背景
在分布式领域中,为了提高系统的稳定性,一般会采用数据复制/镜像的方式,同时部署多个相同功能的节点提供服务,也就是A B C存储的相同的数据。有一个主节点提供读写服务,另外两个节点进行数据的复制,在MySQL中其实就是一主多从,在Redis其实也是一样的机制。而Kafka中呢,具体表现形式,也是通过多个节点进行构建集群模式。
但是为了提供系统的整体容量,也就是提供系统的高性能,一般单节点存储的数据量是有一定的上线,比如单台的MySQL存储上亿数据查询速度就比较慢,同样对于Kafka、Redis来说,其实他们存储的数据容量都受限于宿主机的配置,比如CPU、内存、磁盘、网络带宽等,所以为了提高系统的整体存储量,在不影响性能的前提下,大多会采用分片、切片、分库、分表模式进行数据存储。具体形式可能在不同的中间件表现形式不一样,但是只要是存储系统,很难逃脱以下几个问题
- 单点故障-> 采用集群模式 (数据复制/镜像)(目的:提供系统稳定性、高可用)
- 提升系统吞吐量-> 采用分片模式(数据分片)(目的:提升系统高性能)
- 一般集群只要涉及到数据一致性,都会用到共识算法,比如raft、paxos等。
你看进行釜底抽薪之后,发现其实存储中间件的本质都是一样的。比如MySQL中分片模式会采用分库分表,将数据存储到不同的节点上,以分摊数据压力,Kafka很巧妙的使用了集群模式+分片的机制。那么对于Redis是如何处理的呢?让我们开始学习。
如何保存更多数据
比如我们一下子存储25G的数据到Redis中,一般的配置服务器肯定是容纳不下,所以解决方案就是要么采用高配置的单实例要么就采用多实例,将25G的数据进行切分分别存储到不同的实例中。
其实就是横行拓展和水平拓展。
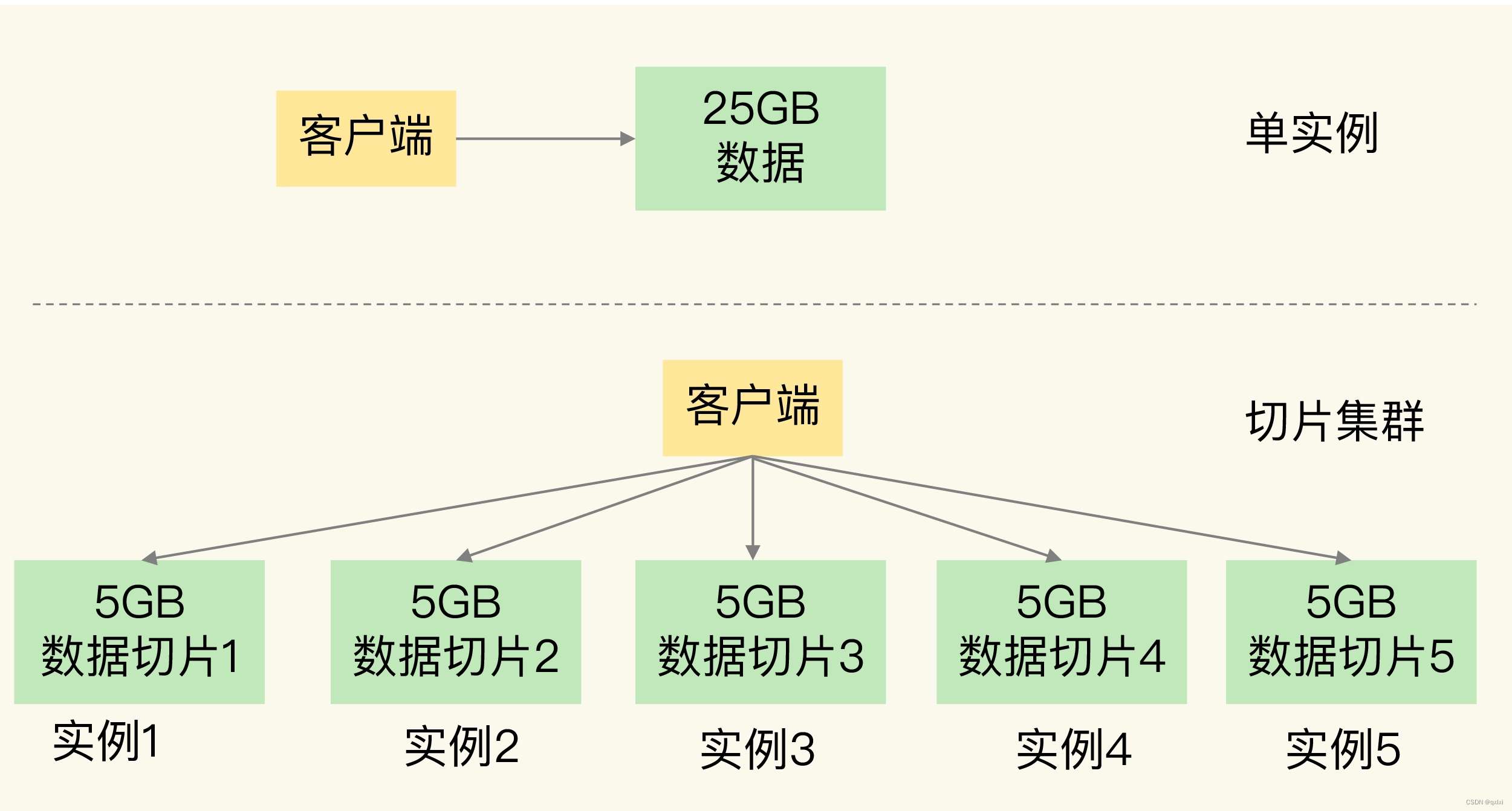
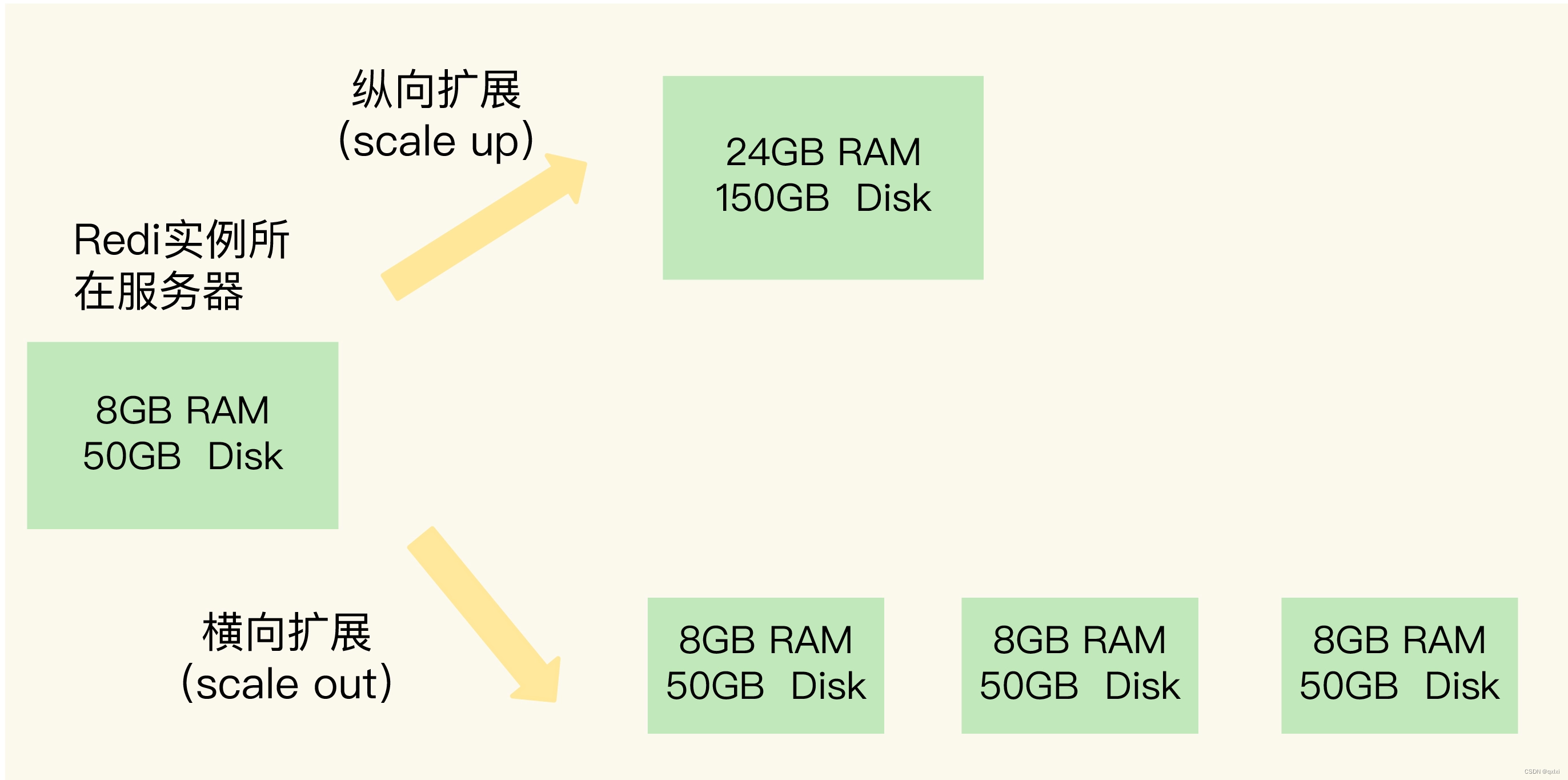
两种方式都有优缺点。
横行拓展:可以方便的进行添加实例,但是这样会引入数据如何进行存储到不同的实例中,肯定需要引入一个比较好的负载算法,这是存数据的过程,如何进行查询数据,也就是采用相同的算法,需要将数据在对应的实例中查询到。也就是两点,一个是数据切片和实例的对应关系如何查询和判断,另一个就是客户端查询数据的时候如何能查询到数据
