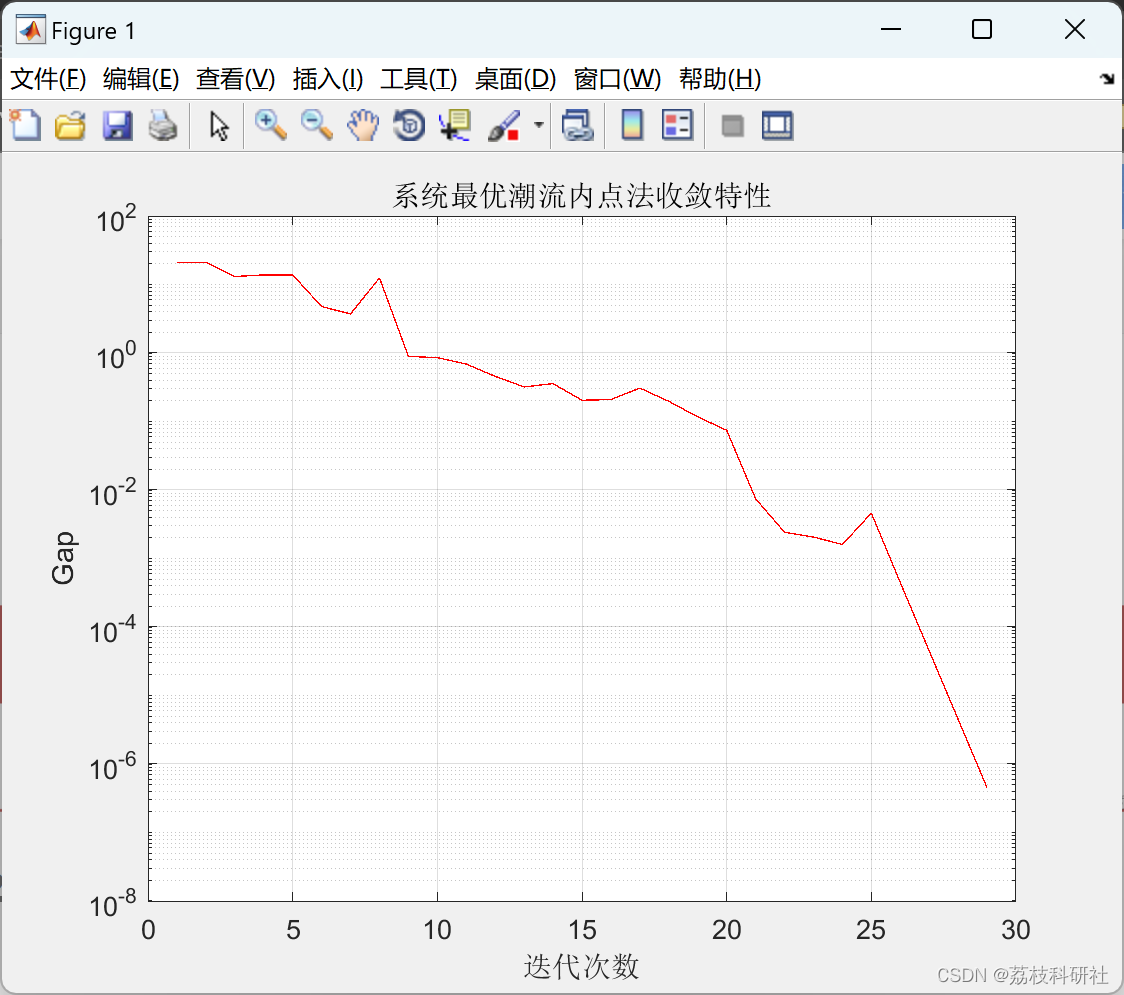
背景
在本周的时候,接到了短信数据空间报警短信,提示的是磁盘空间占用80以上,而这个数据库总体的存储量一共100G,商量之后决定在不升配置的前提下,删除一些不需要的数据表。比如针对A表删除1000W数据。但是和DBA沟通后,说删除数据后,还需要进行缩表的操作,我在想删除数据后,空间不就缩小了嘛?为什么还需要进行缩表操作?基于这个背景来学习下表数据是如何存储和删除的原理。
参数innodb_file_per_table
目前主流的数据库都采用的是InnoDB存储引擎,一个InnoDB表包含两部分,表结构定义和数据,8.0之前,表结构存在.frm后缀的文件中,8.0之后表结果存储在系统数据表中。而表结构占用的数据表少,所以主要删除的都是表数据。
表数据即可以存在共享表空间中,也可以存储在单独的文件中。可以通过innodb_file_per_table参数指定
