文章目录
- 摘要
- 安装MMPose
- 安装虚拟环境
- 安装pytorch
- 安装MMCV
- 安装其他的安装包
- 下载 MMPose
- 下载预训练模型权重文件和视频素材
- 安装MMDetection
- 安装Pytorch
- 安装MMCV
- 安装其它工具包
- 下载 MMDetection
- 安装MMDetection
- 下载预训练模型权重文件和视频素材
- MMPose预训练模型预测
- 命令行的方式
- 代码的方式
摘要
今天,学习RTMPose关键点检测实战。教大家如何安装安装MMDetection和MMPose。
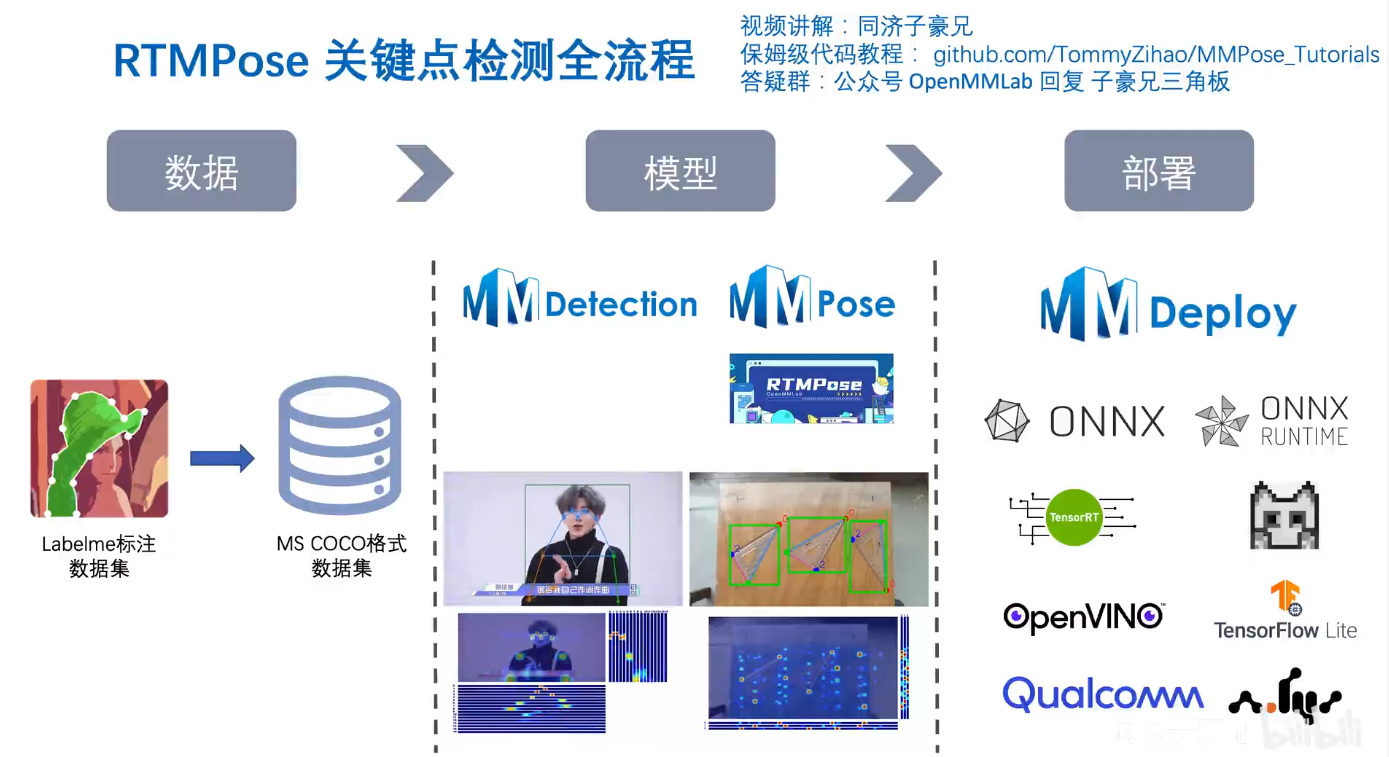
实战项目以三角板关键点检测场景为例,结合OpenMMLab开源目标检测算法库MMDetection、开源关键点检测算法库MMPose、开源模型部署算法库MMDeploy,全面讲解项目全流程:
-
数据集:Labelme标注数据集、整理标注格式至MS COCO
-
目标检测:分别训练Faster R CNN和RTMDet-Tiny目标检测模型、训练日志可视化、测试集评估、对图像、摄像头画面预测
-
关键点检测:训练RTMPose-S关键点检测模型、训练日志可视化、测试集上评估、分别对“图像、视频、摄像头画面”预测
-
模型终端部署:转ONNX格式,终端推理
视频链接:
1、安装MMDetection和MMPose:https://www.bilibili.com/video/BV1Pa4y1g7N7
