向量加法包括常见的普通加指令,还包括长加、宽加、半加、饱和加、按对加、按对加并累加、选择高半部分结果加、全部元素加等。如果你和我一开始以为的只有一种普通加,那就太小看设计者了!同时这么多加法指令的确会提升我们设计程序的效率,同样学习这些指令也需要花费不少精力。
1 ADD
加(向量),该指令将两个源 SIMD&FP 寄存器中的相应元素相加,将结果放入向量中,并将向量写入目标 SIMD&FP 寄存器。
标量

ADD <V><d>, <V><n>, <V><m>
向量

ADD <Vd>.<T>, <Vn>.<T>, <Vm>.<T>
<V> 是宽度说明符,以“size”编码:
| size | <V> |
|---|---|
| 0x | RESERVED |
| 10 | RESERVED |
| 11 | D |
<d> 是 SIMD&FP 目标寄存器的编号,在“Rd”字段中。
<n> 是第一个 SIMD&FP 源寄存器的编号,编码在“Rn”字段中。
<m> 是第二个 SIMD&FP 源寄存器的编号,编码在“Rm”字段中。
<Vd> 是 SIMD&FP 目标寄存器的名称,在“Rd”字段中编码。
<T> 是排列说明符,编码为“size:Q”:
| size | Q | <T> |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | 2S |
| 10 | 1 | 4S |
| 11 | 0 | RESERVED |
| 11 | 1 | 2D |
<Vn> 是第一个 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<Vm> 是第二个 SIMD&FP 源寄存器的名称,在“Rm”字段中编码。
下面是使用 ADD 指令的例子。
auto *srcArr = new int[4];
for (int i = 0; i < 4; i++) {
srcArr[i] = 100 * (i + 1);
}
char *src = (char *) srcArr;
LOGD("in srcArr: %d %d %d %d", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
asm volatile(
"LD1 {v0.4S}, [%[src]]\n"
"ADD v1.4S, v0.4S, v0.4S\n"
"ST1 {v1.4S}, [%[src]]\n"
:[src] "+r"(src)
:
: "cc", "memory", "v0");
LOGD("-----------------------------");
LOGD("out srcArr: %d %d %d %d", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
delete[] srcArr;
ADD v1.4S, v0.4S, v0.4S 将 v0 寄存器 S 通道的值加上 v0 寄存器 S 通道的值的结果写入 v1 的 S 通道。
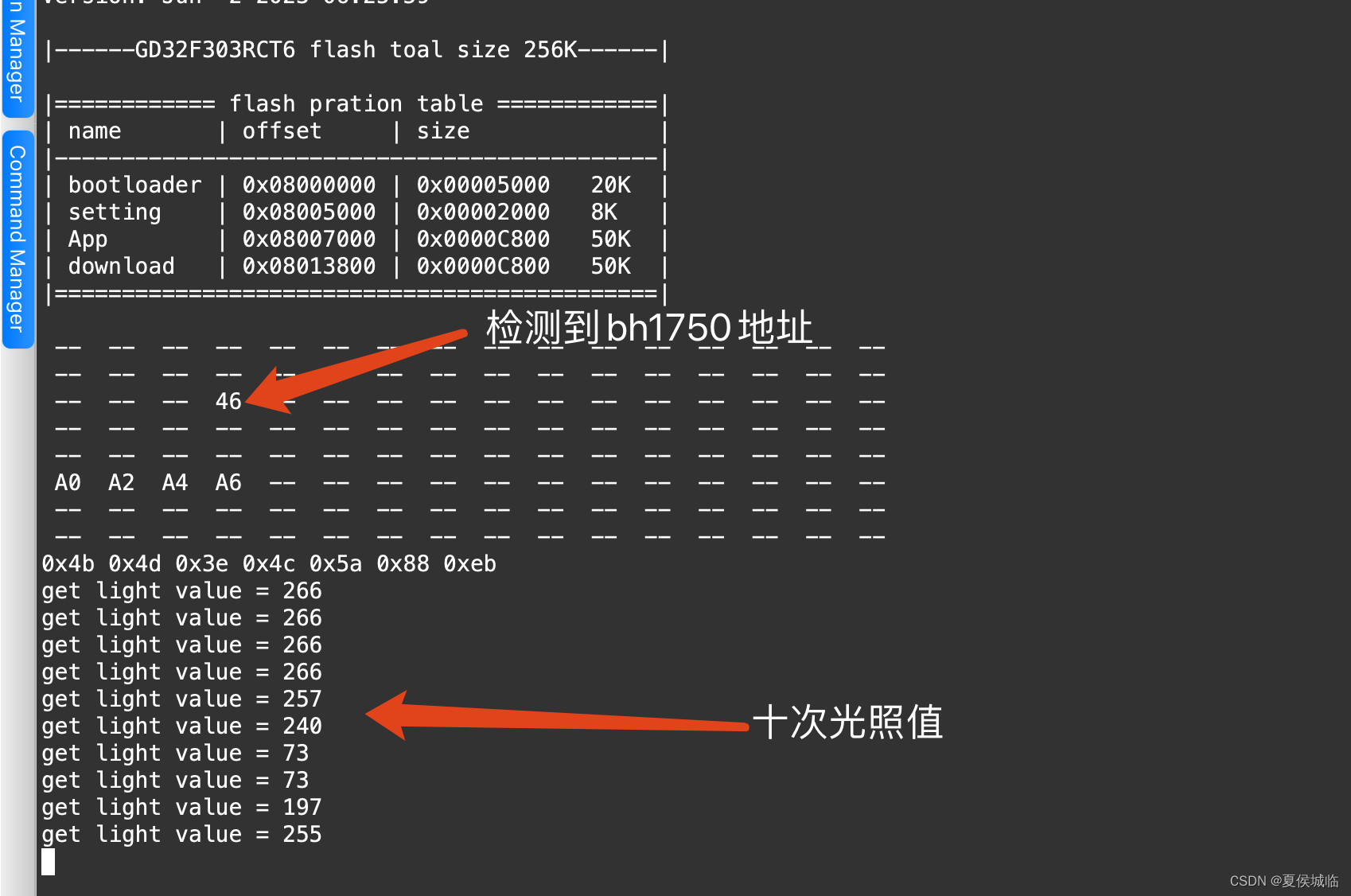
运行结果:
2023-05-20 14:58:44.906 5306-5306/com.example.myapplication D/native-armv8a: in srcArr: 100 200 300 400
2023-05-20 14:58:44.906 5306-5306/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-20 14:58:44.906 5306-5306/com.example.myapplication D/native-armv8a: out srcArr: 200 400 600 800
2 UADDL/UADDL2
无符号长加(向量),该指令将第一个源 SIMD&FP 寄存器的下半部分或上半部分中的每个向量元素与第二个源 SIMD&FP 寄存器的相应向量元素相加,将结果放入向量中,并将向量写入目标 SIMD&FP 寄存器。目标向量元素的长度是源向量元素的两倍。该指令中的所有值都是无符号整数值。
UADDL 指令从每个源寄存器的下半部分提取每个源向量。UADDL2 指令从每个源寄存器的上半部分提取每个源向量。

