说,API 的可见性比 API 版本号更容易实现增量的功能迭代,不过这要求比较成熟的 API 基础架构的支持。Google Cloud APIs 经常使用 API 可见性用于预览功能。
兼容性
这里的兼容性讨论的是对于 API 使用者的影响,API 生产者应当自身知晓为了实现兼容性需要哪方面的工作。
总的来说,API 的小版本更新或者补丁更新不应该对客户端造成兼容性问题。可能的不兼容问题包括:
- 源代码兼容性:针对1.0版本编写的代码升级到1.1版本后编译失败
- 二进制文件兼容性:针对1.0版本编译生成的二进制文件链接到1.1版本后运行失败
- 通信兼容性:针对1.0版本编写的应用程序无法和运行1.1版本的服务端通信
- 语义兼容性:针对1.0版本编写的应用程序升级到1.1版本后能够运行,但是存在不可预知的结果
从另一个角度来说,只要主版本号一致,运行着旧版本的客户端程序就能够和运行着新版本的服务端结合使用,并且客户端程序也能轻易的升级小版本。
后向兼容的修改
- 向 API 服务添加新的接口
从协议角度来看,添加新的接口始终是安全的。需要注意的是有可能新添加的接口名称已经被客户端代码占用了。如果当前新添加的接口与当前存在的接口完全不同,则基本不用担心;但是如果新添加的接口是当前某个存在的接口的简化版本,则有可能和客户端自定义实现的接口冲突。
- 向 API 接口添加新的方法
除非新添加的方法和客户端自动生成的代码中的某个方法冲突,否则这也是安全的。
例如当前已经存在了一个 GetFoo 方法,C# 的代码生成器会同时生成一个 GetFooAsync 的方法,如果此时再添加一个 GetFooAsync 方法,则会造成冲突。
- 向已有的方法添加 HTTP 绑定
假设绑定 HTTP 没有任何歧义,那么让服务端响应之前拒绝的 URL 就是安全的。这个操作可能在将某个已有的操作映射到某个新资源时发生。
- 向请求消息体添加新的字段
只要服务端在新版本的代码中处理未传入的新字段的逻辑和老版本代码中的逻辑一致,那么添加新的字段就是安全的。
一个最可能出错的场景是添加分页相关的字段:如果 v1.0 版本的代码中没有分页功能,那么也不能将分页功能添加到 v1.1 版本中,除非 page_size 的默认值是无限大(但这通常不是个好的设计)。否则的话依赖了 v1.0 版本的客户端期望一次请求获取所有的数据,但实际上可能只获取了第一页的数据。
- 向响应消息体添加新的字段
对于非资源类的响应消息体来说(例如 ListBooksResponse)添加一个字段都不会造成后向兼容性问题,只要新添加的字段不会影响其他字段的行为即可。消息体中之前暴露的字段应当继续以相同的语义保留,即使可能存在冗余。
例如,1.0版本的响应消息体中有一个字段是 contained_duplicates 表示返回的结果存在重复值并已经进行了去重。在1.1版本中新增了 duplicate_count 字段表示重复的数据数量,虽然原有的 contained_duplicates 已经冗余了但是该字段也必须保留。
- 向枚举添加新值
如果枚举是在请求消息体中使用,那么向枚举添加新值是安全的。因为客户端并不关心它们用不到的值。
对于在资源消息体或者响应消息体中的枚举,默认的假设是客户端需要能够处理未知的枚举值。不过,API 生产者应当知晓客户端如何正确的处理新的枚举值不是一件简单的事,因此必须在文档中标注如果客户端遇到未知的枚举值时期望的行为是什么。
- 添加新的输出字段
如果一个字段只可能会由服务端设置并仅作为输出使用,那么添加这个字段也是安全的。服务端可能会校验客户端发送的消息体中的字段,但是如果新添加的输出字段在请求消息体中不存在,服务端不允许抛出异常。
后向不兼容的修改
- 移除或者重命名服务,字段,方法或者枚举值
一般来说,移除或者重命名某个客户端代码可能引用的内容都是一次后向不兼容的修改,必须升级主版本号才能更新。对于某些编程语言来说如果引用了旧的名称则会造成编译问题(例如 C# 和 Java)或者对于另一些编程语言来说造成运行时异常或者数据丢失。
- 更改 HTTP 映射
这里的更改指的是删除然后添加。例如,假设你想将某个已经存在的方法的 HTTP 映射改为 PATCH,而目前暴露的 HTTP 方法是 PUT,你可以添加一个新的 HTTP 映射,但是不能删除原有的 HTTP 映射。
- 更改字段类型
即使更改后的字段类型和当前的传输格式兼容,也可能造成客户端生成的代码不兼容,因此也必须升级主版本号才能更新。对于静态编译型编程语言来说,这很容易引入编译问题。
- 更改资源的命名格式
不允许修改资源的名称,这也意味着资源集合的名称也不允许修改。
如果客户端能够在 v2.0 版本中访问 v1.0 版本中创建的资源(或者反过来),那么该资源在两个版本中就应当使用相同的资源名称。
