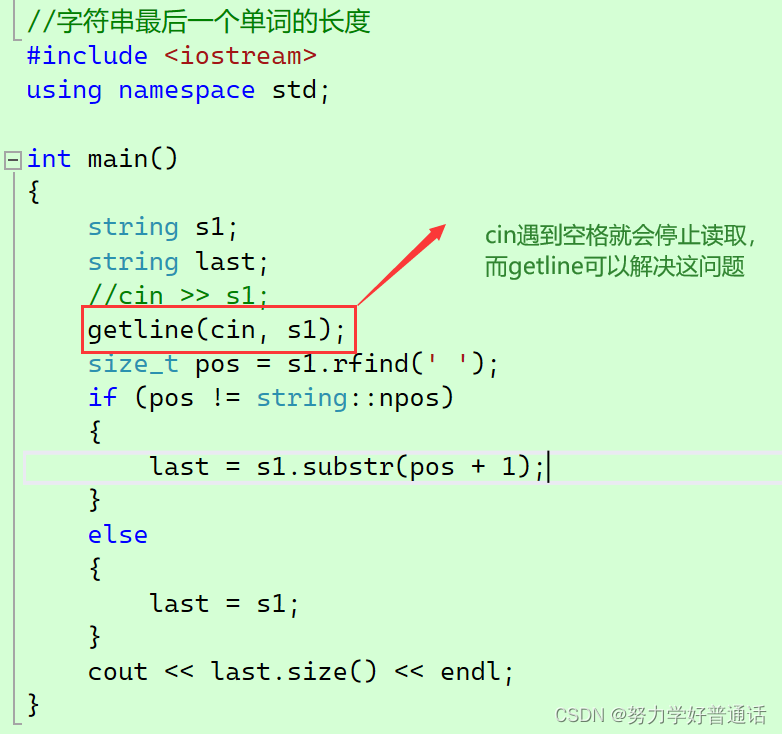
1. 引言
本文为最近学习的强化学习Q-learning的学习笔记,主要用于总结和日常记录,本文主要讲解相应的必备入门知识。
闲话少说,我们直接开始吧!
2. 概念
我们小时候都经历过以下情形:我们做错了某年事,受到了惩罚,我们学习后,在遇到类似的状况,我们将不会再犯错。同样,许多时候,做的好的行为会得到相应奖励回报,这将鼓励我们在更多的场合重复这些行为。
类似地,强化学习agent将根据策略采取某些行动action,并收到积极或消极的反馈reward,这取决于所采取的行动是否有益。然后,该奖励用于更新策略,并重复整个过程,直到达到最佳策略,如图1所示。

强化学习代理的目标是通过代理agent与动态环境Env的连续交互,优化所采取的行动action,以获得尽可能高的回报reward。
3. Model-Free and Model-Based
在继续解释和实现Q-learnng算法之前,我们需要注意的是,RL算法分为两大类:Model-Based算法和Model_Free算法。
其中,Model-Based的目的是通过与环境的互动来学习环境模型,这样agent就能够在采取行动之前预测给定行动的回报(通过建立环境模型,它可以预见每次行动之后会发生什么),从而进行行动规划。另一方面,Model-Free算法必须采取行动来观察其后果,然后从中学习(见图2)。需要注意的是,“模型”一词不是指机器学习模型,而是指环境本身的模型。

严格来说,Q-Learning是一种Model-Free算法,因为它的学习包括采取行动、获得奖励以及从采取这些行动的结果中来不断改进学习。
4. Q-learning
Q-learning算法使用包含状态-动作二元组构成的Q表(2D矩阵),使得矩阵中的每个值Q(S,a)对应于在状态a下采取行动S的Q值的估计值(Q值将在后面介绍)。当agent与环境Env交互时,Q表的Q值随着找到最优策略的迭代而将不断收敛直到它们的最优值。
一开始理解所有这些术语很复杂,出现许多疑问也是正常的,比如什么是Q值?Q表是如何构建的?Q值是如何更新的?
接下来我们就逐渐来介绍上述概念和相应的问题吧!
5. 构建Q-Table
如上所述,Q-Table是一个矩阵,其中每个元素对应于一个状态-动作二元组。因此,Q-Table将是一个mxn的矩阵,其中m是可能状态的数量,n是可能动作的数量。Q表的Q值必须有一个初始值,一般来说,Q-Table所有初始化值都设置为零。
举例:
为了简化,假设环境Env将是一个具有4种可能状态(a,b,c,d)的房间,如下图所示。同时,不妨假设代理agent将能够执行4个可能的动作:向上、向下、向左和向右。