- OFF:表数据存储在系统表空间中,也就是和数据字典放在一起。
- ON:数据存储在.ibd文件中
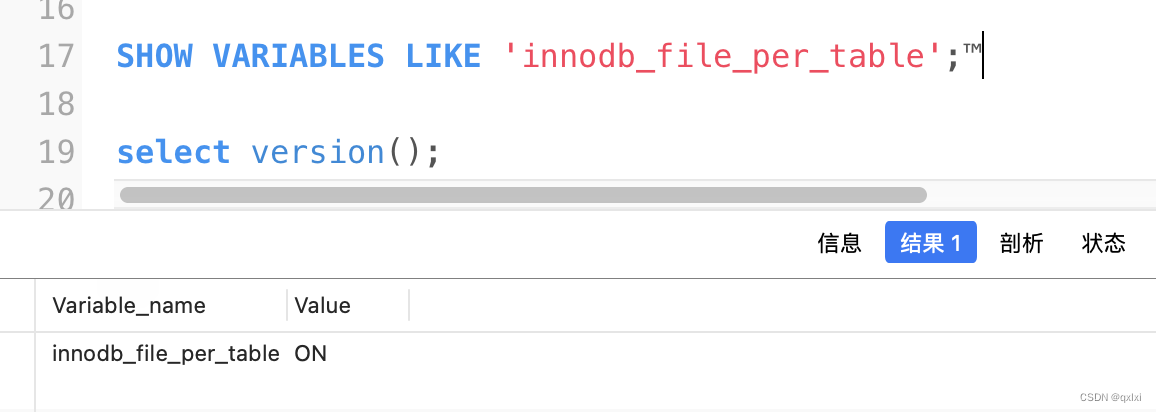
SHOW VARIABLES LIKE 'innodb_file_per_table';
select version();
而在5.6.6版本之后默认值是ON,推荐方式是使用当数据存储在单独的文件进行管理,直接使用drop table可以删除这个文件,而如果存储在系统表空间中,即使删除表,数据也不会删除。大多数的时候,我们使用drop table删除表可以将数据删除,但是更多的时候是使用delete 删除部分数据。
数据删除流程
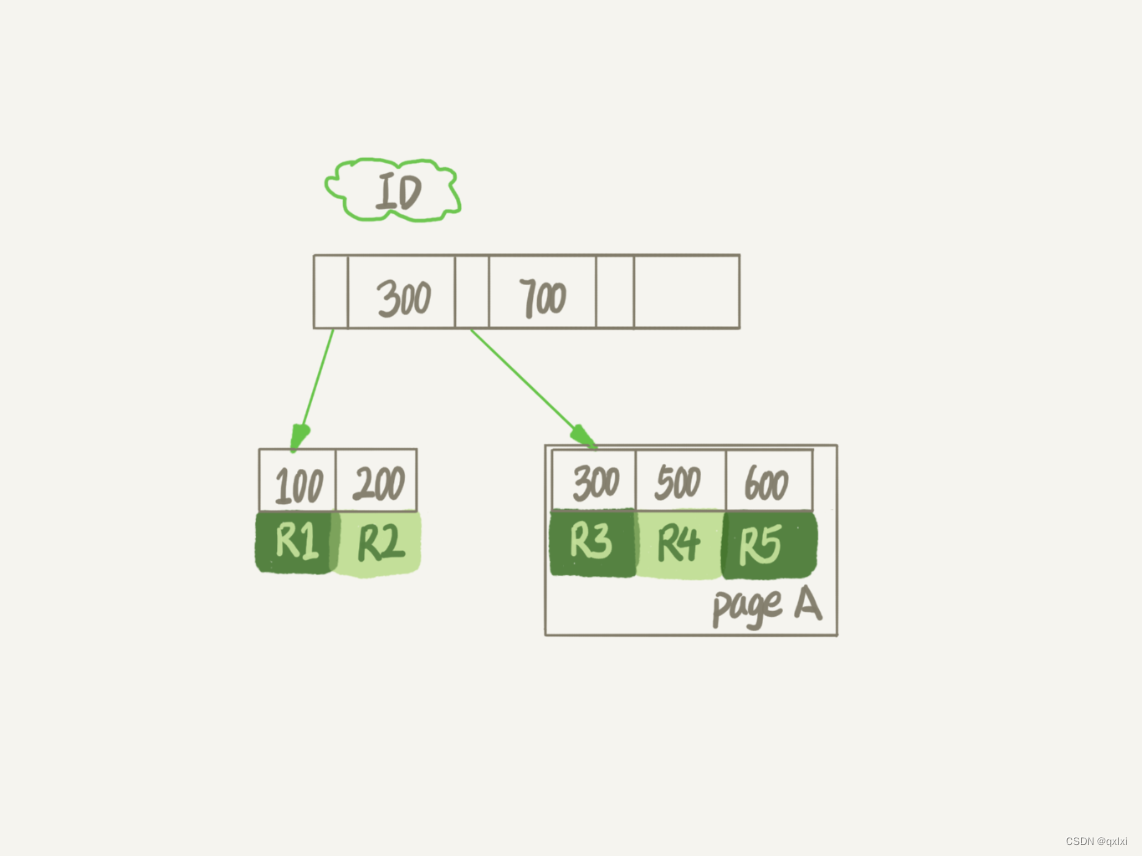