UADDL{2} <Vd>.<Ta>, <Vn>.<Tb>, <Vm>.<Tb>
2 是第二个和上半部分说明符。如果存在,它会导致对保存较窄元素的寄存器的高 64 位执行操作,并以“Q”编码:
| Q | 2 |
|---|---|
| 0 | [absent] |
| 1 | [present] |
<Vd> 是 SIMD&FP 目标寄存器的名称,在“Rd”字段中编码。
<Ta> 是排列说明符,以“size”编码:
| size | <Ta> |
|---|---|
| 00 | 8H |
| 01 | 4S |
| 10 | 2D |
| 11 | RESERVED |
<Vn> 是第一个 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<Tb> 是排列说明符,编码为“size:Q”:
| size | Q | <T> |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | 2S |
| 10 | 1 | 4S |
| 11 | x | RESERVED |
<Vm> 是第二个 SIMD&FP 源寄存器的名称,在“Rm”字段中编码。
下面是使用 UADDL/UADDL2 指令的例子。
auto *srcArr = new unsigned int[4];
auto *outArr = new unsigned long long int[4]{0};
for (int i = 0; i < 4; i++) {
srcArr[i] = 100 * (i + 1);
}
char *src = (char *) srcArr;
char *dst = (char *) outArr;
LOGD("in srcArr: %u %u %u %u", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
asm volatile(
"LD1 {v0.4S}, [%[src]]\n"
"UADDL v1.2D, v0.2S, v0.2S\n"
"UADDL2 v2.2D, v0.4S, v0.4S\n"
"ST1 {v1.2D, v2.2D}, [%[dst]]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1", "v2");
LOGD("-----------------------------");
LOGD("out outArr: %llu %llu %llu %llu", outArr[0], outArr[1], outArr[2], outArr[3]);
delete[] srcArr;
delete[] outArr;
UADDL v1.2D, v0.2S, v0.2S 将 v0 寄存器低半部分两个 S 通道的值加上 v0 寄存器低半部分两个 S 通道的值,并将结果写入 v1 寄存器的两个 D 通道。
UADDL2 v2.2D, v0.4S, v0.4S 将 v0 寄存器高半部分两个 S 通道的值加上 v0 寄存器高半部分两个 S 通道的值,并将结果写入 v2 寄存器的两个 D 通道。
运行结果:
2023-05-20 15:23:48.145 9806-9806/com.example.myapplication D/native-armv8a: in srcArr: 100 200 300 400
2023-05-20 15:23:48.145 9806-9806/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-20 15:23:48.145 9806-9806/com.example.myapplication D/native-armv8a: out outArr: 200 400 600 800
3 UADDW/UADDW2
无符号宽加,该指令将第一个源 SIMD&FP 寄存器的向量元素与第二个源 SIMD&FP 寄存器的下半部分或上半部分中相应的向量元素相加,将结果放入向量中,并将向量写入 SIMD&FP 目标寄存器。目标寄存器和第一个源寄存器的向量元素是第二个源寄存器的向量元素的两倍长。该指令中的所有值都是无符号整数值。
UADDW 指令从第二个源寄存器的下半部分提取向量元素。UADDW2 指令从第二个源寄存器的上半部分提取向量元素。

