层次多尺度注意力用于语义分割
HIERARCHICAL MULTI-SCALE ATTENTION FOR SEMANTIC SEGMENTATION
https://arxiv.org/pdf/2005.10821.pdf
摘要
多尺度推断通常用于提高语义分割的结果。多个图像尺度通过网络传递,然后使用平均或最大池化方法将结果组合起来。在本文中,我们提出了一种基于注意力的方法来结合多尺度预测。我们表明,在某些尺度上的预测能够更好地解决特定的失败模式,并且网络学习在这些情况下偏向于选择这些尺度以生成更好的预测。我们的注意机制是分层的,使其大约比其他最新方法节省4倍内存。除了使训练速度更快外,这样也允许我们使用更大的裁剪大小,从而提高模型的准确性。我们在两个数据集上展示了我们方法的结果:Cityscapes和Mapillary Vistas。对于具有大量弱标记图像的Cityscapes,我们还利用自动标注来改善泛化效果。使用我们的方法,在Mapillary(61.1 IOU val)和Cityscapes(85.1 IOU test)中,我们实现了新的最先进结果。
关键词: 语义分割· 注意力·自动标注
1 Introduction
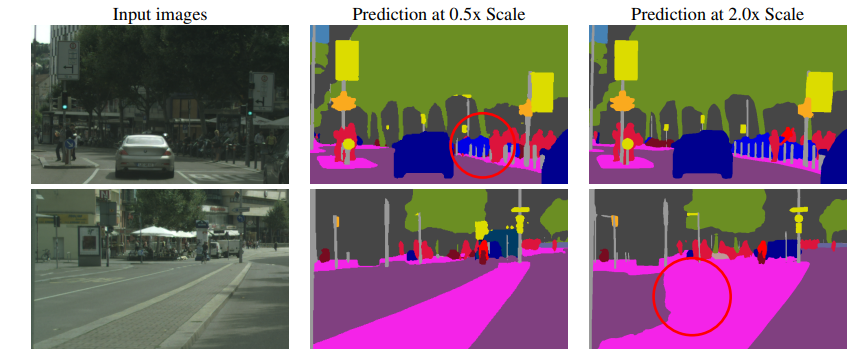
Figure 1: 展示了语义分割在推断尺度方面普遍存在的失败模式。在第一行中,细小的柱状物在缩小(0.5倍)的图像中被不一致地分割,但在放大(2倍)的图像中预测更好。在第二行中,较大的道路/隔离区域在较低分辨率(0.5倍)下进行了更好的分割。
语义分割的任务是将图像中所有像素标记为属于N个类别中的一个。在这项任务中,存在一种折衷,即某些类型的预测在较低推断分辨率下处理最好,而其他类型的任务在较高推断分辨率下处理更好。例如,像物体的边缘或薄结构等细节通常需要使用放大的图像尺寸进行更好的预测。同时,需要更多全局上下文的大型结构的预测通常在缩小的图像尺寸上完成得更好,因为网络的感受域可以观察到更多必要的上下文。我们称后一问题为分类混淆。 如图1所示,这些案例的例子都有展示。
使用多尺度推理是解决这种折衷的常用方法。使用一系列尺度进行预测,并使用平均或最大池化将结果组合起来通常会改善结果。使用平均组合多个尺度通常会改善结果,但它面临着将优秀的预测与较差的预测组合在一起的问题。例如,如果对于给定的像素,最佳预测来自2倍尺度,而来自0.5倍尺度的预测则更差,则平均值将组合这些预测,从而产生次优的输出。另一方面,最大池化选择使用给定像素的N个尺度中的一个,而最优答案可能是跨不同尺度预测的加权组合。
为了解决这个问题,我们采用了一种注意机制来预测如何在像素级别结合多尺度预测,类似于Chen等人提出的方法。我们提出了一种分层注意机制,使得网络学会预测相邻尺度之间的相对权重。在我们的方法中,由于它分层的特性,我们只需要在训练管道中增加一个额外的尺度,而其他方法,如[1]则要求在训练阶段显式地添加每个额外推断尺度。例如,当多尺度评估的目标推断尺度为{0.5、1.0和2.0}时,其他注意力方法要求网络首先经过所有这些尺度的训练,产生4.25倍( 0. 5 2 + 2. 0 2 0.5^2 + 2.0^2 0.52+2.02)的额外训练成本。而我们的方法仅需要在训练期间添加一个额外的0.5x尺度,只增加了0.25倍 ( 0. 5 2 0.5^2 0.52)成本。此外,我们提出的分层机制还提供了在推理时选择额外尺度的灵活性,以比以前提出的方法更好的利用可用资源。
为了在Cityscapes中获得最先进的结果,我们还采用了对粗图像进行自动标注的策略,以增加数据集的差异性,从而提高泛化效果。我们的策略受到多个最近的工作的启发,包括[2、3、4]。与典型的软标注策略不同,我们采用硬标注来管理标签存储大小,这有助于通过降低磁盘IO成本来提高训练吞吐量。