2、MMDetection三角板目标检测:https://www.bilibili.com/video/BV1Lm4y1879K
3、MMPose、RTMPose三角板关键点检测:https://www.bilibili.com/video/BV12a4y1u7sd
讲师是张子豪 OpenMMLab算法工程师。
保姆级代码教程: github.com/TommyZihao/MMPose_Tutorials。
教程讲的非常详细。
没想到,子豪兄也是小黑子。
安装MMPose
安装虚拟环境
教程没有新建虚拟环境,我建议大家安装的时候,新建虚拟环境,执行命令:
conda create --name mymm python=3.7
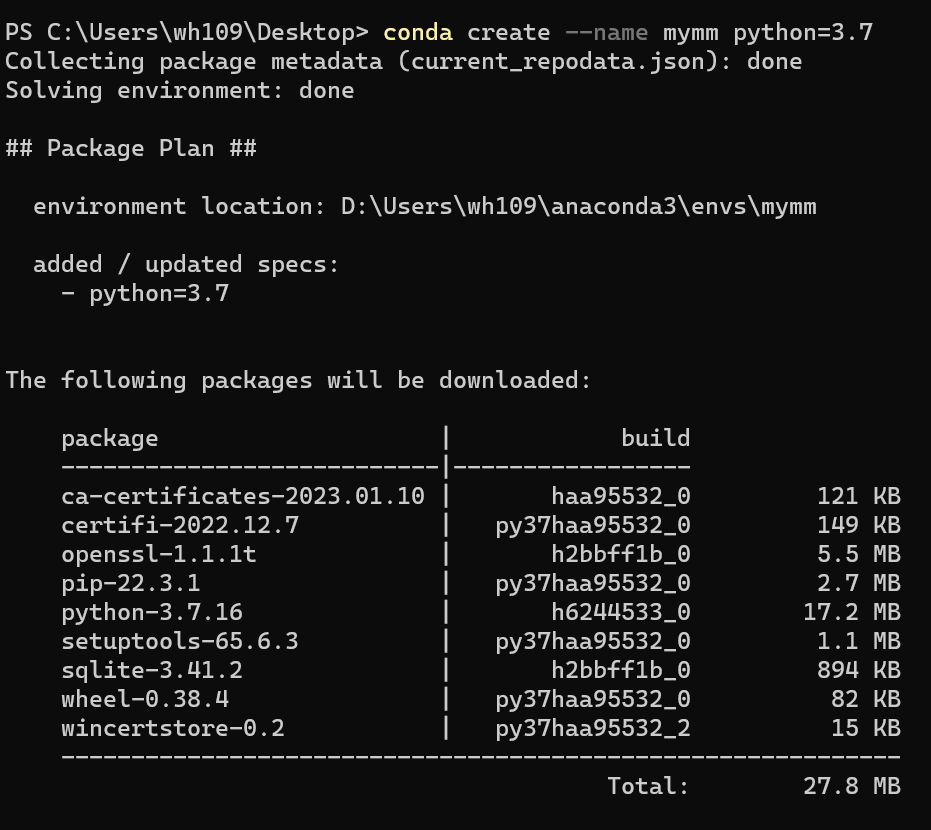
然后,会安装一些必要的安装包。等待安装完成即可。
安装完成后,激活虚拟环境,执行命令:
ubuntu执行命令:
conda activate mymm
Windows环境执行命令:
activate mymm
如果是Windows环境,无法激活虚拟环境参考:
https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/120514255
安装pytorch
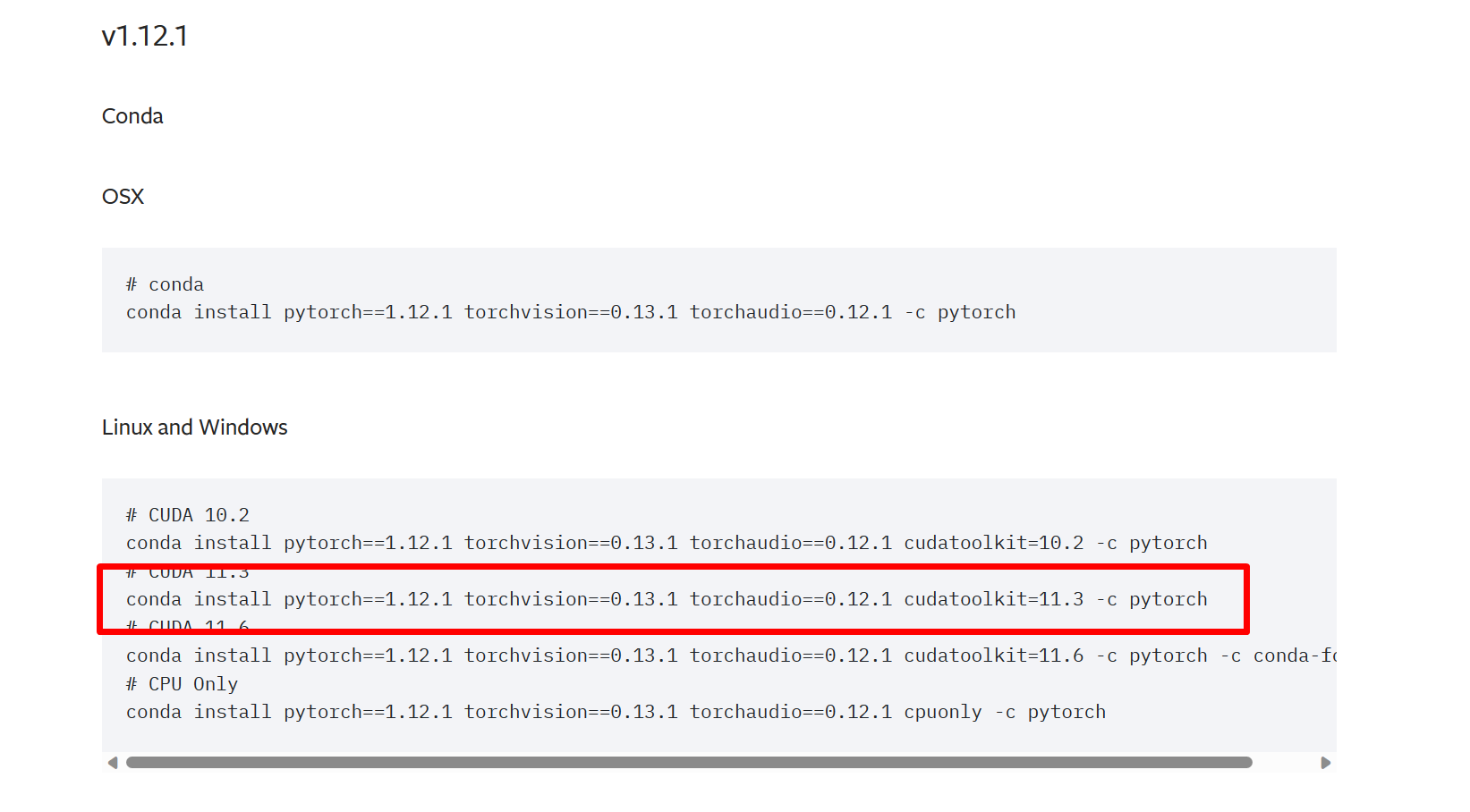
安装pytorch,要结合自己的硬件和Cuda版本。比如我的CUDA版本是11.3的,需要寻找支持11.3版本的pytorch。
打开网站:https://pytorch.org/,选择历史版本。
V1.12.1版本有11.3的版本,就选他了。
执行命令:
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch

安装MMCV
使用openmim安装mmengine、mmcv和mmdet,执行命令:
pip install -U openmim
mim install mmengine
mim install 'mmcv==2.0.0rc3'
mim install "mmdet>=3.0.0rc6"
安装其他的安装包
pip install opencv-python pillow matplotlib seaborn tqdm pycocotools -i https://pypi.tuna.tsinghua.edu.cn/simple
下载 MMPose
使用git下载MMPose代码,Windows需要单独安装git命令,链接:https://git-scm.com/download/win。
安装完成后执行Git命令:
git clone https://github.com/open-mmlab/mmpose.git -b tutorial2023
下载代码。
然后使用Pycharm打开。
安装必要的包,执行命令:
mim install -e .
