前言
压缩列表的最大特点,就是它是一种内存紧凑型的数据结构,占用一块连续的内存空间,而且还会根据数据类型的不同,选择不同的编码方式来节省内存。
压缩列表的缺点也很明显
- 它查询节点只能一个一个查,所以时间复杂度是O(n)。不能存放过多的节点,查询效率会变低。
- 修改/新增数据时,需要重新计算压缩列表空间,并且可能会导致连锁更新问题。
什么是压缩列表
它不同于其他的数据结构,我在Redis甚至看不到它的结构体定义,因为它本身就是一块连续的内存地址。找到它的new函数看看
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
其中,它的常量定义如下
//ziplist的列表头大小,包括2个32 bits整数和1个16bits整数,分别表示压缩列表的总字节数,列表最后一个元素的离列表头的偏移,以及列表中的元素个数
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
//ziplist的列表尾大小,包括1个8 bits整数,表示列表结束。
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
//ziplist的列表尾字节内容
#define ZIP_END 255

| 属性 | 类型 | 长度 | 作用 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 记录整个压缩列表大小 |
| zltail | uint32_t | 4字节 | 记录压缩列表尾部偏移量 |
| zllen | uint16_t | 2字节 | entry个数,最大uint16_max(65534),超过则记录65534。真实需要遍历整个压缩列表才能得到。 |
| entry | 不定 | 不定 | 保存数据 |
| zlend | uint8_t | 1字节 | 0xFF(255)特殊字符,表示列表结束 |
Entry定义

所以整个压缩列表的定义可以是这样
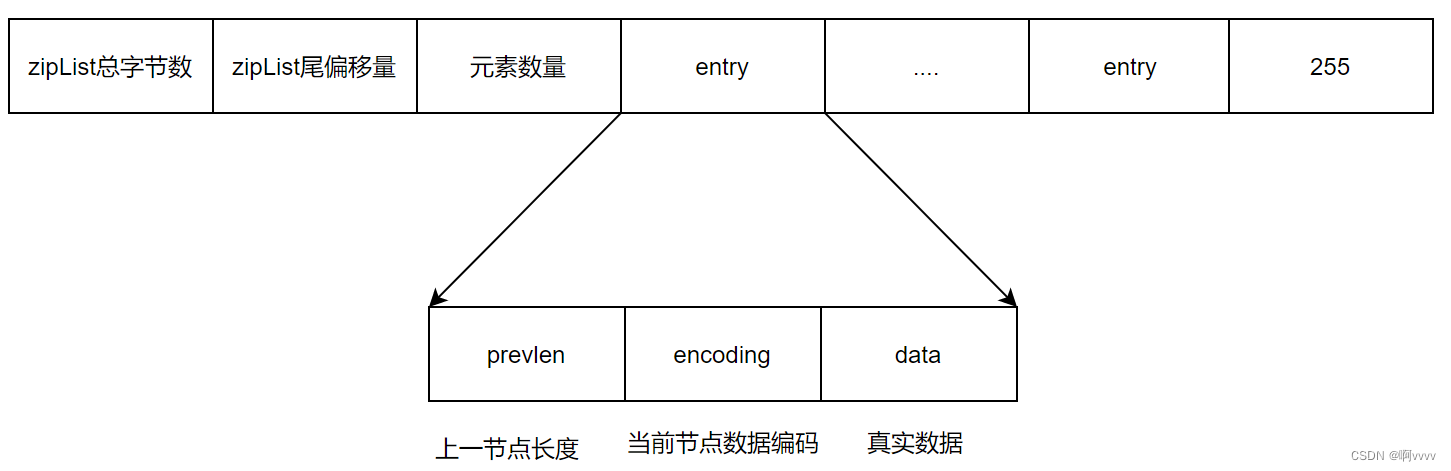
Entry与普通链表节点的区别
普通链表需要记录两个指针,一个 *pre,一个 *next,这样就需要耗费16个字节,而Entry仅仅记录了上一个节点的字节长度、
prevlen:上一节点长度,1字节或5字节
- 前一个节点长度小于254字节,那当前prevlen需要用1个字节来保存长度值
- 前一个节点长度大于254字节,那当前prevlen需要用5个字节来保存长度值
encoding:字符串还是整数,1、2字节或5字节
data:保存真实数据
而为了方便查找,每个列表项中都会记录前一项的长度。因为每个列表项的长度不一样,所以如果使用相同的字节大小来记录 prevlen,就会造成内存空间浪费。
举个例子,假设我们统一使用 4 字节记录 prevlen,如果前一个列表项只是一个字符串“redis”,长度为 5 个字节,那么我们用 1 个字节(8 bits)就能表示 256 字节长度(2 的 8 次方等于 256)的字符串了。此时,prevlen 用 4 字节记录,其中就有 3 字节是浪费掉了。