UADDW{2} <Vd>.<Ta>, <Vn>.<Ta>, <Vm>.<Tb>
2 是第二个和上半部分说明符。如果存在,它会导致对保存较窄元素的寄存器的高 64 位执行操作,并以“Q”编码:
| Q | 2 |
|---|---|
| 0 | [absent] |
| 1 | [present] |
<Vd> 是 SIMD&FP 目标寄存器的名称,在“Rd”字段中编码。
<Ta> 是排列说明符,以“size”编码:
| size | <Ta> |
|---|---|
| 00 | 8H |
| 01 | 4S |
| 10 | 2D |
| 11 | RESERVED |
<Vn> 是第一个 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<Vm> 是第二个 SIMD&FP 源寄存器的名称,在“Rm”字段中编码。
<Tb> 是排列说明符,编码为“size:Q”:
| size | Q | <T> |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | 2S |
| 10 | 1 | 4S |
| 11 | x | RESERVED |
下面是使用 UADDW/UADDW2 指令的例子。
auto *srcArr = new unsigned int[4];
auto *outArr = new unsigned long long int[4]{0};
for (int i = 0; i < 4; i++) {
srcArr[i] = 100 * (i + 1);
outArr[i] = 10 * (i + 1);
}
char *src = (char *) srcArr;
char *dst = (char *) outArr;
LOGD("in srcArr: %u %u %u %u", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
LOGD("in outArr: %llu %llu %llu %llu", outArr[0], outArr[1], outArr[2], outArr[3]);
asm volatile(
"LD1 {v0.4S}, [%[src]]\n"
"LD1 {v1.2D, v2.2D}, [%[dst]]\n"
"UADDW v3.2D, v1.2D, v0.2S\n"
"UADDW2 v4.2D, v2.2D, v0.4S\n"
"ST1 {v3.2D, v4.2D}, [%[dst]]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1", "v2", "v3", "v4");
LOGD("-----------------------------");
LOGD("out outArr: %llu %llu %llu %llu", outArr[0], outArr[1], outArr[2], outArr[3]);
delete[] srcArr;
delete[] outArr;
UADDW v3.2D, v1.2D, v0.2S 将 v0 寄存器低半部分两个 S 通道的值加上 v1 寄存器的两个 D 通道的值,并将结果写入 v3 寄存器的两个 D 通道。
UADDW2 v4.2D, v2.2D, v0.4S 将 v0 寄存器高半部分两个 S 通道的值加上 v2 寄存器的两个 D 通道的值,并将结果写入 v4 寄存器的两个 D 通道。

运行结果:
2023-05-20 15:56:42.446 1618-1618/com.example.myapplication D/native-armv8a: in srcArr: 100 200 300 400
2023-05-20 15:56:42.446 1618-1618/com.example.myapplication D/native-armv8a: in outArr: 10 20 30 40
2023-05-20 15:56:42.446 1618-1618/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-20 15:56:42.446 1618-1618/com.example.myapplication D/native-armv8a: out outArr: 110 220 330 440
4 UQADD
无符号饱和加法,该指令将两个源 SIMD&FP 寄存器的相应元素的值相加,将结果放入向量中,并将向量写入目标 SIMD&FP 寄存器。如果任何结果发生溢出,这些结果就会饱和。如果发生饱和,则设置累积饱和位 FPSR.QC。
标量