纵向拓展:横行拓展说白了就是免去了上面的数据切片和实例这种关系维护,只要在一台机器上就可以存储和查询。坏处是单机的配置是有上限的,不可能无限的添加服务硬件配置。
数据切片和实例的对应分布关系
数据切片的实现方案有很多中,Redis Cluster属于一种方案,其中规定了数据和实例的对应规则。
其实就是Redis Cluster采用哈希槽的方案,分为16384个,通过key进行CRC16算法计算出对应16bit值,然后在对16834取模,就可以获取在那个对应的槽,而槽在那个实例也可以定位到。
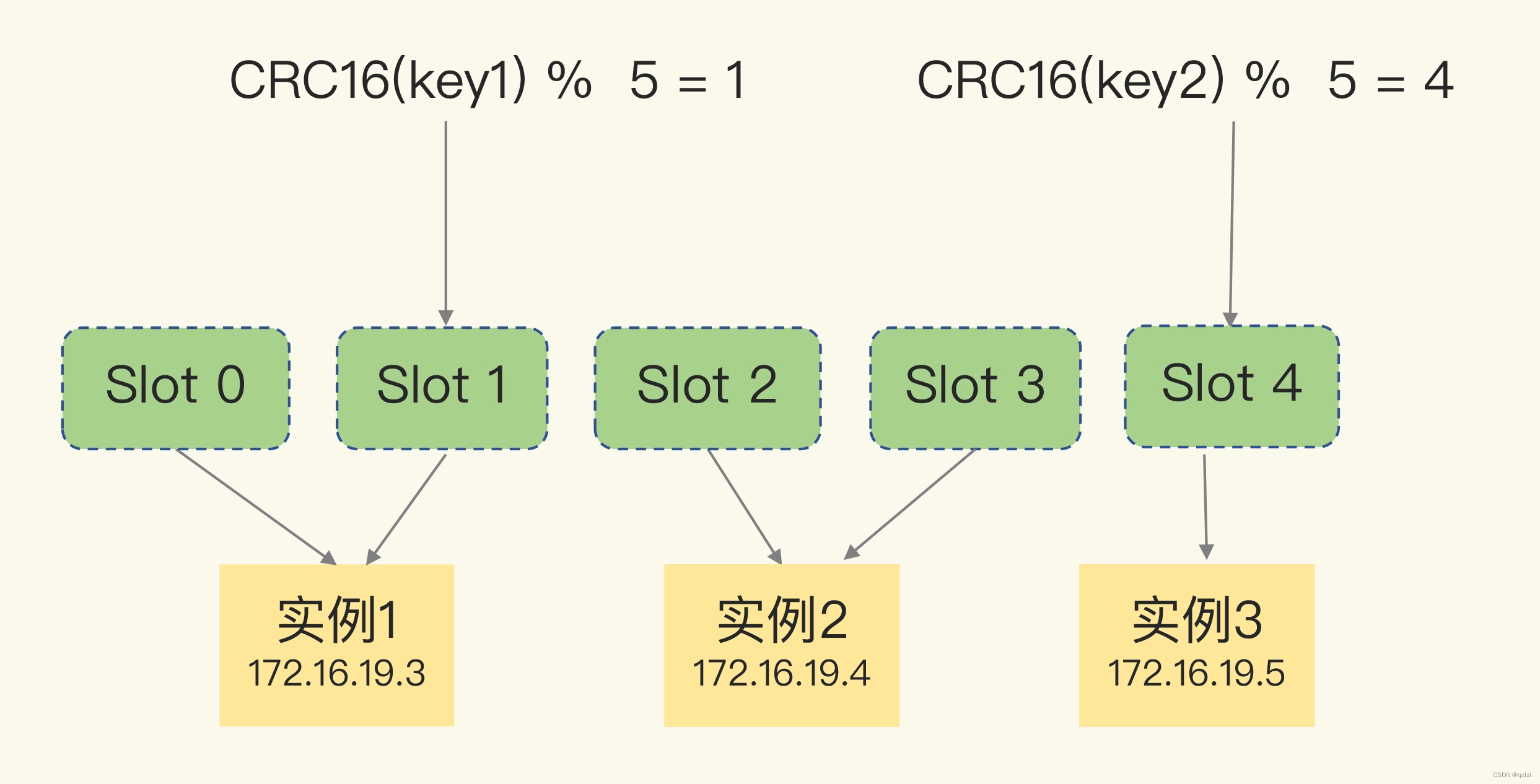
在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。
客户端如何定位数据
其实这个过程就是如何进行数据的读取,客户端在读取数据的时候,可以计算出数据在那个哈希槽,但是这个哈希槽在哪个实例上是不得而知的。