检查环境配置,首先检查pytorch,执行代码:
# 检查 Pytorch
import torch, torchvision
print('Pytorch 版本', torch.__version__)
print('CUDA 是否可用',torch.cuda.is_available())
检查mmcv:
# 检查 mmcv
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
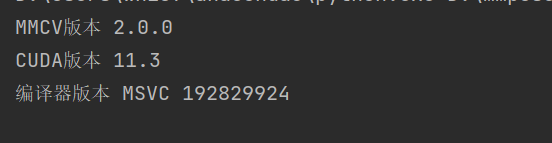
print('MMCV版本', mmcv.__version__)
print('CUDA版本', get_compiling_cuda_version())
print('编译器版本', get_compiler_version())
检查mmpose:
# 检查 mmpose
import mmpose
print('mmpose版本', mmpose.__version__)
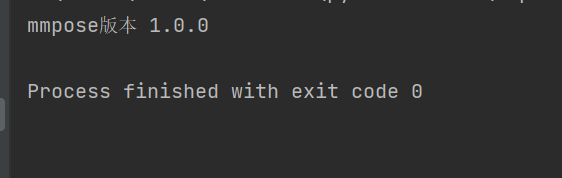
一切OK!!!
下载预训练模型权重文件和视频素材
创建文件夹,执行代码:
import os
# 创建 checkpoint 文件夹,用于存放预训练模型权重文件
os.mkdir('checkpoint')
# 创建 outputs 文件夹,用于存放预测结果
os.mkdir('outputs')
# 创建 data 文件夹,用于存放图片和视频素材
os.mkdir('data')
os.mkdir('data/test')
然后下载素材:
# 多人图片,来源:https://www.pexels.com/zh-cn/photo/2168292/
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220610-mmpose/images/multi-person.jpeg -O data/test/multi-person.jpeg
# 单人视频-唱跳篮球
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220610-mmpose/videos/cxk.mp4 -P data/test
# 妈妈和女儿跳舞,经微信压缩
!wget https://zihao-openmmlab.obs.myhuaweicloud.com/20220610-mmpose/videos/mother_wx.mp4 -P data/test
# 两个女生跳舞视频,来源:https://mixkit.co/free-stock-video/two-girls-having-fun-in-a-retro-restaurant-42298/
!wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220610-mmpose/videos/two-girls.mp4 -O data/test/two-girls.mp4
安装MMDetection
安装Pytorch
同上
安装MMCV
同上
安装其它工具包
同上
下载 MMDetection
git clone https://github.com/open-mmlab/mmdetection.git -b 3.x

安装MMDetection
进入MMDetection的根目录,执行命令:
pip install -v -e .
安装MMDetection。
检查,pytorch,代码如下:
# 检查 Pytorch
import torch, torchvision
print('Pytorch 版本', torch.__version__)
print('CUDA 是否可用',torch.cuda.is_available())
检查MMCV,代码如下:
# 检查 mmcv
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
print('MMCV版本', mmcv.__version__)
print('CUDA版本', get_compiling_cuda_version())
print('编译器版本', get_compiler_version())
检查MMDetection,代码如下:
# 检查 mmpose
import mmdet
print('mmdetection版本', mmdet.__version__)
下载预训练模型权重文件和视频素材
import os
# 创建 checkpoint 文件夹,用于存放预训练模型权重文件
os.mkdir('checkpoint')
# 创建 outputs 文件夹,用于存放预测结果
os.mkdir('outputs')
