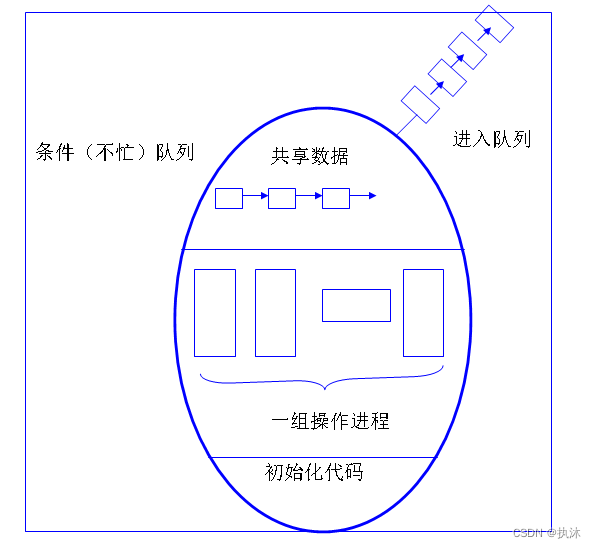
一 说明
窗口函数是什么?窗口函数是时间序列的局部属性处理函数,比如,一维卷积滤波、移动平均、指数平均本篇我们将针对pandas对象的窗口函数展开讨论,并以示例展示他们的概念实质。
二 窗口函数、分组函数( GroupBy & window )
2.1 窗口函数表
因为Series是一维时间序列,因此,我们将主要对Series内部窗口函数进行描述,至于dataframe数据,我们将按此处理,不会有错。
| Series.apply(func[, convert_dtype, args]) | 对 Series 的值调用函数。 |
| Series.agg([func, axis]) | 在指定轴上使用一个或多个操作进行聚合。 |
| Series.aggregate([func, axis]) | 在指定轴上使用一个或多个操作进行聚合。 |
| Series.transform(func[, axis]) | 调用 self 函数生成一个与 self 具有相同轴形状的series。 |
| Series.map(arg[, na_action]) | 根据输入映射或函数映射 Series 的值。 |
| Series.groupby([by, axis, level, as_index, ...]) | 使用映射器或按一系列列对系列进行分组。 |
| Series.rolling(window[, min_periods, ...]) | 提供滚动窗口计算。 |
| Series.expanding([min_periods, axis, method]) | 提供扩展窗口计算。 |
| Series.ewm([com, span, halflife, alpha, ...]) | 提供指数加权 (EW) 计算。 |
| Series.pipe(func, *args, **kwargs) | 应用需要 Series 或 DataFrames 的可链接函数。 |
2.2 分配性函数和聚合性函数
我们将时间序列的处理分成两种情况:
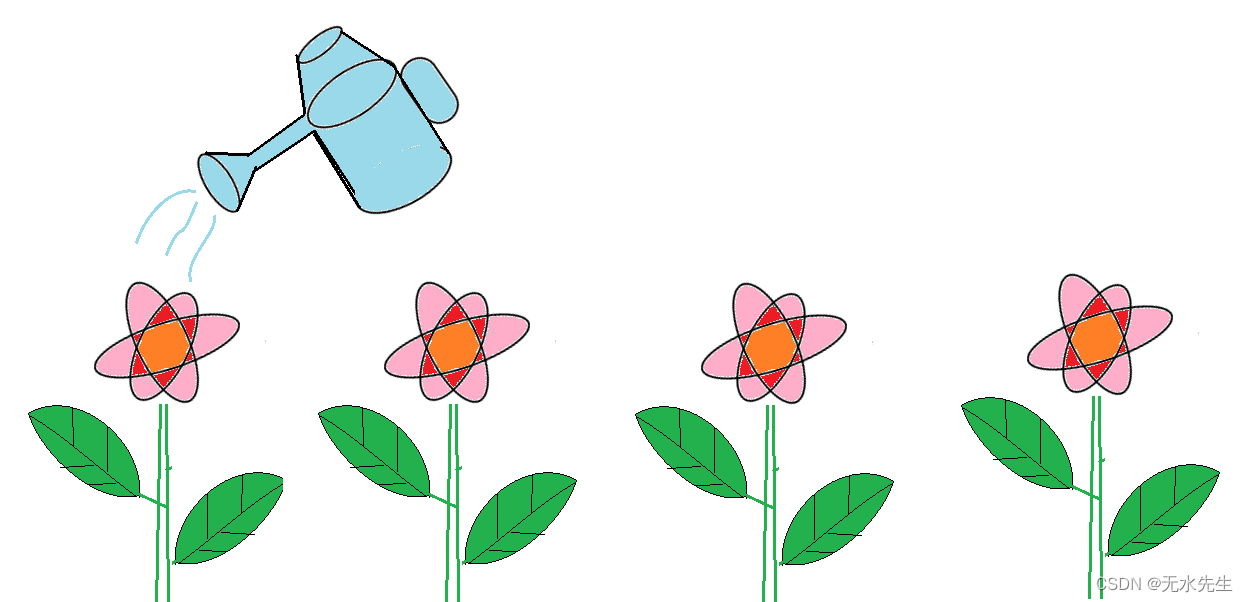
1)分配性函数
一种情况是将时间序列的每一个元素进行某种操作(如map、apply)。这好比浇树,要对每一个树进行浇灌。
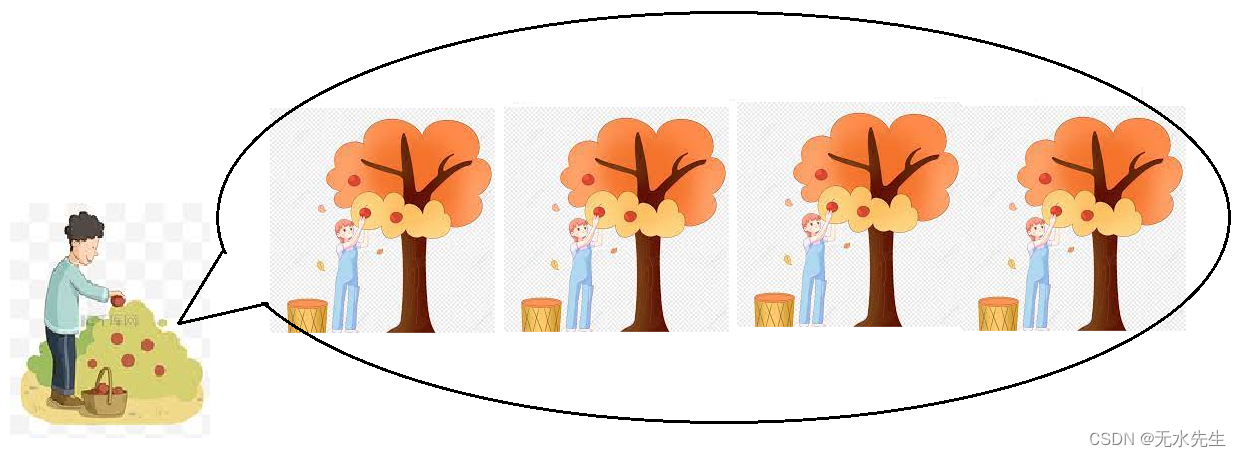
2)聚合性函数
另一个操作,是对时间函数的每一个元素进行积累,我们关心的是总量(agg、transformer)。这好比摘果实,我们不关心每一棵树的停留,而是关心一片树的果实总量(果堆)。
三 窗口函数使用案例
3.1 我们先生成一个表格和数据
下列代码生成数据:
data = pd.DataFrame({
'姓名': ['吉米', '吉米', '吉米','杰克', '杰克', '杰克', '麦克', '麦克','麦克' ],
'科目': ['语文', '数学', '英语', '语文', '数学', '英语', '语文', '数学', '英语'],
'分数': [80, 90, 70, 60, 75, 85,77,92,88],
})姓名 科目 分数
0 吉米 语文 80
1 吉米 数学 90
2 吉米 英语 70
3 杰克 语文 60
4 杰克 数学 75
5 杰克 英语 85
6 麦克 语文 77
7 麦克 数学 92
8 麦克 英语 88
3.2 Series.map函数
series.map是最简单的元素操作函数。复杂操作用apply。操作后原数据长度不变。
1)函数原型
Series.map(arg, na_action=None)[source]
2) 参数表:
案例1:基于回调函数的map映射
def me_power(data):
return data**2