1.1 研究贡献
- 一种高效的分层多尺度注意力机制,有助于解决类别混淆和细节损失问题,使网络能够学习如何从多个推理尺度中最佳地组合预测结果。
- 基于硬阈值的自动标注策略利用未标记的图像以提高IOU。
- 在Cityscapes(85.1 IOU)和Mapillary Vistas(61.1 IOU)数据集上实现了最优结果。
2 相关工作
多尺度上下文方法。目前最先进的语义分割网络使用输出步长较低的网络干线,这使得网络可以更好地解析细节,但也会导致感受野缩小的现象。感受野的缩小可能导致网络难以预测场景中的大物体。金字塔池化可以通过组合多尺度上下文来抵消收缩后的感受野。PSPNet [5] 使用空间金字塔池化模块,其利用从网络干线的最后一层获得的特征作为输入,通过一系列池化和卷积操作将多尺度特征组合起来。DeepLab [6] 使用Atrous Spatial Pyramid Pooling (ASPP),它采用不同扩张率的空洞卷积来创建密集特征,与PSPNet相比更具优势。最近,ZigZagNet [7] 和ACNet [8] 则利用中间特征而非仅网络干线的特征来创建多尺度上下文。
关联上下文方法。金字塔池化技术通常关注固定的正方形上下文区域,因为池化和扩张通常是对称应用的。此外,此类技术往往是静态且不可学习的。然而,关联上下文方法通过关注像素之间的关系来构建上下文,不限于正方形区域。关联上下文方法具有学习性质,可以根据图像构成构建上下文。这种技术可针对非正方形语义区域(如长火车或高窄灯柱)构建更适当的上下文。OCRNet [9]、DANET [10]、CFNet [11]、OCNet [12] 和其他相关工作 [13, 14, 15, 16, 17, 18, 19, 20] 使用这类关系来构建更好的上下文。
多尺度推理。关联和多尺度上下文方法 [21, 22, 23, 9] 都使用多尺度评估来获得最佳结果。将多个尺度的网络预测进行组合的两种常见方法是求平均和求最大值池化,其中求平均池化更为常见。然而,求平均池化需要等权重地组合不同尺度的输出,可能不太理想。Chen等人[1, 24]使用注意力头来结合多个尺度。他们训练一个跨越所有尺度的注意力头,该头使用神经网络的最终特征进行训练。Yang等人[24]则使用不同网络层中的特征组合来构建更好的上下文信息。然而,这两种方法都共同具有一个特点,即网络和注意力头是使用固定的一组尺度进行训练的。在运行时,只能使用这些尺度,否则需要重新训练网络。本文提出了一种基于分层的注意力机制,在推断时不受尺度数量的影响。此外,我们证明了我们所提出的分层注意力机制不仅改善了平均池化的性能,还允许我们诊断性地可视化类别和场景中不同尺度的重要性。此外,我们的方法与其他注意力或金字塔池化方法(如 [22, 25, 26, 9, 27, 10, 28])是互相独立的,因为这些方法使用单尺度图像并执行注意力以更好地组合多级特征以生成高分辨率预测。
自动标记。目前针对Cityscapes的大多数最新语义分割工作,特别是[12, 29],都完全使用 ~20,000 张粗略标注的图像进行训练。然而,由于标签过于粗略,每个粗略图像的很大部分区域未被标记。为了在Cityscapes上实现最先进的结果,我们采用了一个自动标记的策略,受 Xie等人[2] 以及其他半监督、自我训练语义分割的方法 [30, 31, 32, 33, 34] 和伪标签方法(如[4, 35, 36, 3])的启发。我们在Cityscapes粗略图像中生成密集标签。我们生成的标签几乎没有未标记的区域,因此我们能够充分利用粗略图像的所有内容。