InnoDB的存储结构采用的是B+树方式存储。假设我们删除R4这个记录,而InnoDB只会把这个记录标记为删除,而如果正好有插入300/600之间的数据,就会复用这个位置。但是,磁盘的大小并没有缩小。而这个就是记录复用。
如果我们删除的数据正好都在一个page页中,那么这个数据页就是可复用的。但是数据页复用和记录复用不一样的,记录页复用需要符合一定的条件才可以,但是数据页复用,可以复用到任何位置。
比如相邻的两个数据页利用率比较小的时候,就会进行page merge的过程,将另一个数据页标记为可复用。
所以我们在进行delete删除某些数据的时候,数据被删除了,但是所在的记录位置或者数据页只是被标记为了可复用,但是磁盘的大小是不会变的。通过delete命令是不能回收表空间的。
插入数据同样会存在这样的问题
如果我们按照顺序插入数据,那么数据页是比较紧凑的,但是如果是随机插入,就可能造成数据页的分裂。
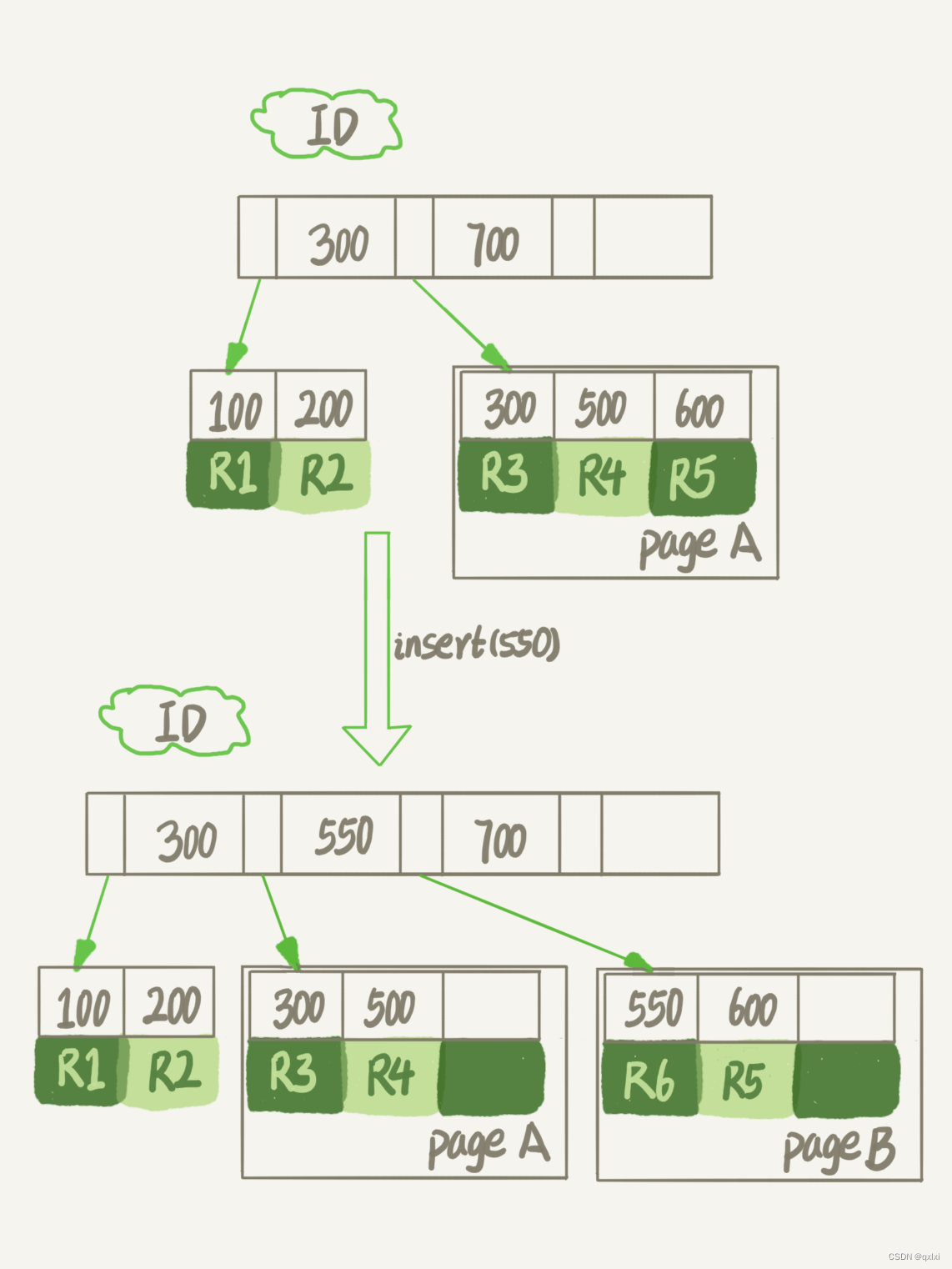
