背景
基于"encoding/csv"库解析。
共解析多个文档,只有这一个解析有问题,所用代码一致,进行比较后
发现该文档和其它文档不同,其它文档是第一行就是列名,下面都是数据;
而这个文档前两行有数据且分别仅占用了1列、2列,接下来几行为空,到第6
行才是每一列数据的列名,第7行为空,第8行开始往后才是真正数据。
文档看起来有点“特殊”。
解析代码
bs, err := ioutil.ReadFile("路径")
if err != nil {
return nil, err
}
r := csv.NewReader(strings.NewReader(string(bs)))
var records [][]string
records, err = r.ReadAll()
if err != nil { // record on line 2: wrong number of fields
return nil, err
}其实代码并无什么问题,但正是由于records, err = r.ReadAll()这一行解析这个“特殊”的文档时报错了。
难道对于这种不规则的文档、这个库就解析不了了吗?有的童鞋已经开始选别的库了,先别急,我们分析一下。
分析
第一,从报错入手。
看看文档中第二行是不是有错误的数据内容?第二行第一列是汉字,第二行第2列是日期,看起来是一堆的#号。
有什么问题吗? 当然没有,每个单元格的内容理论上你想写什么都可以的。
第二,那我们看看代码。
上面是通过ReadAll一次性拿到内容的,平时读取文件不也可以按行吗,又不是必须一次拿到,那就按行试试。
bs, err := ioutil.ReadFile("路径") // 这一步正常,暂不理
if err != nil {
return nil, err
}
r := csv.NewReader(strings.NewReader(string(bs)))
for line := 1; ; line++ {
var record []string
record, err = r.Read() // 验证发现空行会自动跳过
if err == io.EOF { // 到结尾就结束
break
}
// 到这里先不要判断err是不是有错,先打印本行数据看看是不是和文档内容一致
fmt.Println("line ", line, " record:", record)
// 由于第6行才到列名,前面5行内容我们不需要,可以专门控制
if line < 5 {
if err != nil { // 看看前面五行是什么妖魔鬼怪
fmt.Println("前5行出现报错:", err)
err = nil
}
continue
}
// 是正常数据,就放到records中
if len(record) > 0 {
records = append(records, record)
continue
}
// 最后再看是不是出错了,有问题这行就先不管
// 让continue继续看后面的数据有无类似问题,如果没有那就是本行的问题
if err != nil {
fmt.Println("line ", line, " 报错:", err)
continue
}
}这样得到的结果完美,其中的报错并对正常结果无影响。而如果把最后一个if err != nil
放在if line < 5的前面,你就会发现不停的在报错:
record on line 2: wrong number of fields
record on line 4: wrong number of fields
record on line 6: wrong number of fields
record on line 8: wrong number of fields
record on line 9: wrong number of fields
record on line 10: wrong number of fields
record on line 11: wrong number of fields
...无穷匮也。如图:
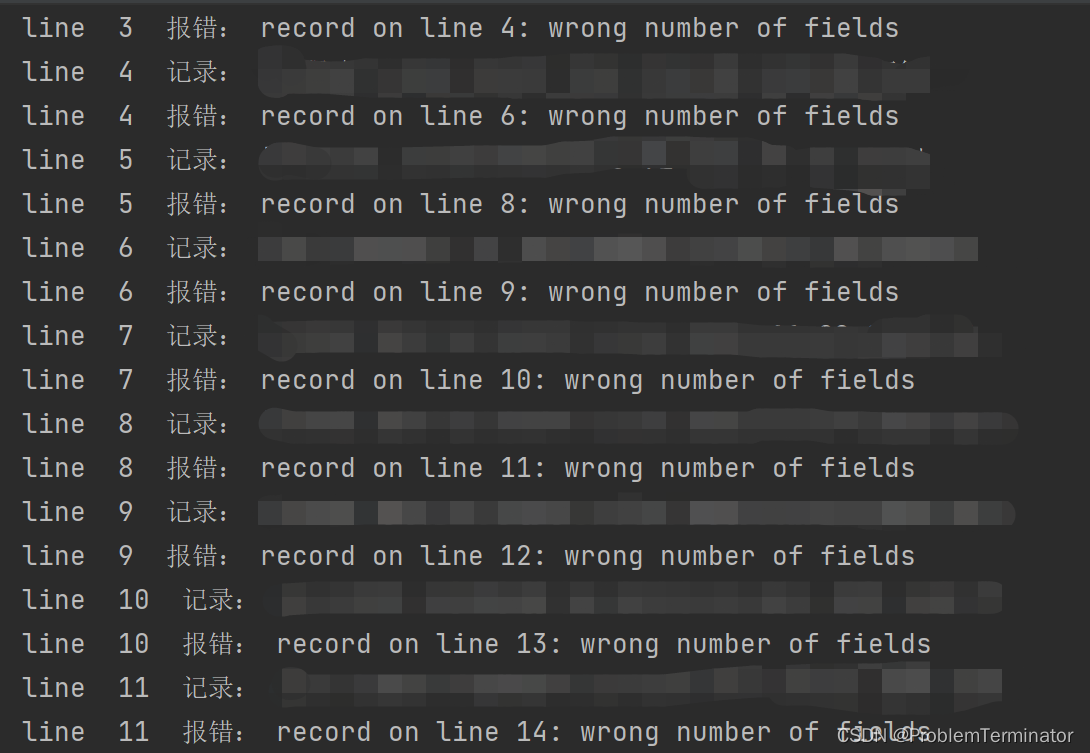
同时record那行打印也一直在打印正常数据。
每行都错,错在谁?
第8行开始是正常数据,而从第8行开始每行都有这个报错,难道是文档问题吗,肯定不是了。
所以综合来看,按如上处理即可达到正常效果,有些错误你看看就行。