好,我们再回过头来看,ziplist 在对 prevlen 编码时,会先调用 zipStorePrevEntryLength 函数,用于判断前一个列表项是否小于 254 字节。如果是的话,那么 prevlen 就使用 1 字节表示;否则,zipStorePrevEntryLength 函数就调用 zipStorePrevEntryLengthLarge 函数进一步编码。这部分代码如下所示:
//判断prevlen的长度是否小于ZIP_BIG_PREVLEN,ZIP_BIG_PREVLEN等于254
if (len < ZIP_BIG_PREVLEN) {
//如果小于254字节,那么返回prevlen为1字节
p[0] = len;
return 1;
} else {
//否则,调用zipStorePrevEntryLengthLarge进行编码
return zipStorePrevEntryLengthLarge(p,len);
}
也就是说,zipStorePrevEntryLengthLarge 函数会先将 prevlen 的第 1 字节设置为 254,然后使用内存拷贝函数 memcpy,将前一个列表项的长度值拷贝至 prevlen 的第 2 至第 5 字节。最后,zipStorePrevEntryLengthLarge 函数返回 prevlen 的大小,为 5 字节。
if (p != NULL) {
//将prevlen的第1字节设置为ZIP_BIG_PREVLEN,即254
p[0] = ZIP_BIG_PREVLEN;
//将前一个列表项的长度值拷贝至prevlen的第2至第5字节,其中sizeof(len)的值为4
memcpy(p+1,&len,sizeof(len));
…
}
//返回prevlen的大小,为5字节
return 1+sizeof(len);
encoding 编码
一个列表项的实际数据,既可以是整数也可以是字符串。整数可以是 16、32、64 等字节长度,同时字符串的长度也可以大小不一。
所以,ziplist 在 zipStoreEntryEncoding 函数中,针对整数和字符串,就分别使用了不同字节长度的编码结果。下面的代码展示了 zipStoreEntryEncoding 函数的部分代码,你可以看到当数据是不同长度字符串或是整数时,编码结果的长度 len 大小不同。
//默认编码结果是1字节
unsigned char len = 1;
//如果是字符串数据
if (ZIP_IS_STR(encoding)) {
//字符串长度小于等于63字节(16进制为0x3f)
if (rawlen <= 0x3f) {
//默认编码结果是1字节
…
}
//字符串长度小于等于16383字节(16进制为0x3fff)
else if (rawlen <= 0x3fff) {
//编码结果是2字节
len += 1;
…
}
//字符串长度大于16383字节
else {
//编码结果是5字节
len += 4;
…
}
} else {
/* 如果数据是整数,编码结果是1字节*/
if (!p) return len;
...
