ZipList:压缩列表,为了节省内存而设计的一种数据结构
ZipList是一种特殊的双端链表,是由一系列的特殊编码的连续内存块组成,不需要通过指针来进行寻址来找到各个节点,可以在任意一端进行压入或者是弹出操作,并且该操作的时间复杂度是O(1);
dict底层是依靠依靠哈希表来实现的,虽然查询性能比较高,但是一个指针要占用8个字节,大量使用指针寻址(因为内存不连续,要通过指针寻址)会浪费内存,况且这种链式存储方式极其容易产生内存碎片;
因为在压缩列表中,存放不同的数据所占用的内存是不一样的,Entry值越大,占用字节数越大在ZipList中,Entry并不像普通链表一样进行记录前后点的指针,因为每记录两个指针要占用16个字节,浪费内存,而是使用了下面的结构
1)previous_entry_length:前一个结点的长度,占用1个字节或者是5个字节
1.1)如果前一个结点的长度小于254个字节,那么就采用1个字节来保存这个长度值;
1.2)如果前一个结点的长度大于254个字节,那么就采用5个字节来保存这个长度的值,第一个字节是OXFE,后四个字节才是真实的长度数据;
2)encoding:编码属性,记录content的数据类型字符串还是整数以及长度,Encoding本身的长度占用1个,2个或者是5个字节,况且只是存在这两个值;


ZipListEntry中的encoding编码分为字符串和整数两种
1)字符串:如果Encoding是以00或者01或者是10来进行开头的那么证明content是字符串类型,下面的p和q是用来记录字符串的长度的;
假设现在要保存"ab"和"bc"这两个字符串
第一部分是表示前一个字符串的长度,第二部分是表示采用00编码,并且所存储的字符串长度是2,第三部分是实际存储的字符串的ASCIL值;
下面是使用16进制编码的形式来进行存储
整个压缩列表的结构:
2)整数:如果encoding是以11开头,那么就证明content是整数,况且encoding固定只是使用1个字节,因为整数值长度固定,来记录四种字节数,就不需要记录长度了
3)1111是结束标识,显然最后一种编码形式不能使用,0000和1110在其他编码中已经使用了,所以范围就是0001-1101,就是0-12
假设我们现在所进行存储的两个整数值是2和5,那么ZipList就会直接将这两个值保存到Encoding中,就不需要0-12了







ZipList的连锁更新问题:
现在假设我们有N个连续的,长度在250-253个字节之间的Entry,因此Entry的previous_entry_length属性用一个字节就可以进行表示:
现在有一个长度是254的entry插入到了这个ZipList的头节点,此时原第一个的previous_entry_length的长度就会发生变化,不得不采用5个字节来进行表示,后面就会产生多个Entry的previous_entry_length发生变化,本来是一段连续的内存空间,如果原来的第一个节点要多申请4个字节,所有的数据都会发生迁移,如果原有的内存空间不够还会发生扩容,新增空间,会频繁的进行内存申请,数据迁移的动作
ZipList这种特殊情况下产生的来纳许多次空间扩展操作称之为是连锁更新,新增和删除操作都有可能会出现连锁更新的情况


ZipList的特性:
1)压缩列表的可以看作是一种连续内存空间的双向链表,连续内存空间不大还好,但是如果你申请的是较大的连续内存空间,再去申请内存就比较麻烦了,因为内存往往是碎片化的,如果你想要申请一大块的连续内存,往往是比较困难的,所以ZipList不能存放过多的数据
2)列表的节点之间不是通过指针连接,而是记录上一个节点和本节点长度进行寻址,内存的占用比较低
3)如果列表中的数据过多,可能会导致链表过长,可能会影响查询性能
4)增或者删较大数据的时候可能会发生previous_entry_length连续更新问题
QuickList介绍:内存占用比较少
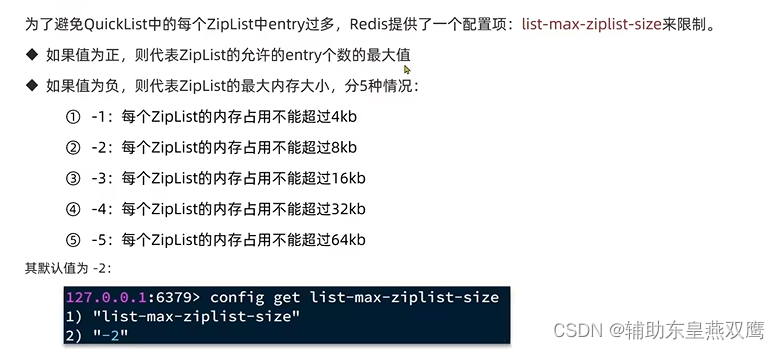
问题1:ZipList虽然节省内存,但是申请的内存必须是连续的内存空间,如果内存占用过高导致内存的申请效率比较低怎么办?
为了缓解这个问题可以创建多个ZipList来分片存储数据
问题2:但是要创建和存储大量数据,超过了ZipList的最佳上限怎么办?
可以创建多个ZipList来进行分片存储数据
问题3:数据拆分后比较分散,不方便进行管理和查找,这多个ZipList之间该如何建立联系?
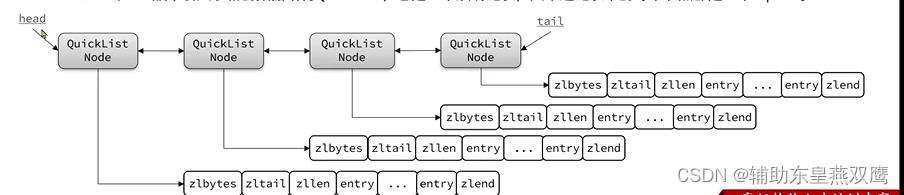
Redis在3.2版本之后引入了新的数据结构QuickList,他是一个双端链表,只不过是链表中的每一个节点都是一个ZipList
进行读取ZipList的时候做解压缩,进行存储ZipList的时候会做压缩
总结:QuickList
1)QuickList本身是一个节点是ZipList的双端链表
2)节点是采用ZipList,解决了传统链表的内存占用问题,但是ZipList不建议存储节点过多,因为会产生连续内存空间申请效率变低
3)所以为了解决上述问题,Redis就控制了ZipList的大小,解决了连续申请内存空间效率较低的问题
4)中间节点可以进行压缩,可以节省内存空间
5)虽然QuickList和ZipList都很节省内存空间,但是对于遍历元素来说还是比较麻烦的,因为他们遍历元素的时间复杂度都是O(N)