UQADD <V><d>, <V><n>, <V><m>
向量

UQADD <Vd>.<T>, <Vn>.<T>, <Vm>.<T>
<V> 是宽度说明符,以“size”编码:
| size | <V> |
|---|---|
| 00 | B |
| 01 | H |
| 10 | S |
| 11 | D |
<d> 是 SIMD&FP 目标寄存器的编号,在“Rd”字段中。
<n> 是第一个 SIMD&FP 源寄存器的编号,编码在“Rn”字段中。
<m> 是第二个 SIMD&FP 源寄存器的编号,编码在“Rm”字段中。
<Vd> 是 SIMD&FP 目标寄存器的名称,在“Rd”字段中编码。
<T> 是排列说明符,编码为“size:Q”:
| size | Q | <T> |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | 2S |
| 10 | 1 | 4S |
| 11 | 0 | RESERVED |
| 11 | 1 | 2D |
<Vn> 是第一个 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<Vm> 是第二个 SIMD&FP 源寄存器的名称,在“Rm”字段中编码。
下面是使用 UQADD 指令的例子。
auto *srcArr = new unsigned int[4];
auto *outArr = new unsigned int[4];
for (int i = 0; i < 4; i++) {
srcArr[i] = 0xFFFFFFFF;
outArr[i] = i;
}
char *src = (char *) srcArr;
char *dst = (char *) outArr;
LOGD("in srcArr: %u %u %u %u", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
LOGD("in outArr: %u %u %u %u", outArr[0], outArr[1], outArr[2], outArr[3]);
asm volatile(
"LD1 {v0.4S}, [%[src]]\n"
"LD1 {v1.4S}, [%[dst]]\n"
"UQADD v2.4S, v0.4S, v1.4S\n"
"ST1 {v2.4S}, [%[dst]]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1", "v2");
LOGD("-----------------------------");
LOGD("out outArr: %u %u %u %u", outArr[0], outArr[1], outArr[2], outArr[3]);
delete[] srcArr;
delete[] outArr;
运行过程中加入断点可查到 FPSR.QC 已经被置为 1(从低到高第 27 位(低位从 0 开始))。

运行结果:
2023-05-20 16:57:15.332 8522-8522/com.example.myapplication D/native-armv8a: in srcArr: 4294967295 4294967295 4294967295 4294967295
2023-05-20 16:57:15.332 8522-8522/com.example.myapplication D/native-armv8a: in outArr: 0 1 2 3
2023-05-20 16:57:15.332 8522-8522/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-20 16:57:15.332 8522-8522/com.example.myapplication D/native-armv8a: out outArr: 4294967295 4294967295 4294967295 4294967295
5 ADDHN/ADDHN2
Add returning High Narrow,该指令将第一个源 SIMD&FP 寄存器中的每个向量元素加上第二个源 SIMD&FP 寄存器中的相应向量元素,将结果的最高有效一半放入向量中,并将向量写入目标 SIMD&FP 寄存器的下半部分或上半部分。结果被截断,有关四舍五入的结果,可使用 RADDHN、RADDHN2。
ADDHN 指令将向量写入目标寄存器的下半部分并清除上半部分,而 ADDHN2 指令将向量写入目标寄存器的上半部分而不影响寄存器的其它位。

ADDHN{2} <Vd>.<Tb>, <Vn>.<Ta>, <Vm>.<Ta>
2 是第二个和上半部分说明符。如果存在,它会导致对保存较窄元素的寄存器的高 64 位执行操作,并以“Q”编码:
| Q | 2 |
|---|---|
| 0 | [absent] |
| 1 | [present] |
<Vd> 是 SIMD&FP 目标寄存器的名称,在“Rd”字段中编码。
<Ta> 是排列说明符,以“size”编码:
| size | <Ta> |
|---|---|
| 00 | 8H |
| 01 | 4S |
| 10 | 2D |
| 11 | RESERVED |
<Vn> 是第一个 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<Vm> 是第二个 SIMD&FP 源寄存器的名称,在“Rm”字段中编码。
<Tb> 是排列说明符,编码为“size:Q”:
| size | Q | <T> |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | 2S |
| 10 | 1 | 4S |
| 11 | x | RESERVED |
下面是使用 ADDHN/ADDHN2 指令的例子。
auto *srcArr = new unsigned long long int[4];
auto *outArr = new unsigned int[4]{0};
for (int i = 0; i < 4; i++) {
srcArr[i] = 0x10010000000 * (i + 1);
}
char *src = (char *) srcArr;
char *dst = (char *) outArr;
LOGD("in srcArr: 0x%llx 0x%llx 0x%llx 0x%llx", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
LOGD("in outArr: 0x%x 0x%x 0x%x 0x%x", outArr[0], outArr[1], outArr[2], outArr[3]);
asm volatile(
"LD1 {v0.2D, v1.2D}, [%[src]]\n"
"ADDHN v2.2S, v0.2D, v0.2D\n"
"ADDHN2 v2.4S, v1.2D, v1.2D\n"
"ST1 {v2.4S}, [%[dst]]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1", "v2");
LOGD("-----------------------------");
LOGD("out outArr: 0x%x 0x%x 0x%x 0x%x", outArr[0], outArr[1], outArr[2], outArr[3]);
delete[] srcArr;
delete[] outArr;
ADDHN v2.2S, v0.2D, v0.2D 将 v0 的两个 D 通道的值加上 v0 的两个 D 通道的值,接着取结果的高位(也就是 D 通道的高 S 通道部分)写入 v2 的两个低 S 通道,v2 寄存器高 S 通道全部清零。
ADDHN2 v2.4S, v1.2D, v1.2D 将 v1 的两个 D 通道的值加上 v1 的两个 D 通道的值,接着取结果的高位(也就是 D 通道的高 S 通道部分)写入 v2 的两个高 S 通道,并保持 v2 其它位不变。