另外,有效的资源名称集也不能修改,因为:
- 如果集合变小,那么之前成功的请求就有可能失败
- 如果集合变大,那么客户端基于之前关于资源名称的假设可能失效。因为客户端很可能会根据资源名称所允许的字符和长度将其存储在其他地方,以及构建自己的资源名称验证规则
- 更改现有请求的可见行为
客户端经常会依赖 API 的行为和语义,即使这些行为没有明确的表示支持或者在文档中说明。因此,在大多数情况下更改 API 的行为会造成后向不兼容问题。如果你的 API 的行为不是非常的隐秘,你都应该假设用户已经识别出 API 的行为并依赖它。
因此,加密分页功能中的页码信息就很有必要(即使该数据没有什么意义),从而防止用户自行创建页码信息,然后当页码行为更改时遭遇后向不兼容问题。
- 更改 HTTP 定义中的 URL 格式
除了资源名称之外,还有两个关于 URL 格式的修改:
- 自定义方法的名称:虽然自定义方法名称不是资源名称的一部分,但依然是 REST 请求路径的一部分,虽然修改 HTTP 的自定义方法名称不会破坏 gRPC 客户端,但依然要假设存在 REST 客户端的用户
- 资源参数名称:例如从 v1/shelves/{shelf}/books/{book} 修改为 v1/shelves/{shelf_id}/books/{book_id} 不会影响资源名称,但是会影响客户端自动生成的代码
- 向资源消息体添加读/写字段
客户端经常会执行先读,然后修改,最后写入的一整套操作,大多数情况下如果某个字段客户端用不到就不会给它赋值。虽然服务端可以采取缺失值的字段就不执行写入的措施,但不适用于基本类型的字段(包括 string 和 bytes),因为基本类型默认值的存在造成无法区分出是客户端主动设置 int32 类型的字段值为0还是没有设置值从而使用默认值0。
总结
虽然 Google 的这篇 API 设计主要是面向资源的设计,但同时也针对其不足提出了改进的方案。不管是 RESTful 还是非 RESTful 的接口设计,都只是一种规范,有各自适合的场景没有孰优孰劣,统一的规范胜过生搬硬套。
四、微软Azure Restful Web API设计
围绕资源组织 API 设计
侧重于 Web API 公开的业务实体。 例如,在电子商务系统中,主实体可能是客户和订单。 可以通过发送包含订单信息的 HTTP POST 请求来创建订单。 HTTP 响应指示下单是否成功。 如果可能,资源 URI 应基于名词(资源)而不是动词(对资源执行的操作)。
https://adventure-works.com/orders // Good
https://adventure-works.com/create-order // Avoid
资源无需基于单个物理数据项。 例如,订单资源可以在内部实现为关系数据库中的多个表,但以单个实体的形式提供给客户端。 避免创建反映数据库内部结构的 API。 REST 旨在为实体建模,以及为应用程序可对这些实体执行的操作建模。 不应将内部实现公开给客户端。
实体通常分组成集合(订单、客户)。 集合是不同于集合中的子项的资源,应具有自身的 URI。 例如,以下 URI 可以表示订单集合:
https://adventure-works.com/orders
向集合 URI 发送 HTTP GET 请求可检索集合中的子项列表。 集合中的每个子项也有自身的唯一 URI。 对子项的 URI 发出 HTTP GET 请求会返回该子项的详细信息。
在 URI 中采用一致的命名约定。 一般而言,有效的做法是对引用集合的 URI 使用复数名词。 最好是将集合和项的 URI 组织成层次结构。 例如,/customers 是客户集合的路径,/customers/5 是 ID 为 5 的客户的路径。 这种方法有助于使 Web API 保持直观。 此外,有许多 Web API 框架可以基于参数化 URI 路径来路由请求,因此,你可以对路径 /customers/{id} 定义路由。
还需要考虑不同类型的资源之间的关系,以及如何公开这些关联。 例如,/customers/5/orders 可以表示客户 5 的所有订单。 我们还可以改变思维方向,使用类似于 /orders/99/customer 的 URI 来表示从订单到客户的关联。 但是,过度扩展此模型可能会变得难以实现。 更好的解决方案是在 HTTP 响应消息的正文中提供指向关联资源的可导航链接。 使用 HATEOAS 启用对相关资源的导航部分详细介绍了该机制。
在更复杂的系统中,我们往往提供 URI(例如 /customers/1/orders/99/products),使客户端能够通过多个关系级别进行导航。 但是,如果资源之间的关系在将来更改,此级别的复杂性可能很难维护并且不够灵活。 相反,请尽量让 URI 相对简单。 应用程序获取对某个资源的引用后,应该可以使用此引用去查找与该资源相关的项目。 可将前面的查询替换为 URI /customers/1/orders 以查找客户 1 的所有订单,然后替换为 /orders/99/products 以查找此订单中的产品。
