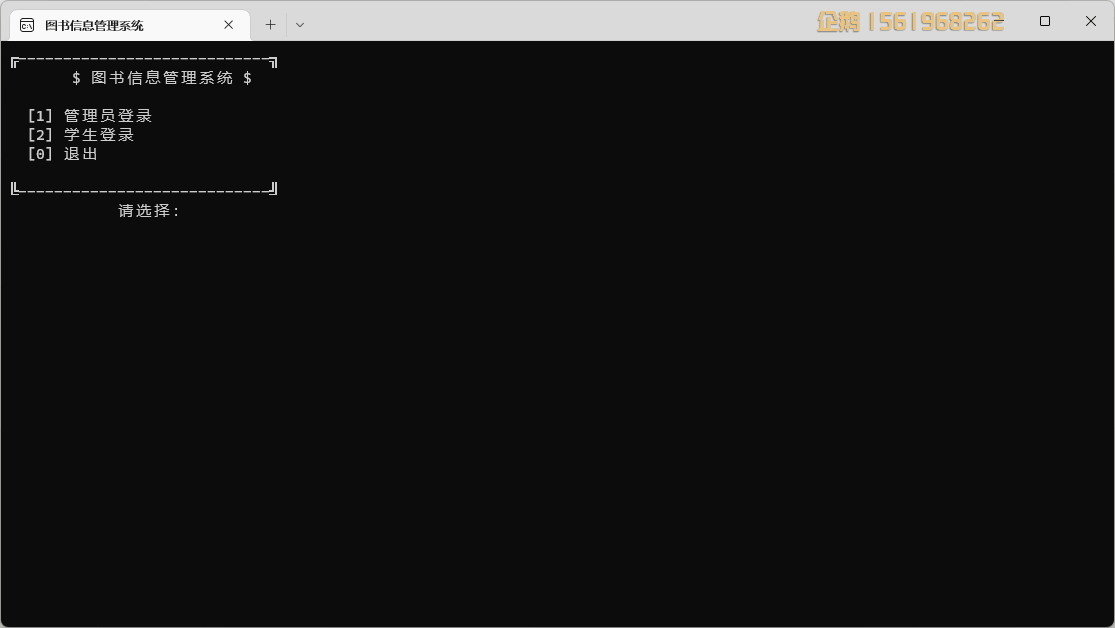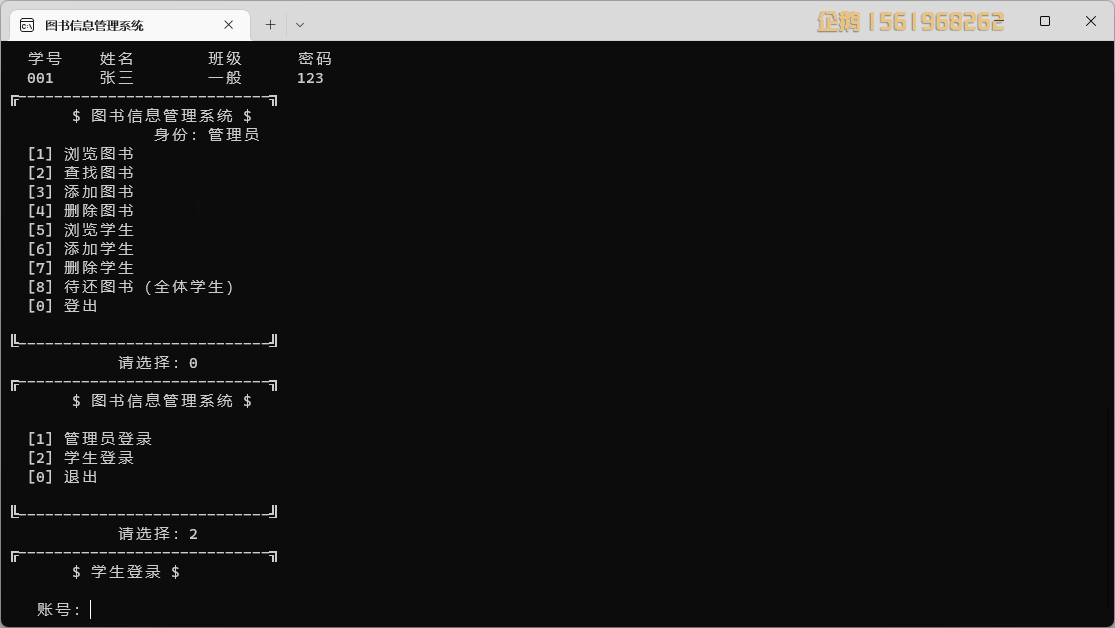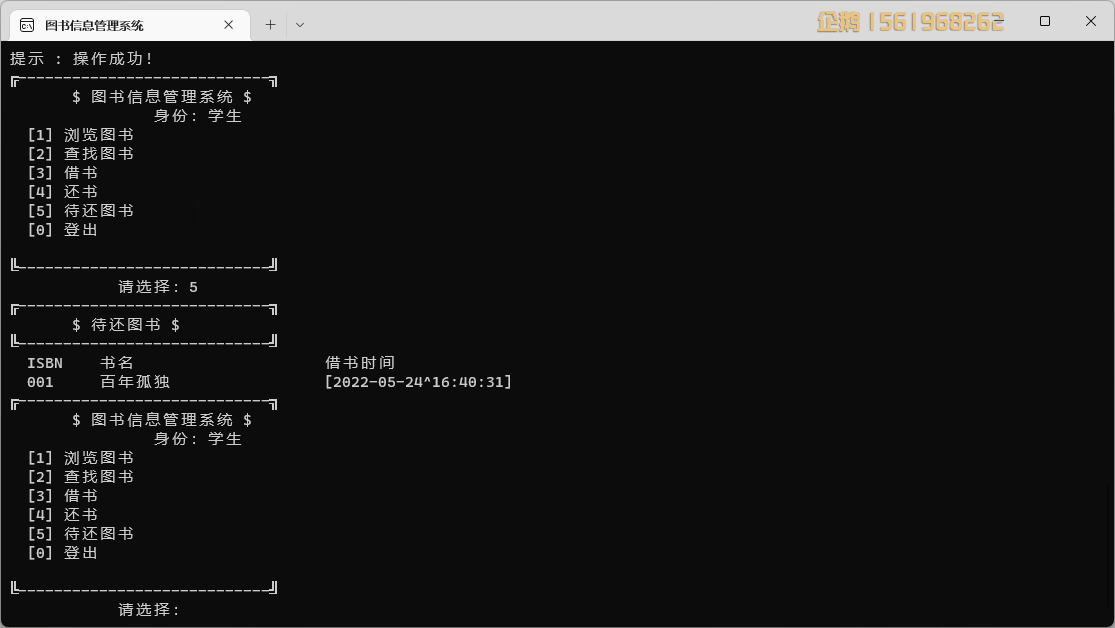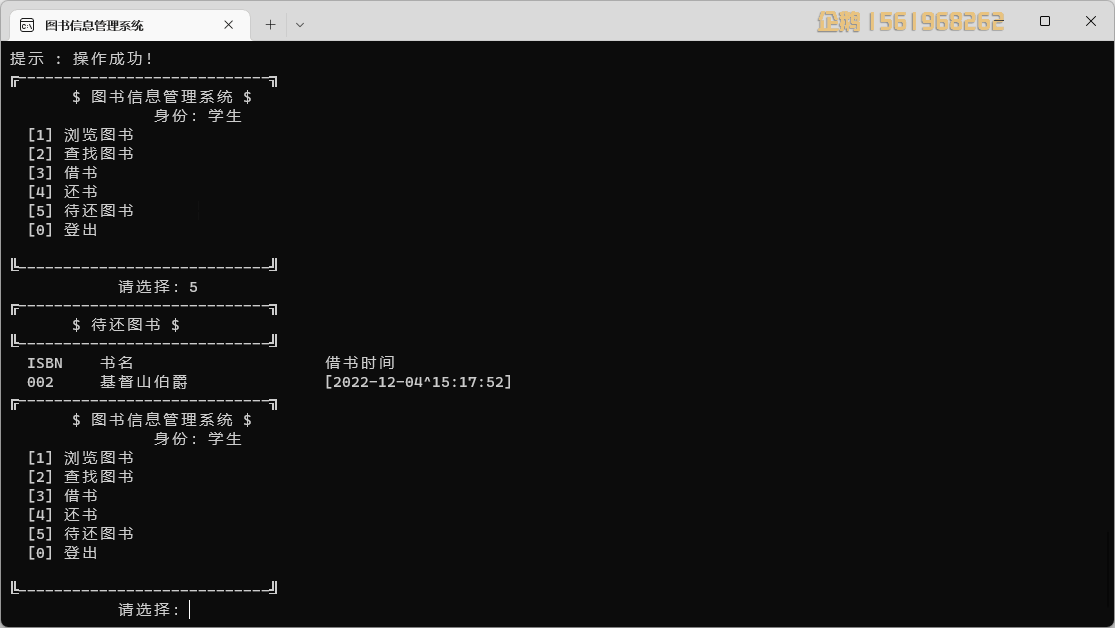
string的初始化
1.常见初始化方式
string对象的初始化和普通类型变量的初始化基本相同,只是string作为类,还有类的一些特性:使用构造函数初始化。如下表,第2 4 6条是作为类才有的初始化方式:
当然,也可以用下面这种格式初始化,其实就是调用string的构造函数生成一个临时的string类,再用临时的string类初始化s5 s6。
string s5 = string("value");
string s6(string("value"));
区别初始化和赋值操作:
区别其实很简单,初始化是生成对象的时候(也就是刚分配内存空间时)就给它值;赋值就是过了初始化后,给对象值。下面的例子就是给st1赋值:
string st1, st2(2,'b');
st1 = st2; //st1此时已近占据了一块内存
string对象的操作
1.用cin获取键盘输入的值
用法很简单,和int、double等内置类型的cin一样使用。不过需要说明一点:
string对象会自动忽略开头的空白(既空格、换行符、制表符等),并从第一个真正的字符开始读入,直到遇到下一处空白
