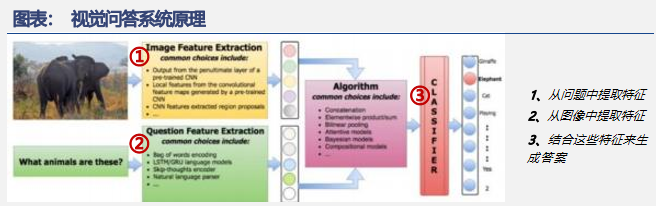
1.摘要
深度学习是红外和可见光图像融合领域中快速发展的方法。在这个背景下,密集块在深层网络中的使用显著提高了浅层信息的利用率,并且生成对抗网络(GAN)的组合也提高了两个源图像的融合性能。我们提出了一种基于密集块和GAN的新方法,并直接将输入图像 - 可见光图像插入到整个网络的每一层中。我们使用结构相似性和梯度损失函数,这些函数比均方误差损失更符合感知。在生成器和鉴别器之间的对抗性训练之后,我们展示了最终得到的训练端到端融合网络 - 生成器网络。我们的实验表明,我们方法获得的融合图像在多个评估指标方面得分良好。此外,我们的融合图像在多组对比度方面具有更好的视觉效果,更符合人类视觉感知的要求。
2.引言
随着深度学习的发展,深层网络的特征提取和数据表示能力变得越来越有吸引力。深度学习在计算机视觉领域是一个极为优秀的应用,同时在图像融合领域有许多出色的方法。在小于十层的浅层神经网络中有许多有效的方法,比如卷积神经网络(CNN)或稀疏自编码器(SAE)可以用于中间层,作为权重计算工具来确定特征并得到两个源图像的权重图,然后根据权重图融合图像。此外,可以使用密集块(Densefuse)或PCANet的主成分分析滤波器提取一组特征,然后在中间层将这些特征进行融合。最终,通过特定的解码操作过程得到融合图像。
在深度学习网络中,还可以使用预训练模型,如VGGNet 和ResNet 来提取深度特征并进行融合,重建的特征可以生成融合图像。除了将神经网络作为特征提取工具外,它也可以直接作为端到端的图像融合网络。例如,FusionGAN 这样的代表性工作中,其生成器网络通过适当的损失函数直接从源图像生成理想的融合图像。
近年来,随着生成对抗网络(GAN) 的快速发展,图像可以生成具有足够的信息和良好的视觉效果。这些方法被广泛应用于超分辨率、语义分割和图像增强。GAN也可以用于图像融合。在FusionGan中,Ma等人首次使用GAN来融合图像。通过将源图像添加到GAN网络的生成器中,生成器可生成一个包含源图像特征信息的融合图像。==在生成器中设计适当的损失函数来控制融合图像的结构,==鉴别器则提高了融合质量。然而,融合图像不稳定,其融合效果不够自然,如图1©所示。虽然红外图像中的特征信息可以被提取出来,但融合图像失去了源图像的边缘和细节纹理信息。在接下来的一年中,Ma等人提出了两种基于GAN的改进网络,如DDcGAN和ResNetFusion,表现出了出色的性能。但它们存在模糊、丢失细节和融合图像感知效果较差的缺点。在这种情况下,我们认为网络在融合过程中会失去一部分源图像特征,需要补充细节纹理信息的损失。

为了提高GAN的端到端融合质量,本文提出了一种新的GAN网络框架。为了增加细节信息,我们在生成器中使用了密集块,并且将具有更丰富细节特征的浅层和源图像与深层进行级联。此外,我们在每层级联可见光图像,从而使融合图像保留更多的可见信息。
同时,为了使融合图像的结构与源图像都有相似性,而不仅仅是可见光图像,我们在生成器中加入了结构相似性损失函数和梯度损失来控制生成图像与源图像之间的结构相似性。另一方面,鉴别器的作用是将融合图像与可见光图像进行比较并得到损失值。因为可见光图像通常具有更好的视觉效果,更符合人类审美感知。鉴别器的作用是让融合图像更接近于可见光图像,以增强融合图像的视觉效果。在我们提出的网络中,生成器是一个端到端的融合网络。图像融合不需要提取特征以计算权重图或设计出优秀的融合策略。该方法采用生成器直接生成所需要的融合图像。生成器网络仅有五层。网络模型在训练之前使用大量的图像进行预训练,以便生成器能够快速生成融合图像。因此图像融合实现了实时效果。实验证明,我们的方法具有出色的融合效果,如图1(d)所示。
我们的贡献概述如下:
(1) 我们将密集连接应用作生成的主干网络,使用可见光跳跃连接来融合来自可见光的图像纹理信息,这是一种简单但非常有效的方法,可以增强融合图像的纹理细节。
(2) 我们放弃了常见的均方误差损失函数作为内容损失函数,并用结构相似性损失和梯度损失进行替代。
(3) 此外,我们仅计算图像与可见光图像之间的对抗性损失,以确保生成的图像足够真实和自然。
为什么很多基于GAN网络的红外和可见光图像融合 鉴别器只和可见光图像进行比较?