大多数图像分类的自动标记工作使用连续或软标签,而我们生成硬阈值标签,以实现存储效率和训练速度。使用软标签时,教师网络为每个像素的N个类别提供连续的概率,而对于硬标签,则使用阈值选择每个像素的单个最高级类别。类似于[37,4],我们为粗糙的Cityscapes图像生成硬密集标签。示例显示在图4中。与Xie等人不同,我们不执行标签的迭代改进,而是使用默认的粗糙和精细标注的图像进行教师模型的完整训练的单次迭代。在此联合训练之后,我们对粗糙图像进行自动标记,并将其替换为我们教师训练配方中的图像,以获得最先进的测试结果。通过结合我们所提出的分层注意力算法,使用我们伪造的硬标签,我们能够在Cityscapes上获得最先进的结果。
3. 分层多尺度注意力机制
我们的注意力机制在概念上与[1]非常相似,其中为每个尺度学习了一个密集的掩码,然后通过对每个尺度的掩码与预测值进行逐像素乘法和尺度间逐像素求和的方式来组合这些多尺度预测结果,见图2。我们称Chen的方法为显式方法。通过我们的分层方法,我们不是同时学习每个固定尺度的所有注意力掩码,而是学习相邻尺度之间的相对注意力掩码。在训练网络时,我们仅训练相邻尺度对。如图2所示,给定单一(较低)尺度的一组图像特征,我们预测两个图像尺度之间密集像素级的相对注意力。实际上,为了获得成对比例的图像,我们将单个输入图像缩小2倍,这样我们便有一个1x比例的输入和一个0.5x缩放的输入,当然也可以选择其他任意缩放比例。需要注意的是,网络输入本身是原始训练图像的重新缩放版本,因为我们在训练时使用图像尺度增强,这使得网络可以预测多种图像尺度的相对注意力。在运行推理时,我们可以分层应用已学习的注意力,将N个预测尺度组合在一起进行计算。我们优先处理较低的尺度并逐步增加到较高的尺度,这样可以选择更具有全局情境信息的较高尺度对通过较高尺度预测来改进预测结果的位置进行调整。
更具体地说,在训练期间,给定的输入图像按因子r缩放,其中r = 0.5表示2倍下采样,r = 2.0表示2倍上采样,r = 1表示不进行操作。在我们的培训中,我们选择了r = 0.5和r = 1.0。然后将具有r = 1和r = 0.5的两个图像通过共享网络干架发送,它产生语义logits(L)以及每个比例的注意力掩码(α),这些用于在掩码之间组合logits(L)。因此,针对两个尺度的训练和推理,U代表双线性上采样运算符,∗和+分别为逐像素乘法和加法,则该方程可以被形式化表示为:
L
(
r
=
1
)
=
U
(
L
(
r
=
0.5
)
∗
α
(
r
=
0.5
)
)
+
(
(
1
−
U
(
α
(
r
=
0.5
)
)
)
∗
L
(
r
=
1
)
)
(1)
L_{(r=1) }= U(L_{(r=0.5)} ∗ α_{(r=0.5)}) + ((1 − U(α_{(r=0.5)})) ∗ L_{(r=1)}) \tag{1}
L(r=1)=U(L(r=0.5)∗α(r=0.5))+((1−U(α(r=0.5)))∗L(r=1))(1)
There are two advantages using our proposed strategy:

图2:网络架构左右两侧分别展示了显式和分层(我们的)架构。
左边展示了[1]的架构,其中每个尺度的注意力均被显式地学习。右侧展示了我们的分层注意力架构。右上是我们训练流程的说明,网络会学习如何预测相邻尺度对之间的注意力。右下的推理以分层/层级方式进行,以组合多个预测尺度。较低尺度的注意力决定了下一个较高尺度的贡献。