SkipList
SkipList底层的实现是依据跳表来实现的,他和传统的链表是具有一定差异的
1)元素按照升序排列进行存储
2)节点可能包含着多个指针,指针的跨度不同
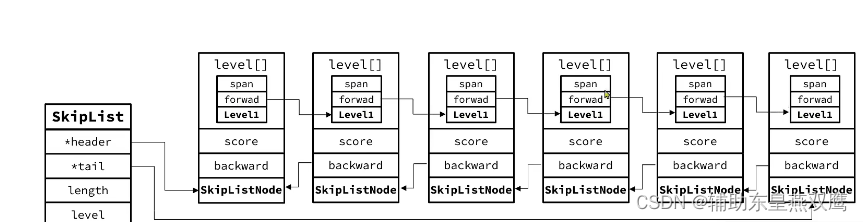
1)level:链表越长,可能level的层级也是大的,如果链表越短,可能level的层级也是越短的,将来进行查询的时候,肯定是从层级最高的索引向下进行查询的;
2)在一个节点中,score是存放着对应的值,而SDS是节点所进行存储的字符串
3)在一个节点的结构体中,存在着一个level数组,里面存放的是这个数组包含了多少级指针,以及每一个对应的指针的跨度,这个数组可能包含一个元素,就是指是存在着一级指针,也有可能存在着多个元素,但是至少要存在一个一级指针;
4)当数组从后向前进行查找的时候,只是通过backward指针从后向前进行遍历;
但是从head向tail进行遍历的时候就可以通过level的多级指针来进行查找;
5)链表越长,指针层级也就越多,进行查找元素也是十分方便
下面是所有节点都是一级指针的结构:
下面是部分节点包括二级指针的结构:
下面是部分节点包括三级指针的结构:



SkipList的特点:
1)跳表是一个双向链表,每一个节点都包含着score值和ele值,score值是得分,将来要依靠score值来进行排序,ele就是节点中要保存的一个数据,本质上是一个SDS字符串
2)节点会按照score值做升序排序,score值相同那么按照ele字典进行排序
3)每一个节点都可以包含多级指针,层数是1-32之间的随机数
4)在一个节点中,不同的层级指针到下一个结点的跨度是不相同的,层级越高跨度就越大
5)增删改查效率和红黑树基本一致,实现起来确实更简单
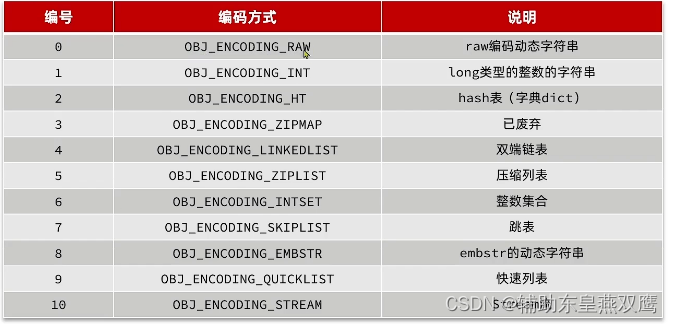
RedisObject:不包括指针指向的内存空间,至少占有40个字节
Redis任意的数据类型的键和值都会被封装成一个RedisObject,也叫做Redis对象,源码如下
并不推荐经常使用String类型,因为挺浪费内存空间的,假设现在有10个字符串都使用String类型进行存储,那么至少需要10个RedisObject来存储String类型的头信息,于是就被浪费掉了400个字节,而在同等情况下如果使用List数据结构,那么RedisObject的个数就会大量地减少
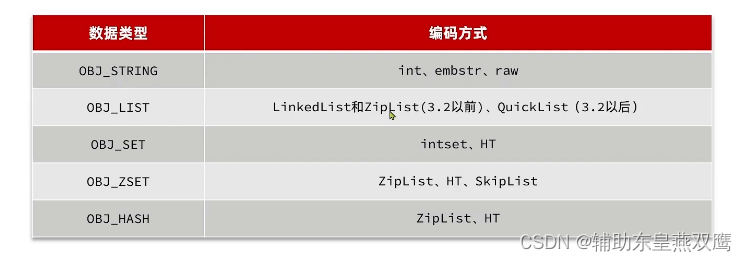
Redis会根据所存储的数据结构的不同会选择不同的编码方式,一共有11种类型