答:很多基于GAN网络的红外和可见光图像融合中,鉴别器只和可见光图像进行比较是因为可见光图像通常具有更好的视觉效果和更符合人类感知的要求,而红外图像中的光谱信息则对应着物体的温度分布和热辐射信息等,在图像融合中起到不同的作用,因此保留可见光图像的特征可以在融合后使图像更加符合人类的观感要求。同时,通过只与可见光图像进行比较可以使鉴别器更加专注于区分出真实和虚假的融合图像,而避免对红外图像信息产生过大的噪声干扰。
3.方法
3.1 Network framework
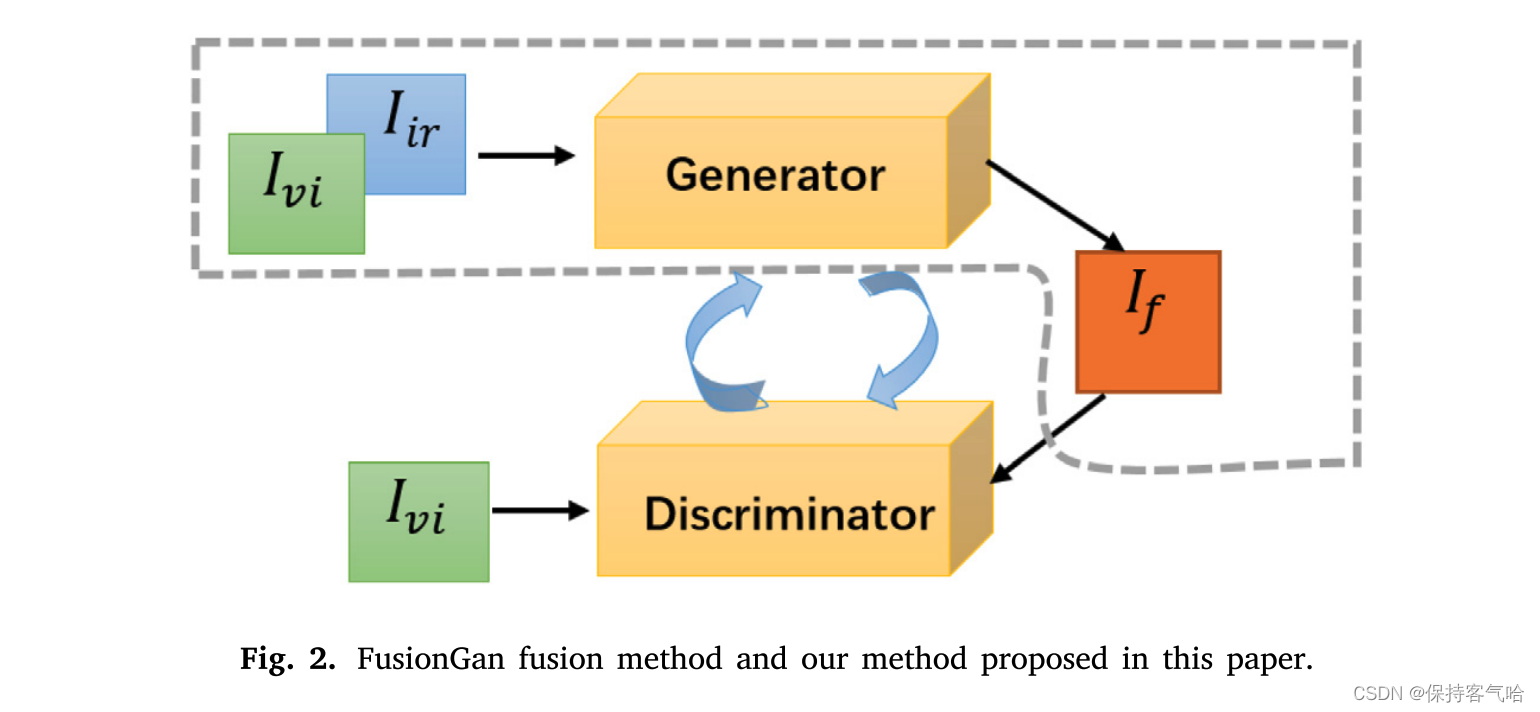
我们的网络由生成器和鉴别器组成。在训练阶段,图2所示的网络将红外图像 I i r I_{ir} Iir和可见光图像 I v i I_{vi} Ivi串联作为生成器G的输入。经过5层卷积和密集块串联操作,获得融合图像 I f I_f If。然后,将可见光图像 I v i I_{vi} Ivi和融合图像 I f I_f If作为输入输入到鉴别器D中进行对抗训练。 这里只将可见光图像输入到鉴别器中,而不是源图像。因为鉴别器判断生成器生成的图像是否足够“真实”或“自然”,鉴别器可以参考可见光图像强制生成器生成更自然的图像。我们方法的“自然”结果可以在第4.2.1节——主观评估中找到。换句话说,鉴别器的损失可以改变生成器生成的图像的风格,但对于生成器从源图像获取详细信息的数量影响不大。为了获得自然的图像,我们决定将可见光图像和融合图像输入到鉴别器中,而不是两个源图像。 在测试阶段,鉴别器D没有使用,只保留生成器如图2所示的灰色框中。将红外图像 I i r I_{ir} Iir与可见光图像 I v i I_{vi} Ivi串联作为输入到生成器中,以获得融合图像 I f I_f If。
3.1.1. Generator network
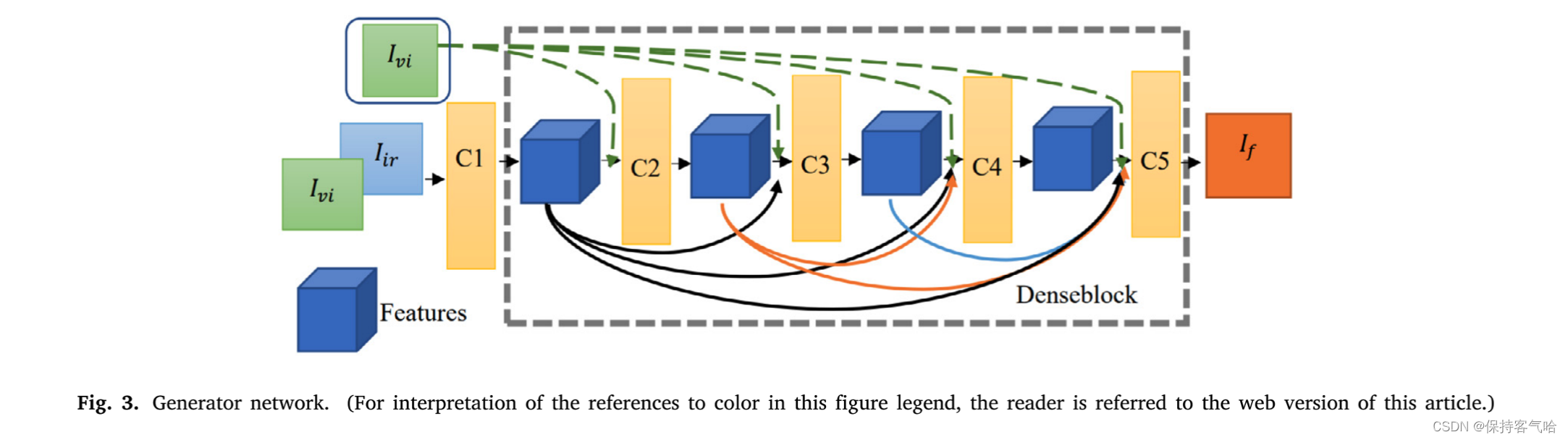
如图3所示,生成器网络G基于一个简单的卷积神经网络。可见光图像 I v i I_{vi} Ivi和红外图像 I i r I_{ir} Iir作为生成器网络的输入图像进行串联。
- 第一层包含一个5×5的卷积核,用于提取浅层特征。如图3中的灰色框所示,
- 第二到第五层形成了一个密集块卷积层,每层的输出都连接到所有后续层作为输入传递到下一层。
- 第二层使用5×5的卷积核扩大浅层网络的感受野。
- 第三到第四层使用3×3的卷积核减少网络参数。
- 第五层使用1×1的卷积核将串联特征的维度降到单通道图像上,以实现特征融合,从而以端到端的方式获得融合图像 I f I_f If。每个层后面都有批量归一化层,前四层使用Leaky ReLU激活函数,第五层使用Tan激活函数。我们选择Leaky ReLU作为激活函数,因为ReLU激活函数会丢弃CNN的负阈值神经元。这可能会使输出变得稀疏,但不适用于需要保留大量信息的图像融合任务。此外,密集块使网络前几层的浅层信息特征被尽可能地重复使用。对于深层次的图像细节,如颜色和边缘轮廓的保留得很好。
此外,像DenseFuse、DeepFuse等重构网络不能在中间层串联源图像,这会导致网络通过跳跃连接秘密复制源图像到输出层。然而,在我们的方法中,我们在融合图像和两个源图像之间计算多个有效的损失,必须能够生成包含两个图像信息的图像。基于这一点,我们创新性地直接在中间层串联可见光图像。这可以保留更多可见光图像信息,而不会丢失红外信息。我们使用可见光图像 I v i I_{vi} Ivi作为输入图像的一部分。如图3中的绿色虚线连接所示,我们的网络在每一层中串联 I v i I_{vi} Ivi,以补充特征的细节纹理信息。 直接在网络的每一层插入输入图像可以使网络更容易学习可见光图像信息。对于可见光图像,我们希望保留其原始细节,因此可见光图像的跳跃连接等价于使用不同深度的网络提取可见光图像的特征。因此,可见光图像的基本信息已从多个深度的网络中提取出来,可以获得其语义信息,并尽可能地保留其纹理信息。我们认为,红外图像的更重要的信息是辐射信息,这是一种局部语义信息,因此我们没有在中间层使用跳跃连接,并使用最深的网络提取红外图像的语义信息。
3.1.2. Discriminator network
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k3h8ZSP1-1685499668975)(/Users/zhangkai/Library/Application Support/typora-user-images/image-20230530193654165.png)]](https://img-blog.csdnimg.cn/929b8c5eeff34266b9ca6edec9b39140.png)
如图4所示,鉴别器网络由四层卷积层和一层全连接层组成。网络的输入图像为可见图像 I v i I_{vi} Ivi或生成器的融合图像 I f I_f If。每个卷积层后面都有一个最大池化层。前四层使用Leaky ReLU激活函数,最后一层使用Tanh激活函数的全连接层。鉴别器网络的输出是一个标签,表示输入图像是真实图像还是融合图像。
3.2. Loss function
这里的策略是将红外图像 I i r I_{ir} Iir和可见光图像 I v i I_{vi} Ivi拼接起来,将它们输入到鉴别器G中,得到一个融合后的图像 I f I_f If。为了使融合后的图像 I f I_f If更趋向于可见光图像 I v i I_{vi} Ivi,我们将它们输入到鉴别器中以区分它们。鉴别器D为生成器G提供损失,使G能生成具有更好视觉效果的融合后的图像。
3.2.1. Discriminator loss function
为了使鉴别器能够更好地区分融合图像和可见光图像,这里使用LSGAN的损失函数。鉴别器的损失函数如下:
L D = 1 N ∑ n = 1 N ( D ( I v i n ) − b ) 2 + 1 N ∑ n = 1 N ( D ( I f n ) − a ) 2 L_{D}=\frac{1}{N} \sum_{n=1}^{N}\left(D\left(I_{v i}^{n}\right)-b\right)^{2}+\frac{1}{N} \sum_{n=1}^{N}\left(D\left(I_{f}^{n}\right)-a\right)^{2} LD=N1n=1∑N(D(Ivin)−b)2+N1n=1∑N(D(Ifn)−a)2
其中𝑛∈ℕ,𝑁代表融合图像的数量, I v i n I^n_{vi} Ivin代表第𝑛个可见光图像, I f n I_{f}^{n} Ifn代表第𝑛个融合后的图像。目的是使鉴别器能够区分 I v i n I^n_{vi} Ivin和 I f n I_{f}^{n} Ifn,使 I f I_f If更偏向于可见光图像,这是更真实、自然的,从而提高融合图像 I f I_f If的视觉效果。
在这里,我们只计算可见光图像和融合后的图像的损失。根据GAN的理论,鉴别器只用于图像分类。传统的融合图像保留了红外信息,但也保留了红外图像中模糊和昏暗光的特征,图像往往呈灰色。==在我们的网络中,鉴别器中可见光图像和融合图像之间的损失可以迫使生成器生成明显的图像而不是灰色的图像。==换句话说,以前的融合方法的大部分融合结果都是在学习红外图像和可见光图像之间不同分布的平均数据分布。它们生成的融合图像更像是红外图像和可见光图像的插值图像。鉴别器将融合图像的数据分布移动到可见光图像的数据分布,使得融合结果看起来更自然。我们的鉴别器用于增强融合图像的视觉效果,符合人类美学。对于红外信息的融合,主要依靠生成器损失函数中的内容损失。
3.2.2. Generator loss function
生成器使用LSGAN生成器损失函数作为其损失函数,如下所示:
L L S G A N ( G ) = 1 N ∑ n = 1 N ( D ( G ( I f n ) ) − c ) 2 L_{LSGAN}(G)=\frac{1}{N}\sum_{n=1}^N(D(G(I_f^n))-c)^2 LLSGAN(G)=N1n=1∑N(D(G(Ifn))−c)2
其中𝑏=𝑐=1,𝑎= 0。通过修改生成器的损失函数,我们希望生成器能够保证融合图像保留源图像的细节。因此,将内容损失函数 L c o n t e n t L_{content} Lcontent(见下文)添加到损失函数中,如下所示:
L G = L L S C A N + γ L c o n t e n t L_G=L_{LSCAN} +\gamma L_{content} LG=LLSCAN+γLcontent
其中𝛾是一个超参数,用于平衡两者的权重,在我们的论文中,该值𝛾= 100。
在以前的图像融合方法中,作者通常使用 L 2 L_2 L2损失函数或均方误差损失。这种损失函数存在以下缺点:
1.与小误差相比,MSE对大误差更敏感,这会使生成的图像趋于平滑。
2.网络直接对生成的图像和原始图像施加像素级别的约束,而不考虑图像的整体结构,这会使生成的图像趋于红外和可见光图像的平均图像-灰色图像。
基于这个想法,我们放弃了MSE损失函数。考虑到融合图像和原始图像之间的结构相似性,我们将 S S I M f SSIM_f SSIMf损失添加到损失函数中。为了使 I f I_f If能从 I i r I_{ir} Iir和 I v i I_{vi} Ivi中提取更多细节,我们将 G r a d i e n t f Gradient_f Gradientf损失添加到损失函数中。损失函数如下所示:
L c o n t e n t = ( 1 − S S I M f ) + α G r a d i e n t f L_{content}=(1-SSIM_f)+\alpha Gradient_f Lcontent=(1−SSIMf)+αGradientf
其中𝛼是一个超参数,用于平衡两个损失值的权重,在我们的论文中,该值为𝛼= 5。
其中, S S I M f SSIM_f SSIMf分别针对 I v i I_{vi} Ivi、 I i r I_{ir} Iir和 I f I_f If之间的结构相似性进行计算。两个值乘以0.5后相加。相似度计算算法𝑆𝑆𝐼𝑀(𝑥, 𝑦)是计算两个图像𝑥和𝑦之间亮度、对比度和结构差异的值。计算公式如下:
SSIM ( x , y ) = ( 2 μ x μ y + c 1 ) ( 2 σ x y + c 2 ) ( μ x 2 + μ y 2 + c 1 ) ( σ x 2 + σ y 2 + c 2 ) S S I M f = SSIM ( I f , I v i ) + S S I M ( I f , I i r ) 2 \begin{array}{l} \operatorname{SSIM}(x, y)=\frac{\left(2 \mu_{x} \mu_{y}+c_{1}\right)\left(2 \sigma_{x y}+c_{2}\right)}{\left(\mu_{x}^{2}+\mu_{y}^{2}+c_{1}\right)\left(\sigma_{x}^{2}+\sigma_{y}^{2}+c_{2}\right)}\\ S S I M_{f}=\frac{\operatorname{SSIM}\left(I_{f}, I_{v i}\right)+S S I M\left(I_{f}, I_{i r}\right)}{2} \end{array} SSIM(x,y)=(μx2+μy2+c1)(σx2+σy2+c2)(2μxμy+c1)(2σxy+c2)SSIMf=2SSIM(If,Ivi)+SSIM(If,Iir)
其中𝜇表示平均值,𝜎表示标准差。𝑆𝑆𝐼𝑀越大,两者之间的结构相似性越高。在中 L c o n t e n t L_{content} Lcontent,我们期望的𝑆𝑆𝐼𝑀更大,所以我们取(1 − S S I M f SSIM_f SSIMf)作为的一部分 L c o n t e n t L_{content} Lcontent。
𝐺𝑟𝑎𝑑𝑖𝑒𝑛𝑡(𝑥,𝑦)计算𝑥,𝑦之间的梯度差如下所示:
Gradient ( x , y ) = 1 M ∑ n = 1 M ( ∇ x − ∇ y ) 2 \operatorname{Gradient}(x, y)=\frac{1}{M} \sum_{n=1}^{M}(\nabla \mathrm{x}-\nabla \mathrm{y})^{2} Gradient(x,y)=M1n=1∑M(∇x−∇y)2
G r a d i e n t f = Gradient ( I f , I v i ) + β Gradient ( I f , I i r ) Gradient _{f}=\operatorname{Gradient}\left(I_{f}, I_{v i}\right)+\beta \operatorname{Gradient}\left(I_{f}, I_{i r}\right) Gradientf=Gradient(If,Ivi)+βGradient(If,Iir)
其中𝑀是图像的像素数,是梯度计算操作,并且𝐺𝑟𝑎𝑑𝑖𝑒𝑛𝑡(𝑥,𝑦)被计算为具有2范数的平均值𝐿。𝛽 是超参数,用于平衡和的梯度权重
I
v
i
I_{vi}
Ivi、
I
i
r
I_{ir}
Iir。在我们的论文中,值𝛽= 2。
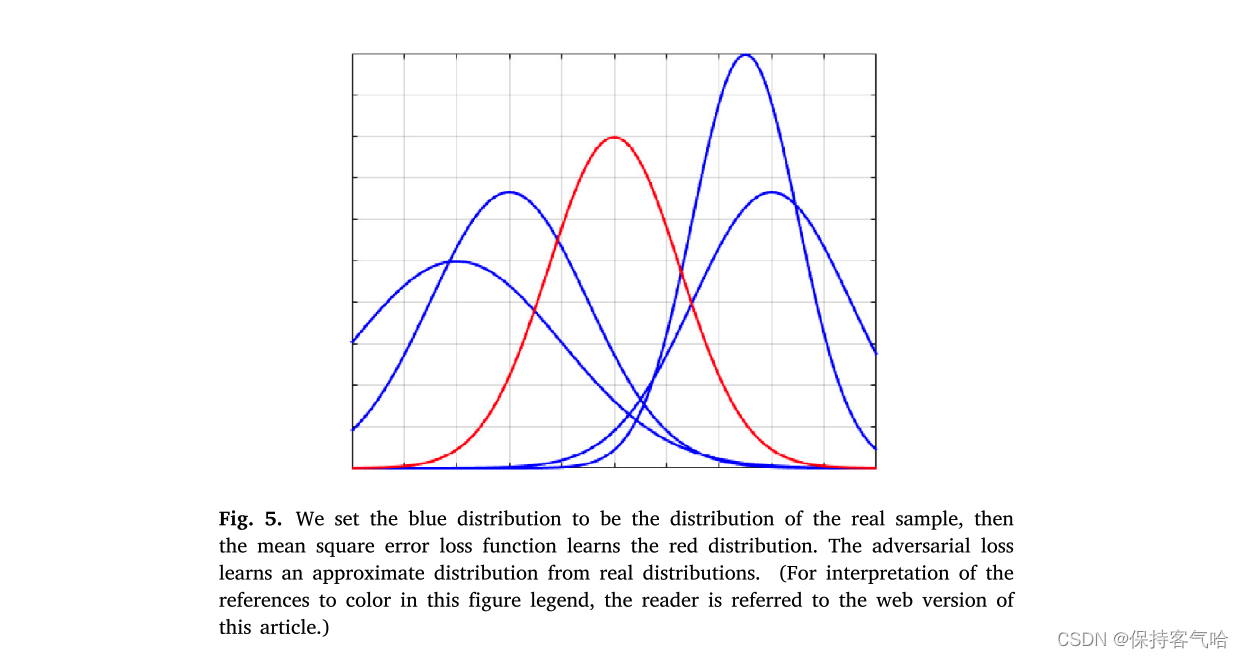
我们不使用均方误差损失函数,因为均方误差损失会使生成器生成的数据分布成为所有样本分布中的一个平均值,如图5所示。我们认为对抗性损失是一种更合理的损失函数,它使生成器能够随机选择一个“真实”的数据分布生成它来欺骗鉴别器。融合图像不易模糊,看起来足够自然。此外,我们必须确保生成的图像与输入图像保持足够的结构相似性和一定的边缘信息,因此我们添加了设计的内容损失。
3.3. Network framework parameters
3.3.1. Generator parameters
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X2Ni8AAf-1685499668975)(/Users/zhangkai/Library/Application Support/typora-user-images/image-20230530201950055.png)]](https://img-blog.csdnimg.cn/16bfb8d1211a4529b06e6e4ed69799a0.png)
生成器是一个带有denseblock的卷积神经网络。第一层和第二层都使用3×3的滤波器。第三层和第四层都使用3×3的滤波器,第五层使用1×1的滤波器进行通道维度降维操作。步幅设置为1,填充设置为SAME。为了使特征拼接后保持相同的形状,我们没有进行下采样操作。为了避免网络梯度的消失,在卷积层的每一层后添加批归一化层和非线性激活函数可以使网络更加稳定。对于激活函数,前四层选择Leaky Relu激活函数,最后一层选择Tanh激活函数。生成器网络的详细网络参数如表1所示。
3.3.2. Discriminator parameters