}
简而言之,针对不同长度的数据,使用不同大小的元数据信息(prevlen 和 encoding),这种方法可以有效地节省内存开销。
连锁更新问题
在压缩列表的节点中
prevlen:上一节点长度,1字节或5字节
- 前一个节点长度小于254字节,那当前prevlen需要用1个字节来保存长度值
- 前一个节点长度大于254字节,那当前prevlen需要用5个字节来保存长度值
举个极端例子,不过可能性也是非常小
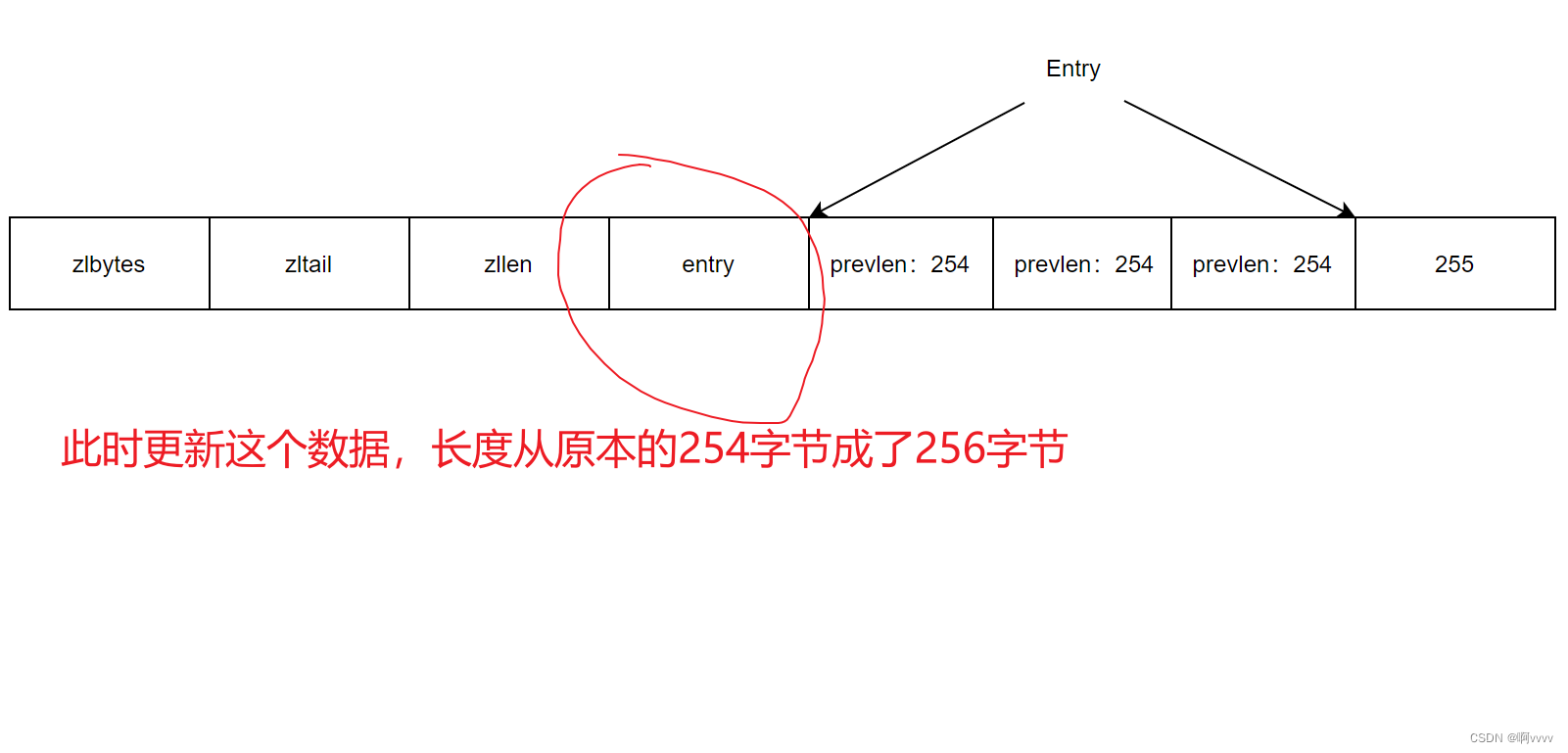
这个地方更新,后一个节点本身长度也已经是254,现在从prevlen从1字节修改成5字节,整个节点又超出254,又需要更新。此时就出现了连锁更新问题。
小结
- 压缩列表可以看做是特殊的“双向链表”。因为保存了头尾节点偏移地址。
- 压缩列表不通过指针存储,而是直接采用一块连续的内存地址,并且不同大小的数据采用不同的编码方式,内存占用少。
- 压缩列表不能存储太多数据,因为它查找数据的速度是O(n)。
- 压缩列表存在连锁更新问题,只要节点不是特别多,开销是能接受的。