避免请求复杂度超过集合/项目/集合的资源 URI。
另一个因素是所有 Web 请求都会增加 Web 服务器的负载。 请求越多,负载就越大。 因此,请尽量避免使用公开大量小型资源的“琐碎”Web API。 此类 API 可能需要客户端应用程序发送多个请求才能找到它需要的所有数据。 我们建议将数据非规范化,并将相关信息合并成可通过单个请求检索的较大资源。 但是,需要权衡客户端获取不需要的数据所产生的开销。 检索大型对象可能增大请求的延迟时间,并产生额外的带宽成本。 有关这些性能反模式的详细信息,请参阅琐碎 I/O 和超量提取。
避免在 Web API 与底层数据源之间引入依赖关系。 例如,如果数据存储在关系数据库中,则 Web API 不需要将每个表公开为资源集合。 事实上,这可以算作一种粗劣的设计。 请考虑将 Web API 视为数据库的抽象。 如有必要,可在数据库与 Web API 之间引入映射层。 这样,对于底层数据库方案所做的更改不会影响客户端应用程序。
最后,可能无法将 Web API 实现的每个操作都映射到特定资源。 可以通过 HTTP 请求处理此类非资源场景,这些请求调用某个函数并将结果作为 HTTP 响应消息返回。 例如,实现简单计算器操作(例如,加法和减法)的 Web API 可以提供公开这些操作作为伪资源的 URI,并使用查询字符串来指定所需的参数。 例如:向 URI /add?operand1=99&operand2=1 发出的 GET 请求会返回正文包含值 100 的响应消息。 但是,请尽量少使用这些形式的 URI。
根据 HTTP 方法定义 API 操作
HTTP 协议定义了大量为请求赋于语义的方法。 大多数 RESTful Web API 使用的常见 HTTP 方法是:
- GET 检索位于指定 URI 处的资源的表示形式。 响应消息的正文包含所请求资源的详细信息。
- POST 在指定的 URI 处创建新资源。 请求消息的正文将提供新资源的详细信息。 请注意,POST 还用于触发不实际创建资源的操作。
- PUT 在指定的 URI 处创建或替换资源。 请求消息的正文指定要创建或更新的资源。
- PATCH 对资源执行部分更新。 请求正文包含要应用到资源的一组更改。
- DELETE 删除位于指定 URI 处的资源。
特定请求的影响应取决于资源是集合还是单个子项。 下表使用电子商务示例汇总了大多数 RESTful 实现所采用的常见约定。 请注意,并非所有这些请求都可以实现,具体取决于特定方案。
| 资源 | POST | GET | PUT | DELETE |
|---|---|---|---|---|
| /customers | 创建新客户 | 检索所有客户 | 批量更新客户 | 删除所有客户 |
| /customers/1 | 错误 | 检索客户 1 的详细信息 | 如果客户 1 存在,则更新其详细信息 | 删除客户 1 |
| /customers/1/orders | 创建客户 1 的新订单 | 检索客户 1 的所有订单 | 批量更新客户 1 的订单 | 删除客户 1 的所有订单 |
POST、PUT 和 PATCH 之间的差异可能会引起混淆。
-
POST 请求创建资源。 服务器为新资源分配 URI,并将该 URI 返回给客户端。 在 REST 模型中,我们经常向集合应用 POST 请求。 新资源将添加到集合中。 还可以使用 POST 请求将待处理数据提交到现有资源,且不创建任何新资源。
-
PUT 请求创建资源或更新现有资源。 客户端指定资源的 URI。 请求正文包含资源的完整表示形式。 如果已存在具有此 URI 的资源,则替换该资源。 否则创建新资源(如果服务器支持此操作)。 PUT 请求往往应用到单项资源(例如特定的客户)而不是集合。 服务器可能支持通过 PUT 更新,但不支持通过 PUT 执行创建。 是否支持通过 PUT 执行创建取决于在创建某个资源之前,客户端能否以有意义的方式向该资源分配 URI。 如果不能,则可以使用 POST 来创建资源,并使用 PUT 或 PATCH 来执行更新。
-
PATCH 请求对现有资源执行部分更新。 客户端指定资源的 URI。 请求正文指定要应用到资源的更改集。 这比使用 PUT 更高效,因为客户端只发送更改,而无需发送资源的整个表示形式。 从技术上讲,如果服务器支持,PATCH 也可以创建新资源(通过对一个“null”资源指定一组更新)。