考虑到上述代理agent和环境Env,Q-Table将是一个4x4的矩阵,其中4行对应于4种可能的状态States,4列对应于4个可能的动作Actions。如下所示,所有值都已初始化为零。

6. Q-Values
一旦Q表被初始化,代理agent就可以开始与环境Env进行交互,并更新Q-Values以实现最优策略。但是,Q值是如何更新的?
首先,引入值函数Value Function的概念是很重要的。一般来说,值函数是衡量代理agent处于给定状态State或处于给定状态-动作sate-action二元组可以带来的益处的指标。
价值函数有两种类型:State-Value Function, v(S),它决定了处于特定状态下遵循特定策略的好处;以及Action-Value Function, q(S, A),它决定了在遵循特定策略的同时从特定状态触发采取特定行动的益处。更具体地说,这些函数返回从状态State(对于状态值函数)或状态动作state-action二元组(对于动作值函数)出发,遵循给定策略的预期好处。图示如下:
函数Action-Value Function 的结果被称为Q值,如前所述,它是构成Q表的基本单元。因此,Q表为我们提供了从某种状态出发采取某种行动的预期好处,即代理agent将用来在环境Env中最佳行动的信息。因此,代理agent的目标是通过不断迭代,找到最优的q*(S, A),这样它就可以根据任何策略从任何状态-动作二元组state-action中返回尽可能高的回报reward。
7. Q-Values 更新
最优Action-Value函数q*(S,A)的一个性质是它需要满足Bellman的最优方程,如下所示。我们知道,Bellman方程可以用来迭代最优Action-Value 函数,这是智能体的主要目标。

在Q-learning的情况下,使用下图中所示的Bellman最优方程的自适应来迭代更新Q-Table中的Q值。该方程用于通过在每次迭代中将当前Q值与最佳Q值进行比较来减少误差,从而寻求两者的均衡。

请注意,上述Q值的更新方程使用了一个称为学习率的α参数,该参数用于在每次更新/迭代中对新Q值的加权程度。实际实验中,通常通过反复试验来找到该参数的理想值。
8. 算法流程
既然已经解释了算法的所有组成部分和步骤,现在是时候把它们放在一起,让代理agent学习了。以下是该算法的伪代码,将作为Q-learning实现过程中的参考。

流程如下:
- 初始化
Q-Table
Q-Table的初始化形状取决于可能的状态state和动作action的数量,并且其所有值都设置为零,如前所述。 - 训练一次
episode
每一次episode训练时,都需要代理agent达到目标状态。代理agent从一个随机状态开始,对于一次episode中的每个step,它将执行如下操作:
a) 根据策略采取相应行动action(该算法最常用的是贪婪策略)。
b) 根据前面提到的Q值更新方程,从达到的新状态和获得的奖励中计算新的Q值。
c) 从达到的新状态开始迭代进入下一个step。
训练将在所有episode完成后结束。在这一点上,Q表的Q值将是最优的(只要训练有效),这意味着如果代理agent选择具有最高Q值的动作A,则他将在每个状态S中获得最大回报reward。最后,为了在非训练环境中使用经过训练的代理agent``,只需要使其在每个步长中选择具有最高Q值的动作,因为Q表在训练期间已经被优化。
9. 总结
本文重点介绍了Q-learning算法的理论和相关概念,而没有关注它在代码中的实现。后续我会计划针对特定代码进行相应的举例讲解,嗯捏,如果你感兴趣,请多多关注。