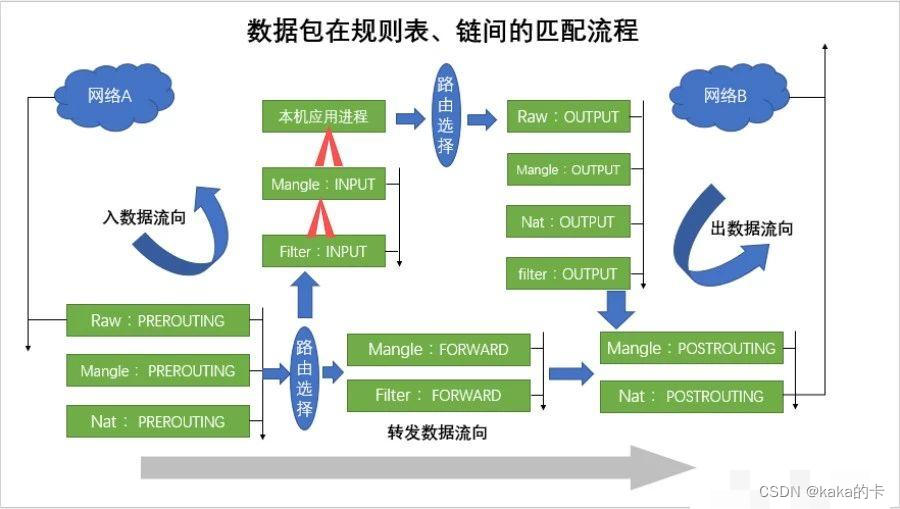
爬虫基础知识 1、爬虫简介: 爬虫的作用:帮助我们把网站信息快速提取并保存 爬虫的分类: 通用爬虫 聚集爬虫 爬虫的安全知识:目前来说,无明确法律规定,但每个官网都有自己的爬虫协议(网址后面加/robots.txt) 爬虫的爬取流程: 1、获取网页 2、提取信息 3、保存数据 2、爬虫必须了解的前端基础: HTML是超文本标记语言,主要负责写网页内容,CSS是用来装饰网页的,JS是用来写网页逻辑的。 HTML中有两类标签: 1、一般标签:在标签内可以添加属性,在标签之间可以写其他标签或内容,如:h1标签 2、自闭合标签:只有一个标签,只能在标签内加属性,如:img标签 网页分类:静态网页(数据内容一般在HTML中),动态网页(通过js使网页连接数据库) 谷歌浏览器的“开发者工具”无疑是最方便的打开方式:打开谷歌浏览器,右击选择检查 谷歌浏览器查看网页源代码也非常方便:如上,右击选择查