说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。
1.项目背景
基于用户的协同过滤推荐(User-based CF)的原理假设:跟你喜好相似的人喜欢的东西你也很有可能喜欢。先找到相似的用户,再找到他们喜欢的物品,基于用户的协同过滤通过用户的历史行为数据,发现用户喜欢的物品,并对这些偏好进行打分和度量,然后根据不同的用户对物品的评分或者偏好程度来评测用户之间的相似性,对有相同偏好的用户进行物品推荐。
本项目应用用户的协同过滤推荐算法进行相似度计算、给用户推荐及模型评估。
2.数据获取
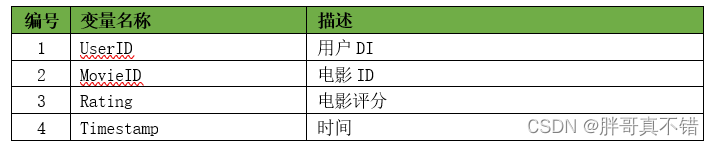
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
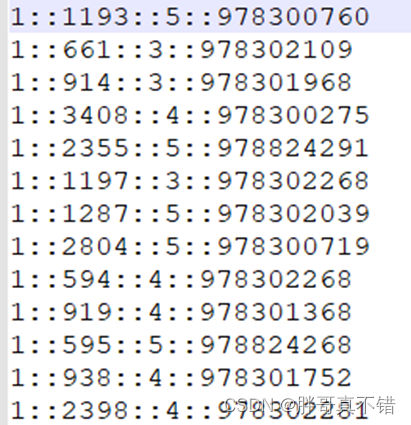
数据详情如下(部分展示):
数据解释:例如 1::1193::5::978300760
该条记录队列的列是 UserID::MovieID::Rating::Timestamp,表示id为1的用户在978300760时对1193电影评分为5。
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:
3.2 数据缺失查看
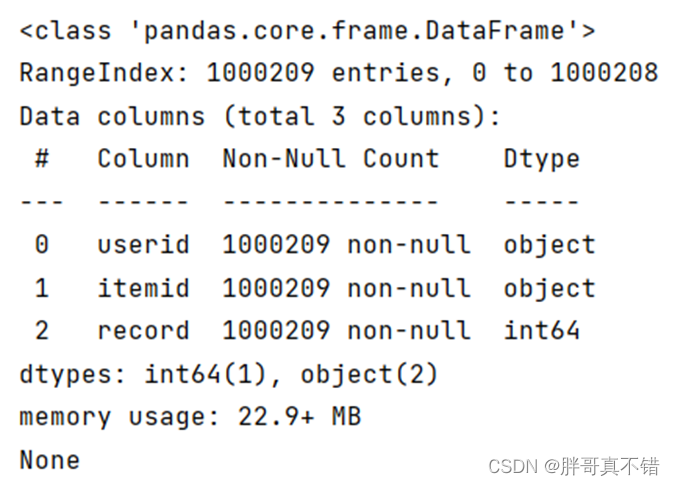
使用Pandas工具的info()方法查看数据信息:
从上图可以看到,总共有3个变量,数据中无缺失值,共1000209条数据。
关键代码:
4.探索性数据分析
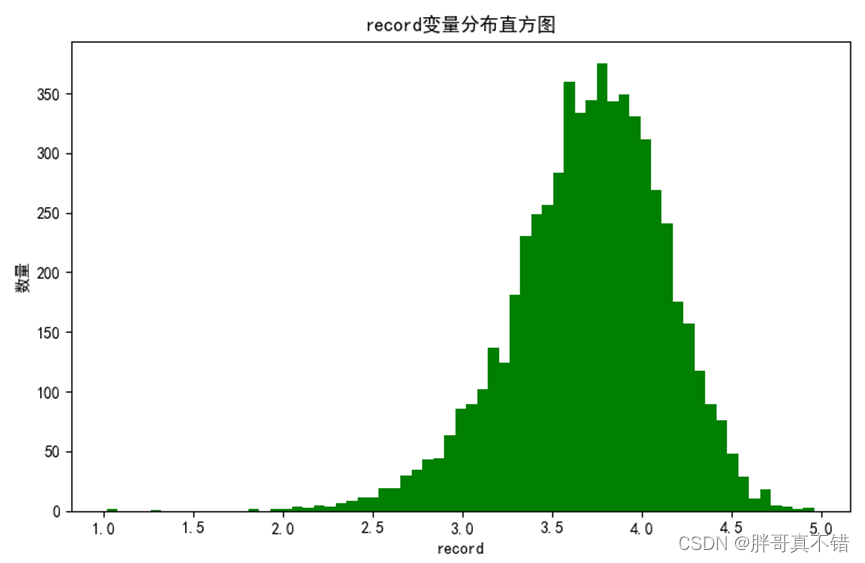
4.1 评分变量直方图
用Matplotlib工具的hist()方法绘制直方图:
从上图可以看到,评分平均记录主要集中在3.0~4.5之间。
5.特征工程
5.1 数据集拆分
通过splitData()方法进行数据集拆分,关键代码如下:
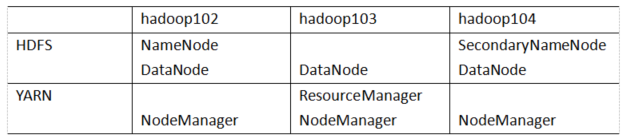
6.构建电影推荐系统
主要使用基于用户的协同过滤推荐算法构建电影推荐系统。
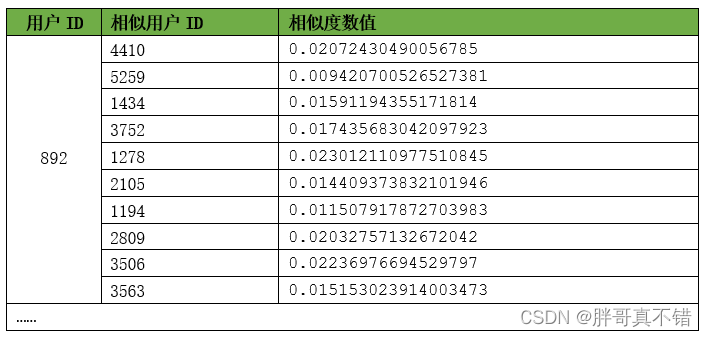
6.1 相似度计算
关键代码:
相似度计算结果展示:
6.2 对用户进行推荐
对用户1进行推荐,推荐结果如下:
通过上表可以看出,是按照推荐值的大小从高到低进行排序的。
7.模型评估
7.1 评估指标及结果
评估指标主要包括准确率。
从上表可以看出,准确率为23%,作为一个推荐系统,在数据量有限的情况下,此效果良好。
关键代码如下:
8.结论与展望
综上所述,本项目采用了基于用户的协同过滤推荐算法来构建电影推荐系统,主要包括数据集的读取、拆分、探索性数据分析、相似度计算、对用户进行推荐、模型的评估等,最终证明了我们提出的模型效果较好。








本次机器学习项目实战所需的资料,项目资源如下:
项目说明:
链接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取码:bcbp


![[Error]适配iPad时调用UIAlertController和UIActivityViewController软件崩溃问题](https://img-blog.csdnimg.cn/6c75a67b821146848597ddade2e6acc5.png)