如果pageA是满的,当插入一条500-600之间的数据,那么就会发生页分裂,也就是分裂成两个数据页,而PageA就会出现数据空洞,不止在插入数据,在更新索引上的值,也会出现数据空洞。也就是哪些频繁的随机修改的表,都可能出现数据空洞。如果将数据空洞去掉之后,就可以达到收缩表空间的目的,而通过重建表的方式就可以实现。
重建表
假如有一个表A,存在大量的delete操作,为实现表空间收缩,我们可以建立一个表B,然后将表A中的数据,按照主键顺序依次插入数据到表B中,然后修改表B的名称为表A,也可以实现重建表的过程。而这个过程中就是使用alter table A engine = InnoDB重建表。
但是想过没有在整个过程中,如果出现有新增的数据或者修改的数据,我们是没有办法保证增量数据的存储。为此5.6版本后,引入了Online DDL。
而这个过程说白了,就是在复制数据的过程中,有一个raw log专门记录修改数据,在复制数据到新表的过程中,插入进入。
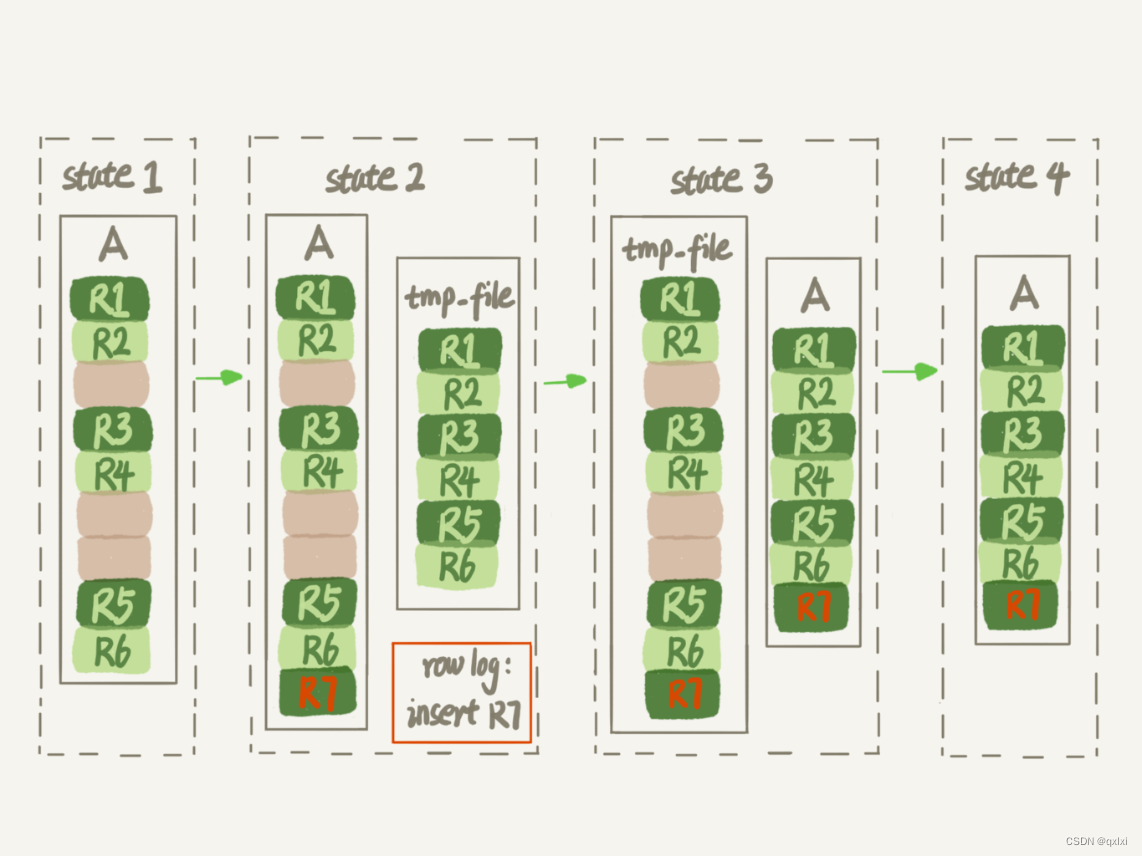
一般这种重建表的过程都是进行整个表的重建工作,对于千万级、亿级别的表,比较消耗IO和CPU资源。需要谨慎操作。
小结
optimize table 、analyze table 、alter table三种重建表的区别
5.6版本,alter table t engin = InnoDB使用的是online的重建表过程。而analyze table t不是重建表,只是对表的索引信息做重新统计,没有修改数据,加了DML读锁。optimize table t 等于recreate+analze 。
所以我们在删除数据之后,要进行表空间收缩操作,直接使用alter table engine = InnoDB,这样表空间数据占用空间才会恢复。