# 创建 data 文件夹,用于存放图片和视频素材
os.mkdir('data')
MMPose预训练模型预测
命令行的方式
HRNet预测单张图像
python demo/topdown_demo_with_mmdet.py \
demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py \
https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth \
--input data/test/multi-person.jpeg \
--output-root outputs/B1_HRNet_1 \
--device cuda:0 \
--bbox-thr 0.5 \
--kpt-thr 0.2 \
--nms-thr 0.3 \
--radius 8 \
--thickness 4 \
--draw-bbox \
--draw-heatmap \
--show-kpt-idx
RTMPose预测单张图像
python demo/topdown_demo_with_mmdet.py \
demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py \
https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth \
--input data/test/multi-person.jpeg \
--output-root outputs/B1_RTM_1 \
--device cuda:0 \
--bbox-thr 0.5 \
--kpt-thr 0.5 \
--nms-thr 0.3 \
--radius 8 \
--thickness 4 \
--draw-bbox \
--draw-heatmap \
--show-kpt-idx
预测视频:直接将–input换成视频路径即可
python demo/topdown_demo_with_mmdet.py \
demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py \
https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth \
configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py \
https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth \
--input data/test/mother_wx.mp4 \
--output-root outputs/B1_HRNet_2 \
--device cuda:0 \
--bbox-thr 0.5 \
--kpt-thr 0.2 \
--nms-thr 0.3 \
--radius 5 \
--thickness 2 \
--draw-bbox \
--draw-heatmap \
--show-kpt-idx
代码的方式
在MMPose的根目录,新建test.py,运行下面的代码:
import cv2
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import torch
import mmcv
from mmcv import imread
import mmengine
from mmengine.registry import init_default_scope
from mmpose.apis import inference_topdown
from mmpose.apis import init_model as init_pose_estimator
from mmpose.evaluation.functional import nms
from mmpose.registry import VISUALIZERS
from mmpose.structures import merge_data_samples
from mmdet.apis import inference_detector, init_detector
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
img_path = 'data/test/multi-person.jpeg'
# Faster R CNN
detector = init_detector(
'demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py',
'https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth',