看下面的示例:
string s1;
cin >> s1;
cout << s1 << endl;
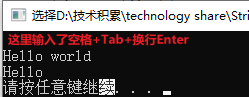
忽略了输入Hello world前的空白。从H开始读取字符,在o后面遇到了一处空白,此时不再读取后面的字符。注意,world其实还在缓冲区内,如果再用cin读取,你无法从键盘输入,会直接读到world。
2.用getline读取一整行
getline的函数格式:getline(cin,string对象)
getline的作用是读取一整行,直到遇到换行符才停止读取,期间能读取像空格、Tab等的空白符。实例如下:
string s1;
getline(cin, s1);
cout << s1 << endl;
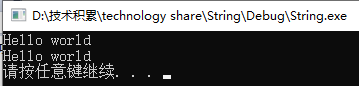
注意:getline函数和cin一样,也会返回它的流参数,也就是cin,所以可以用getline循环读取一行:
string s1;
while(getline(cin, s1))
cout << s1 << endl;
4.比较string的大小
直接给出例子:
string str = "Hello";
string phrase = "Hello ";
尽管两者的前面对应的字符都一样,但是phrase长度长(多一个空格),所以phrase>str。
string str2 = "Hello";
string phrase2 = "Hi ";
这种情况比较的是第一个相异字符,根据字符值比较大小,因为i的字符值>e的字符值,所以phrase2> str2。
总结:看上面两种情况,实际上可以都看成是一个一个字符比较。对于第一种,str最后为空,而phrase为空格,空格字符值不为负,所以phrase>str。
5.两个string对象相加
5.1 两个string对象相加
string str = "Hello,";
string phrase = "world ";
string s = str + phrase;
str += phrase;//相当于str = str + phrase
cout << s << endl;
cout << str << endl;
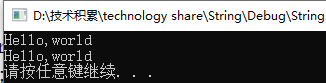
5.2 string对象加上一个字符(或字符串)字面值
首先问一个问题:为什么string对象可以加上字符或字符串字面值?实际上是因为它们可以自动转换为string类型。下面看例子:
string str = "Hello";
string phrase = "world";
string s = str + ','+ phrase+ '\n';
cout << s ;
- 1
- 2
- 3
- 4
- 5

判断下面的加法是否正确?