- 在推理时,现在我们可以灵活选择尺度,因此借助我们提出的分层注意力机制链在一起,添加新尺度,例如0.25x或2.0x,到已经使用0.5x和1.0x训练的模型中是可行的。这与以前提出的方法不同,以前的方法局限于使用模型训练期间使用的相同比例。
- 这种分层结构允许我们提高训练效率,与显式方法相比有所改进。采用显式方法时,如果使用0.5、1.0、2.0三种比例,则训练成本将为 0. 5 2 + 1. 0 2 + 2. 0 2 = 5.25 0.5^2 + 1.0^2 + 2.0^2 = 5.25 0.52+1.02+2.02=5.25,相对于使用单一尺度的训练。采用我们提出的分层方法时,训练成本仅为 0. 5 2 + 1. 0 2 = 1.25 0.5^2 + 1.0^2 = 1.25 0.52+1.02=1.25。
3.1 架构
主干网:在本节中的剖析研究中,我们使用ResNet-50 [38](配置输出步长为8)作为网络的干架。在达到最先进结果时,我们使用更大、更强大的干架——HRNet-OCR [9]。
语义头:专为语义预测设计的完全卷积头,由(3x3 conv) → (BN) → (ReLU) → (3x3 conv) → (BN) → (ReLU) → (1x1 conv)组成。最终卷积输出num_classes channels。
注意力头:使用类似于语义头结构的单独头进行注意力预测,除了最终卷积输出以外,它输出单个通道。当使用ResNet-50作为干架时,语义和注意力头与ResNet-50的最后一个阶段的特征配合使用。当使用HRNet-OCR时,语义和注意力头与OCR块的特征配合使用。对于HRNet-OCR,还存在一个辅助语义头,在OCR之前直接从HRNet干架中获取其特征。这个头部包括(1x1 conv) → (BN) → (ReLU) → (1x1 conv)。在对语义logits应用注意力之后,使用双线性上采样将预测结果还原成目标图像大小。
3.2 Analysis
为了评估我们的多尺度注意力方法的有效性,我们使用DeepLab V3+架构和ResNet50主干网训练网络。在表1中,我们展示了我们的分层注意力方法相对于基准平均方法(49.4)或显式方法(51.4)具有更好的精度(51.6)。我们还观察到,在添加0.25x比例时,我们的方法比显式方法获得了显着更好的结果。与显式方法不同,我们的方法在使用额外的0.25x比例时不需要重新训练网络。这种推理时间上的灵活性是我们方法的一个关键优势。我们可以进行一次训练,但可以用一系列不同的比例进行灵活评估。

表格1:我们的分层多尺度注意力方法与Mapillary验证集上其他方法的比较。网络架构是DeepLab V3+与ResNet-50树干结合。Eval scales:用于多尺度评估的尺度。FLOPS:网络在训练中消耗的浮点运算次数相对量。Minibatch time:在Nvidia Tesla V100 GPU上测量的训练minibatch时间。
此外,我们还观察到,在基准平均多尺度方法中,仅添加0.25x比例会对准确性产生负面影响,因为IOU降低了0.7,而我们的方法加上额外的0.25x比例则将准确性提高了0.6 IOU。基准平均方法中,0.25x预测是如此粗糙,以至于当平均到其他尺度时,我们观察到类别,如车道线标记、人孔、电话亭、街灯、红绿灯和红绿灯标志(前后),自行车架等,降低了1.5 IOU。预测的粗糙度伤害了边缘和细节。然而,使用我们提出的注意力方法时,添加0.25x比例会使结果提高0.6,因为我们的网络能够以最合适的方式应用0.25x预测,并远离在边缘周围使用它。这可以在图3中观察到的细柱的左侧图像中,0.5x预测只覆盖了非常少量的细柱,但2.0x尺度下存在着非常强的关注信号。反过来,在右侧的非常大区域中,注意力机制学会充分利用较低的比例(0.5x),对错误的2.0x预测几乎没有使用。
