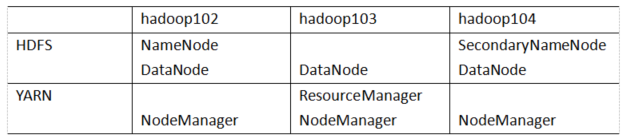
1. hadoop集群规划
1.准备3台客户机(关闭防火墙,静态ip,主机名称)
2.安装jdk
3.配置环境变量
4.安装hadoop,hadoop版本是3.1.3,包名为hadoop-3.1.3.tar.gz
5.配置环境变量
6.配置集群
7.单点启动
8.配置ssh
9.群起集群并测试集群
注意: NameNode和SecondaryNameNode和ResourceManage三者很消耗内存,不要安装在同一台服务器上
2. hadoop具体安装步骤
2.0 端口号说明
namenode端口号说明
| namenode | 版本号 | 端口号 |
|---|---|---|
| 1.x | 8020 | |
| 2.x | 9000 | |
| 3.0.x | 9020 | |
| 3.1.x | 8020 |
namenode web端口号说明
| namenode web端口号 | 版本号 | 端口号 |
|---|---|---|
| 1.x 2.x | 50070 | |
| 3.x | 9870 |
secondarynamenode web端口号说明
| secondarynamenode web端口号 | 版本号 | 端口号 |
|---|---|---|
| 1.x 2.x | 50090 | |
| 3.x | 9868 |
2.1 上传
2.2 解压
2.3 修改hadoop相关配置文件
有core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml,works
(1)core-site.xml修改的内容有:
①NameNode的内部连接地址;
②hadoop数据存储的目录,默认是linux临时目录,到日期会被清除掉;
③配置hdfs登录的静态用户moxi,(好处是当使用的是moxi用户启动的hadoop,有权限进行删除);
④配置moxi为代理用户(因为在使用hive的时候,每一个用户都会创建一个hiveserver2,这个客户端非常占用空间,就想着所有用户用同一个hiveserver2,提交作业,如果不配置不可以,配置了就能用。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为moxi -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>moxi</value>
</property>
<!-- 配置该moxi(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该moxi(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.moxi.groups</name>
<value>*</value>
</property>
<!-- 配置该moxi(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.moxi.users</name>
<value>*</value>
</property>
</configuration>
(2)hdfs-site.xml修改的内容有:
①配置nn web端访问的地址,配置为hadoop102:9870
②配置2nn web端访问地址,配置为hadoop104:9868
③配置hdfs副本的数量,一般指定为3个,测试集群一般是1个
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
<!-- 环境指定HDFS副本的数量3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
(3)yarn-site.xml修改的内容有:
①指定MR走shuffle
②指定ResourceManager的地址:在hadoop103
③环境变量的继承
④yarn单个容器允许分配的最大最小内存,(默认是8G,需要修改,限定为和服务器一样大),这个参数每个机器单独设置,(内存为8,4,4和6,3,3需要修改,最大内存和服务器分配的最大内存一样,否则,内存超出会崩)
⑤yarn容器允许管理的物理内存大小,这个参数每个机器单独设置
⑥关闭yarn对虚拟内存的限制,物理内存不能关闭。(默认都是true,检测nodemanager和其它组件内存使用情况,超过内存大小就阻止它使用,把他干掉,很危险,需要关闭;虚拟内存,就是把超出内存的空间运行在磁盘上)
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--yarn单个容器允许分配的最大最小内存,最大内存不超过虚拟机分配的内存-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小,最大内存不超过虚拟机分配的内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
(4)mapred-site.xml修改的内容有:
①指定mapreduce程序在yarn上运行
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)配置集群works:
在1.x和2.x名字叫slaves,不叫works。
把默认的localhost删掉,注意:填写下面的hadoop102,hadoop103,hadoop104,需要提前做好主机名和ip地址的映射;下面的文件不能有空格例如在hadoop102后面不能有空格;也不能有空行,在hadoop104下面不能有空行
hadoop102
hadoop103
hadoop104
2.4 配置历史服务器
为什么要配置历史服务器?
任务在运行过程中,会记录运行过程的日志,不配置,运行结束了就结束了。
在hadoop-3.1.3/etc/hadoop/mapred-site.xml文件下配置
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
2.5 配置日志聚集功能
作用:不配置,查看日志需要在各自台上查询各自的,这是很麻烦的一件事,如果配置过之后,就可以在一台设备上,查看所有设备的日志,这是很方便的
在 yarn-site.xml上配置。
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2.6 分发hadoop到其它集群
[moxi@hadoop102 hadoop-3.1.3]$ xsync /opt/module/hadoop-3.1.3/
2.7 配置hadoop环境变量
[moxi@hadoop102 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
2.8 分发环境变量
注意:在root下,需要把分发指令路径写完整。
[moxi@hadoop102 hadoop-3.1.3]$ sudo /home/moxi/bin/xsync /etc/profile.d/my_env.sh
2.9 source 是之生效
[moxi@hadoop102 module]$ source /etc/profile.d/my_env.sh
[moxi@hadoop103 module]$ source /etc/profile.d/my_env.sh
[moxi@hadoop104 module]$ source /etc/profile.d/my_env.sh
2.10 第一次启动需要格式化namenode
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[moxi@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode -format
2.11 单节点启动集群
(1)启动HDFS
[moxi@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
(2)在配置了ResourceManager的节点(一定要在hadoop103上启动,因为在103上配置的)启动YARN
[moxi@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
2.12 在web端查看页面
①Web端查看HDFS的Web页面:http://hadoop102:9870/
②Web端查看yarn的web页面:http://hadoop103:8088/
2.13 hadoop群起集群配置
在一台设备上启动所有进程。
进入目录/home/moxi/bin
编辑文件vim hdp.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
给权限
chmod 777 hdp.sh
使用指南:
hdp.sh start
安装包链接:
链接:https://pan.baidu.com/s/1NUBmKLx6K71H95OZwOweag?pwd=kpv1
提取码:kpv1