Kafka Topic
可以根据业务类型,分发到不同的Topic中,对于每一个Topic,下面可以有多个分区(Partition)日志文件:
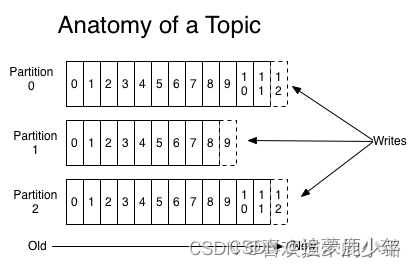
kafka 下的Topic的多个分区,每一个分区实质上就是一个队列,将接收到的消息暂时存储到队列中,根据配置以及消息消费情况来对队列消息删除。
Partition是一个有序的message序列 这些message按顺序添加到一个叫做commit log的文件中。每个partition中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。
每个partition,都对应一个commit log文件。一个partition中的message的offset都是唯一的,但是不同的partition中的message的offset可能是相同的。
可以这么来理解Topic,Partition和Broker
一个topic,代表逻辑上的一个业务数据集,比如按数据库里不同表的数据操作消息区分放入不同topic,订单相关操作消息放入订单topic,用户相关操作消息放入用户topic,
对于大型网站来说,后端数据都是海量的,订单消息很可能是非常巨量的,比如有几百个G甚至达到TB级别,如果把这么多数据都放在一台机器上可定会有容量限制问题,
那么就可以在topic内部划分多个partition来分片存储数据,不同的partition可以位于不同的机器上,每台机器上都运行一个Kafka的进程Broker。
为什么要对Topic下数据进行分区存储?
1、commit log文件会受到所在机器的文件系统大小的限制,分区之后可以将不同的分区放在不同的机器上,相当于对数据做了分布式存储,理论上一个topic可以处理任意数量的数据。
2、为了提高并行度。
消费者消费消息的offset记录机制
每个consumer会定期将自己消费分区的offset提交给kafka内部
topic:__consumer_offsets,提交过去的时候,
key是 consumerGroupId+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的那条数据。
因为__consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发
kafka 日志存储
查看指定topic信息
bin/kafka-topics.sh --describe --bootstrap-server node02:9092 --topic test
 可以进入kafka的数据文件存储目录查看test和test1主题的消息日志文件:默认log目录 /tmp/kafka-logs
可以进入kafka的数据文件存储目录查看test和test1主题的消息日志文件:默认log目录 /tmp/kafka-logs

消息日志文件主要存放在分区文件夹里的以log结尾的日志文件里,如下是test-1主题对应的分区0的消息日志:

kafka一般不会删除消息,不管这些消息有没有被消费。只会根据配置的日志保留时间(log.retention.hours)确认消息多久被删除,
默认保留最近一周的日志消息。kafka的性能与保留的消息数据量大小没有关系,
因此保存大量的数据消息日志信息不会有什么影响。
每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。
在kafka中,消费offset由consumer自己来维护;一般情况下我们按照顺序逐条消费commit log中的消息,
当然我可以通过指定offset来重复消费某些消息,或者跳过某些消息。
这意味kafka中的consumer对集群的影响是非常小的,添加一个或者减少一个consumer,
对于集群或者其他consumer来说,都是没有影响的,因为每个consumer维护各自的消费offset。
Kafka 一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名,消息在分区内是分段(segment)存储,
每个段的消息都存储在不一样的log文件里,这种特性方便old segment file快速被删除,kafka规定了一个段位的 log 文件最大为 1G,做这个限制目的是为了方便把 log 文件加载到内存去操作:
部分消息的offset索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的offset到index文件,
如果要定位消息的offset会先在这个文件里快速定位,再去log文件里找具体消息
00000000000009936472.index
消息存储文件,主要存offset和消息体
00000000000009936472.log
消息的发送时间索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的发送时间戳与对应的offset到timeindex文件,
如果需要按照时间来定位消息的offset,,会先在这个文件里查找
00000000000009936472.timeindex
这个 9936472 之类的数字,就是代表了这个日志段文件里包含的起始 Offset,也就说明这个分区里至少都写入了接近1000 万条数据了。
Kafka Broker 有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是 1GB。
一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做 log rolling,正在被写入的那个日志段文件,叫做 active log segment。
![[附源码]Python计算机毕业设计SSM京东仓库管理系统(程序+LW)](https://img-blog.csdnimg.cn/aa49a5f11b6948019058efb0e08a8fa4.png)
![[附源码]计算机毕业设计项目管理系统的专家评审模块Springboot程序](https://img-blog.csdnimg.cn/d266f6148348495b993f0af70e5ee15b.png)






![[附源码]计算机毕业设计基于JEE平台springboot技术的订餐系统](https://img-blog.csdnimg.cn/166403baafb045a7aedace45343646e1.png)

![[附源码]计算机毕业设计校园快递柜存取件系统Springboot程序](https://img-blog.csdnimg.cn/98f0e35461144c96bc4dfc10e1b9cd4c.png)