目录
前言
课题背景和意义
实现技术思路
实现效果图样例
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器视觉的车型识别
课题背景和意义
在交通安防中,车型识别是一个重要的技术点,车型识别主要包括车辆检测、型号识别、颜色识别,基于视频的车型识别,还包括跟踪算法的设计。
实现技术思路
数据集准备与处理
拍摄尽可能多的车辆照片,主要为汽车、公共汽车、卡车三种类型,拍摄时尽可能从不同角度、不同场景、不同环境下采集图片,初次之外,每种类型车型的图片量尽可能相差不大。
数据标记
标注图片时,要时常查看标注的数据是否已经保存,并且要非常注意要勾选标注图片的类型
一定要生成指定的XML格式文件,此次主要是根据pascal xml数据制作数据标签
生成标签
object-class:是指对象的索引,从0开始,具体代表哪个对象去obj.names配置文件中按索引查,初次之外,每个txt文件可以有多个boundbox的信息,表示圈定的图片不是一个单一类。
x,y:是一个坐标,需要注意的是它可不是对象左上角的坐标,而对象中心的坐标
width,height:是指对象的宽高
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2018', 'train'), ('2018', 'val')]
classes = ["car", "bus", "truck"] #设置分类车型
def convert(size, box): #此函数主要生成labels文件中归一化的值
dw = 1./(size[0]) #用于归一化
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 #找出对象的中心点坐标
y = (box[2] + box[3])/2.0
w = box[1] - box[0] # 得到真是的boundbox的长宽信息
h = box[3] - box[2]
x = x*dw #归一化
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):#解析XMl文件
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text #查找是不是我们自己的类
if cls not in classes or int(difficult)==1:#跳过
continue
cls_id = classes.index(cls)#得到类别标签
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
#1.创建labels文件夹
for year, image_set in sets: #此处第一个循环训练集 第二个循环验证集
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
#2.得到图片的id
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
#3.创建训练集和验证集文件夹
list_file = open('%s_%s.txt'%(year, image_set), 'w')
#4.创建绝对路径下的图片文件路径
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
#5.xml 转 label
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2018_train.txt 2018_val.txt > train.txt")#扩充训练集数据量
数据预处理
classes= 3 #分类类型
train = /home/gavin/Machine/darknet/scripts/train.txt #训练集
valid = /home/gavin/Machine/darknet/scripts/2018_val.txt #验证集
names = data/voc.names #类别信息
backup = backup #存放训练权重训练模型
Avg IOU:当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class: 标注物体的分类准确率,越大越好,期望数值为1;
obj: 越大越好,期望数值为1;
No obj: 越小越好;
.5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R: 以IOU=0.75为阈值时候的recall;
count:正样本数目。
检测图片
测试检测结果准确度
数据分析
提取数据
import inspect
import os
import random
import sys
def extract_log(log_file,new_log_file,key_word):
with open(log_file, 'r') as f:
with open(new_log_file, 'w') as train_log:
#f = open(log_file)
#train_log = open(new_log_file, 'w')
for line in f:
# 去除多gpu的同步log
if 'Syncing' in line:
continue
# 去除除零错误的log
if 'nan' in line:
continue
if key_word in line:
train_log.write(line)
f.close()
train_log.close()
extract_log('yolov3.log','train_log_loss.txt','images')
extract_log('yolov3.log','train_log_iou.txt','IOU')
绘制数据图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
lines =79755 #改为自己生成的train_log_loss.txt中的行数