3.2.1 单尺度特征 vs 双尺度特征
虽然我们采取的架构仅使用较低的两个相邻图像尺度的特征向注意力头部提供输入(参见图2),但我们尝试将注意力头部训练为从两个相邻尺度获取的特征提供输入。我们没有观察到显著的精度差异,因此我们选择了一组特征。
4 在Cityscape上的自动标注(Auto Labelling)
受到最近[2]和[39]有关图像分类任务自动标注工作的启发,我们采用自动标注策略对Cityscapes进行增强,以提高有效数据集大小和标签质量。在Cityscapes中,有20,000个粗略标记的图像与3,500个细致标记的图像一起使用。粗略图像的标签质量非常适中,并且包含大量未标记的像素,如图4所示。通过使用我们的自动标注方法,我们可以提高标签质量,从而有助于模型IOU。
在图像分类的自动标注中,常用的技术是使用软或连续标签,其中教师网络为每个像素的每个N类提供一个目标(软)概率。这种方法的挑战在于磁盘空间和训练速度:存储这些标签需要大约3.2TB的磁盘空间:20000张图像* 2048w * 1024 h * 19类别 * 4B = 3.2TB。即使我们选择存储这些标签,在训练过程中也会明显降低训练速度。因此,我们采用一种硬标注策略,在给定像素的情况下,选择教师网络的顶部类别预测。基于教师网络输出概率的阈值来阈值化标签。超过阈值的教师预测结果成为真实标签,否则将像素标记为忽略类别。在实践中,我们使用0.9的阈值。
5 Results
5.1 实现协议
在本节中,我们详细介绍了我们的实现协议。
训练细节:我们的模型使用Pytorch [40]在Nvidia DGX服务器上训练,每个节点有8个GPU,采用混合精度、分布式数据并行训练和同步批量归一化。我们使用随机梯度下降(SGD)作为优化器,在每个GPU上使用大小为1的批处理、动量0.9和权重衰减5e-4进行训练。
我们采用“多项式”学习率策略[41]。我们使用默认设置下的RMI [42]作为主要损失函数,并使用交叉熵作为辅助损失函数。对于Cityscapes,我们使用2.0的多项式指数、0.01的初始学习率,在2个DGX节点上进行175个时期的训练。对于Mapillary,我们使用1.0的多项式指数、0.02的初始学习率,在4个DGX节点上进行200个时期的训练。与[29]类似,我们在数据加载程序中使用类均匀采样来平等采样每个类,这有助于改善不平衡数据分布时的结果。
数据增强:我们对输入图像进行高斯模糊、颜色增强、随机水平翻转和随机缩放(0.5x-2.0x)以增加数据集的训练过程。我们使用2048x1024的裁剪尺寸对Cityscapes进行裁剪,使用1856x1024的裁剪尺寸对Mapillary进行裁剪。

图3:对两个不同场景的每个尺度级别进行的语义和注意预测。左边的场景说明了细微细节问题,而右边的场景说明了大区域分割问题。注意力的白色表示高值(接近1.0)。给定像素在所有尺度上的注意力值总和为1.0。左侧:细小的路边柱最好在2倍尺度下解决,并且注意力成功地更多地关注该比例,证明了2倍注意图像中柱子的白色表示。右侧:较大的道路/隔离区域在0.5倍尺度下预测效果最佳,并且注意力确实将重点放在了该区域的0.5倍尺度上。

图4:我们自动生成的粗略图像标签示例。自动生成的粗略标签(右侧)提供了比原始地面真值粗糙标签(中间)更细节的标注信息。这种更细致的标注信息改善了标签分布,因为现在既代表了小型物体,也代表大型物体,而不再仅仅是大型物体。
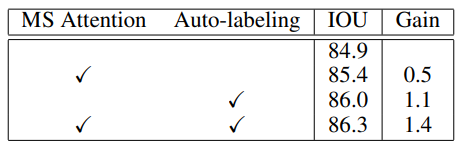
