#CSDN AI写作助手创作测评
目录
ID3算法
1.算法原理
2.代码实现
3.ID3算法的优缺点分析
C4.5算法
1.原理
2.优缺点
心得感受
决策树表示方法是应用最广泛的逻辑方法之一,它从一组无次序、无规则的事例中推理出决策树表示形式的分类规则。在决策树的内部节点进行属性值的比较,根据不同的属性值判断从该节点向下的分支,在决策树的叶节点得到结论
决策树分类算法的主要优点包括易于理解和解释、对缺失值不敏感、能处理不相关特征等。它的主要缺点是容易过拟合、对噪声敏感、不稳定等问题。
在实践中,决策树分类算法可以使用不同的算法实现,如ID3、C4.5和CART等。这些算法的主要区别在于如何选择属性、如何处理连续值属性和如何处理缺失值等方面。
ID3算法
1.算法原理
ID3算法是一种决策树学习算法,通过对数据集进行递归分割来构建决策树。它基于信息增益选择最佳属性进行分裂。下面是ID3算法的基本原理:
- 1. 选择最佳分裂属性:对于数据集中的每个属性,计算它们对数据集的信息增益(或信息增益比),选择信息增益最大(或信息增益比最大)的属性作为该节点的分裂属性。
- 2. 将节点分裂成子节点:用分裂属性将数据集分成几个子集,每个子集对应一个子节点。
- 3. 递归处理子节点:对每个子节点递归进行操作,直到所有叶子节点都是同一类别或无法继续分裂。
- 4. 剪枝:使用预留的测试数据集来剪枝以防止过拟合。
- 5. 生成决策树:所有子节点的递归处理完成后,生成一棵决策树。
ID3算法的缺点是对于具有连续属性和缺失值的数据集处理能力较差。因此,它常与C4.5和CART算法结合使用,用于改进这些限制。
2.代码实现
import math
def entropy(data):
"""计算数据集的熵"""
count = {}
for item in data:
if item[-1] not in count:
count[item[-1]] = 0
count[item[-1]] += 1
entropy = 0
for key in count:
prob = count[key] / len(data)
entropy -= prob * math.log2(prob)
return entropy
def split_data(data, feature, value):
"""根据特征和特征值划分数据集"""
sub_data = []
for item in data:
if item[feature] == value:
sub_item = item[:feature]
sub_item.extend(item[feature+1:])
sub_data.append(sub_item)
return sub_data
def info_gain(data, feature):
"""计算特征的信息增益"""
count = {}
for item in data:
if item[feature] not in count:
count[item[feature]] = 0
count[item[feature]] += 1
sub_entropy = 0
for key in count:
prob = count[key] / sum(count.values())
sub_data = split_data(data, feature, key)
sub_entropy += prob * entropy(sub_data)
return entropy(data) - sub_entropy
def choose_feature(data):
"""选择最优特征"""
max_gain = 0
best_feature = -1
for i in range(len(data[0])-1):
gain = info_gain(data, i)
if gain > max_gain:
max_gain = gain
best_feature = i
return best_feature
def majority_vote(class_list):
"""多数表决"""
count = {}
for item in class_list:
if item not in count:
count[item] = 0
count[item] += 1
return max(count, key=count.get)
def create_tree(data, labels):
"""创建决策树"""
class_list = [item[-1] for item in data]
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
if len(data[0]) == 1:
return majority_vote(class_list)