device=device
)
pose_estimator = init_pose_estimator(
'configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-256x192.py',
'https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth',
device=device,
cfg_options={'model': {'test_cfg': {'output_heatmaps': True}}}
)
init_default_scope(detector.cfg.get('default_scope', 'mmdet'))
# 获取目标检测预测结果
detect_result = inference_detector(detector, img_path)
print(detect_result.keys())
# 预测类别
print(detect_result.pred_instances.labels)
# 置信度
print(detect_result.pred_instances.scores)
# 置信度阈值
CONF_THRES = 0.5
pred_instance = detect_result.pred_instances.cpu().numpy()
bboxes = np.concatenate((pred_instance.bboxes, pred_instance.scores[:, None]), axis=1)
bboxes = bboxes[np.logical_and(pred_instance.labels == 0, pred_instance.scores > CONF_THRES)]
bboxes = bboxes[nms(bboxes, 0.3)][:, :4]
print(bboxes)
# 获取每个 bbox 的关键点预测结果
pose_results = inference_topdown(pose_estimator, img_path, bboxes)
print(len(pose_results))
# 把多个bbox的pose结果打包到一起
data_samples = merge_data_samples(pose_results)
print(data_samples.keys())
# 每个人 17个关键点 坐标
print(data_samples.pred_instances.keypoints.shape)
# 索引为 0 的人,每个关键点的坐标
print(data_samples.pred_instances.keypoints[0,:,:])
# 每一类关键点的预测热力图
print(data_samples.pred_fields.heatmaps.shape)
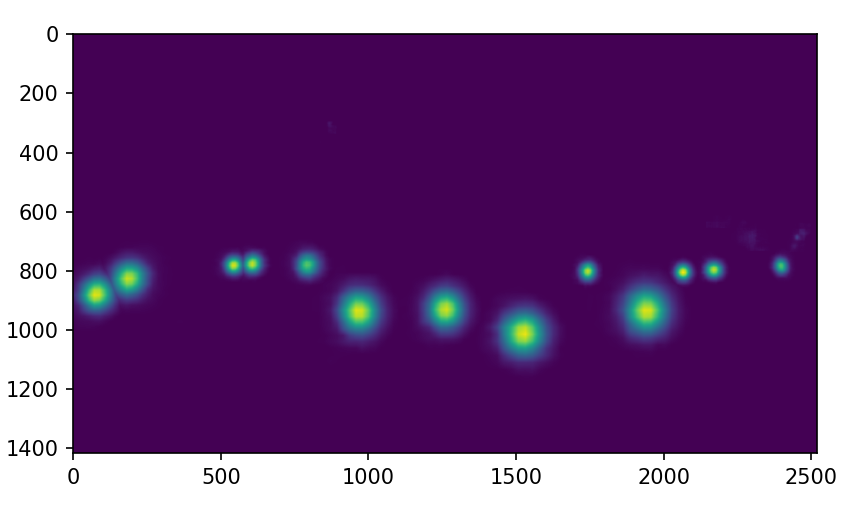
idx_point = 13
heatmap = data_samples.pred_fields.heatmaps[idx_point,:,:]
print(heatmap.shape)
# 索引为 idx 的关键点,在全图上的预测热力图
plt.imshow(heatmap)
plt.show()
# 半径
pose_estimator.cfg.visualizer.radius = 10
# 线宽
pose_estimator.cfg.visualizer.line_width = 8
visualizer = VISUALIZERS.build(pose_estimator.cfg.visualizer)
# 元数据
visualizer.set_dataset_meta(pose_estimator.dataset_meta)
img = mmcv.imread(img_path)
img = mmcv.imconvert(img, 'bgr', 'rgb')
img_output = visualizer.add_datasample(
'result',
img,
data_sample=data_samples,
draw_gt=False,
draw_heatmap=True,
draw_bbox=True,
show_kpt_idx=True,
show=False,
wait_time=0,
out_file='outputs/B2.jpg'
)
print(img_output.shape)
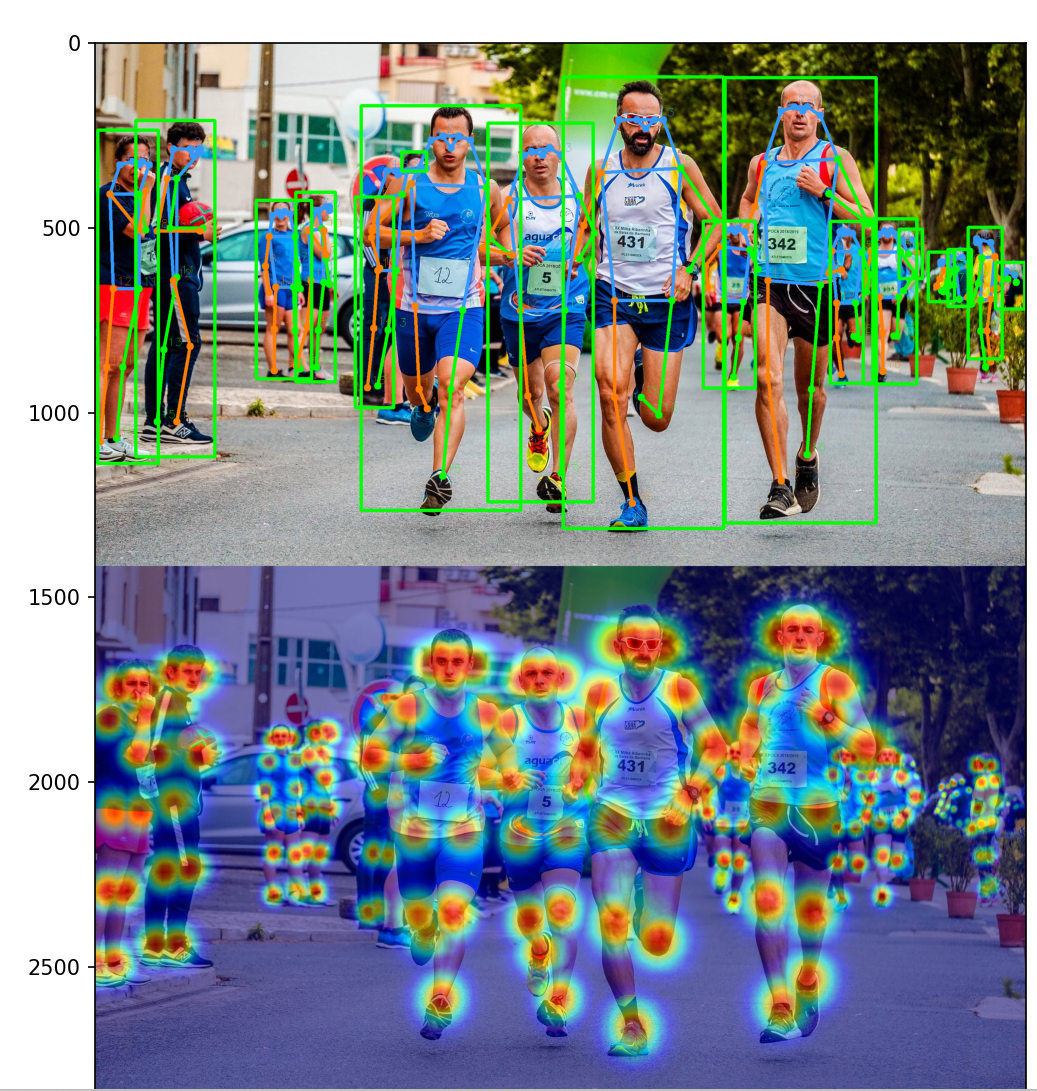
plt.figure(figsize=(10,10))
plt.imshow(img_output)
plt.show()
中间运行结果:
热力图:
展示可视化效果: