目录
- 0 简介
- 1 字符串基础
- 2 字符串长度
- 3 不受限制的字符串函数
- 3.1 复制字符串
- 3.2 连接字符串
- 3.3 函数的返回值
- 3.4 字符串比较
- 4 长度受限的字符串函数
- 5 字符串查找基础
- 5.1 查找一个字符串
- 5.2 查找任何几个字符
- 5.3 查找一个子串
- 6 高级字符串查找
- 6.1 查找一个字符串前缀
- 6.2 查找标记
- 7 错误信息
- 8 字符操作
- 8.1 字符分类
- 8.2 字符转换
- 9 内存操作
- 9.1 memcpy和memmove真的不一样吗?
- 9.2 memcmp:简单的比较
- 9.3 memchr:简单的查找
- 9.4 memset:初始化的值只能是0和-1?
- 10 总结
0 简介
在C语言中,字符串和数组有很多相似之处,且官方提供了很多的库函数可供调用。那么字符串和数组这对姐妹花,究竟有着什么样的亲密关系,而作为我们本期的重点角色,字符串又有何独特之处呢?
C语言并没有显式的字符串数据类型,因为字符串以字符串常量的形式出现或者存储于字符数组中。字符串常量很适用于那些程序不会对它们进行修改的字符串。所有其他字符串都必须存储于字符数组或动态分配的内存中。
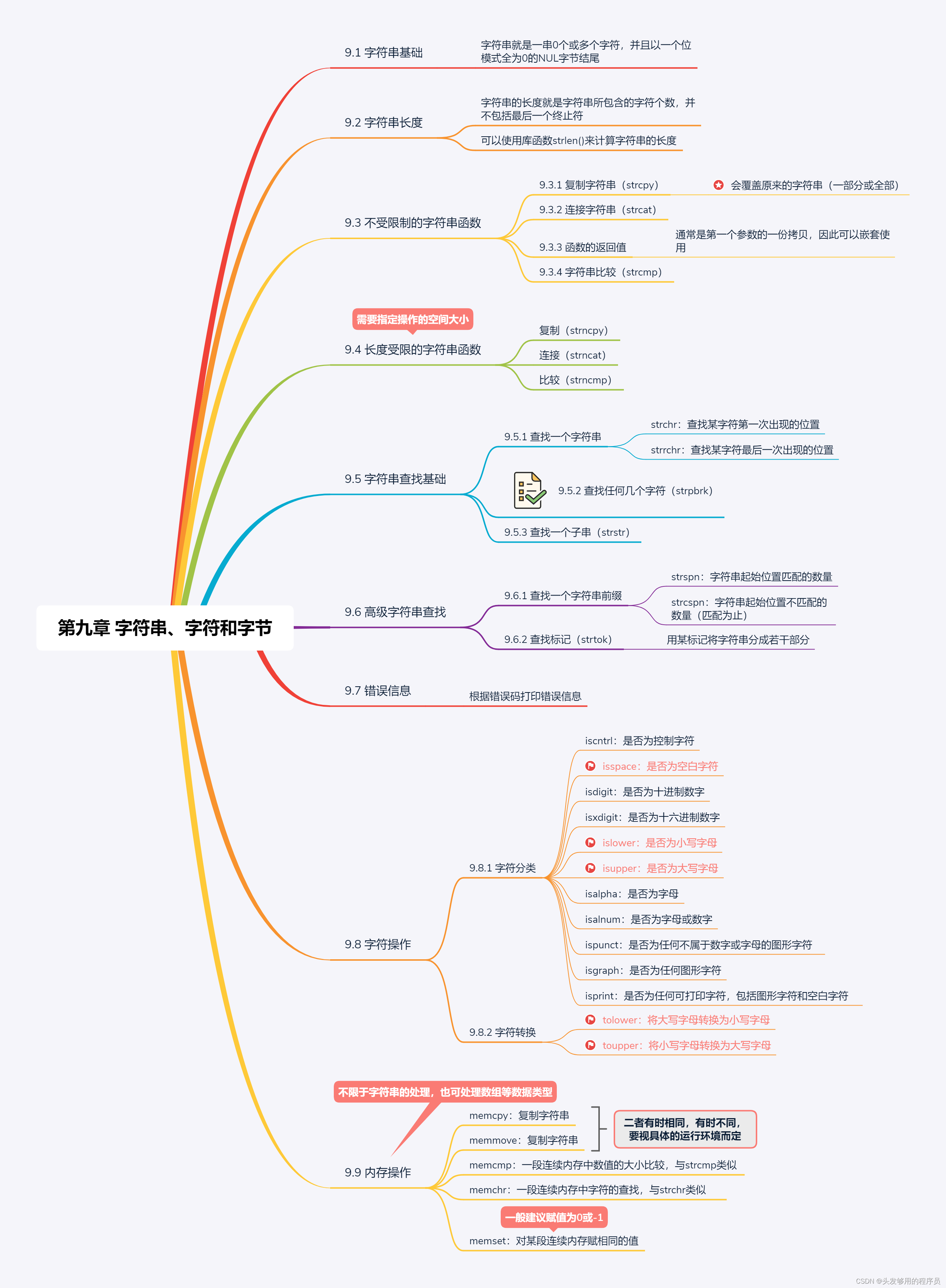
本篇着重介绍了一些字符串常用的库函数,使大家在不同的情况下去选择最适合的库函数。下面是本文的内容概览
1 字符串基础
字符串就是一串0个或多个字符,并且以一个位模式全为0的NUL字节结尾。
例如:
char message[] = "hello word";
2 字符串长度
字符串的长度就是字符串所包含的字符个数,并不包括最后一个终止符。这个在面试中会经常考查。
可以通过库函数strlen()来自动计算字符串的长度。
例如:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char message[] = "hello word";
printf("字符串的长度为:%d\n",strlen(message));
system("pause");
return 0;
}
打印输出:

需要注意的是,该函数返回的是无符号数,因此通过该函数比较两个字符串的长度的时候需要格外注意:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char message1[] = "hello word";
char message2[] = "hello Shanghai";
//比较方式1
if(strlen(message1) >= strlen(message2))
printf("字符串1更长\n");
else
printf("字符串2更长\n");
//比较方式2
if (strlen(message1) - strlen(message2) >= 0)
printf("字符串1更长\n");
else
printf("字符串2更长\n");
system("pause");
return 0;
}
打印输出:

因为返回的是无符号数,所以比较方式2中,条件判断的结果永远为真,导致判断结果出现错误。
3 不受限制的字符串函数
所谓的不受限制的字符串函数,是指在使用的时候,不需要指定字符串(实参)的长度,函数即可顺利运行。
3.1 复制字符串
复制字符串在开发中经常会用到,但是在复制到新的字符串中时,会覆盖掉原来的部分,所以需要格外注意。
例如:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char message1[] = "hello word";
char message2[] = "hello Shanghai";
int message2_len = strlen(message2);
printf("字符串2的长度为:%d\n", strlen(message2));
strcpy(message2,message1);
printf("字符串2的长度为:%d\n",strlen(message2));
for(int i = 0; i < message2_len; i++)
printf("%c",message2[i]);
system("pause");
return 0;
}
打印输出:

可以看到,在将字符串message1复制到message2之后,message2的长度居然都不一样了,这是为什么呢?
这是因为,在复制字符串的时候,顺便也将终止符复制了过来,在strlen()函数进行处理的时候,肯定就会返回10,从打印结果来看,message2的其余部分仍然被保留了下来。
而将较长字符串复制到较短的字符串中时,常常会报错,这是因为没有足够的空间去容纳需要复制的字符。
3.2 连接字符串
连接字符串的时候,可以使用strcat()函数。它的原型如下:
char *strcat(char *dst, char const *src);
举个例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char message1[] = "hello word";
char message2[] = "hello Shanghai";
strcat(message1,message2);
printf("%s\n", message1);
system("pause");
return 0;
}
打印输出:

可以看到,直接将两个字符串进行了拼接。新字符串的长度值是原来两个字符串的长度之和。
3.3 函数的返回值
这些函数的返回值有时候是第一个参数的一份拷贝,因此可以嵌套使用,因为当字符串做实参的时候,传递的也是第一个元素的地址。所以这些函数经常可以嵌套地调用。
例如:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char message1[] = "hello ";
char message2[] = "word ";
char message3[] = "Shanghai";
strcat(strcat(message1, message2), message3);
printf("%s\n", message1);
system("pause");
return 0;
}
打印输出:

但是为了程序的可读性,不嵌套也可以。
3.4 字符串比较
字符串比较,常用的库函数只有一个,就是strcmp。它的原型如下:
int strcmp(char const *s1, char const *s2);
这个函数的比较规则比较 有意思,该函数对两个字符串的字符逐个进行比较,直到发现不匹配为止,这里有两种情况:
- 最先不匹配的字符中在ASCII中排名靠前的那个字符所在的字符串被认为是较小的字符串;
- 如果开始部分的两个字符串都相等,那么较短的字符串被认为是较小的字符串。
字符串发现有不匹配的某个字符,即可得到对比结果,而无须比较剩余部分。
如下图所示:

看看实际的代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char temp1[] = "hello";
char temp2[] = "hello world";
char temp3[] = "hello worLd";
//字符串temp1和temp2作比较
if(strcmp(temp1,temp2) == 0)
{
printf("temp1 = temp2\n");
}
else if (strcmp(temp1, temp2) > 0)
{
printf("temp1 > temp2\n");
}
else if (strcmp(temp1, temp2) < 0)
{
printf("temp1 < temp2\n");
}
printf("------------------\n");
//字符串temp2和temp3作比较
if (strcmp(temp2, temp3) == 0)
{
printf("temp2 = temp3\n");
}
else if (strcmp(temp2, temp3) > 0)
{
printf("temp2 > temp3\n");
}
else if (strcmp(temp2, temp3) < 0)
{
printf("temp2 < temp3\n");
}
printf("\n");
system("pause");
return 0;
}
打印输出:

4 长度受限的字符串函数
有的库函数在调用的时候,需要传入待处理的字符串的长度,因此称为长度受限的字符串函数。
这些函数提供了一种方便的机制,可以防止难以预料的长字符串从它们的目标数组溢出。
常见的有一下几个函数:
char *strncpy(char *dst, char const *src, size_t len);
char *strncat(char *dst, char const *src, size_t len);
int strncmp(char const *s1, char const *s2, size_t len);
举个例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char message1[] = "hello ";
char message2[] = "hello Beijing ";
char message3[] = "Shanghai";
char message_all[] = "hello Beijing Shanghai";
if(strncmp(strncpy(strncat(message2, message3, strlen(message3)), message1, strlen(message1)), message_all,strlen(message_all)) == 0)
printf("二者相等\n");
else
printf("二者不相等\n");
system("pause");
return 0;
}
打印输出:

这个例子举得并不十分恰当。因为长度都是按最大进行传入的,但也可以说明问题。
5 字符串查找基础
标准库中存在很多函数,它们用各种不同的方法查找字符串。这些各种各样的工具给了C程序员很大的灵活性。
5.1 查找一个字符串
在一个字符串中查找特定字符有两个库函数可用。
char *strchr(char const *str, int ch);
char **strrchr(char const *str, int ch);
前者用来查找某字符第一次出现的位置(返回指向该地址的指针),后者用来查找某字符最后一次出现的位置(返回指向该地址的指针)。
这两个函数可以这样用:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char message1[] = "hello ";
char message2[] = "hello Beijing ";
char message3[] = "Shanghai";
char message_all[] = "hello Beijing Shanghai";
char *first_site, *last_site;
first_site = strchr(message_all, 'h');
last_site = strrchr(message_all, 'h');
printf("字符串的长度是:%d\n",strlen(message_all));
printf("h第一次出现的位置是:%d\n", first_site - message_all);
printf("h最后一次出现的位置是:%d\n", last_site - message_all);
system("pause");
return 0;
}
打印输出:

需要注意的是,该函数返回的并不是目标元素位置的值,而是指针,所以需要与该字符串的第一个元素指针作差,才可以得出结果。
注意:在查找的时候是区分大小写的。
5.2 查找任何几个字符
strpbrk是一个更为常见的函数,用来查找某个字符串中任意字符第一次在目标字符串中出现的位置。它的原型如下:
char *strpbrk(char const *str, char const *group);
可以这样用:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char message_all[] = "hello Beijing Shanghai";
char *first_site;
first_site = strpbrk(message_all, "abcde");
printf("字符串的长度是:%d\n",strlen(message_all));
printf("abcde第一次出现匹配字符的位置是:%d\n", first_site - message_all);
system("pause");
return 0;
}
打印输出:

容易看出,第一个匹配到的字符是e,位置是1。
5.3 查找一个子串
为了在字符串中查找一个子串,我们可以使用strstr函数,它的原型如下:
char *strstr(char const *s1, char const *s2);
举个实际使用中的例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char message_all[] = "hello Beijing Shanghai";
char *first_site;
first_site = strstr(message_all, "Beijing");
printf("字符串的长度是:%d\n",strlen(message_all));
printf("Beijing第一次出现的位置是:%d\n", first_site - message_all);
system("pause");
return 0;
}
打印输出:

可以看到,在此次查找中,需要匹配到所有的字符,而不是某个或者局部。
6 高级字符串查找
接下来的一组函数简化了从一个字符串的起始位置中查找和抽取一个子串的过程。
6.1 查找一个字符串前缀
strspn和strcspn函数用于在字符串中的起始位置对字符串计数,它们的原型如下所示:
size_t strspn( char const *str, char const *group);
size_t strcspn( char const *str, char const *group);
需要注意的是,这两个函数返回的 并不是元素指针,而是实际匹配字符的数量。
具体的使用方法可以来看个例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
int len1, len2;
char buffer[] = "25,142,330,smith,J,239-4123";
len1 = strspn(buffer, "0123456789");
len2 = strcspn(buffer, ",");
printf("0123456789的起始匹配数是:%d\n", len1);
printf(",的起始不匹配数是:%d\n", len2);
system("pause");
return 0;
}
打印输出:

从上面例子中可以看出,strspn函数是从头开始找符合所找字符串的字符,直到找不到为止。在该例中,,已经不合适了,所以连续查找的情况下,合适的只有2个。
strcspn函数却恰好相反,找的是不符合的,开头的2和5显然都不符合,,是符合的,所以连续查找的情况下,合适的有2个。
6.2 查找标记
一个字符串常常包含好几个单独的部分,他们彼此被分隔开。每次为了处理这些部分,首先必须把它们从字符串中抽取出来。
strtok函数就可以实现这样的功能。它从字符串中隔离各个单独的称为标记的部分。并丢弃分隔符。它的原型如下:
char *strtok( char *str, char const *sep);
注意:
- 当strtok函数执行任务时,它会修改它所处理的字符串。如果源字符串不能被修改,那就复制一份,将这份拷贝传递给strtok函数。
- 如果strtok函数的第1个参数不是NULL,函数将找到字符串的第1个标记。strtok同时将保存它在字符串中的位置。如果strtok函数的第1个参数是NULL,函数就在同一个字符串中从这个被保存的位置开始像前面一样查找下一个标记。
举个例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
int add = 0;
char buffer[] = "25,142,330,smith,J,239-4123";
char *token = NULL;
for (token = strtok(buffer, ","); token != NULL; token = strtok(NULL, ","))
{
printf("%s\n", token);
add++;
}
printf("--------------------------\n");
printf("add的值为:%d\n",add);
system("pause");
return 0;
}
打印输出:

从上面的例子中可以看出,以我们需要寻找的标记为分界,每循环一次,得到一个分割的子串,直到全部分割完毕。共分割6次。
7 错误信息
C语言的库函数在执行失败时,都会有一个错误码(0 1 2 3 4 5 6 7 8 9 …),操作系统是通过设置一个外部的整型变量errno进行错误代码报告的。也就是说,一个错误码,对应了一种错误类型,strerror函数把其中一个错误代码作为参数并返回一个指向用于描述错误的字符串的指针。这个函数的原型如下:
char *strerror(int error_number);
举个例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
for(int i = 0; i < 10; i++)
printf("%s\n",strerror(i));
system("pause");
return 0;
}
打印输出:

可以看到,不同的操作码,对应着不同的错误类型,而错误码0表示没有错误。其他均表示各种各样的错误。这部分内容了解即可。不需要掌握。也不需要知道每个操作码究竟代表哪种错误。
8 字符操作
标准库包含了两组函数,用于操作单独的字符,它们的原型位于头文件ctype.h。第1组函数用于对字符串分类,而第2组函数用于字符转换。
8.1 字符分类
每个分类函数接受一个包含字符值的整形参数。函数测试这个字符并返回一个整形值,表示真或假。下面的表格列出了每个函数以及返回真所需要的条件。
| 函数 | 返回真所需要的条件 |
|---|---|
| iscntrl | 控制字符 |
| isspace | 空白字符:空格,换页’\f’,换行’\n’,回车’\r’,制表符’t’或垂直制表符’\v’ |
| isdigit | 十进制数字 |
| isxdigit | 十六进制数字,包含大小写形式的a~f |
| islower | 小写字母 |
| isupper | 大写字母 |
| isalpha | 字母(大小写皆可) |
| isalnum | 字母或数字 |
| ispunct | 任何不属于数字或字母的图形字符(可打印符号) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
所以这些函数是用来判定字符串元素的, 举个例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
int main()
{
char temp[] = "To carry things with great virtue";
for (int i = 0; i < strlen(temp); i++)
{
if (islower(temp[i]))
printf("temp[%d] : %c是小写字母\n", i, temp[i]);
else if (isupper(temp[i]))
printf("temp[%d] : %c是大写字母\n", i, temp[i]);
else if(isspace(temp[i]))
printf("temp[%d] : %c是空格\n", i, temp[i]);
}
printf("\n");
system("pause");
return 0;
}
打印输出:

可以看到,此时已经将temp每个元素究竟是大写字母还是小写字母,或者是空格进行了判定。
8.2 字符转换
转换函数白大写字母转换为小写字母或者把小写字母转换为大写字母。有两个函数可供调用。toupper函数返回其参数对应的大写形式,tolower函数返回其参数对应的小写形式。
int tolower(int ch);
int toupper(int ch);
举个实际的例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
int main()
{
char temp1[] = "To carry things with great virtue";
char temp2[] = "To carry things with great virtue";
//全转换为大写
for (int i = 0; i < strlen(temp1); i++)
{
if (islower(temp1[i]))
temp1[i] = toupper(temp1[i]);
printf("%c",temp1[i]);
}
printf("\n-----------------------------\n");
//全转换为小写
for (int i = 0; i < strlen(temp2); i++)
{
if (isupper(temp2[i]))
temp2[i] = tolower(temp2[i]);
printf("%c", temp2[i]);
}
printf("\n");
system("pause");
return 0;
}
打印输出:

可以看到,我们可以按照自己的意愿去调整字符串中字母的大小写。
9 内存操作
字符串一般以NUL结尾,但是如果我们想要处理中间包含NUL的字符串,或者任意长度的字节序列的时候,前面的函数就显得比较乏力,或者说根本没法用。不过我们可以有另外一组函数,供我们使用,去完成实际开发中的一些需求。下面是它们的原型。
注意:这些函数能够处理的不仅仅是字符串,还可以是结构体或数组等数据类型,具体可以处理的数据类型要根据具体函数来定。
void *memcpy(void *dst, void const *src, size_t length);
void *memmove(void *dst, void const *src, size_t length);
void *memcmp(void const *a, void const *b, size_t length);
void *memchr(void const *a, int ch, size_t length);
void *memset(void *a, int ch, size_t length);
举个例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SIZE 10
int main()
{
char temp1[] = "hello world";
char temp2[] = "hello world";
char temp3[] = "hello world";
char temp4[] = "hello world";
unsigned int int_array[SIZE];
char *p = NULL;
//复制字符串
memcpy(temp1 + 2, temp1, 5);
memmove(temp2 + 2, temp2, 5);
printf("temp1 = %s\n", temp1);
printf("temp2 = %s\n", temp2);
printf("---------------------------------------\n");
//比较字符串
if(!memcmp(temp1, temp2, 6))
printf("temp1 = temp2\n");
else
printf("temp1 != temp2\n");
printf("---------------------------------------\n");
//查找字符
p = (char *)memchr(temp3, 'e', strlen(temp3));
if(p != NULL)
printf("字符e在temp3中的位置是:%d\n", p - &temp3[0]);
printf("---------------------------------------\n");
//初始化数组
memset(int_array, 0, sizeof(int_array));
for (int i = 0; i < SIZE; i++)
printf("int_array[%d]的值为:%d\t", i, int_array[i]);
printf("\n", sizeof(int));
printf("---------------------------------------\n");
//初始化数组
memset(temp4, 'a', sizeof(temp4) - 1);
printf("字符串temp4为:%s\n", temp4);
system("pause");
return 0;
}
打印输出:

9.1 memcpy和memmove真的不一样吗?
有一个很值得探讨的问题:
memcpy和memmove函数真的一样吗?《C和指针》以及网上的很多说法都是:两者不一样,如果src和dst出现了重叠,则memcpy会出现问题,而memmove总能按照理想的情况去运行,但我们的程序运行结果却是,这两个函数都可以按照理想情况运行,这是为什么呢?
唯一的解释就是,软件的运行环境不一样,程序的底层库出现了差异,所以会出现这样的情况。但这并不影响我们对以前版本的(也就是两者不同)的memcpy和memmove进行一番研究!
先来看看所谓的重叠是什么意思,为什么重叠的时候,字符串复制会出现问题。