运行结果:
2023-05-21 11:16:56.576 6664-6664/com.example.myapplication D/native-armv8a: in srcArr: 0x10010000000 0x20020000000 0x30030000000 0x40040000000
2023-05-21 11:16:56.576 6664-6664/com.example.myapplication D/native-armv8a: in outArr: 0x0 0x0 0x0 0x0
2023-05-21 11:16:56.576 6664-6664/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-21 11:16:56.576 6664-6664/com.example.myapplication D/native-armv8a: out outArr: 0x200 0x400 0x600 0x800
6 RADDHN/RADDHN2
和 ADDHN/ADDHN2 的唯一区别在于对结果进行了四舍五入,而非截断。
下面是使用 RADDHN/RADDHN2 指令的例子。使用 ADDHN/ADDHN2 的例子将命令替换为 RADDHN/RADDHN2 即可。
auto *srcArr = new unsigned long long int[4];
auto *outArr = new unsigned int[4]{0};
for (int i = 0; i < 4; i++) {
srcArr[i] = 0x10010000000 * (i + 1);
}
char *src = (char *) srcArr;
char *dst = (char *) outArr;
LOGD("in srcArr: 0x%llx 0x%llx 0x%llx 0x%llx", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
LOGD("in outArr: 0x%x 0x%x 0x%x 0x%x", outArr[0], outArr[1], outArr[2], outArr[3]);
asm volatile(
"LD1 {v0.2D, v1.2D}, [%[src]]\n"
"RADDHN v2.2S, v0.2D, v0.2D\n"
"RADDHN2 v2.4S, v1.2D, v1.2D\n"
"ST1 {v2.4S}, [%[dst]]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1", "v2");
LOGD("-----------------------------");
LOGD("out outArr: 0x%x 0x%x 0x%x 0x%x", outArr[0], outArr[1], outArr[2], outArr[3]);
delete[] srcArr;
delete[] outArr;
从运行结果来看,最后出现了 0x801 这个值,这是因为 0x40040000000 + 0x40040000000 = 0x80080000000,提取高 4 个字节的时候同时四舍五入进位了。
运行结果:
2023-05-21 11:11:08.096 20999-20999/com.example.myapplication D/native-armv8a: in srcArr: 0x10010000000 0x20020000000 0x30030000000 0x40040000000
2023-05-21 11:11:08.096 20999-20999/com.example.myapplication D/native-armv8a: in outArr: 0x0 0x0 0x0 0x0
2023-05-21 11:11:08.096 20999-20999/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-21 11:11:08.096 20999-20999/com.example.myapplication D/native-armv8a: out outArr: 0x200 0x400 0x600 0x801
7 UHADD
无符号半加,该指令将两个源 SIMD&FP 寄存器中相应的无符号整数值相加,将每个结果右移一位,将结果放入向量中,并将向量写入目标 SIMD&FP 寄存器。结果被截断。有关四舍五入的结果,请使用 URHADD。

UHADD <Vd>.<T>, <Vn>.<T>, <Vm>.<T>
<Vd> 是 SIMD&FP 目标寄存器的名称,在“Rd”字段中编码。
<T> 是排列说明符,编码在“size:Q”字段中。它可以具有以下值:
| size | Q | <T> |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | 2S |
| 10 | 1 | 4S |
| 11 | x | RESERVED |
<Vn> 是第一个 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<Vm> 是第二个 SIMD&FP 源寄存器的名称,在“Rm”字段中编码。
下面是使用 UHADD 指令的例子。
auto *srcArr = new unsigned int[4];
auto *outArr = new unsigned int[4];
for (int i = 0; i < 4; i++) {
srcArr[i] = 0x01020304 * (i + 1);
outArr[i] = 0x10203040 * (i + 1);
}
char *src = (char *) srcArr;
char *dst = (char *) outArr;
LOGD("in srcArr: 0x%x 0x%x 0x%x 0x%x", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
LOGD("in outArr: 0x%x 0x%x 0x%x 0x%x", outArr[0], outArr[1], outArr[2], outArr[3]);
asm volatile(
"LD1 {v0.4S}, [%[src]]\n"
"LD1 {v1.4S}, [%[dst]]\n"
"UHADD v2.4S, v0.4S, v1.4S\n"
"ST1 {v2.4S}, [%[dst]]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1", "v2");
LOGD("-----------------------------");
LOGD("out outArr: 0x%x 0x%x 0x%x 0x%x", outArr[0], outArr[1], outArr[2], outArr[3]);
delete[] srcArr;
delete[] outArr;
我们计算一组数值:0x1020304 + 0x10203040 = 0x11223344 = 0b00010001 00100010 00110011 01000100,右移一位后即 0b00001000 10010001 00011001 10100010 = 0x089119A2。
运行结果:
2023-05-21 14:59:44.900 13393-13393/com.example.myapplication D/native-armv8a: in srcArr: 0x1020304 0x2040608 0x306090c 0x4080c10
2023-05-21 14:59:44.900 13393-13393/com.example.myapplication D/native-armv8a: in outArr: 0x10203040 0x20406080 0x306090c0 0x4080c100
2023-05-21 14:59:44.900 13393-13393/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-21 14:59:44.900 13393-13393/com.example.myapplication D/native-armv8a: out outArr: 0x89119a2 0x11223344 0x19b34ce6 0x22446688
8 URHADD
和 UHADD 的唯一区别在于对结果进行了四舍五入,而非截断。
笔者实际没有琢磨出设计这条指令的意义,就比如说 S 通道相加,最大的无符号数是 0xFFFFFFFF,如果 0xFFFFFFFF + 0xFFFFFFFF,也就是两倍的 0xFFFFFFFF,对这个结果右移 1 位(相当于除以 2),还是 0xFFFFFFFF,根本就无法触及四舍五入的操作!
9 ADDP
标量
加一对元素,该指令将源 SIMD&FP 寄存器中的两个向量元素相加,并将结果写入目标 SIMD&FP 寄存器。

ADDP <V><d>, <Vn>.<T>
<V> 是宽度说明符,以“size”编码:
| size | <V> |
|---|---|
| 0x | RESERVED |
| 10 | RESERVED |
| 11 | D |
<d> 是 SIMD&FP 目标寄存器的编号,在“Rd”字段中。
<Vn> 是 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<T> 是排列说明符,编码为“size”:
| size | <V> |
|---|---|
| 0x | RESERVED |
| 10 | RESERVED |
| 11 | D |
向量
该指令通过将第一个源 SIMD&FP 寄存器的向量元素连接在第二个源 SIMD&FP 寄存器的向量元素之后创建一个向量,从连接的向量中读取每对相邻的向量元素,将每对值加在一起,将结果放入 向量,并将向量写入目标 SIMD&FP 寄存器。

ADDP <Vd>.<T>, <Vn>.<T>, <Vm>.<T>
<Vd> 是 SIMD&FP 目标寄存器的名称,在“Rd”字段中编码。
<T> 是排列说明符,编码为“size:Q”:
| size | Q | <T> |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | 2S |
| 10 | 1 | 4S |
| 11 | 0 | RESERVED |
| 11 | 1 | 2D |
<Vn> 是第一个 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<Vm> 是第二个 SIMD&FP 源寄存器的名称,在“Rm”字段中编码。
下面是使用 ADDP 指令的例子。
auto *srcArr = new unsigned int[4];
auto *outArr = new unsigned int[4];
for (int i = 0; i < 4; i++) {
srcArr[i] = i + 1;
outArr[i] = (i + 1) * 2;
}
char *src = (char *) srcArr;
char *dst = (char *) outArr;
LOGD("in srcArr: %u %u %u %u", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
LOGD("in outArr: %u %u %u %u", outArr[0], outArr[1], outArr[2], outArr[3]);
asm volatile(
"LD1 {v0.4S}, [%[src]]\n"
"LD1 {v1.4S}, [%[dst]]\n"
"ADDP v2.4S, v0.4S, v1.4S\n"
"ST1 {v2.4S}, [%[dst]]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1", "v2");
LOGD("-----------------------------");
LOGD("out outArr: %u %u %u %u", outArr[0], outArr[1], outArr[2], outArr[3]);
delete[] srcArr;
delete[] outArr;
ADDP v2.4S, v0.4S, v1.4S 将 v1 寄存器的 S 通道连接到 v0 寄存器之后形成一个新的向量,从这个新的向量中按对加,最后将结果写入 v2 的 S 通道。
运行结果:
2023-05-21 16:16:33.270 11613-11613/com.example.myapplication D/native-armv8a: in srcArr: 1 2 3 4
2023-05-21 16:16:33.270 11613-11613/com.example.myapplication D/native-armv8a: in outArr: 2 4 6 8
2023-05-21 16:16:33.270 11613-11613/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-21 16:16:33.270 11613-11613/com.example.myapplication D/native-armv8a: out outArr: 3 7 6 14
10 UADDLP
Unsigned Add Long Pairwise,该指令将源 SIMD&FP 寄存器中向量中的相邻无符号整数值对相加,将结果放入向量中,并将向量写入目标 SIMD&FP 寄存器。目标向量元素的长度是源向量元素的两倍。

UADDLP <Vd>.<Ta>, <Vn>.<Tb>
<Vd> 是 SIMD&FP 目标寄存器的名称,在“Rd”字段中编码。
<Ta> 是排列说明符,编码在“size:Q”字段中。 它可以具有以下值:
| size | Q | <Ta> |
|---|---|---|
| 00 | 0 | 4H |
| 00 | 1 | 8H |
| 01 | 0 | 2S |
| 01 | 1 | 4S |
| 10 | 0 | 1D |
| 10 | 1 | 2D |
| 11 | x | RESERVED |
<Vn> 是 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<Tb> 是排列说明符,编码在“size:Q”字段中。 它可以具有以下值:
| size | Q | <Tb> |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | 2S |
| 10 | 1 | 4S |
| 11 | x | RESERVED |
下面是使用 UADDLP 指令的例子。
auto *srcArr = new unsigned int[4];
auto *outArr = new unsigned long long int[2]{0};
for (int i = 0; i < 4; i++) {
srcArr[i] = i + 1;
}
char *src = (char *) srcArr;
char *dst = (char *) outArr;
LOGD("in srcArr: %u %u %u %u", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
LOGD("in outArr: %llu %llu", outArr[0], outArr[1]);
asm volatile(
"LD1 {v0.4S}, [%[src]]\n"
"UADDLP v1.2D, v0.4S\n"
"ST1 {v1.2D}, [%[dst]]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1");
LOGD("-----------------------------");
LOGD("out outArr: %llu %llu", outArr[0], outArr[1]);
delete[] srcArr;
delete[] outArr;
UADDLP v1.2D, v0.4S 将 v0 寄存器的 S 通道按对加,最后将结果写入 v1 的两个 D 通道。
运行结果:
2023-05-21 16:34:07.706 1951-1951/com.example.myapplication D/native-armv8a: in srcArr: 1 2 3 4
2023-05-21 16:34:07.706 1951-1951/com.example.myapplication D/native-armv8a: in outArr: 0 0
2023-05-21 16:34:07.706 1951-1951/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-21 16:34:07.706 1951-1951/com.example.myapplication D/native-armv8a: out outArr: 3 7
11 UADALP
Unsigned Add and Accumulate Long Pairwise,该指令将源 SIMD&FP 寄存器中向量中的相邻无符号整数值对相加,并将结果与目标 SIMD&FP 寄存器的向量元素累加。目标向量元素的长度是源向量元素的两倍。

UADALP <Vd>.<Ta>, <Vn>.<Tb>
<Vd> 是 SIMD&FP 目标寄存器的名称,在“Rd”字段中编码。
<Ta> 是排列说明符,编码在“size:Q”字段中。 它可以具有以下值:
| size | Q | <Ta> |
|---|---|---|
| 00 | 0 | 4H |
| 00 | 1 | 8H |
| 01 | 0 | 2S |
| 01 | 1 | 4S |
| 10 | 0 | 1D |
| 10 | 1 | 2D |
| 11 | x | RESERVED |
<Vn> 是 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<Tb> 是排列说明符,编码在“size:Q”字段中。 它可以具有以下值:
| size | Q | <Tb> |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | 2S |
| 10 | 1 | 4S |
| 11 | x | RESERVED |
下面是使用 UADALP 指令的例子。
auto *srcArr = new unsigned int[4];
auto *outArr = new unsigned long long int[2]{0};
for (int i = 0; i < 4; i++) {
srcArr[i] = i + 1;
}
outArr[0] = 1;
outArr[1] = 2;
char *src = (char *) srcArr;
char *dst = (char *) outArr;
LOGD("in srcArr: %u %u %u %u", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
LOGD("in outArr: %llu %llu", outArr[0], outArr[1]);
asm volatile(
"LD1 {v0.4S}, [%[src]]\n"
"LD1 {v1.2D}, [%[dst]]\n"
"UADALP v1.2D, v0.4S\n"
"ST1 {v1.2D}, [%[dst]]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1");
LOGD("-----------------------------");
LOGD("out outArr: %llu %llu", outArr[0], outArr[1]);
delete[] srcArr;
delete[] outArr;
UADALP v1.2D, v0.4S 将 v0 寄存器的 S 通道按对加,得到按对加的结果后,将其分别累加到 v1 的两个 D 通道。
运行结果:
2023-05-21 16:45:00.687 4754-4754/com.example.myapplication D/native-armv8a: in srcArr: 1 2 3 4
2023-05-21 16:45:00.687 4754-4754/com.example.myapplication D/native-armv8a: in outArr: 1 2
2023-05-21 16:45:00.687 4754-4754/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-21 16:45:00.687 4754-4754/com.example.myapplication D/native-armv8a: out outArr: 4 9
12 ADDV
Add across Vector,该指令将源 SIMD&FP 寄存器中的每个向量元素相加,并将标量结果写入目标 SIMD&FP 寄存器。

ADDV <V><d>, <Vn>.<T>
<V> 是目标宽度说明符,在“size”字段中编码。它可以具有以下值:
| V | size |
|---|---|
| B | 00 |
| H | 01 |
| S | 10 |
| RESERVED | 11 |
<d> 是 SIMD&FP 目标寄存器的编号,在“Rd”字段中编码。
<Vn> 是 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<T> 是排列说明符,编码在“size:Q”字段中。 它可以具有以下值:
| size | Q | T |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | RESERVED |
| 10 | 1 | 4S |
| 11 | x | RESERVED |
下面是使用 ADDV 指令的例子。
auto *srcArr = new unsigned int[4];
unsigned int dst = 0;
for (int i = 0; i < 4; i++) {
srcArr[i] = i + 1;
}
char *src = (char *) srcArr;
LOGD("in srcArr: %u %u %u %u", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
LOGD("in dst: %u", dst);
asm volatile(
"LD1 {v0.4S}, [%[src]]\n"
"ADDV S1, v0.4S\n"
"MOV %w[dst], v1.S[0]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1");
LOGD("-----------------------------");
LOGD("out dst: %u", dst);
delete[] srcArr;
ADDV S1, v0.4S 将 v0 寄存器的 S 通道值全部相加,并将得到的结果写入 S1 寄存器。
运行结果:
2023-05-21 16:59:39.237 18281-18281/com.example.myapplication D/native-armv8a: in srcArr: 1 2 3 4
2023-05-21 16:59:39.237 18281-18281/com.example.myapplication D/native-armv8a: in dst: 0
2023-05-21 16:59:39.237 18281-18281/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-21 16:59:39.237 18281-18281/com.example.myapplication D/native-armv8a: out dst: 10
13 UADDLV
Unsigned sum Long across Vector,该指令将源 SIMD&FP 寄存器中的每个向量元素相加,并将标量结果写入目标 SIMD&FP 寄存器。目标标量是源向量元素的两倍长。该指令中的所有值都是无符号整数值。

UADDLV <V><d>, <Vn>.<T>
<V> 是目标宽度说明符,在“size”字段中编码。它可以具有以下值:
| V | size |
|---|---|
| H | 00 |
| S | 01 |
| D | 10 |
| RESERVED | 11 |
<d> 是 SIMD&FP 目标寄存器的编号,在“Rd”字段中编码。
<Vn> 是 SIMD&FP 源寄存器的名称,在“Rn”字段中编码。
<T> 是排列说明符,编码在“size:Q”字段中。 它可以具有以下值:
| size | Q | T |
|---|---|---|
| 00 | 0 | 8B |
| 00 | 1 | 16B |
| 01 | 0 | 4H |
| 01 | 1 | 8H |
| 10 | 0 | RESERVED |
| 10 | 1 | 4S |
| 11 | x | RESERVED |
下面是使用 UADDLV 指令的例子。
auto *srcArr = new unsigned int[4];
unsigned long long int dst = 0;
for (int i = 0; i < 4; i++) {
srcArr[i] = i + 1;
}
char *src = (char *) srcArr;
LOGD("in srcArr: %u %u %u %u", srcArr[0], srcArr[1], srcArr[2], srcArr[3]);
LOGD("in dst: %llu", dst);
asm volatile(
"LD1 {v0.4S}, [%[src]]\n"
"UADDLV D1, v0.4S\n"
"MOV %[dst], v1.D[0]\n"
:[src] "+r"(src),
[dst] "+r"(dst)
:
: "cc", "memory", "v0", "v1");
LOGD("-----------------------------");
LOGD("out dst: %llu", dst);
delete[] srcArr;
UADDLV D1, v0.4S 将 v0 寄存器的 S 通道值全部相加,并将得到的结果写入 D1 寄存器。
运行结果:
2023-05-21 17:06:17.782 6272-6272/com.example.myapplication D/native-armv8a: in srcArr: 1 2 3 4
2023-05-21 17:06:17.782 6272-6272/com.example.myapplication D/native-armv8a: in dst: 0
2023-05-21 17:06:17.782 6272-6272/com.example.myapplication D/native-armv8a: -----------------------------
2023-05-21 17:06:17.782 6272-6272/com.example.myapplication D/native-armv8a: out dst: 10
14 其它
上面很多加法指令都是基于无符号数的,实际上它们也有对应的有符号数版本,就不再一一展开了。
参考资料
1.《ARMv8-A-Programmer-Guide》
2.《Arm® A64 Instruction Set Architecture Armv8, for Armv8-A architecture profile》



![[自学记录02|百人计划]纹理压缩](https://img-blog.csdnimg.cn/35bfd91a53174d70a1e96e2ec6c15981.png)