表格2:Cityscapes验证集上的消融实验。基线方法使用HRNet-OCR作为架构。MS Attention是我们提出的多尺度注意力方法。Auto-labeling表示我们在训练期间使用自动生成的或地面真值粗略标签。两种技术的结合产生了最佳结果。
5.1.1 Cityscapes的结果
Cityscapes [43]是一个大型数据集,涵盖19个语义类别,在5000个高分辨率图像中进行标记。对于Cityscapes,我们使用HRNet-OCR作为主干网,同时采用我们提出的多尺度注意力方法。我们使用RMI作为主分段头部的损失函数,但对于辅助分段头部,我们使用交叉熵,因为我们发现使用RMI损失导致训练深入后的训练精度降低。我们通过先在更大的Mapillary数据集上进行预训练,然后在Cityscapes上进行训练来实现最佳结果。对于Mapillary的预训练任务,我们不使用注意力进行训练。我们在使用亚像素级标注的基础上,从train+val图像和自动标记的粗略图像集合中以50%的概率进行采样。测试时,我们使用比例={0.5,1.0,2.0}和图像翻转。
如表2所示,我们在Cityscapes验证集上进行了消融研究。多尺度注意力比基于平均池化的HRNet-OCR架构提高0.5% IOU。自动标注将IOU基线提高了1.1%。将两个技术结合起来可获得总增益1.4%下IOU 。
最后,在表3中,我们展示了我们的方法与Cityscapes测试集中其他最佳表现方法的结果进行比较。我们的方法获得85.1分,是所有方法中报告的最高Cityscapes测试成绩,超过最佳先前得分0.6 IOU。此外,在除了三个类之外的所有类中,我们的方法都具有最高的类内分数。一些结果在图5中被可视化呈现。

表格3:与Cityscapes测试集上其它方法的比较。每个类别中的最佳结果以粗体表示。
5.1.2 Mapillary Vistas的结果
Mapillary Vistas [45]是一个包含25,000个高分辨率图像并注释为66个对象类别的大型数据集。对于Mapillary,我们使用HRNet-OCR作为主干网,同时采用我们提出的多尺度注意力方法。由于Mapillary的图像可能具有非常高且不同的分辨率,因此我们将图像调整大小,使其长边为2177,就像[23]中所做的那样。我们使用在ImageNet分类上训练的HRNet部分的权重进行模型初始化。由于在Mapillary中66个类别的存储器需求更大,因此我们将裁剪尺寸减小到1856x1024。
在表4中,我们展示了我们的方法在Mapillary验证集上的结果。我们的单一模型方法获得了61.1分,比下一个最接近的方法Panoptic Deeplab[23]高出2.4分,后者使用多模型组合实现了58.7分。

表格4:在Mapillary验证集上的结果比较。每个类别中的最佳结果以粗体表示。
6 结论
本文提出了一种分层多尺度注意力方法用于语义分割。我们的方法在提高语义分割精度的同时,也具有内存和计算效率,这两个方面都是实际问题。训练效率限制研究速度,GPU内存效率限制可同时训练的网络大小,这些都可能限制网络精度。我们通过实验证明了我们提出的方法可以在Cityscapes和Mapillary数据集中获得一致的改善效果。
致谢:我们要感谢Sanja Fidler、Kevin Shih、Tommi Koivisto和Timo Roman的有益讨论。

References
[1] Liang-Chieh Chen, Yi Yang, Jiang Wang, Wei Xu, and Alan L. Yuille. Attention to scale: Scale-aware semantic
image segmentation, 2015.
