卷积层的设计思路
使用Im2Col来实现高性能卷积
在深度学习中实现高性能卷积有以下几个方法:
-
并行计算:在网络或硬件层面上,利用并行计算的优势对卷积过程进行加速,例如使用GPU。
-
转换卷积算法:卷积操作可由矩阵相乘代替,使用Im2Col来实现高性能卷积。
-
减少内存带宽:通过修改计算顺序、优化缓存管理或手动调整内存布局等方法来减少内存访问量,从而提高卷积性能。
-
降低精度:使用低精度数据类型(如半精度浮点数)进行计算可以提高卷积性能,因为这些数据类型在内存和计算方面都需要较少的资源。
Im2Col(图像到列)是一种将卷积层输入的多维图像数据转换为二维列状数据的算法。该算法被广泛应用于深度学习框架中,以加速卷积计算,提高图像处理的效率和准确性。下面是 Im2Col 算法的基本原理:
-
输入数据:一个形状为 [ N , C , H , W ] [N, C, H, W] [N,C,H,W] 的四维张量,其中 N 表示样本数,C 表示通道数,H 和 W 分别表示图像高度和宽度。
-
设定卷积核大小和步幅:卷积层通常包含若干个卷积核,每个卷积核大小为 K h ∗ K w K_h * K_w Kh∗Kw,步幅为 S h ∗ S w S_h * S_w Sh∗Sw。
-
对输入图像进行填充:在输入图像的周围填充 P h P_h Ph 行和 P w P_w Pw 列的零值,使得输出特征图大小为 [ ( H − K h + 2 ∗ P h ) / S h + 1 , ( W − K w + 2 ∗ P w ) / S w + 1 ] [(H - K_h + 2*P_h)/S_h+1, (W - K_w + 2*P_w)/S_w+1] [(H−Kh+2∗Ph)/Sh+1,(W−Kw+2∗Pw)/Sw+1]。
-
将卷积核拉成一维向量:将每个卷积核从形状为 [ K h , K w , C ] [K_h, K_w, C] [Kh,Kw,C] 的三维张量转换为形状为 [ K h ∗ K w ∗ C ] [K_h * K_w * C] [Kh∗Kw∗C] 的一维向量。
-
Im2Col 转换:将输入图像的每个大小为 K h ∗ K w K_h * K_w Kh∗Kw 的图块
按行将像素展开成一列,生成一个形状为 [ K h ∗ K w ∗ C , H o u t ∗ W o u t ] [K_h * K_w * C, H_{out} * W_{out}] [Kh∗Kw∗C,Hout∗Wout] 的二维张量。 -
矩阵乘法计算:将
一维卷积核向量与 Im2Col 转换得到的列向量进行矩阵乘法运算,得到一个形状为 [ N ∗ n u m f i l t e r s , H o u t ∗ W o u t ] [N * num_filters, H_{out} * W_{out}] [N∗numfilters,Hout∗Wout] 的矩阵,其中 num_filters 表示卷积核数量。 -
将结果转换为输出特征图:将结果矩阵
重组成形状为 [ N , n u m f i l t e r s , H o u t , W o u t ] [N, num_filters, H_{out}, W_{out}] [N,numfilters,Hout,Wout] 的四维张量,即为卷积层输出的特征图。
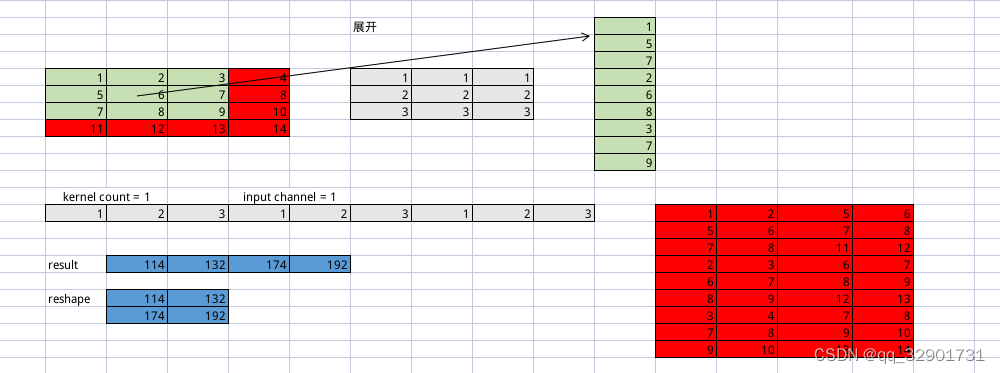
总之,Im2Col 算法是通过将输入图像转换为列状数据,并利用矩阵乘法计算来提高卷积运算效率和准确性。在实际应用中,使用 Im2Col 算法可以加速卷积操作,提升深度学习模型的训练和推理速度。
详细可以查看:
- High Performance Convolutional Neural Networks for Document Processing
- https://blog.csdn.net/qq_32901731/article/details/128822803
ConvolutionLayer的定义
由于ConvolutionLayer是带参数的,因此可通过继承ParamLayer类,定义ConvolutionLayer类来实现卷积层。具体来说:
-
构造函数:定义了卷积层的一些基本参数,包括输出通道数 output_channel、输入通道数 in_channel、卷积核大小 kernel_h 和 kernel_w、padding_h 和 padding_w、stride_h 和 stride_w、group数 groups 和是否使用偏置 use_bias。通过该函数初始化了类成员变量。
-
静态函数 GetInstance:给定运行时操作符 op,该函数返回一个 conv_layer 实例的指针。在卷积层中,该函数主要解析和验证输入张量的形状和参数,以及计算输出张量的形状。
-
前向传播函数 Forward:根据输入张量 inputs 和已经初始化的卷积层参数,执行卷积操作,并将结果写入输出张量 outputs 中。具体实现涉及到 Im2Col 转换、矩阵乘法等计算过程。
此外,该类定义了一些私有成员变量,包括是否使用偏置 use_bias_、groups 数量 groups_、padding 和 stride 的高度和宽度等参数。这些变量在构造函数中进行初始化,并在前向传播函数中使用。
ConvolutionLayer的实例化
通过LayerRegistererWrapper kConvGetInstance("nn.Conv2d", ConvolutionLayer::GetInstance);来定义