鉴别器的前四层是卷积神经网络,具有带有Leaky ReLU激活函数的激活层和最大池化层。第四层获得的特征被重新塑造为一个通道。最后一层是完全连接层,使用Tanh激活函数获取分类结果。鉴别器的详细参数如表2所示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-peen8X8p-1685499668976)(/Users/zhangkai/Library/Application Support/typora-user-images/image-20230530202052955.png)]](https://img-blog.csdnimg.cn/e2feeb9b4cef460f8f4bc8f062c4ea73.png)
4.实验
4.1. Training and test details
我们从TNO数据库中选择了59对不同的红外图像和可见图像作为网络的训练数据集。为了解决现实中源图像的大小可能不同的问题,每对源图像的像素大小不同。训练图像的最大像素大小为678×917,最小像素大小为256×256。注意,仅使用59对图像进行网络模型的训练是不够的。每个图像通过设置步长为14进行裁剪,大小为120×120像素。然后我们得到了54842对图像。每个裁剪后的图像的像素大小均为120×120。整个数据集随机分为两部分:70%的数据用于训练,其余30%用于测试。
在训练阶段,我们选择批量大小为s对源图像作为输入。首先,我们训练判别器M次以使模型训练良好。然后仅训练一次生成器。重复上述操作直到达到最大迭代次数K。优化器选择Adam。在本实验中,实验设置如下:判别器训练次数M=2,网络最大迭代次数K=50,批量大小s=32。
通常,判别器比生成器更容易收敛。传统的GAN网络通常用于将噪声转换为伪造的图像,因此我们的判别器只完成分类任务,所以它会快速收敛,我们首先训练了判别器M次。因此,在中间层中特征提取和融合后,生成器很容易生成融合图像。此外,源图像被输入到生成器中,并且我们还将源图像连接到中间层中,如图3所示。
4.2. Fusion evaluation
4.2.1. Subjective evaluation
融合图像经常用于生产或实践中。因此,这里使用的主观评价是融合图像的视觉效果,如颜色、亮度、保真度等比较抽象的判断。即融合后的图像是否给人以满意的感觉。本文的主观评价方法是对同一组图像的融合图像列出不同的算法,直接比较视觉效果.

Fig. 6展示了端到端的GAN(生成对抗网络)具有的优势,即生成的图像不仅可以包含源图像信息,还可以包含丰富的对比度和梯度信息。我们的算法扩展了图像中物体和周围环境的区分。可见图像中的边缘纹理信息以及红外图像中所需的辐射信息在融合图像中得到更好的体现。

在图11中,对于房屋和植物的细节,大多数方法都存在严重的信息损失或低对比度,融合结果不自然。例如,房子前的垃圾桶和电话亭里的男子在我们的方法中非常明显。天空由树枝构成的前景纹理很明显。此外,我们的图像看起来非常自然。在DenseFuse方法中生成的图像更加自然,但是红外细节丢失了很多。此外,我们的方法保留了很多显然的植物细节以及墙壁信息。


在图12和13中,我们的方法同样出色。我们的图像不仅保留了足够的红外辐射信息,还保留了背景复杂纹理信息,并且小目标的显示也非常清晰明了。作为主观评价的一个重要点,我们的图像感知效果非常好,看起来自然。


同时,我们还在RoadScene数据集中选取并展示了两个主观评估结果(见图14和15)。我们的结果具有更明显的纹理信息,图像看起来更自然。
显然,其他方法生成的大多数结果类似于红外图像和可见光图像的插值图像,生成的结果整体上看起来灰暗。此外,我们的方法具有视觉上令人印象深刻的效果。这是因为我们使用更加感知的结构相似性(SSIM)损失和梯度损失来代替简单粗暴的均方误差(MSE)损失。SSIM损失关注图像的结构信息,包括对比度信息。梯度损失则确保图像保留足够的边缘轮廓信息。最后,生成对抗网络(GAN)损失让生成的图像具有更好的视觉效果