[2] Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V. Le. Self-training with noisy student improves imagenet
classification, 2019.
[3] Eric Arazo, Diego Ortego, Paul Albert, Noel E O’Connor, and Kevin McGuinness. Pseudo-labeling and confirmation bias in deep semi-supervised learning. arXiv preprint arXiv:1908.02983, 2019.
[4] Dong-Hyun Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural
networks. 2013.
[5] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In
Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2881–2890, 2017.
[6] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with
atrous separable convolution for semantic image segmentation. In ECCV, 2018.
[7] Di Lin, Dingguo Shen, Siting Shen, Yuanfeng Ji, Dani Lischinski, Daniel Cohen-Or, and Hui Huang. Zigzagnet:
Fusing top-down and bottom-up context for object segmentation. In CVPR, 2019.
[8] Jun Fu, Jing Liu, Yuhang Wang, Yong Li, Yongjun Bao, Jinhui Tang, and Hanqing Lu. Adaptive context network
for scene parsing, 2019.
[9] Yuhui Yuan, Xilin Chen, and Jingdong Wang. Object-contextual representations for semantic segmentation, 2019.
[10] Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang, and Hanqing Lu. Dual attention network for
scene segmentation, 2018.
[11] Hang Zhang, Han Zhang, Chenguang Wang, and Junyuan Xie. Co-occurrent features in semantic segmentation.
In CVPR, 2019.
[12] Yuhui Yuan and Jingdong Wang. Ocnet: Object context network for scene parsing, 2018.
[13] Yunpeng Chen, Yannis Kalantidis, Jianshu Li, Shuicheng Yan, and Jiashi Feng. A2-nets: Double attention ˆ
networks. In NIPS, 2018.
[14] Fan Zhang, Yanqin Chen, Zhihang Li, Zhibin Hong, Jingtuo Liu, Feifei Ma, Junyu Han, and Errui Ding. Acfnet:
Attentional class feature network for semantic segmentation. In ICCV, 2019.
[15] Yunpeng Chen, Marcus Rohrbach, Zhicheng Yan, Shuicheng Yan, Jiashi Feng, and Yannis Kalantidis. Graph-based
global reasoning networks. arXiv:1811.12814, 2018.
[16] Xiaodan Liang, Zhiting Hu, Hao Zhang, Liang Lin, and Eric P Xing. Symbolic graph reasoning meets convolutions.
In NIPS, 2018.
[17] Yin Li and Abhinav Gupta. Beyond grids: Learning graph representations for visual recognition. In NIPS, 2018.
[18] Kaiyu Yue, Ming Sun, Yuchen Yuan, Feng Zhou, Errui Ding, and Fuxin Xu. Compact generalized non-local
network. In NIPS. 2018.
[19] Xia Li, Zhisheng Zhong, Jianlong Wu, Yibo Yang, Zhouchen Lin, and Hong Liu. Expectation-maximization
attention networks for semantic segmentation. In ICCV, 2019.
[20] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei, and Wenyu Liu. Ccnet: Criss-cross
attention for semantic segmentation. arXiv:1811.11721, 2018.
[21] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for
semantic image segmentation. arXiv:1706.05587, 2017.
[22] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with
atrous separable convolution for semantic image segmentation, 2018.
[23] Bowen Cheng, Maxwell D. Collins, Yukun Zhu, Ting Liu, Thomas S. Huang, Hartwig Adam, and Liang-Chieh
Chen. Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation, 2019.
[24] Shiqi Yang and Gang Peng. Attention to refine through multi scales for semantic segmentation. In Pacific Rim
Conference on Multimedia, pages 232–241. Springer, 2018.
[25] Ashish Sinha and Jose Dolz. Multi-scale self-guided attention for medical image segmentation, 2019.