string str = "Hello";
- 1
(1)string s2 = str + "," + "world";(2)string s3 = "Hello" + "," + str;
答案:(1)正确;(2)错误
(2)错误的原因是:当string对象和字符或字符串字面值相加时,必须确保+号的两侧的运算对象至少有一个string。
至于(1),需要明白,str + “,”会返回一个string类。
如何获取和处理string中的每个字符
1.使用下标运算符[]
直接看下面的例子:
string s = "Hello world!";
cout << s[0] << endl;
cout << s[s.size()-1] << endl;
cout << s << endl;
s[0] = 'h';
cout << s << endl;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
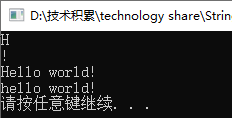
可以通过下标来遍历整个string对象:
string s = "Hello world!";
for (decltype(s.size()) index = 0; index != s.size(); index++){
cout << s[index] << ",";
}
cout<<endl;
- 1
- 2
- 3
- 4
- 5
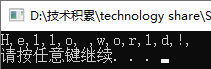
这里把index的类型声明为s.size()的返回类型:string::size_type,它是无符号类型。当然你也可以用其他类型,但是请注意,下标值不能超过string.size()-1,否则会产生不可预知的结果。
decltype使用可参考:有auto为什么还要decltype ?详解decltype的用法
2.使用迭代器
看下面的例子:
string s = "Hello world!";
for (auto i = s.begin(); i != s.end(); i++){
cout << *i << ",";
}
cout << endl;
- 1
- 2
- 3
- 4
- 5
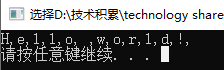
当然,获取每个字符后,你可以做一些处理,比如讲小写改大写等。
3.使用基于范围的for语句
基于范围的for语句是C++11新提供的一种语句,其语法形式是:
declaration:定义一个变量,它每次的值都是expression中的基础元素
expression:一个已经定义的对象(变量)
statement:具体的语句
这样看上去还不明白的话,请看下面的例子,通过例子就可以很好理解:
string str("some string");
for (auto c : str)
cout << c << ",";
cout << endl;
- 1
- 2
- 3
- 4
c就是declaration;str就是expression;cout << c << “,”;就是statement。
for循环把c和str联系起来了。此例中,通过auto关键字让编译器推断c的类型,c这里的类型实际上推断出的是char类型,c每次的值都是str中的一个字符,上述代码的运行的结果如下: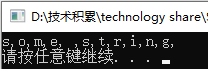
当你需要修改str中的字符时,你可以使用引用,既:for (auto &c : str)。
关于基于范围的for的使用:C++基于范围的for循环:for(auto a:b)
构造string对象的其他方法
1拷贝数组
形式:string s(cp,n)解释:将cp所指的数组的前n个字符拷贝给string对象s,n为可选参数。
直接看下面的例子:
定义3个字符数组,注意: cp和cp2以空字符结尾,cp3没有空字符结尾。
const char *cp = "hello world";//最后有一个空字符
char cp2[] = "hello world";//最后有一个空字符
char cp3[] = { 'h', 'e' };//最后没有空字符
- 1
- 2
- 3
(1) string s1(cp);//s1为”hello world”,长度为11
(2) string s2(cp2);//s2为”hello world”,长度为11
(3) string s3(cp3);//因为cp3不以空字符结尾,所以这是未定义行为
(4) string s4(cp,5);//s4为”hello”,长度为5。将cp改为cp2一样
(5) string s5(cp,13);//s5为”hello world ”,长度为13,后面有两个空字符。将cp改为cp2一样
(6) string s6(cp3,2);//s6为”he”,长度为2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.拷贝string对象
形式:
- string s(s1,pos)
- string s(s1,pos,len)
解释:
- 第一个将s1从下标pos开始拷贝到结尾。当pos>s1.size()时,为未定义行为;当pos=s1.size(),拷贝一个空字符
- 第二个将s1从下标pos开始拷贝,拷贝len个字符。当pos>s1.size()时,为未定义行为;当pos=s2.size(),拷贝一个空字符
例子:
string s1("value");
(1) string s2(s1, 1);//s2为” alue”,长度为4
(2) string s3(s1, 5);//s3为””,长度为0
(3) string s8(s1, 6);// 错误,未定义的行为,抛出异常
(4) string s4(s1, 1,3);// s4为” alu”,长度为3
(5) string s5(s1, 1,8);// 正确,s5为” alue”,长度为4
(6) string s6(s1, 5,8);// s6为””,长度为0
(7) string s7(s1, 6,1);// 错误,未定义的行为,抛出异常
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
总结:相比于数组,拷贝string对象时,只能拷贝到string的结尾,这一点可以看数组的(5)和string对象(5)。
3.使用substr成员函数
格式:s.substr(pos,n)解释:返回一个string对象,返回的对象包含s从pos下标开始的n个字符。pos和n均为可选参数。pos默认为下标0;n默认为s.size()-pos。示例:
string s ("value");
(1)string s2 = s.substr();//s2为”value”,大小为5
(2)string s3 = s.substr(2);//s3为”lue”,大小为3
(3)string s4 = s.substr(5);//s3为””,大小为0
(4)string s5 = s.substr(6);//错误,s5的大小为pos = 5,小于s.size()
(5)string s6 = s.substr(1,2);// s6为”al”,大小为2
(6)string s7 = s.substr(1,7);// s7为”alue”,大小为4
(7)string s8 = s.substr(5,7);// s8为””,大小为0
(8)string s9 = s.substr(6,7);// 错误,s9的大小为pos = 5,小于s.size()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
总结:和第2部分“拷贝string对象”的形式2基本相同。
string对象的insert()
string的insert操作有两种版本的insert:除了顺序容器通用的迭代器版本外还可以使用下标版本。下面分别介绍这两种版本。
迭代器insert
有4种形式:
- iterator insert( iterator pos, CharT ch )
- void insert( iterator pos, size_type count, CharT ch )
- void insert( iterator pos, InputIt first, InputIt last )
- 插入初始化列表
因为是顺序容器通用的迭代器版本,这里不过多介绍,只简单举例说明一下使用。
在list容器的insert操作中,我详细介绍了insert的使用,感兴趣可以看看。C++ STL::list常用操作及底层实现(中1)——实现list常用操作之插入(insert、push_front、push_back、splice)
pos是调用insert的string对象的迭代器位置;ch是单个字符;count是ch的个数。下面是例子。
string s1("value");
s1.insert(s1.begin(), 's');//执行后,s1为"svalue"
s1.insert(s1.begin(), 1, 's');//执行后,s1为"ssvalue"
s1.insert(s1.begin(), s1.begin(), ++s1.begin());//执行后,s1为"sssvalue"
s1.insert(s1.end(), {'1','2'});//执行后,s1为"sssvalue12"
- 1
- 2
- 3
- 4
- 5
- 6
下标insert
- basic_string& insert( size_type index, size_type count, CharT ch )
解释:在下标index前插入count个字符ch。
例子:
string s1("value");
s1.insert(0,2,’s’); //执行后,s1为” ssvalue”
s1.insert(5,2,’s’); //执行后,s1为” valuess”
- basic_string& insert( size_type index, const CharT* s );
basic_string& insert( size_type index, const basic_string& str );
解释:在下标index前插入一个常量字符串或者string对象。
例子:
string s1("value");
string s3 = "value";
const char* cp = "value";
s1.insert(0,s3);//执行完后,s1为" valuevalue"
s1.insert(0,cp); //执行完后,s1为" valuevalue"
- basic_string& insert( size_type index, const basic_string& str,
size_type index_str, size_type count );
解释:在下标index前插入str中的从str[index_str]开始的count个字符
例子:
string s1("value");
string s3 = "value";
const char* cp = "value";
下面在s1的下标0前插入s3的从s3[1]开始的2个字符
s1.insert(0,s3,1,2);//执行后,s1为” alvalue”
- basic_string& insert( size_type index, const CharT* s, size_type count );
解释:在index前插入常量字符串的count个字符
例子:
string s1("value");
const char* cp = "value";
下面在s1的下标0前插入cp的前3个字符
s1.insert(0, cp,3); //执行后,s1为” valvalue”
string对象的erase()
erase有3种形式,其方法原型如下:
basic_string & erase(size_type pos=0, size_type n=npos)
解释:如果string对象s调用,它删除s从pos下标开始的n个字符,并返回删除后的s。当pos > s.size()时,报错
iterator erase(const_iterator position)
解释:如果string对象s调用,它删除s迭代器position位置的字符,并返回下一个字符的迭代器。
iterator erase(const_iterator first, const_iterator last)
解释:如果string对象s调用,它删除s迭代器[first,last)区间的字符,并返回last字符的迭代器。
例子:
string s1("value");
string s2("value");
string s3("value");
string s4("value");
s1.erase();//执行后,s1为空
s2.erase(0,2); //执行后,s2为”lue”
s3.erase(s3.begin());//执行后,s3为”alue”
s4.erase(s4.begin(),++s4.begin());//执行后,s4为”alue”
string对象的append()和replace()
1. append()
append是在string对象的末尾进行插入操作。这一点使用+运算符也能做到。
string s("i love China!");
s.append("forever");//执行完后,s=” i love China! forever”
2. replace()
replace可看作是erase和insert的结合体,它删除指定的字符,删除后再插入指定的字符。
和insert一样,可以通过下标或者是迭代器指定位置。
情形1:下标指定删除的位置
string s("i very love China!");
const char* cp1 = "truly";
const char* cp2 = "truly!!!";
string str1 = "really";
string str2 = "really!!!";
//1.将s从下标2开始删除4个字符,删除后在下标2处插入cp1
s.replace(2,4,cp1);//s=” i truly love China!”
//2.将s从下标2开始删除5个字符,删除后在下标2插入cp2的前5个字符
s.replace(2, 5, cp2,5); //s=” i truly love China!”
//3.将s从下标2开始删除5个字符,删除后在下标2插入str1
s.replace(2, 5, str1);//s=”i really love China!”
//4.将s从下标2开始删除6个字符,删除后在下标2插入str2从下标0开始的6个字符
s.replace(2, 6, str2,0,6);//s=”i really love China!”
//5.将s从下标2开始删除6个字符,删除后在下标2插入4个’*’字符
s.replace(2, 6, 4, '*');//s=”i **** love China!”
情形2:迭代器指定删除的位置
string s1("bad phrase");
const char* cp3 = "sample";
const char* cp4 = "sample!!!";
string str3 = "useful";
string str4 = "useful!!!";
//1.删除[s1.begin(),s1. begin()+3)区间字符,删除后插入cp3
s1.replace(s1.begin(),s1.begin()+3,cp3);//s1="sample phrase"
//2.删除[s1.begin(),s1. begin()+6)区间字符,删除后插入cp4的前6个字符
s1.replace(s1.begin(),s1.begin()+6,cp4,6);//s1="sample phrase"
//3.删除[s1.begin(),s1. begin()+6)区间字符,删除后插入str3
s1.replace(s1.begin(),s1.begin()+6, str3);//s1="useful phrase"
//4.删除[s1.begin(),s1. begin()+6)区间字符,删除后插入str4[str4.begin(),str4. begin()+6)区间字符
s1.replace(s1.begin(),s1.begin()+6, str4.begin(),str4.begin() + 6);//s1="useful phrase"
//5. 删除[s1.begin(),s1. begin()+6)区间字符,删除后插入4个’*’字符
s1.replace(s1.begin(),s1.begin()+6, 4, '*');//s1="**** phrase"
//6. 删除[s1.begin(),s1. begin()+4)区间字符,删除后插入初始化列表
s1.replace(s1.begin(), s1.begin() + 4, {'3','4','5'});//s1="345 phrase"
总结insert和replace
这两个成员函数有太多的参数形式,如何更好的记忆呢?看下表:
说明如下
pos:下标位置
len:个数
b\e\b2\e2:迭代器指向的位置,如begin() end()等
n,c:n个字符c
str:字符串str
cp:cp指向以空字符结尾的字符数组
总结表格:
- 使用了下标标识位置的,其args参数不能含有迭代器;使用了迭代器标识位置的,其args参数不能含有下标信息;
- cp和cp,len是一对;str和str,pos,len是一对
- args为初始化列表只能在用迭代器标识位置时使用
- 注意:上表还有一种情况没有列出,既insert可以直接插入一个字符,如(s.begin(),’’);所以在insert初始化列表时,初始化列表不能有单个字符如{‘’},使用vs2013编译器会报错“对重载函数的调用不明确”。
string对象的assign()
assign方法可以理解为先将原字符串清空,然后赋予新的值作替换。
格式如下,可以发现,就输入参数而言,和“总结insert和replace”这一节中的表的args参数是一样的,这里不在多做说明,直接给出7个例子,在例子中说明。
- string& assign (const string& str);
- string& assign (const string& str, size_t subpos, size_t sublen);
- string& assign (const char* s);
- string& assign (const char* s, size_t n);
- string& assign (size_t n, char c);
- template string& assign (InputIterator first, InputIterator last);
- string& assign (initializer_list il);
实例:
std::string str;
std::string base = "The quick brown fox jumps over a lazy dog.";
//1.参数形式1
str.assign(base);
std::cout << str << '\n';
//2.参数形式2:将base从下标10开始的9个字符赋值给str
str.assign(base, 10, 9);
std::cout << str << '\n'; // "brown fox"
//3.参数形式4:将"pangrams are cool"的前7个字符赋值给str
str.assign("pangrams are cool", 7);
std::cout << str << '\n'; // "pangram"
//4.参数形式3:将"c-string"赋值给str
str.assign("c-string");
std::cout << str << '\n'; // "c-string"
//5.参数形式5:将10个字符'*'赋值给str
str.assign(10, '*');
std::cout << str << '\n'; // "**********"
//6.参数形式6:将[base.begin() + 16, base.end() - 12)赋值给str
str.assign(base.begin() + 16, base.end() - 12);
std::cout << str << '\n'; // "fox jumps over"
//7.参数形式7:将初始化列表{'l','o','v','e'}赋值给str
str.assign({ 'l', 'o', 'v', 'e' });
std::cout << str << '\n'; // "love"
string对象的搜索操作
string提供6个不同的搜索函数,每个函数都有4个重载版本,所有函数的返回值都为string::size_type值,表示匹配发生位置的下标。
函数形式:
| string搜索函数 | 描述 |
|---|---|
| s.find(args) | 在s中查找第一次出现args的下标 |
| s.rfind(args) | 在s中查找最后一次出现args的下标 |
| s.find_first_of(args) | 在s中查找第一个在args中出现的字符,返回其下标 |
| s.find_first_not_of(args) | 在s中查找第一个不在args中出现的字符,返回其下标 |
| s.find_last_of(args) | 在s中查找最后一个在args中出现的字符,返回其下标 |
| s.find_last_not_of(args) | 在s中查找最后一个不在args中出现的字符,返回其下标 |
其中args参数格式如下:
| args参数格式 | 描述 |
|---|---|
| c,pos | 搜索单个字符。从s中位置pos开始查找字符c。pos可省略,默认值为0 |
| s2,pos | 搜索字符串。从s中位置pos开始查找字符串string对象s2。pos可省略,默认值为0 |
| cp,pos | 搜索字符串。从s中位置pos开始查找指针cp指向的以空字符结尾的C风格字符串。pos可省略,默认值为0 |
| cp,pos,n | 从s中位置pos开始查找指针cp指向的数组的前n个字符。 |
搜索函数实例
注:
- 下面的例子均参考自http://www.cplusplus.com/reference/string/string/find/。
- std::string::npos是string类中定义的一个std::size_t类型变量,值为std::size_t类型的最大值。
1.find()函数的实列
下面的例子包含了args对应的4种参数形式。在后面介绍其他函数时将不在针对args都给出例子。
std::string str("There are two needles in this haystack with needles.");
std::string str2("needle");
//1.对应参数args为s2,pos
std::size_t found = str.find(str2);//返回第一个"needles"n的下标
if (found != std::string::npos)
std::cout << "first 'needle' found at: " << found << '\n';
//2.对应参数args为cp,pos, n
found = str.find("needles are small", found + 1, 6);
if (found != std::string::npos)
std::cout << "second 'needle' found at: " << found << '\n';
//3.对应参数args为cp,pos
found = str.find("haystack");
if (found != std::string::npos)
std::cout << "'haystack' also found at: " << found << '\n';
//4.对应参数args为c,pos
found = str.find('.');
if (found != std::string::npos)
std::cout << "Period found at: " << found << '\n';
// 替换第一个needle:
str.replace(str.find(str2), str2.length(), "preposition");
std::cout << str << '\n';

2.rfind()函数实例
把最后一个”sixth”换成” seventh”。
cout << " rfind()函数:" << endl;
std::string str("The sixth sick sheik's sixth sheep's sick.");
std::string key("sixth");
std::size_t found = str.rfind(key);//找到最后一个sixth的下标
if (found != std::string::npos)
str.replace(found, key.length(), "seventh");//替换找到的sixth
std::cout << str << '\n';

3.find_first_of()函数例子
把str中的所有元音字母aeiou换成*。
std::string str("Please, replace the vowels in this sentence by asterisks.");
std::size_t found = str.find_first_of("aeiou");
while (found != std::string::npos)
{
str[found] = '*';
found = str.find_first_of("aeiou", found + 1);
}
std::cout << str << '\n';

4.find_first_not_of函数例子
找到str中的第一个非小写字母或空格的字符。
std::string str("look for non-alphabetic characters...");
std::size_t found = str.find_first_not_of("abcdefghijklmnopqrstuvwxyz ");
if (found != std::string::npos)
{
std::cout << "The first non-alphabetic character is " << str[found];
std::cout << " at position " << found << '\n';
}

5.find_last_of函数例子
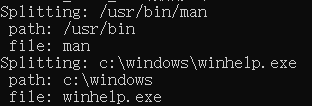
SplitFilename()函数是将str1和str2中的文件名和文件名所在路径分开并打印。注意,str2中有两个\,其中第一个是转义字符。同样,find_last_of()中的\的第一个也是转义字符。
#include <iostream> // std::cout
#include <string> // std::string
#include <cstddef> // std::size_t
void SplitFilename (const std::string& str)
{
std::cout << "Splitting: " << str << '\n';
std::size_t found = str.find_last_of("/\\");
std::cout << " path: " << str.substr(0,found) << '\n';
std::cout << " file: " << str.substr(found+1) << '\n';
}
int main ()
{
std::string str1 ("/usr/bin/man");
std::string str2 ("c:\\windows\\winhelp.exe");
SplitFilename (str1);
SplitFilename (str2);
system("pause");
return 0;
}
6.find_last_not_of()例子
查找最后一个不是whitespaces对象的字符,并删除(erase函数)此字符后面的所有字符。
std::string str("Please, erase trailing white-spaces \n");
std::string whitespaces(" \t\f\v\n\r");
std::size_t found = str.find_last_not_of(whitespaces);
if (found != std::string::npos)
str.erase(found + 1);
else
str.clear(); // str is all whitespace
std::cout << '[' << str << "]\n";

string对象的compare操作
在前面,我们介绍了用比较运算符比较两个字符串的方法,同时string对象中有一个成员函数compare,它也可以比较字符串,并且有6种不同的参数形式,比较字符串时更加灵活。compare的参数形式如下:
| 参数形式s.compare() | 说明 |
|---|---|
| s2 | 比较s和s2 |
| pos1, n1, s2 | 将s中从pos1开始的n1个字符与s2比较 |
| pos1, n1, s2, pos2, n2 | 将s中从pos1开始的n1个字符与s2中从pos2开始的n2个字符比较 |
| cp | 比较s与cp指向的以空字符结尾的数组 |
| pos1, n1, cp | 将s中从pos1开始的n1个字符与cp指向的以空字符结尾的数组比较 |
| pos1, n1, cp,n2 | 将s中从pos1开始的n1个字符与cp指向的以空字符结尾的数组前n个字符比较 |
注意:
- 若s=指定的字符串,s.compare()返回0
- 若s>指定的字符串,s.compare()返回正数
- 若s<指定的字符串,s.compare()返回负数
例子:
std::string str1("green apple");
std::string str2("red apple");
//1.str1和str2比较:参数形式1
if (str1.compare(str2) != 0)
std::cout << str1 << " is not " << str2 << '\n';
//2.str1的下标6开始的5个字符和"apple"比较:参数形式5
if (str1.compare(6, 5, "apple") == 0)
std::cout << "still, " << str1 << " is an apple\n";
//3.str2的下标str2.size() - 5(就是下标6)开始的5个字符和"apple"比较:参数形式5
if (str2.compare(str2.size() - 5, 5, "apple") == 0)
std::cout << "and " << str2 << " is also an apple\n";
//4.str1的下标6开始的5个字符和str2的下标4开始的5个字符比较:参数形式3
if (str1.compare(6, 5, str2, 4, 5) == 0)
std::cout << "therefore, both are apples\n";
//5.str1的下标6开始的5个字符和"apple pie"的前5个字符比较:参数形式6
if (str1.compare(6, 5, "apple pie",5) == 0)
std::cout << "apple pie is maked by apple\n";
//6.str1和"poisonous apple"比较:参数形式4
if (str1.compare("poisonous apple") < 0)
std::cout << "poisonous apple is not a apple\n";
字符串和数值间的转换
格式和说明如下:
注意:
- std::to_string()有9种重载形式,分别对应int/long /long long/unsigned/unsigned long/unsigned long long/float/double/long double。
- b默认值为10,即10进制;若b = 0,则表示自动确定string序列的基数,如0x7f会自动以16进制为基数。
- 对于转换为浮点型的字符串(上述表格的最后3个),可以识别小数点和指数e、E,如
std::stod(".3e3")结果为300。
to_string 例子
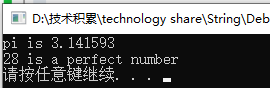
std::string pi = "pi is " + std::to_string(3.1415926);
std::string perfect = std::to_string(1 + 2 + 4 + 7 + 14) + " is a perfect number";
std::cout << pi << '\n';
std::cout << perfect << '\n';
stoi(s,p,b) 例子(stol stoll stoul stoull类似,不再举例)
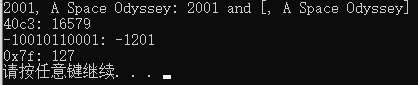
std::string str_dec = "2001, A Space Odyssey";
std::string str_hex = "40c3";
std::string str_bin = "-10010110001";
std::string str_auto = "0x7f";
std::string::size_type sz; // alias of size_t
//1.转换基数为10进制,sz保存','下标,i_dec = 2001
int i_dec = std::stoi(str_dec, &sz);
//2.转换基数为16进制。所以i_hex = 0x40c3,十进制为16579
int i_hex = std::stoi(str_hex, nullptr, 16);
//3.转换基数为2进制。所以i_bin = -10010110001B,十进制为-1201
int i_bin = std::stoi(str_bin, nullptr, 2);
//4.自动确定 转换基数
int i_auto = std::stoi(str_auto, nullptr, 0);
std::cout << str_dec << ": " << i_dec << " and [" << str_dec.substr(sz) << "]\n";
std::cout << str_hex << ": " << i_hex << '\n';
std::cout << str_bin << ": " << i_bin << '\n';
std::cout << str_auto << ": " << i_auto << '\n';
stof(s,p)例子
cout << "stof示例" << endl;
std::string orbits("686.97 365.24");
std::string::size_type sz; // alias of size_t
//1.mars = 686.97,sz保存空格下标
float mars = std::stof(orbits, &sz);
//1.将" 365.24"转换为float类型,earth = 686.97
float earth = std::stof(orbits.substr(sz));
std::cout << "One martian year takes " << (mars / earth) << " Earth years.\n";

以上就是string的常用操作使用说明
C++ string使用介绍(非常全面,详细)_代码乌龟的博客-CSDN博客_c++ string