如图7所示,也存在一些失败案例。例如,由于对比度降低,水面和草地之间的分界线变弱了。云层中的掩体与红外图像中不够明显。我们相信我们提出的方法将更加专注于这些问题的解决
4.2.2. Objective evaluation
然而,主观评价很主观。因此,引入了十个重要的客观评价方法进行比较
EI主要表示边缘信息和相邻像素的对比强度。SF表示图像中变异数量,例如边缘和线条。EN基于信息论定义,可以测量融合图像中所含有的信息量。SCD计算源图像和融合图像的差异图像,然后将相关系数作为SCD的值。这反映了源图像和差异图像之间的关联性。CrossEntropy值越大,图像之间的信息差异越大。MI表示两个图像之间的相关度。VIF和VIFF都用于测量图像信息在失真过程中的损失。DF指示图像是否清晰。标准差可以在一定程度上代表图像的对比度。
其中,CrossEntropy和𝑁𝑎𝑏∕𝑓值越小,其他值越高,图像的融合质量就越好。
与现有技术方法的比较,这些方法可分为以下几类:
- 基于图像处理而不是深度学习的方法,例如LP、RP、DTCWT、CVT、MSVD、NVCE、HybridMSD、IFEVIP。它们使用滤波器或图像分解进行图像特征提取和融合。
- 基于深度学习自编码器的方法,例如Densefuse、Deepfuse、Nestfuse。它们使用编码器提取特征,并在潜在层进行特征融合。
- 一些方法基于单步融合网络,例如FusionDN、PMGI和U2fuion,使用合理的网络结构和损失函数。
- 基于GAN网络,这是我们方法的主要对比方法,例如FusionGAN、DDcGAN、ResNetFusion和MEF-GAN。它们的生成器类似于第三种单步方法,但使用鉴别器进行对抗生成以提高融合图像的质量。
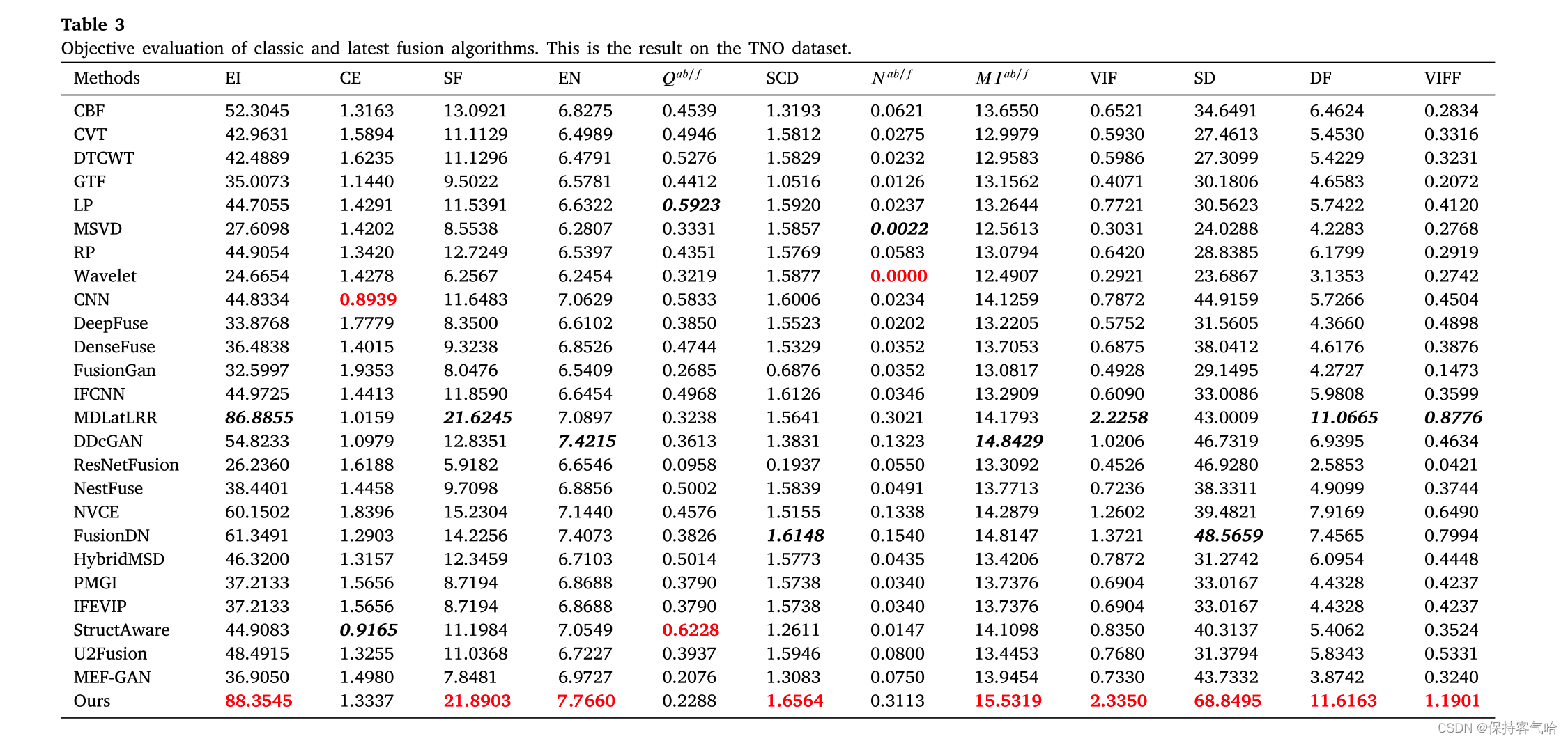
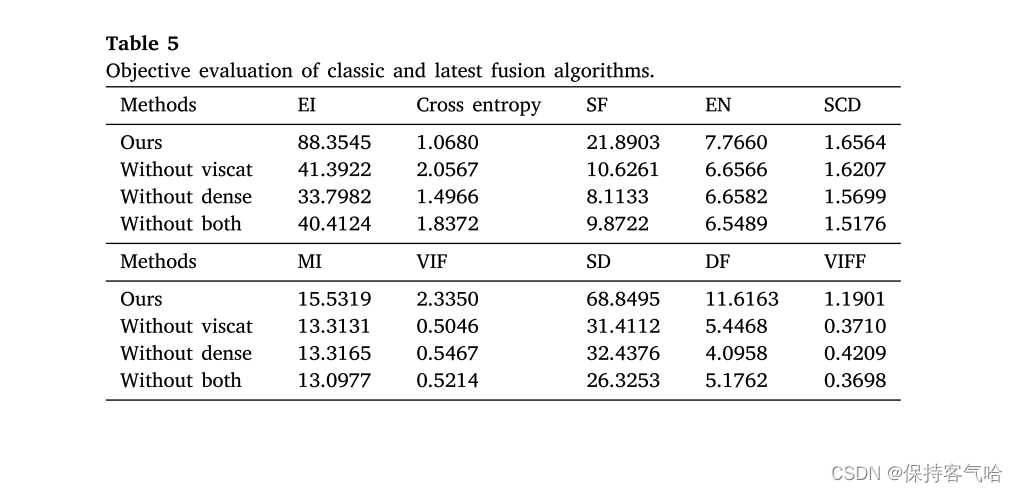
针对客观评估,我们选取了十二个融合评价指标进行比较,结果如表3所示。质量表中的最佳值用粗体红色字体突出显示,次优值在黑色方框中以斜体呈现。可以看出,我们提出的方法在九个指标(EI、SF、EN、SCD、MI、VIF、SD、DF、VIFF)上取得了最佳值。其中EI和SF指标中的最佳值为我们的方法,这意味着我们提出的算法的融合图像提取了更多的边缘信息和细节信息。EN指标中的最佳值也是我们的方法,这意味着融合图像包含更多的信息。在SCD和MI指标中获得了两个最优值,表明融合图像充分保留了源图像的信息,且融合图像更接近源图像。在VIF和VIFF指标中,我们的方法也获得了最佳值,这意味着融合图像更真实自然。DF和SD的两个最优值表明我们的图像有较高的图像对比度。
𝑄𝑎𝑏∕𝑓和𝑁𝑎𝑏∕𝑓的不良结果意味着我们的融合图像可能有更多的噪声。我们认为这个结果的原因是损失函数缺乏像素级均方误差损失和对抗性损失的影响。均方误差损失可以让网络学习所有样本分布的平均分布,生成的图像不会有太多的噪声。在GAN网络的生成中,生成器更容易生成“真实”样本分布。同时,它也受到梯度损失的指导,使网络更容易生成带噪声的图像。当然,数据集中可见光图像的噪声也是一个原因,判别器使用这种噪声作为一个标准。
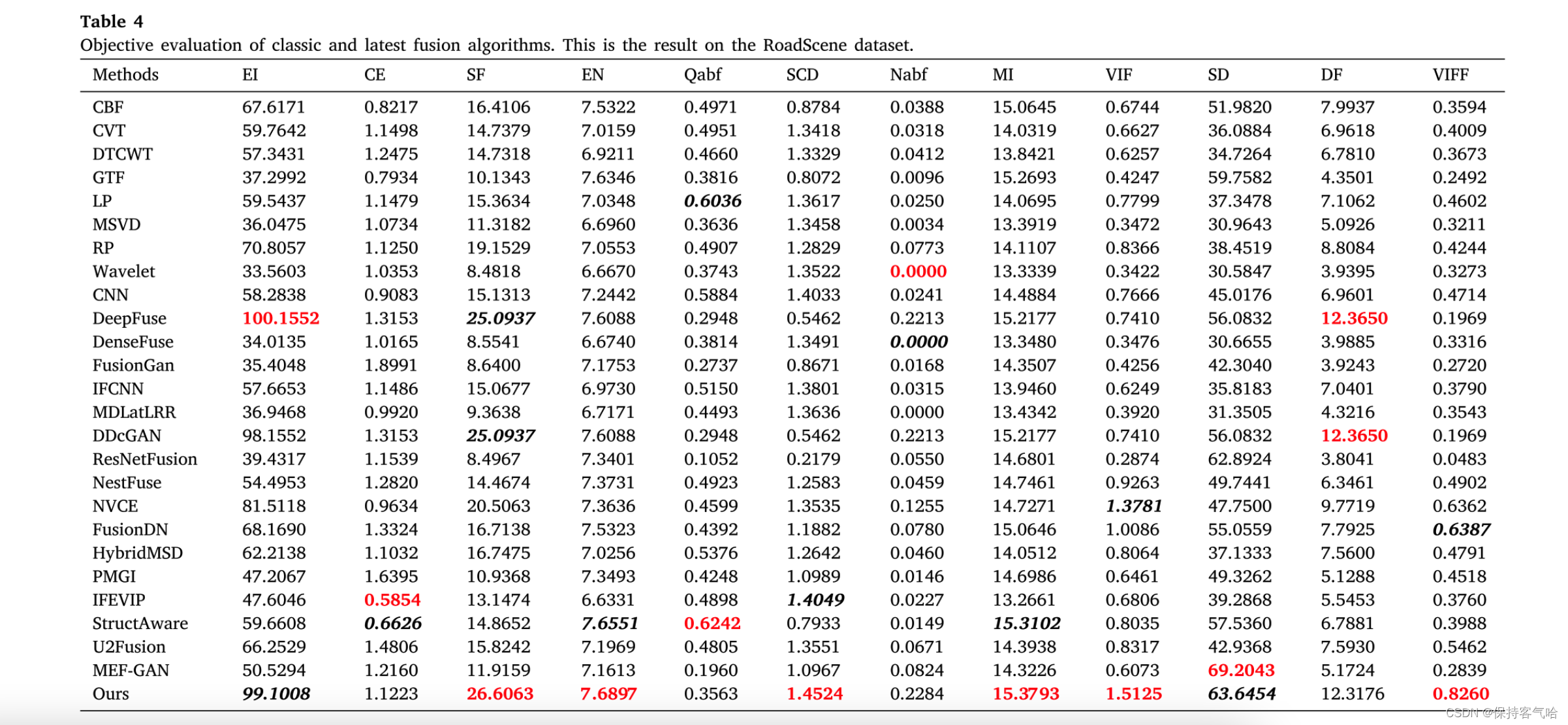
我们还对RoadScene数据集进行了目标评估,结果如表4所示,也获得了类似的结果。我们获得了六个最佳值和两个次优值。
4.3. Ablation studies
4.3.1. Network structure
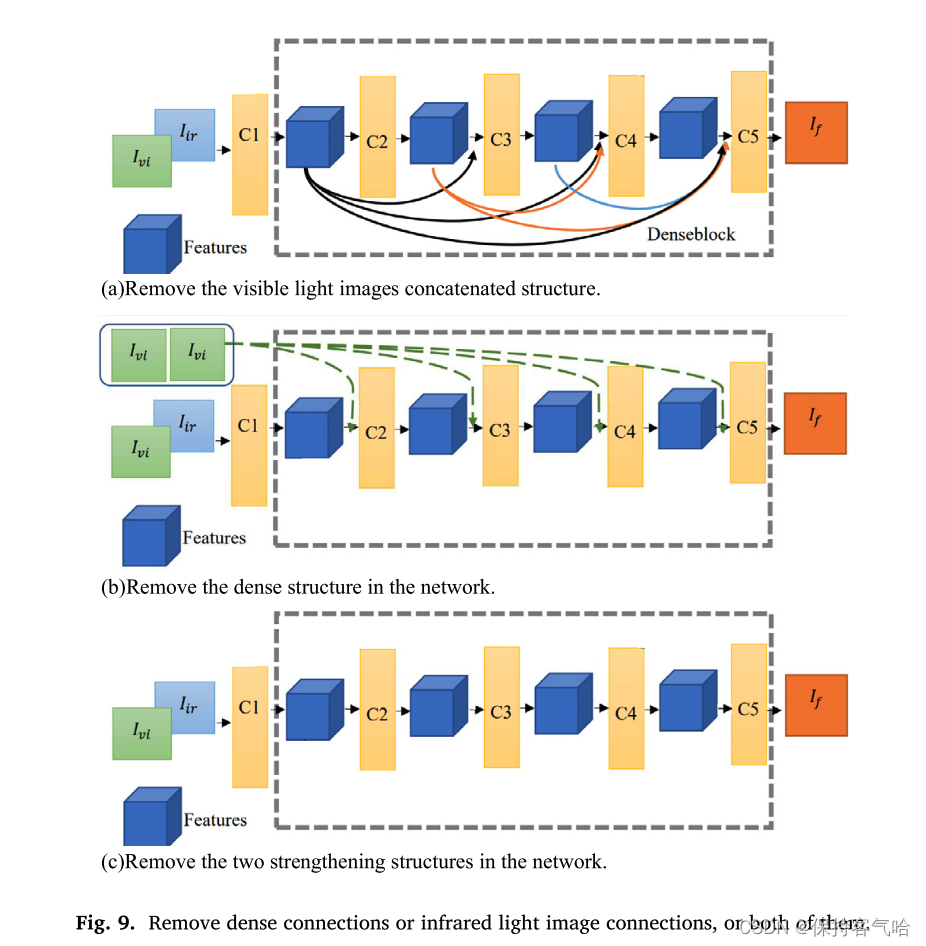
为了证明我们的网络结构的有效性,我们对网络进行了一些消融实验,如图9所示。我们保持或删除可见光图像和denseblock的交替连接,如图9(a)(b)所示。如果两者都不保留,则生成器网络只是一个多层卷积网络,如图9©所示。
