批量识别石墨烯团簇结构中的吡啶氮,并删除与其相连的氢
- 文章背景
- 任务内容
- 程序实现思路
- 实现代码
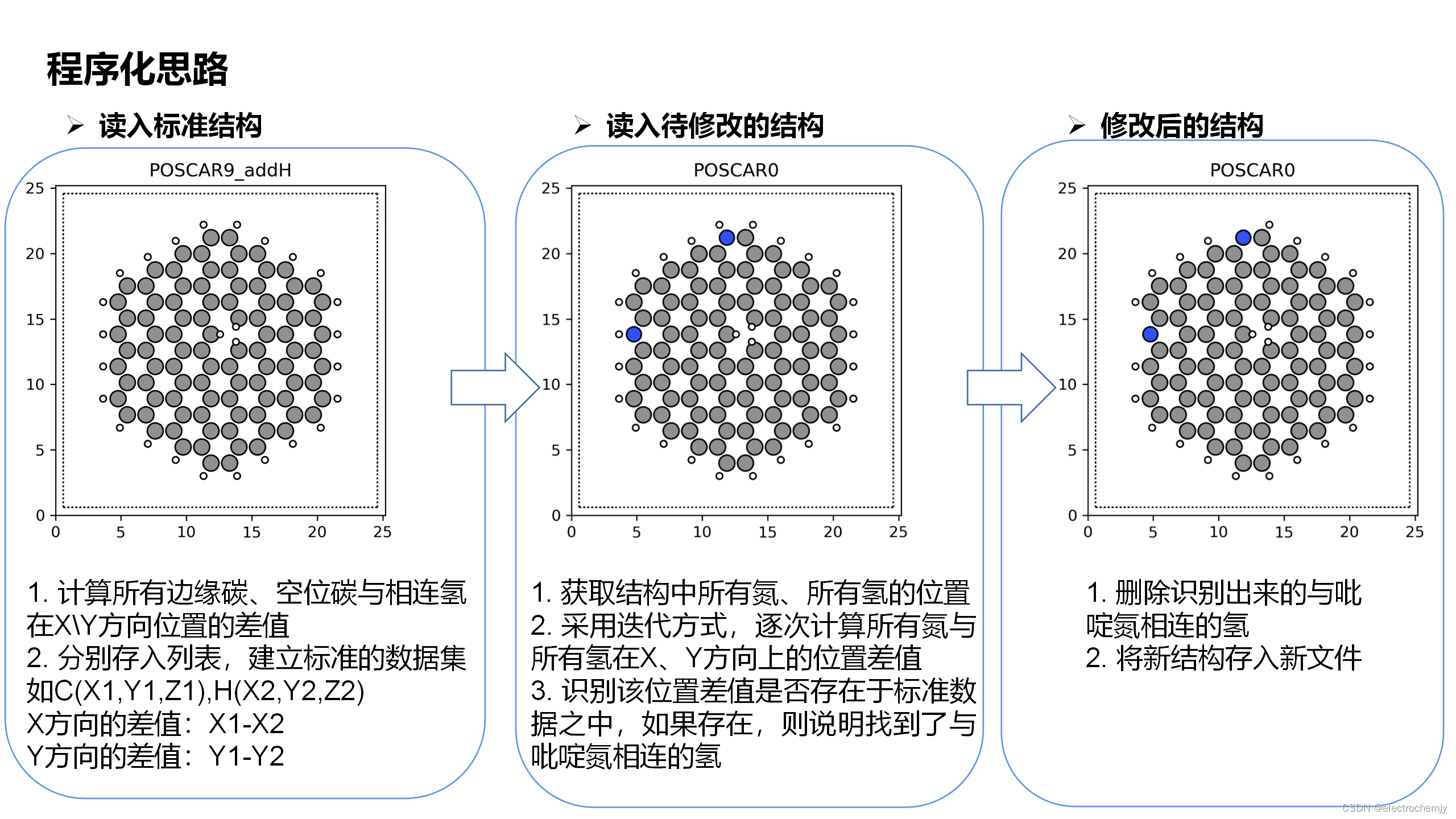
- 建立标准结构中边缘碳与氢的位置差值标准数据集
- 读入待修改结构,识别氮与氢位置差值是否存在标准数据集
- 代码细节剖析
文章背景
在科研工作中,我的工作需要接触大量的石墨烯团簇结构。对结构掺入一个氮时,氮的分布位置可以分为三类:在团簇内部,团簇边缘,团簇空位附近。对于后两种,一般会形成吡啶氮,但掺氮后我们得到的结构其吡啶氮往往还包括了氢,即有个氢与吡啶氮相连。这是不合理的,因此需要将与吡啶氮相连的氢删除掉。
常规操作是逐次打开结构,然后手动删除相应的氢。但如果有几千个这样的结构,手动删除需要花费很长的时间。我一开始是手动删除,执行了一个早上跟晚上也只删除了六百多个,还有两千多个。这样的重复工作让我不禁思考,怎么样可以让程序自动识别出吡啶氮的位置,然后找到相连的氢,自动把它删除呢?
一切自动执行的任务,其实现的核心是程序员对任务过程每个步骤的规则都烂熟于心,然后采用数据与逻辑的方法将每个步骤程序化。结合循环便可以实现批量自动执行。
因此,我针对这个任务的特点,重新剖析了每个实现步骤,尝试使用简单的数学方法结合for循环、if条件结构将步骤程序化。
任务内容
打开石墨烯团簇结构,删除与吡啶氮相连的氢原子

程序实现思路
自动打开石墨烯团簇结构,识别出与吡啶氮相连的氢原子,自动删除
实现代码
建立标准结构中边缘碳与氢的位置差值标准数据集
def get_str_NH_varyposition(str_path=r'D:\software output files\initial_str_addH',str_file='POSCAR0'):
'''
该函数实现自动识别吡啶氮,找出与吡啶氮相连的氢的index,并进行删除
完整设计思路为:
1.首先读入一个完整的结构,提取出所有吡啶氮与氢的位置信息
2.计算吡啶氮与对应氢之间的位置差,存入列表,作为标准数据
3.读入待删除含有吡啶氮相连氢的结构,提取所有氮、氢的位置
4.使用迭代,计算氮与氢的相对位置,与标准数据进行比对,如果完全一致,则识别出与吡啶氮相连氢的序号
5.删除对应的氢,将新结构存入新文件路径
本函数实现步骤1,2
str_path:为标准结构所在文件夹的路径
str_file:为标准结构文件的名字
'''
#读入结构
str_atom=read(os.path.join(str_path,str_file),format='vasp')#读入结构信息,转为atoms object
#获取结构位置信息
str_position=str_atom.get_positions()
#提取结构中所有的N
N2=str_atom[[atom.index for atom in str_atom if atom.symbol=='N']]
#提取结构中所有的H
H27=str_atom[[atom.index for atom in str_atom if atom.symbol=='H']]
#获取N,H的位置
H27_position=H27.get_positions()
N2_position=N2.get_positions()
#边缘氮、空位氮与相连氢的坐标差
Npev_index=[73,118,57,45,29,81,92,83,89,93,117,64,65,59,72,31,32,25,70,61,27,53,54,99,102,103,50]
Hev_index=[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,119,120,121]
N_H_varyx_L=[]
N_H_varyy_L=[]
for i in range(0,len(Npev_index),1):
Npev_position=str_position[Npev_index[i]]
Hev_position=str_position[Hev_index[i]]
N_H_varyx=Npev_position[0]-Hev_position[0]
N_H_varyy=Npev_position[1]-Hev_position[1]
N_H_varyx_L.append(N_H_varyx)
N_H_varyy_L.append(N_H_varyy)
#print("N_H_varyx_L",N_H_varyx_L)
#print("N_H_varyy_L",N_H_varyy_L)
return N_H_varyx_L,N_H_varyy_L
读入待修改结构,识别氮与氢位置差值是否存在标准数据集
def find_NpH_index(str_folder,save_path):
'''
该函数实现自动识别吡啶氮,找出与吡啶氮相连的氢的index,并进行删除
完整设计思路为:
1.首先读入一个完整的结构,提取出所有吡啶氮与氢的位置信息
2.计算吡啶氮与对应氢之间的位置差,存入列表,作为标准数据
3.读入待删除含有吡啶氮相连氢的结构,提取所有氮、氢的位置
4.使用迭代,计算氮与氢的相对位置,与标准数据进行比对,如果完全一致,则识别出与吡啶氮相连氢的序号
5.删除对应的氢,将新结构存入新文件路径
本函数实现步骤3,4,5
str_folder:为待修改结构文件所在文件夹路径
save_path:为存储修改后的结构文件的存储文件夹路径
'''
str_files=os.listdir(str_folder)
for file in str_files:
str_PATH=os.path.join(str_folder,file)
str_atom=read(str_PATH,format='vasp')#读入结构信息,转为atoms object
#获取结构位置信息
str_position=str_atom.get_positions()
#提取结构中所有的N
N2=str_atom[[atom.index for atom in str_atom if atom.symbol=='N']]
#提取结构中所有的H
H27=str_atom[[atom.index for atom in str_atom if atom.symbol=='H']]
#获取N,H的位置
H27_position=H27.get_positions()
N2_position=N2.get_positions()
#获取吡啶氮与氢位置相差的标准数据
N_H_varyx_L,N_H_varyy_L=get_str_NH_varyposition()
#识别读入的氢与氮的相对位置差
H_delete_index_L=[]#建立新列表存储识别出的氢列表
for i in range(0,len(N2_position),1):
for j in range(0,len(H27_position),1):
N2_H27_varyx=N2_position[i][0]-H27_position[j][0]#计算x坐标差值
#print("N2_H27_varyx",N2_H27_varyx)
N2_H27_varyy=N2_position[i][1]-H27_position[j][1]#计算y坐标差值
#print("N2_H27_varyy",N2_H27_varyy)
z_L=[z for z in N_H_varyx_L if N2_H27_varyx==z]#识别坐标差值是否符合标准数据
k_L=[k for k in N_H_varyy_L if N2_H27_varyy==k]
if not z_L == []:
if not k_L == []:
str_position_L=str_position.tolist()#np.array转为list
H27_position_j=H27_position[j].tolist()
H_delete_index=str_position_L.index(H27_position_j)
H_delete_index_L.append(H_delete_index)
#print("H_delete_index_L",H_delete_index_L)
del str_atom[[i for i in H_delete_index_L]]#删除识别出来的与吡啶氮相连的氢原子
write(os.path.join(save_path,file),str_atom,format='vasp')#将修改后的结构保存
函数调用:
str_folder=r'D:\software output files\initial_str_addH'
save_path=r'D:\software output files\initial_str_auto_deleteH'
find_NpH_index(str_folder,save_path)
代码细节剖析
该函数代码主要包括以下知识点:
【ASE方面】
- read(),write()函数,作用分别是:将结构信息读取为atom object,将atom object写入文件;
- atom_object.get_positions()函数,可以获取atom object中所有的原子坐标信息,数据形式为列表;
- atom.index,atom.symbol,可以获取atom object中某种元素所对应所有原子索引
- del atom_object[atom_index] ,删除atom object中某个原子
【python方面】
- for循环遍历列表,如:for i in list:
- 增加列表元素,append()
- os模块,os.listdir(), 将文件名读取为列表形式;os.path.join(),实现文件路径拼接
- tolist()函数,实现将np.array转为list
- if 条件语句,如判断列表是否为空列表,if not List == []:



![[附源码]JAVA毕业设计科研项目审批管理系统(系统+LW)](https://img-blog.csdnimg.cn/f2dbe9886f4c4aefa2c4b4f48080dfaa.png)







![[附源码]计算机毕业设计JAVA医院挂号管理系统](https://img-blog.csdnimg.cn/b659e39d22824c08a3894ceb5125c7ae.png)