PUT 请求必须是幂等的。 如果客户端多次提交同一个 PUT 请求,结果应始终相同(使用相同的值修改相同的资源)。 无法保证 POST 和 PATCH 请求的幂等性。
符合 HTTP 语义
本部分阐述在设计符合 HTTP 规范的 API 时的一些典型注意事项。 但是,本部分不会一一介绍具体细节或方案。 如有疑问,请查阅 HTTP 规范。
媒体类型
如前所述,客户端和服务器交换资源的表示形式。 例如,在 POST 请求中,请求正文包含要创建的资源的表示形式。 在 GET 请求中,响应正文包含已提取的资源的表示形式。
在 HTTP 协议中,格式是使用媒体类型(也称为 MIME 类型)指定的。 对于非二进制数据,大多数 Web API 支持 JSON(媒体类型 = application/json),可能还支持 XML(媒体类型 = application/xml)。
请求或响应中的 Content-Type 标头指定表示形式的格式。 下面是包含 JSON 数据的 POST 请求示例:
POST https://adventure-works.com/orders HTTP/1.1
Content-Type: application/json; charset=utf-8
Content-Length: 57
{"Id":1,"Name":"Gizmo","Category":"Widgets","Price":1.99}
如果服务器不支持媒体类型,则应返回 HTTP 状态代码 415(不支持的媒体类型)。
客户端请求可以包含一个 Accept 标头,该标头包含客户端可以接受的、来自服务器的响应消息中的媒体类型列表。 例如:
GET https://adventure-works.com/orders/2 HTTP/1.1
Accept: application/json
如果服务器无法匹配所列的任何媒体类型,应返回 HTTP 状态代码 406(不可接受)。
GET 方法
成功的 GET 方法通常返回 HTTP 状态代码 200(正常)。 如果找不到资源,该方法应返回 404(未找到)。
如果请求已完成,但 HTTP 响应中没有包含响应正文,则应返回 HTTP 状态代码 204(无内容);例如,不产生匹配项的搜索操作可能会通过此行为实现。
POST 方法
如果 POST 方法创建了新资源,则会返回 HTTP 状态代码 201(已创建)。 新资源的 URI 包含在响应的 Location 标头中。 响应正文包含资源的表示形式。
如果该方法执行了一些处理但未创建新资源,则可以返回 HTTP 状态代码 200,并在响应正文中包含操作结果。 或者,如果没有可返回的结果,该方法可以返回 HTTP 状态代码 204(无内容)但不返回任何响应正文。
如果客户端将无效数据放入请求,服务器应返回 HTTP 状态代码 400(错误的请求)。 响应正文可以包含有关错误的其他信息,或包含可提供更多详细信息的 URI 链接。
PUT 方法
与 POST 方法一样,如果 PUT 方法创建了新资源,则会返回 HTTP 状态代码 201(已创建)。 如果该方法更新了现有资源,则会返回 200(正常)或 204(无内容)。 在某些情况下,可能无法更新现有资源。 在这种情况下,可考虑返回 HTTP 状态代码 409(冲突)。
请考虑实现可批量更新集合中的多个资源的批量 HTTP PUT 操作。 PUT 请求应指定集合的 URI,而请求正文则应指定要修改的资源的详细信息。 此方法可帮助减少交互成本并提高性能。
PATCH 方法
客户端可以使用 PATCH 请求向现有资源发送一组修补文档形式的更新。 服务器将处理该修补文档以执行更新。 修补文档不会描述整个资源,而只描述一组要应用的更改。 PATCH 方法的规范 (RFC 5789) 未定义修补文档的特定格式。 必须从请求中的媒体类型推断格式。
JSON 也许是 Web API 的最常用数据格式。 有两种基于 JSON 的主要修补格式,分别称作“JSON 修补”和“JSON 合并修补”。
JSON 合并修补更简单一些。 修补文档的结构与原始 JSON 资源相同,但只包含要更改或添加的字段的子集。 此外,可以通过在修补文档中为字段值指定 null,来删除该字段。 (这意味着,如果原始资源包含显式 null 值,则不适合使用合并修补。)
例如,假设原始资源采用以下 JSON 表示形式:
{
"name":"gizmo",
"category":"widgets",
"color":"blue",
"price":10
}
下面是此资源的可能 JSON 合并修补代码:
{
"price":12,
"color":null,
"size":"small"
}
此代码告知服务器要更新 price、删除 color 以及添加 size,而不修改 name 与 category。 有关 JSON 合并修补的具体详细信息,请参阅 RFC 7396。 JSON 合并修补的媒体类型是 application/merge-patch+json。