best_feature = choose_feature(data)
best_label = labels[best_feature]
tree = {best_label: {}}
del(labels[best_feature])
count = {}
for item in data:
if item[best_feature] not in count:
count[item[best_feature]] = 0
count[item[best_feature]] += 1
for key in count:
sub_labels = labels[:]
sub_data = split_data(data, best_feature, key)
tree[best_label][key] = create_tree(sub_data, sub_labels)
return tree
# 测试数据
data = [
[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no'],
]
labels = ['no surfacing', 'flippers']
# 构建决策树
tree = create_tree(data, labels)
# 输出熵和信息增益
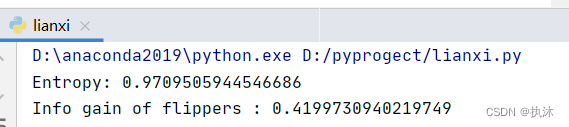
print('Entropy:', entropy(data))
for i in range(len(labels)):
print('Info gain of', labels[i], ':', info_gain(data, i))
3.ID3算法的优缺点分析
ID3算法是一种决策树学习算法,其优缺点如下:
优点:
- 1. 算法简单易懂,不需要复杂的数学知识。
- 2. 生成的决策树易于理解和解释,可以很好地反映属性之间的关系。
- 3. 在处理大型数据集时,算法的效率较高。
- 4. 可以处理缺失值。
缺点:
- 1. ID3算法容易过拟合,很容易出现训练集上表现很好,但是在测试集上表现很差的情况。
- 2. ID3算法只能处理离散型数据,对于连续型数据需要先进行离散化处理。
- 3. 对于分类类别较多的数据集,生成的决策树不易读懂且容易过于复杂。
- 4. ID3算法只考虑当前数据集中的最优特征,可能会错过更好的特征组合。这种算法也称为"贪心算法"。
- 5. 对于噪声较大或者数据比较杂乱的数据集,决策树有些难以生成。
C4.5算法
1.原理
C4.5算法是一种决策树算法,用于解决分类问题。它的主要原理是通过对数据集进行划分来构建一棵决策树,每次选择最优特征进行划分,直到所有数据都被正确分类或者没有更多的特征可用。
C4.5算法的具体步骤如下:
- 1. 读入训练数据集,对每个特征计算出其信息增益比。信息增益比是指使用该特征进行划分所得到的信息增益与该特征对应的数据集的经验熵之比。
- 2. 选择信息增益比最大的特征作为当前节点的划分特征,将该节点对应的数据集划分成若干个子集。
- 3. 对每个子集递归执行步骤1和2,直到满足终止条件。
- 4. 终止条件可以是所有数据都被正确分类,或者没有更多的特征可用进行划分。此时,将该节点标记为叶子节点,并将该节点的分类设定为子集中出现次数最多的分类。
- 5. 对新的数据进行分类时,从根节点开始,根据特征的取值依次按照决策树的分支进行遍历,直到到达叶子节点,将叶子节点的分类作为最终结果。
C4.5算法在构建决策树的过程中,还采用了剪枝操作来避免过拟合,同时能够处理连续特征和缺失值。它是ID3算法的改进,相对于ID3算法而言,C4.5算法可以处理更复杂的数据集。
2.优缺点
C4.5算法是一种决策树分类算法,其优缺点如下:
优点:
- 1. 可以处理具有连续值属性的数据集,而不需要对数据进行离散化处理。
- 2. 能够自动剪枝,避免过度拟合的问题。
- 3. 具有良好的可读性和可解释性,生成的决策树可以直观地表示数据集的结构和规律。
- 4. 在实际应用中具有较高的准确性和鲁棒性。
缺点:
- 1. 对于具有大量特征或特征空间较大的数据集,算法的时间复杂度很高,需要消耗大量的计算资源。
- 2. 由于C4.5算法是基于贪心策略构建决策树的,可能会导致决策树的局部最优解与全局最优解不一致,从而影响分类准确性。
- 3. 对于存在分类不平衡问题的数据集,可能会导致决策树生成过程中的类别偏差,从而影响分类准确性。
心得感受
CSDN的AI写作相当牛了,并且操作方便;
回答速度也是相当可观的,就是总会一卡一卡的,不过无伤大雅;
写代码的能力,我也是很认可的,比我强多了;
就我而言,平时想要需求人工智能的帮助的话,用这个创作助手就完全够用了;
就目前而言,大多数的语言模型的回答模式都差不多,类似于一个模板;
如果与chatgpt3.5相比的话,我还真比不出来,感觉差不多。