df = data['分数'].map(me_power)
print(df)结果:
0 6400
1 8100
2 4900
3 3600
4 5625
5 7225
6 5929
7 8464
8 7744
案例2:基于字典的map映射
import pandas as pd
from pandas import Series, DataFrame
data = DataFrame({'food':['bacon','pulled pork','bacon','Pastrami',
'corned beef','Bacon','pastrami','honey ham','nova lox'],
'ounces':[4,3,12,6,7.5,8,3,5,6]})
meat_to_animal = {
'bacon':'pig',
'pulled pork':'pig',
'pastrami':'cow',
'corned beef':'cow',
'honey ham':'pig',
'nova lox':'salmon' }
data['animal'] = data['food'].map(str.lower).map(meat_to_animal)
data
data['food'].map(lambda x: meat_to_animal[x.lower()])
food ounces
0 bacon 4.0
1 pulled pork 3.0
2 bacon 12.0
3 Pastrami 6.0
4 corned beef 7.5
5 Bacon 8.0
6 pastrami 3.0
7 honey ham 5.0
8 nova lox 6.0
运算结果
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastrami 3.0 cow
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
3.3 Series.apply函数
与series.map类似,但更加复杂,有更多的参数输入。
1)函数原型
Series.apply(func, convert_dtype=True, args=(), **kwargs)
2)参数表
| 函数参数 | 参数意义 | 类型 |
|---|---|---|
| func | 回调函数(Python,Numpy类型) | 函数指针 |
| convert_dtype | 尝试为元素函数结果找到更好的数据类型。如果为 False,则保留为 dtype=object。请注意,对于某些扩展数组数据类型,例如分类数据类型,数据类型始终保留。 | 布尔 |
| args | 在系列值之后传递给 func 的位置参数。 | int |
| **kwargs | 传递给 func 的附加关键字参数。 | 列表 |
3)Series.apply()是pandas中的函数,它可以将一个函数应用到Series中的每个元素,并返回一个新的Series。
4)举例:
下面是一个使用案例,假设有一个Series,它表示若干个人的年龄:
import pandas as pd
ages = pd.Series([18, 25, 41, 32, 27])
现在我们想将这些年龄进行分组,把年龄小于等于30岁的人分为一组,大于30岁的人分为另一组。我们可以定义一个函数来实现:
def age_group(age):
if age <= 30:
return 'young'
else:
return 'middle-aged'
然后使用Series.apply()将这个函数应用到ages中的每个元素:
groups = ages.apply(age_group)
最终得到的groups就是一个新的Series,它的每个元素表示对应年龄所属的分组:
print(groups)
# 输出:
# 0 young
# 1 young
# 2 middle-aged
# 3 middle-aged
# 4 young
# dtype: object
这个例子展示了如何使用Series.apply()将一个自定义函数应用到Series中的每个元素,并返回一个新的Series。
Pandas教程 | 数据处理三板斧——map、apply、applymap详解 - 知乎 (zhihu.com)
3.4 Series.agg函数
1)函数原型
Series.agg(func=None, axis=0, *args, **kwargs)[source]#
2)参数表
Pandas的Series.agg函数是用于对一维数据进行聚合操作的函数。它可以对Series进行多种聚合操作,例如求和、平均值、最大值、最小值等。下面是一个示例:
假设有一个Series对象a,它包含了一些数值:
import pandas as pd
import numpy as np
a = pd.Series([1, 2, 3, 4, 5])我们可以用agg函数对这个Series进行求和、平均值和标准差的操作:
print(a.agg('sum')) # 求和
print(a.agg('mean')) # 平均值
print(a.agg('std')) # 标准差
输出结果为:
15
3.0
1.5811388300841898
我们也可以使用numpy提供的函数进行聚合操作:
print(a.agg(np.sum)) # 求和
print(a.agg(np.mean)) # 平均值
print(a.agg(np.std)) # 标准差
输出结果同样为:
15
3.0
1.5811388300841898
除了使用字符串和numpy函数进行聚合操作外,我们还可以使用lambda函数来定义聚合操作:
print(a.agg(lambda x: x.sum() - x.mean())) # 求和减去平均值
输出结果为:
10.0
以上就是使用Series.agg函数对一维数据进行聚合操作的示例。
3.5 series.aggragate函数
与series.agg同。
1)函数原型:
Series.aggregate(func=None, axis=0, *args, **kwargs)
这是一个示例代码:
import pandas as pd
# 创建一个Series
s = pd.Series([1, 2, 3, 4, 5])
# 定义一个函数,用于计算平均值、中位数和最大值
def my_agg(x):
return {'mean': x.mean(), 'median': x.median(), 'max': x.max()}
# 使用aggregate函数对Series进行聚合操作
result = s.aggregate(my_agg)
print(result)
这个代码创建了一个包含5个元素的Series,并定义了一个名为my_agg的函数,该函数接受一个Series并返回包含平均值、中位数和最大值的字典。
然后,使用aggregate函数将my_agg函数应用于Series,并将结果存储在一个字典中。最后,将结果打印出来。
输出结果为:
{'mean': 3.0, 'median': 3.0, 'max': 5}
这是平均值、中位数和最大值的结果。
3.6、Series.transform函数
有时候我们需要对dataframe进行groupby操作,但序列长度不变。这一点用agg不能完成,因此用transform实现。
1)函数原型:
Series.transform(func, axis=0, *args, **kwargs)
2)参数表
3)非聚合操作示例代码
import pandas as pd