由于修补文档中的 null 具有特殊的含义,如果原始资源包含显式 null 值,则不适合使用合并修补。 此外,修补文档不会指定服务器应用更新的顺序。 此限制是否造成影响具体取决于数据和域。 RFC 6902 中定义的 JSON 修补更灵活。 它以操作序列的形式指定要应用的更改。 操作包括添加、删除、替换、复制和测试(以验证值)。 JSON 修补的媒体类型是 application/json-patch+json。
下面是在处理 PATCH 请求时可能遇到的典型错误状态,以及相应的 HTTP 状态代码。
| 添加状态 | HTTP 状态代码 |
|---|---|
| 修补文档格式不受支持。 | 415(媒体类型不受支持) |
| 修补文档的格式不正确。 | 400(错误的请求) |
| 修补文档有效,但无法将更改应用到处于当前状态的资源。 | 409(冲突) |
DELETE 方法
如果删除操作成功,Web 服务器应以 HTTP 状态代码 204(无内容)做出响应,指示已成功处理该过程,但响应正文不包含其他信息。 如果资源不存在,Web 服务器可以返回 HTTP 404(未找到)。
异步操作
有时,POST、PUT、PATCH 或 DELETE 操作可能需要一段处理时间才能完成。 如果需要等待该操作完成后才能向客户端发送响应,可能会造成不可接受的延迟。 在这种情况下,请考虑将该操作设置为异步操作。 返回 HTTP 状态代码 202(已接受),指示该请求已接受进行处理,但尚未完成。
应公开一个可返回异步请求状态的终结点,使客户端能够通过轮询状态终结点来监视状态。 在 202 响应的 Location 标头中包含状态终结点的 URI。 例如:
HTTP/1.1 202 Accepted
Location: /api/status/12345
如果客户端向此终结点发送 GET 请求,响应中应包含该请求的当前状态。 (可选)响应中还可以包含预计完成时间,或者用于取消操作的链接。
HTTP/1.1 200 OK
Content-Type: application/json
{
"status":"In progress",
"link": { "rel":"cancel", "method":"delete", "href":"/api/status/12345" }
}
如果异步操作创建了新资源,则该操作完成后,状态终结点应返回状态代码 303(查看其他)。 在 303 响应中,包含一个 Location 标头用于提供新资源的 URI:
HTTP/1.1 303 See Other
Location: /api/orders/12345
有关如何实现此方法的详细信息,请参阅为长时间运行的请求提供异步支持和异步请求-答复模式。
URI 版本管理
每次修改 Web API 或更改资源的架构时,向每个资源的 URI 添加版本号。 以前存在的 URI 应像以前一样继续运行,并返回符合原始架构的资源。
继续解释前面的示例,如果将 address 字段重构为包含地址的每个构成部分的子字段(例如 streetAddress、city、state 和 zipCode),则可通过包含版本号的 URI(如 https://adventure-works.com/v2/customers/3)公开此版资源:
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{"id":3,"name":"Contoso LLC","dateCreated":"2014-09-04T12:11:38.0376089Z","address":{"streetAddress":"1 Microsoft Way","city":"Redmond","state":"WA","zipCode":98053}}
此版本控制机制非常简单,但依赖于将请求路由到相应终结点的服务器。 但是,随着 Web API 经过多次迭代而变得成熟,服务器必须支持多个不同版本,它可能变得难以处理。 此外,简单而言,在所有情况下客户端应用程序都要提取相同数据(客户 3),因此 URI 实在不应该因版本而有所不同。 此方案也增加了 HATEOAS 实现的复杂性,因为所有链接都需要在其 URI 中包括版本号。
查询字符串版本控制
不是提供多个 URI,而是可以通过在追加到 HTTP 请求后面的查询字符串中使用参数来指定资源的版本,例如 https://adventure-works.com/customers/3?version=2。 如果 version 参数被较旧的客户端应用程序省略,则应默认为有意义的值(例如 1)。