客户端连接的是一个实例集群,所以每个实例知道自己所分配的哈希槽信息,在构建这个集群的时候,会进行哈希槽信息的扩散。而客户端随便连接任意一个实例都可以获取整个哈希槽分配的位置的信息。之后客户端进行获取数据,就可以把哈希槽分配信息数据存储到本地缓存。
这里的情况只是描述了一次分配哈希槽之后不会改变的情况,但是随着实例减少或者增加,会改变哈希槽分配信息的。以及为实现哈槽负载均衡,会进行动态的分配哈希槽。而这个过程其实有点类似于Kafka中rebalance过程,也就是随着消费者减少或者增加的时候,会进行消息的重新分配。你看解决问题的思路都是相同的。
那么针对上面的情况,Redis是如何解决的?
当出现哈槽槽变更的时候,客户端存储的是缓存的旧数据,因此两者之间的数据就不一致。解决方案也比较简单,通过重定向的方式,当访问哈希槽1的时候,客户端缓存的数据是在实例1中,但是由于负载均衡,哈希槽1分给了实例2,所以实例1会返回 move指令
get k1 v1
move 1 实例2ip:6379
这个时候客户端接受到实例1的MOVE指令,就会请求实例2,并将更新信息存储到本地缓存。
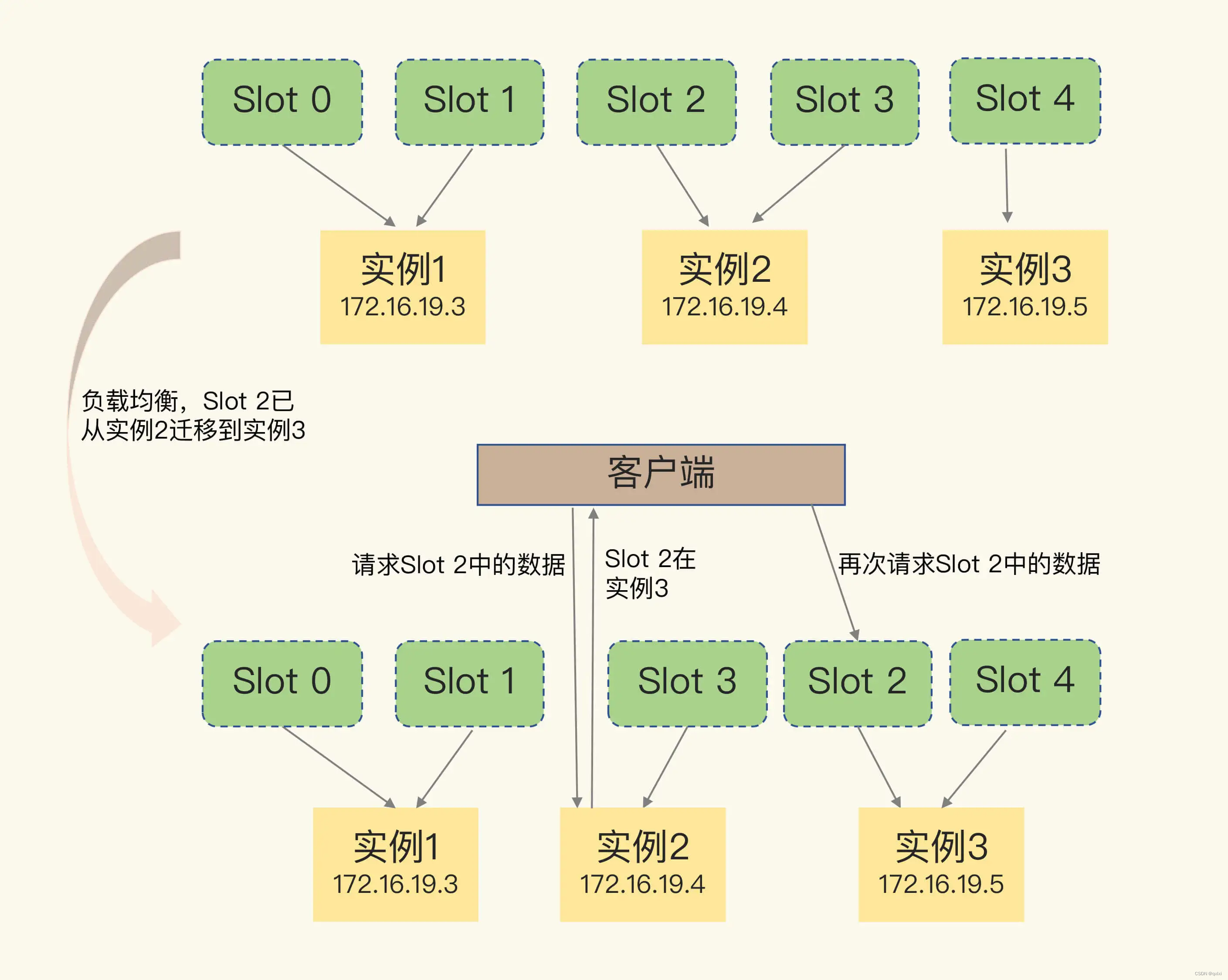
上面描述的是数据完全迁移成功的情况,但是如果数据没有迁移成功,而是还在处理中,如何解决?
其实,比较简单,说白了,比如客户端请求的哈希槽1 缓存信息是在实例1中,但是由于负载均衡,导致将哈希槽1数据分配给了实例2,这个时候客户端发送请求过来请求实例1,但是由于哈希槽1数据比较多,导致数据不能完全迁移过程,一个处理中状态。实例1会返回给客户端一个ASK命令,这个命令的含义有两层,一个是数据哈希槽1还没有完全迁移成功,二是会把最新的哈希槽1实例返回给你,你需要通过ASKing进行在请求哈希槽1的真正实例。接受发送获取数据的命令。
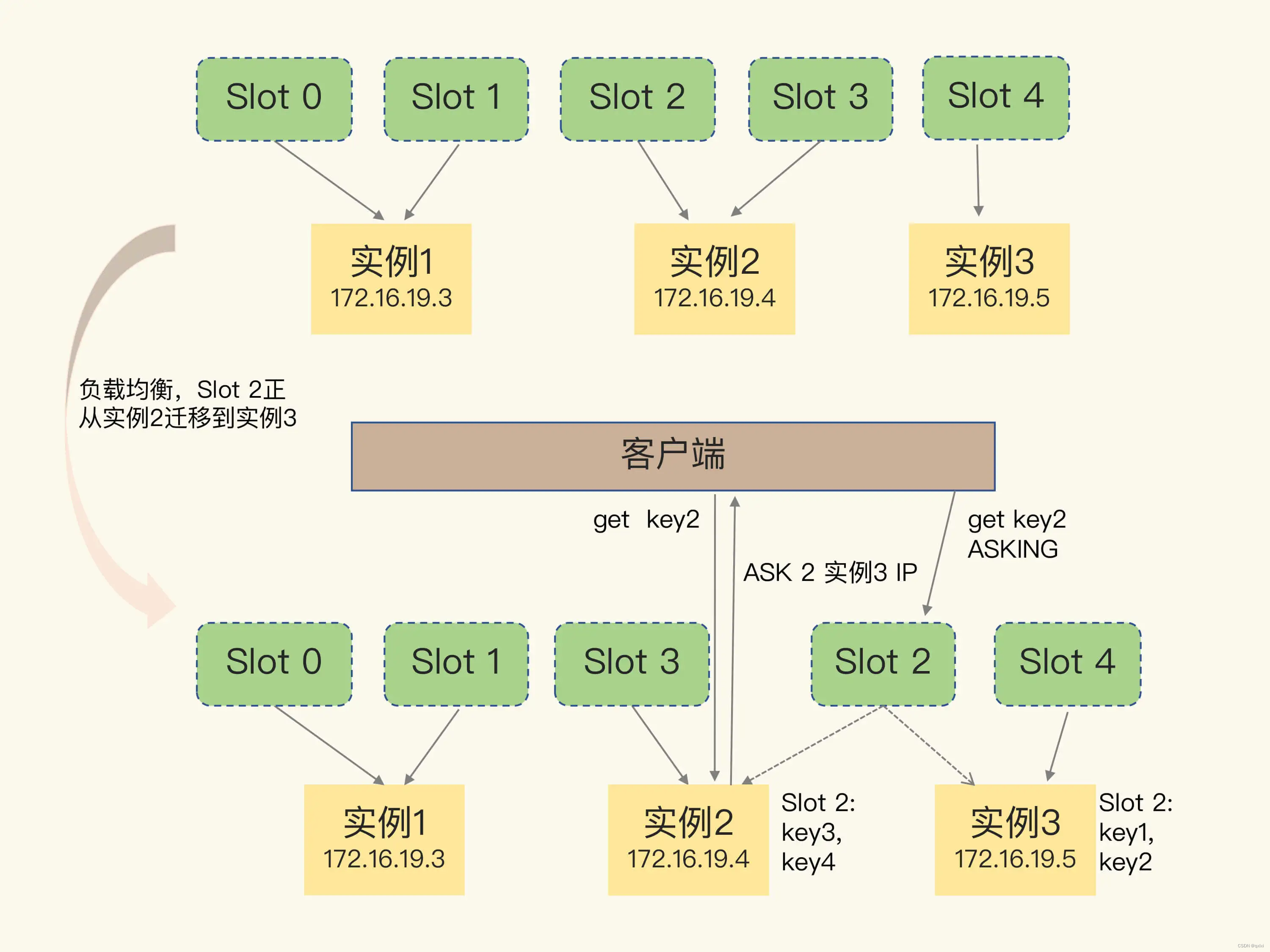
如果按照上述图中描述的说,整体流程就是如下
1.客户端请求Slot2,但是由于本地缓存数据存储的是实例2,所以会给实例2发送一个数据的请求。
2.实例2接受到请求后,发现这个数据已经在转移到实例3中,并且这个数据还没有完全迁移成功。所以会返回一个ASK的命令给客户端。
3.客户端接受到ASK命令就会请求发送给真正的实例3,先发送一个ASKING的命令,然后在发送获取数据的命令。
那么有同学就会问,MOVE和ASK的区别是什么?
MOVE会更新客户端本地哈希槽分配信息,但是ASK不会更新,ASK只会告诉客户端发送一条信息给新实例一个请求,而需要等数据完全同步之后,通过MOVE指令进行重定向到新的实例,这个时候才会更新客户端本地的哈希槽分配信息。
小结
本篇主要介绍了Redis分片集群的方式,用以保存大量数据的场景,以及切片之后数据的写入和读取问题。具体的就是哈希槽的分配机制,以及客户端的定位键值对的问题。ASK和MOVE指令,而这种方式也就是Redis Cluser。所以总结以下就是Redis 复制、Redis sentinel、Redis cluser。


![[数据结构习题]队列——用栈实现队列](https://img-blog.csdnimg.cn/5e936a0dc79247a9b1ff7e8c3daefec8.gif#pic_center)