以上就是我们程序中复制字符串操作的示意图。可以看到src子串和dst子串有三个字母出现了重叠,如果我们按照常规的操作方法,复制之后就会出现下面这样的结果。

若区域重叠,就会导致复制出错,也就是说,想要取的值被新值所覆盖,导致无法顺利取值,复制后temp1变成了hehehehorld。这就是之前memcpy字符串的复制方法。
然后让我们来看看memmove(以及优化后的memcpy)是如何巧妙地解决这个问题的。

可以看到,复制的顺序出现了变化,这次是从后往前复制的,很好地避免了这个问题。
那么问题来了,这次是要复制的目的位置在后面,如果在前面又该如何处理呢?答案是复制顺序也反过来。看看执行过程:

这个时候,也不会出现将要取的值被原来的值覆盖的情况,会按照预想的结果去执行,结果是:llo w world。
9.2 memcmp:简单的比较
memcmp比较内存区域a和的前length个字节。比较方法,返回值都和strcmp基本一致,详情可以参考本文的strcmp部分。
9.3 memchr:简单的查找
memchr从a的起始位置开始查找字符ch的第一次出现的位置,并返回一个指向该位置的指针。查找方法,返回值都和strchr基本一致,详情可以参考本文的strchr部分。
9.4 memset:初始化的值只能是0和-1?
从该函数的介绍来看,该函数可以对某连续的内存区域设置相同的任何值(理论上),但在实际的开发中,基本都设置为0或者-1,这是为什么呢?
这是因为,这个函数对于内存的赋值,是以字节为单位的,一般用来对字符串进行赋值没有任何问题,因为字符串的元素只占一个字节,而数组则不同,常见的short,int,long类型的数组元素都不止一个字节,所以初始化才不会出现我们预想的结果。当我们设置为0的时候,各个字节都为0(若为-1,则各个位都为1),所以每个元素无论几个字节都会初始化为0,但是为其他值,结果就不一样了。参考以下程序:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SIZE 10
int main()
{
unsigned int int_array[SIZE];
//初始化数组
printf("--------------初始化值设为0-------------------------\n");
memset(int_array, 0, sizeof(int_array));
for (int i = 0; i < SIZE; i++)
printf("int_array[%d]的值为:%d\t", i, int_array[i]);
printf("\n");
printf("--------------初始化值设为1-------------------------\n");
memset(int_array, 1, sizeof(int_array));
for (int i = 0; i < SIZE; i++)
printf("int_array[%d]的值为:%d\t", i, int_array[i]);
printf("\n");
system("pause");
return 0;
}
打印输出: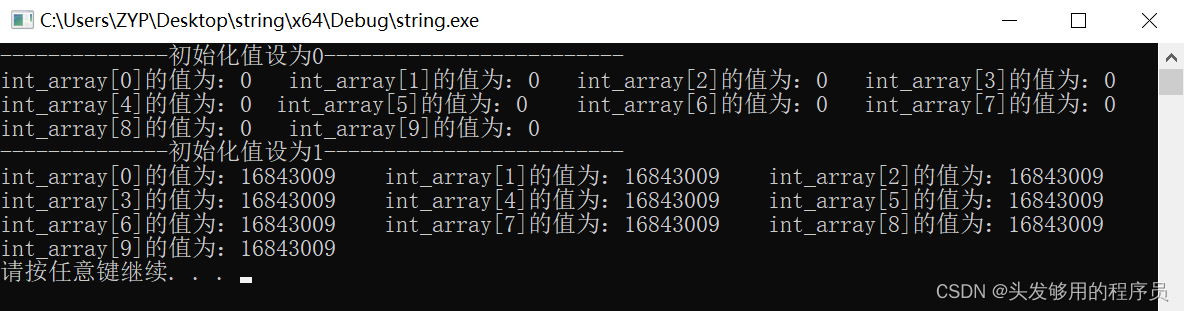
这是为什么呢?
这是因为,memset是按字节赋值的,而int类型的数据在内存中占了4个字节,所以该值应该以4个字节为单位,即:0x01010101,转换成十进制正好是16843009。
所以,一般如果想用memse对一段内存区域设定相同的值,初始化为0或者-1是最好的选择。
10 总结
字符串本身并不是很复杂,为了方便开发,提供了很多的库函数,所以我们只需要掌握C语言的那些库函数即可。尤其是要注意,有的函数返回的并不是数值,而是指针;有的函数使用起来比较特殊,比方说strtok等。
------------------------------------------------------------------------end-------------------------------------------------------------------------