此方法具有语义优势(即,同一资源始终从同一 URI 进行检索),但它依赖于代码处理请求以分析查询字符串并发送回相应的 HTTP 响应。 此方法也与 URI 版本控制机制一样,增加了实现 HATEOAS 的复杂性。
某些较旧的 Web 浏览器和 Web 代理不会缓存在 URI 中包含查询字符串的请求的响应。 这可能会对使用 Web API 以及从此类 Web 浏览器运行的 Web 应用的性能产生不利影响。
标头版本控制
不是追加版本号作为查询字符串参数,而是可以实现指示资源的版本的自定义标头。 此方法需要客户端应用程序将相应标头添加到所有请求,虽然如果省略了版本标头,处理客户端请求的代码可以使用默认值(版本 1)。 下面的示例使用了名为 Custom-Header 的自定义标头。 此标头的值指示 Web API 的版本。
版本 1:
GET https://adventure-works.com/customers/3 HTTP/1.1
Custom-Header: api-version=1
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{"id":3,"name":"Contoso LLC","address":"1 Microsoft Way Redmond WA 98053"}
版本 2:
GET https://adventure-works.com/customers/3 HTTP/1.1
Custom-Header: api-version=2
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{"id":3,"name":"Contoso LLC","dateCreated":"2014-09-04T12:11:38.0376089Z","address":{"streetAddress":"1 Microsoft Way","city":"Redmond","state":"WA","zipCode":98053}}
与前面两个方法一样,实现 HATEOAS 需要在任何链接中加入相应的自定义标头。
媒体类型版本控制
如本指南前面所述,当客户端应用程序向 Web 服务器发送 HTTP GET 请求时,它应使用 Accept 标头规定它可以处理的内容的格式。 通常,Accept 标头的用途是允许客户端应用程序指定响应的正文应是 XML、JSON 还是客户端可以分析的其他某种常见格式。 但是,可以定义包括以下信息的自定义媒体类型:该信息使客户端应用程序可以指示它所需的资源版本。
下面的示例演示了将 Accept 标头指定为值 application/vnd.adventure-works.v1+json 的请求。 vnd.adventure-works.v1 元素向 Web 服务器指示它应返回资源的版本 1,而 json 元素则指定响应正文的格式应为 JSON:
GET https://adventure-works.com/customers/3 HTTP/1.1
Accept: application/vnd.adventure-works.v1+json
处理请求的代码负责处理 Accept 标头并尽可能采用该值(客户端应用程序可以在 Accept 标头中指定多种格式,在这种情况下,Web 服务器可以在其中选择最适合的格式用于响应正文)。 Web 服务器使用 Content-Type 标头确认响应正文中的数据格式:
HTTP/1.1 200 OK
Content-Type: application/vnd.adventure-works.v1+json; charset=utf-8
{"id":3,"name":"Contoso LLC","address":"1 Microsoft Way Redmond WA 98053"}
如果 Accept 标头未指定任何已知的媒体类型,则 Web 服务器可以生成 HTTP 406(不可接受)响应消息或返回使用默认媒体类型的消息。
此方法可以说是最纯粹的版本控制机制并自然地适用于 HATEOAS,后者可以在资源链接中包含相关数据的 MIME 类型。
选择版本控制策略时,还应考虑对性能的影响,尤其是在 Web 服务器上缓存时。 URI 版本控制和查询字符串版本控制方案都是缓存友好的,因为同一 URI/查询字符串组合每次都指向相同的数据。
标头版本控制和媒体类型版本控制机制通常需要其他逻辑来检查自定义标头或 Accept 标头中的值。 在大型环境中,使用不同版本的 Web API 的多个客户端可能会在服务器端缓存中生成大量重复数据。 如果客户端应用程序通过实现缓存的代理与 Web 服务器进行通信,并且该代理在当前未在其缓存中保留所请求数据的副本时,仅将请求转发到 Web 服务器,则此问题可能会变得很严重。