import numpy as np
data = pd.DataFrame({
'姓名': ['吉米', '吉米', '吉米','杰克', '杰克', '杰克', '麦克', '麦克','麦克' ],
'科目': ['语文', '数学', '英语', '语文', '数学', '英语', '语文', '数学', '英语'],
'分数': [80, 90, 70, 60, 75, 85,77,92,88],
})
print(data)
data['分数-对数'] = data['分数'].transform(np.log)
print(data)数据结果:
0 吉米 语文 80
1 吉米 数学 90
2 吉米 英语 70
3 杰克 语文 60
4 杰克 数学 75
5 杰克 英语 85
6 麦克 语文 77
7 麦克 数学 92
8 麦克 英语 88
直接对分数取了对数。
姓名 科目 分数 分数-对数
0 吉米 语文 80 4.382027
1 吉米 数学 90 4.499810
2 吉米 英语 70 4.248495
3 杰克 语文 60 4.094345
4 杰克 数学 75 4.317488
5 杰克 英语 85 4.442651
6 麦克 语文 77 4.343805
7 麦克 数学 92 4.521789
8 麦克 英语 88 4.477337
2)多目标函数操作
import pandas as pd
import numpy as np
data = pd.DataFrame({
'姓名': ['吉米', '吉米', '吉米','杰克', '杰克', '杰克', '麦克', '麦克','麦克' ],
'科目': ['语文', '数学', '英语', '语文', '数学', '英语', '语文', '数学', '英语'],
'分数': [80, 90, 70, 60, 75, 85,77,92,88],
})
print(data)
df = data['分数'].transform([np.log, lambda s: s+1, np.sqrt])
print(df)结果:
log <lambda> sqrt
0 4.382027 81 8.944272
1 4.499810 91 9.486833
2 4.248495 71 8.366600
3 4.094345 61 7.745967
4 4.317488 76 8.660254
5 4.442651 86 9.219544
6 4.343805 78 8.774964
7 4.521789 93 9.591663
8 4.477337 89 9.380832
3)先groupby然后求平均
import pandas as pd
import numpy as np
data = pd.DataFrame({
'姓名': ['吉米', '吉米', '吉米','杰克', '杰克', '杰克', '麦克', '麦克','麦克' ],
'科目': ['语文', '数学', '英语', '语文', '数学', '英语', '语文', '数学', '英语'],
'分数': [80, 90, 70, 60, 75, 85,77,92,88],
})
print(data)
data['均分']= data.groupby('姓名')[['分数' ]].transform('mean')
print(data)结果数据:
姓名 科目 分数 均分
0 吉米 语文 80 80.000000
1 吉米 数学 90 80.000000
2 吉米 英语 70 80.000000
3 杰克 语文 60 73.333333
4 杰克 数学 75 73.333333
5 杰克 英语 85 73.333333
6 麦克 语文 77 85.666667
7 麦克 数学 92 85.666667
8 麦克 英语 88 85.666667