今天同事反馈有个topic出现积压。于是上kfk管理平台查看该topic对应的group。发现6个分区中有2个不消费,另外4个消费也较慢,总体lag在增长。查看服务器日志,日志中有rebalance 12 retry 。。。Exception,之后改消费线程停止。
查阅相关rebalance资料:
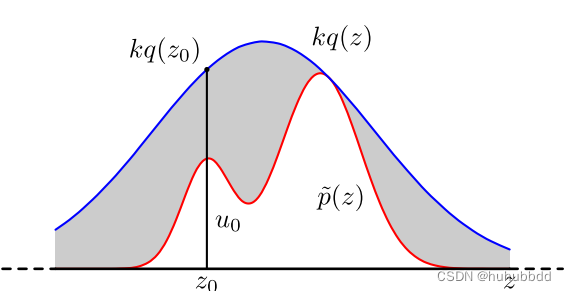
分析Rebalance 可能是 Consumer 消费时间过长导致的,导致消费者被踢。
如何避免不必要的Rebalance
除开consumer正常的添加和停掉导致rebalance外,在某些情况下,Consumer 实例会被 Coordinator 错误地认为 “已停止” 从而被“踢出”Group,导致rebalance,这种情况应该避免。
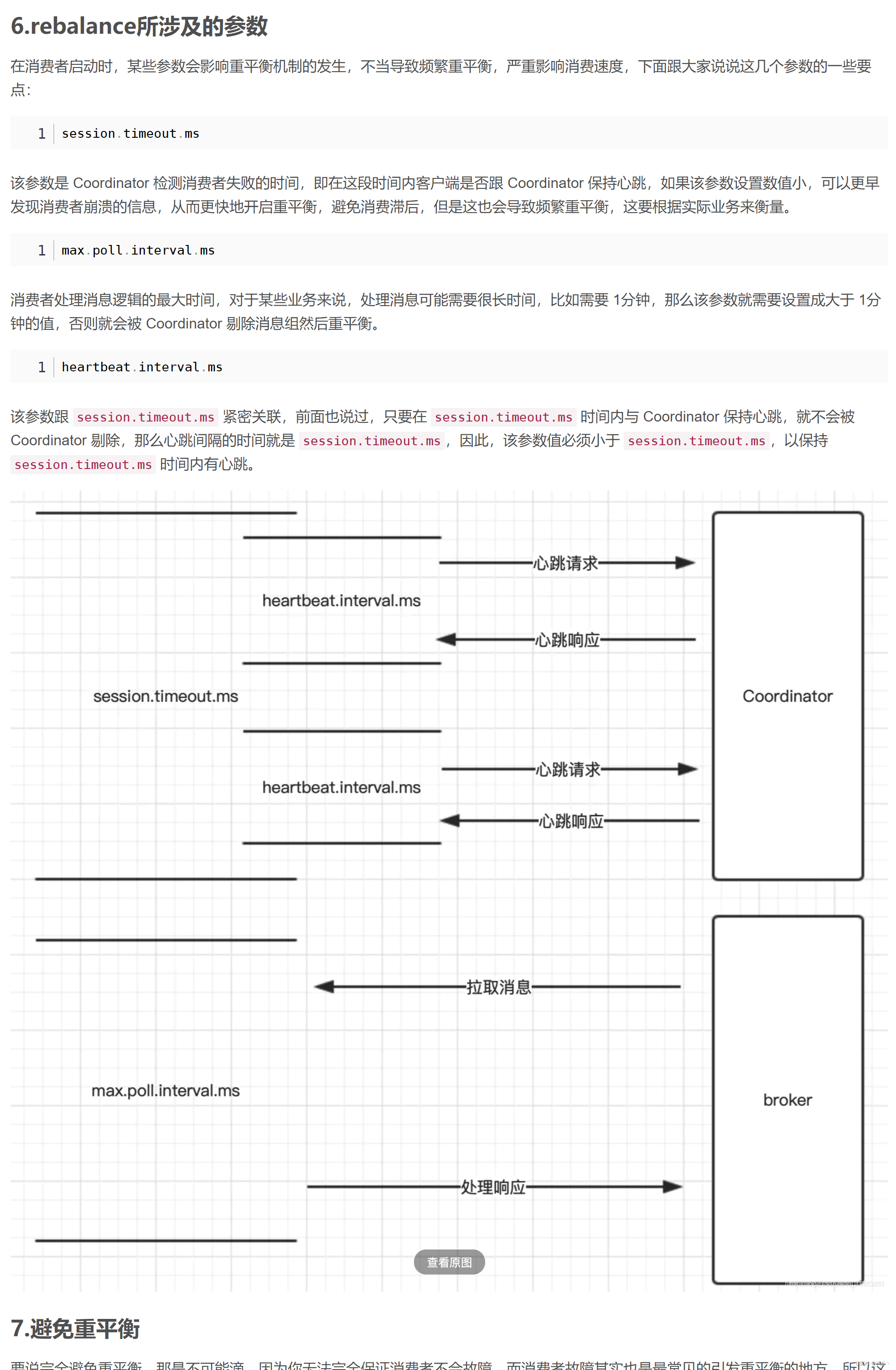
第一类非必要 Rebalance 是因为未能及时发送心跳,导致 Consumer 被 “踢出”Group 而引发的。这种情况下我们可以设置 session.timeout.ms 和 heartbeat.interval.ms 的值,来尽量避免rebalance的出现。(以下的配置是在网上找到的最佳实践,暂时还没测试过)
设置 session.timeout.ms = 6s。
设置 heartbeat.interval.ms = 2s。
要保证 Consumer 实例在被判定为 “dead” 之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。
将 session.timeout.ms 设置成 6s 主要是为了让 Coordinator 能够更快地定位已经挂掉的 Consumer,早日把它们踢出 Group。
第二类非必要 Rebalance 是 Consumer 消费时间过长导致的。此时,max.poll.interval.ms 参数值的设置显得尤为关键。如果要避免非预期的 Rebalance,你最好将该参数值设置得大一点,比你的下游最大处理时间稍长一点。
于是分析代码,将每个处理逻辑加上耗时日志,分析发现又是hbase写入耗时达到3秒。于是将hbase写入开关关闭。重新运行后,消费正常。





![[LsSDK][tool] ls_syscfg_gui2.0](https://img-blog.csdnimg.cn/fcf71920d747482b96b9c2b9ffa11d55.png)