一个 LayerRegistererWrapper 类型的变量 kConvGetInstance,用来注册一个名为 “nn.Conv2d” 的卷积层的 GetInstance 函数 ConvolutionLayer::GetInstance。
这样在使用该卷积层时只需要指定名称 “nn.Conv2d”,就可以自动调用对应的 GetInstance 函数了。
卷积层的 GetInstance 函数,用于对传入的运行时操作符 op 进行解析和验证,并返回一个卷积层实例的指针。具体来说:
-
首先检查输入参数 op 是否为空,如果为空则报错并返回对应的错误码。
-
从 op 中获取卷积层的 dilation(膨胀率)、in_channels(输入通道数)和 out_channels(输出通道数)等参数,进行解析和验证。如果这些参数不存在或格式不正确,则报错并返回对应的错误码。
-
检查卷积核的 dilation 值是否为 1,因为目前只支持 dilation 值为 1。
-
对于 padding 参数,首先检查该参数是否存在,不存在则报错并返回 kParameterMissingPadding 的错误码;接着尝试从运行时参数 op 中获取 padding 值,如果获取不到或者格式不正确,则同样报错返回对应的错误码。
-
对于 bias、stride、kernel_size 参数,也采用类似的方法进行判断和提取,如果某个参数不存在或格式有误,则报错返回相应的错误码。
-
如果 padding_mode 参数存在,则检查该参数是否满足规定的格式(字符串类型),如果格式有误,则报错返回相应的错误码。
-
对 groups 参数进行检查,如果该参数不存在或者其值无效,则报错并返回相应的错误码。
-
接着根据 kernel、padding、stride 参数的值,构造一个 ConvolutionLayer 类的实例 conv_layer,并对其参数进行相应的初始化。
-
如果使用偏置,则从运行时参数 op 中获取 bias 属性的值,并进行一些检查和处理,以确保该属性的形状和值符合要求。如果 bias 属性不存在或数据有误,则报错并返回相应的错误码。
-
最后如果存在权重属性 weight,则从运行时参数 op 中获取该属性的值,检查其形状是否正确。如果 weight 数据有误,则报错并返回相应的错误码。否则,将 weight 值设置给卷积层实例(即 conv_layer),并返回 kParameterAttrParseSuccess 表示解析和构造过程成功完成。
ConvolutionLayer的前向传播
在前向传播中,我们不仅使用Im2Col来实现高性能卷积,还使用了 Armadillo 库来进行矩阵乘法,也使用了OpenMP library线程并行处理。具体如下:
-
首先进行参数和数据的检查,确保输入输出数据正确且合法。
-
接着从权重参数 weights_ 中提取卷积核的数量、大小、通道数等相关信息,并对一些参数进行检查和校验。
-
对 groups_ 参数进行一些校验和检查,确保卷积核数量和输入通道数是组数的整数倍。
-
接着根据输出特征图的大小(即 output_h 和 output_w 值)计算输入矩阵的列长 col_len,并对其进行校验。
-
然后,根据Im2Col原理,对每个分组内的卷积核参数提取并预处理成矩阵形式kernel_matrix_arr。
-
接着,根据Im2Col原理,对每个分组内的输入数据input提前并预处理成矩阵形式input_matrix。
-
获取或创建输出特征图的 output_tensor ,如果该 output_tensor 不存在,则创建一个新的空 tensor,并更新输出数组 output_tensor。
-
接着对 output_tensor 的形状进行检查和校验,确保其形状与预期的输出特征图大小相符合。
-
然后针对每个分组执行以下:将 kernel_matrix_arr 与输入变量 input_matrix 进行矩阵乘法操作得到中间结果 outputs_matrix。
-
对于每个分组,改变张量的形状,根据是否使用偏置进行指定 bias 值的计算,最终将输出结果保存在 output_tensor 中的相应通道。
-
最后返回成功标志 InferStatus::kInferSuccess,结束前向传播计算过程。
此外,在对每个batch_size进行卷积时利用 OpenMP 循环并行处理。其中:
-
#pragma omp 表示这是 OpenMP 库中的预处理指令。
-
parallel for 表示对循环进行并行处理,即多个线程之间分配迭代次数并并行执行循环内部的逻辑。
-
num_threads(batch_size) 指定了同时运行的线程数目,这里将其设置为输入数据的 batch_size。
-
for 循环将输入数据拆分成多个子任务(每个任务处理一个 batch 中的一组数据)。在执行时,不同的线程会负责处理不同的子任务,从而实现并行计算。
这样可以加速并行处理,使得程序可以充分利用系统资源,提高计算效率。
阅读的代码
- source
- layer
- details
- convolution.hpp
- convolution.cpp
- details
- layer







![[2.0快速体验]Apache Doris 2.0 日志分析快速体验](https://img-blog.csdnimg.cn/img_convert/58a82d684da288193a871736cdce62af.webp?x-oss-process=image/format,png)