[26] Guosheng Lin, Anton Milan, Chunhua Shen, and Ian Reid. Refinenet: Multi-path refinement networks for
high-resolution semantic segmentation, 2016.
[27] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei, and Wenyu Liu. Ccnet: Criss-cross
attention for semantic segmentation. In The IEEE International Conference on Computer Vision (ICCV), October
2019.
[28] Hanchao Li, Pengfei Xiong, Jie An, and Lingxue Wang. Pyramid attention network for semantic segmentation.
arXiv preprint arXiv:1805.10180, 2018.
[29] Yi* Zhu, Karan* Sapra, Fitsum A Reda, Kevin J Shih, Shawn Newsam, Andrew Tao, and Bryan Catanzaro.
Improving semantic segmentation via video propagation and label relaxation. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition, pages 8856–8865, 2019.
[30] Qing Lian, Fengmao Lv, Lixin Duan, and Boqing Gong. Constructing Self-Motivated Pyramid Curriculums for
Cross-Domain Semantic Segmentation: A Non-Adversarial Approach. In IEEE International Conference on
Computer Vision (ICCV), 2019.
[31] Yunsheng Li, Lu Yuan, and Nuno Vasconcelos. Bidirectional Learning for Domain Adaptation of Semantic
Segmentation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[32] Pauline Luc, Natalia Neverova, Camille Couprie, Jakob Verbeek, and Yann LeCun. Predicting Deeper into the
Future of Semantic Segmentation. In IEEE International Conference on Computer Vision (ICCV), 2017.
[33] Yang Zou, Zhiding Yu, B. V. K. Vijaya Kumar, and Jinsong Wang. Domain Adaptation for Semantic Segmentation
via Class-Balanced Self-Training. In European Conference on Computer Vision (ECCV), 2018.
[34] Yang Zou, Zhiding Yu, Xiaofeng Liu, B.V.K. Vijaya Kumar, and Jinsong Wang. Confidence Regularized
Self-Training. In IEEE International Conference on Computer Vision (ICCV), 2019.
[35] Ahmet Iscen, Giorgos Tolias, Yannis Avrithis, and Ondrej Chum. Label propagation for deep semi-supervised
learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5070–5079,
2019.
[36] Weiwei Shi, Yihong Gong, Chris Ding, Zhiheng MaXiaoyu Tao, and Nanning Zheng. Transductive semisupervised deep learning using min-max features. In Proceedings of the European Conference on Computer
Vision (ECCV), pages 299–315, 2018.
[37] Yiting Li, Lu Liu, and Robby T Tan. Decoupled certainty-driven consistency loss for semi-supervised learning.
arXiv, pages arXiv–1901, 2019.
[38] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In
Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[39] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets
improve semi-supervised deep learning results, 2017.
[40] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen,
Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep
learning library. In Advances in Neural Information Processing Systems, pages 8024–8035, 2019.
[41] Wei Liu, Andrew Rabinovich, and Alexander C. Berg. Parsenet: Looking wider to see better, 2015.
[42] Zheng Yang Deng Cai Shuai Zhao, Yang Wang. Region mutual information loss for semantic segmentation. In
NeurIPS, 2019.
[43] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe
Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In Proc.
of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[44] Yuan Yuhui, Xie Jingyi, Chen Xilin, and Wang Jingdong. Segfix: Model-agnostic boundary refinement for
segmentation. arXiv preprint, 2020.
[45] Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulò, and Peter Kontschieder. The mapillary vistas dataset for
semantic understanding of street scenes. In International Conference on Computer Vision (ICCV), 2017.
[46] Lorenzo Porzi, Samuel Rota Bulo, Aleksander Colovic, and Peter Kontschieder. Seamless scene segmentation. In
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
[47] Tien-Ju Yang, Maxwell D Collins, Yukun Zhu, Jyh-Jing Hwang, Ting Liu, Xiao Zhang, Vivienne Sze, George
Papandreou, and Liang-Chieh Chen. Deeperlab: Single-shot image parser. arXiv preprint arXiv:1902.05093,
2019.