result = pd.read_csv('train_log_loss.txt', skiprows=[x for x in range(lines) if ((x%10!=9) |(x<1000))] ,error_bad_lines=False, names=['loss', 'avg', 'rate', 'seconds', 'images'])
result.head()
result['loss']=result['loss'].str.split(' ').str.get(1)
result['avg']=result['avg'].str.split(' ').str.get(1)
result['rate']=result['rate'].str.split(' ').str.get(1)
result['seconds']=result['seconds'].str.split(' ').str.get(1)
result['images']=result['images'].str.split(' ').str.get(1)
result.head()
result.tail()
# print(result.head())
# print(result.tail())
# print(result.dtypes)
print(result['loss'])
print(result['avg'])
print(result['rate'])
print(result['seconds'])
print(result['images'])
result['loss']=pd.to_numeric(result['loss'])
result['avg']=pd.to_numeric(result['avg'])
result['rate']=pd.to_numeric(result['rate'])
result['seconds']=pd.to_numeric(result['seconds'])
result['images']=pd.to_numeric(result['images'])
result.dtypes
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(result['avg'].values,label='avg_loss')
# ax.plot(result['loss'].values,label='loss')
ax.legend(loc='best') #图列自适应位置
ax.set_title('The loss curves')
ax.set_xlabel('batches')
fig.savefig('avg_loss')
# fig.savefig('loss')
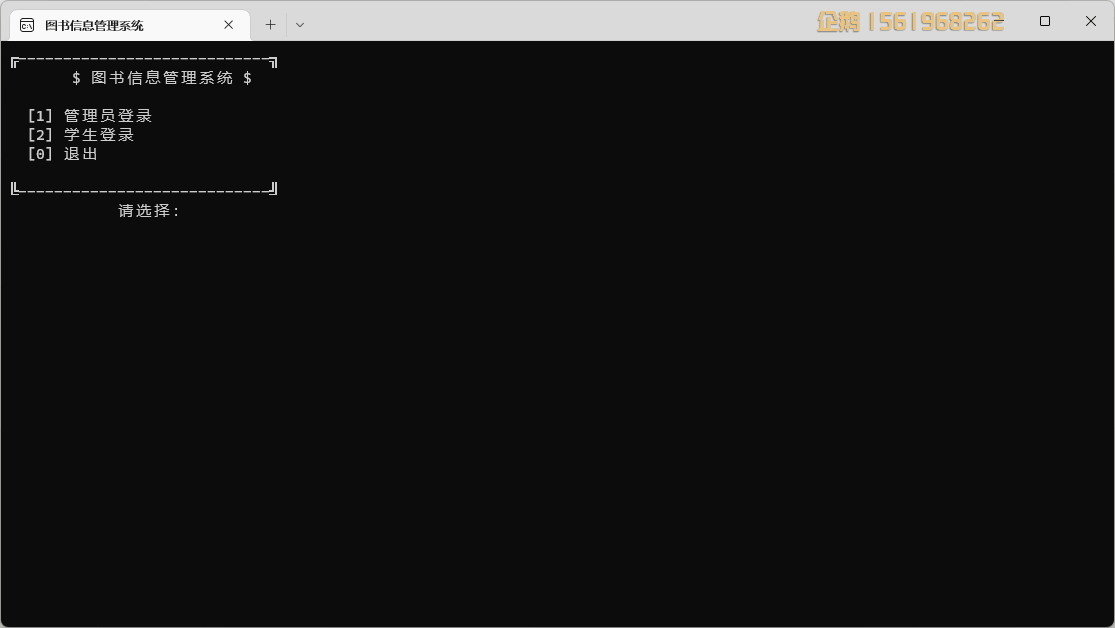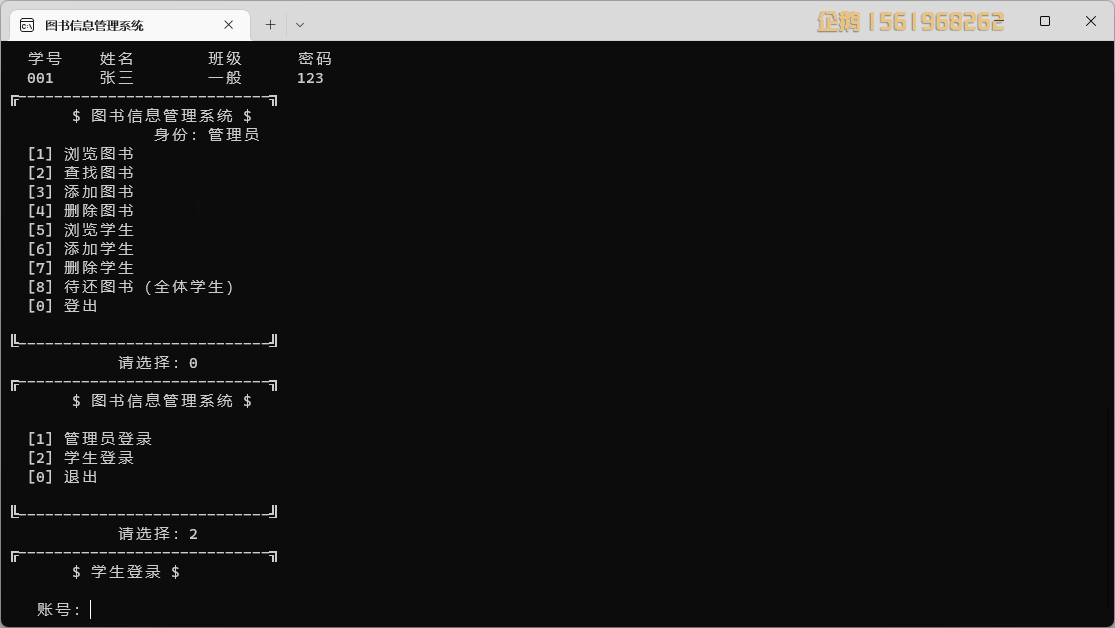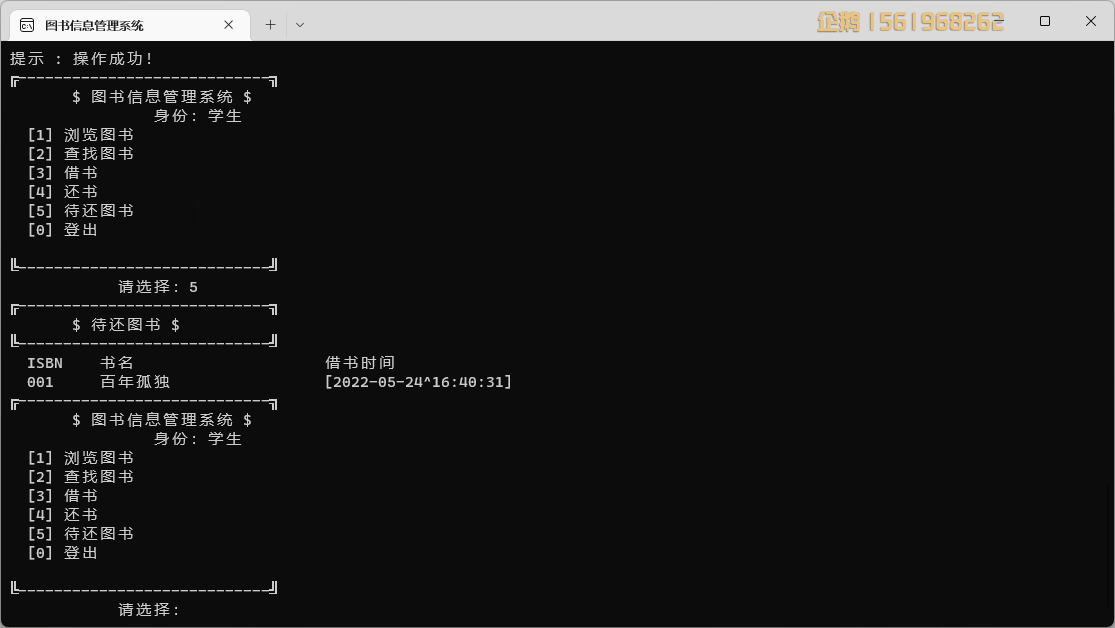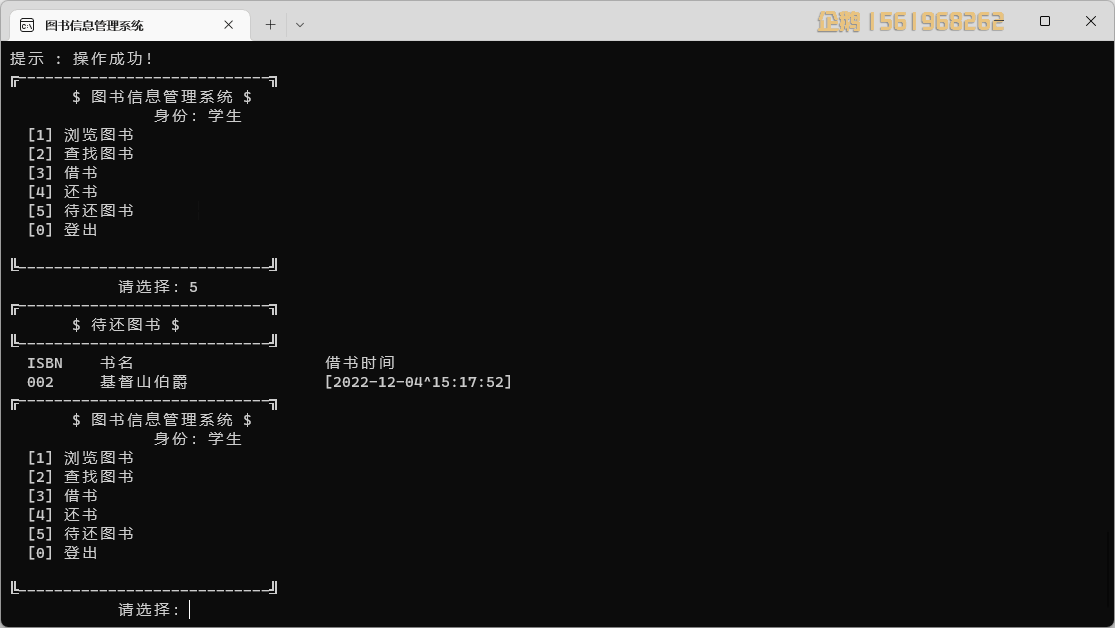
实现效果图样例


我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!