我们还对这些消融网络进行了主客观评估。如图8所示,当我们去除网络结构的一部分时,图像质量明显下降。图像失去了植被的细节,人的辐射信息也不足。总体而言,图像的感知效果仍然不错。

如表5所示,我们对网络结构进行了消融实验,并使用客观指标进行评估。这里,将连接的可见光图像的网络称为“without viscat”。很容易理解,“without Dense”是删除dense block的网络。“Without both”是两者都删除的网络。可以通过表格观察到,无论删除哪个部分,这十个评价指标都会变差。
4.3.2. Hyperparameters comparison
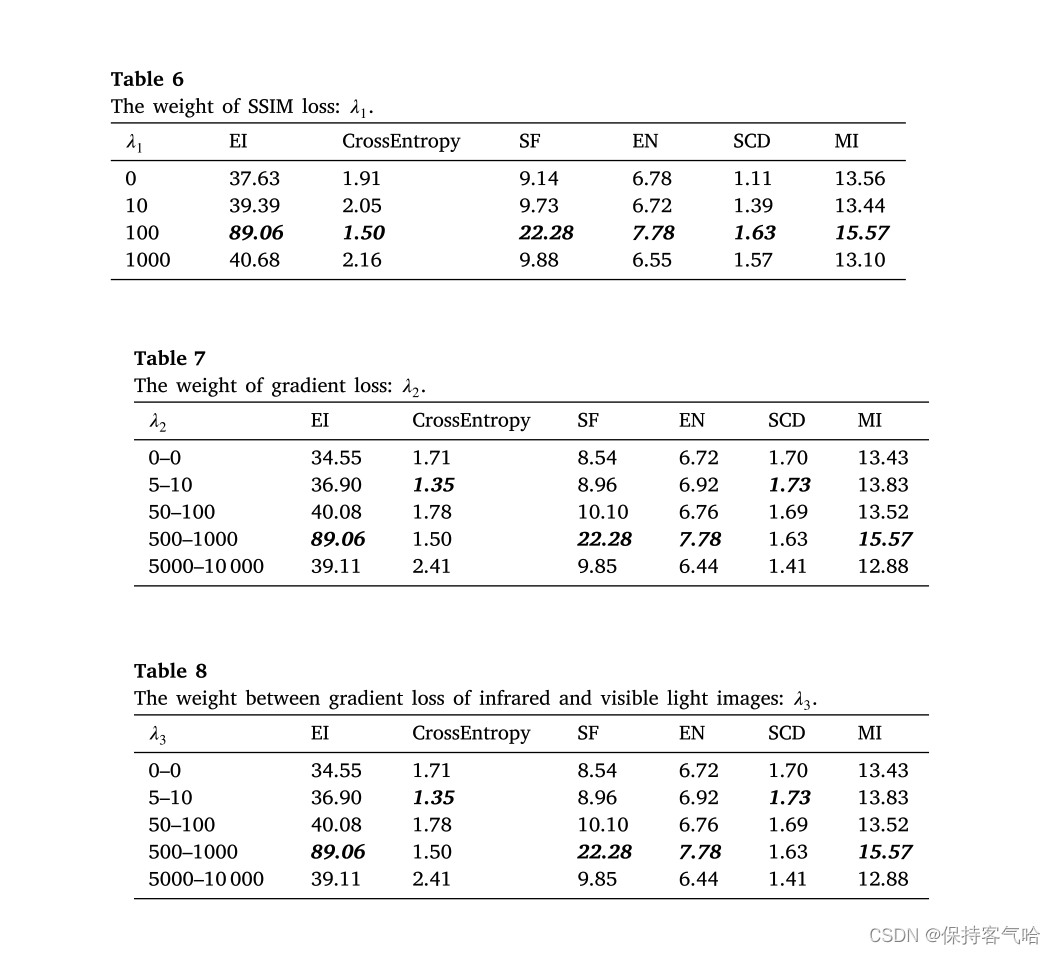
参考公式(6)-(10),我们的损失函数包括LSGAN的损失和内容的损失。我们改变了公式的表达式,以便更容易展示内容损失函数的超参数值对损失函数的影响,如公式(12)所示。
L content = λ 1 [ 1 − ( SSIM ( I f , I v i ) + SSIM ( I f , I i r ) / 2 ) ] + λ 2 [ Gradient ( I f , I v i ) + λ 3 Gradient ( I f , I i r ) ] \begin{aligned} L_{\text {content }}= & \lambda_{1}\left[1-\left(\operatorname{SSIM}\left(I_{f}, I_{v i}\right)+\operatorname{SSIM}\left(I_{f}, I_{i r}\right) / 2\right)\right]+ \\&\lambda_{2}\left[\operatorname{Gradient}\left(I_{f}, I_{v i}\right)+\lambda_{3} \operatorname{Gradient}\left(I_{f}, I_{i r}\right)\right] \end{aligned} Lcontent =λ1[1−(SSIM(If,Ivi)+SSIM(If,Iir)/2)]+λ2[Gradient(If,Ivi)+λ3Gradient(If,Iir)]
用于平衡它们的超参数是:𝜆1取自{0,1,10,100},𝜆2取自{0,10,100,1000,10000},𝜆3取自{0.5,1,2}。通过这些消融实验,我们得到了适当的超参数设置,如表6-8所示。
5.总结
在本文中,我们基于一个简单的端到端网络,加入了密集块来增强融合效果。此外,我们创新地在每一层将可见图像拼接在一起,使融合后的图像保留更多可见信息。我们设计了新的损失函数,使端到端网络能够更好、更稳定地生成融合图像。我们添加了SSIM损失函数以保持融合图像的结构与源图像相似,还添加了梯度损失以生成更多的边缘信息。我们没有使用通用的均方误差损失,因为均方误差会使网络学习到的数据分布更加“平均”,这并不适合GAN网络的功能——生成与“真实”数据分布足够接近的数据分布。鉴别器将可见图像分类,使生成的图像更加真实、自然,符合人类感知。测试模型是生成器模型,因此融合网络非常简单。它是一个端到端网络,不需要特征提取或设计融合策略。因此,视频可以实时融合。我们的方法可以融合比经典方法和最新方法更多的源图像细节。融合图像更自然,满足人类的视觉美感。在客观评价方面,我们的融合方法基于几个评价指标达到了最佳值。在未来的工作中,我们将尝试替换新的鉴别器网络并增强其功能。此外,我们将设计一个新的生成器损失函数,以扩大图像融合的应用领域。我们还将持续研究简化网络,以提高其结果;并尝试让GAN解决图像融合领域的其他问题,如多焦图像融合、医学图像融合和处理其他问题。