- 飞桨
- 官网介绍
- 使用流程
- paddle —— 飞桨的深度学习核心框架
- 本地 padddlepaddle 的安装和卸载
- 安装
- 查看当前安装的版本
- 卸载
- 启动 GPU 训练
- 指定 GPU
- 飞桨创建项目
- PaddlePaddle 2.1.2 下的对比
- 修改为 paddlepaddle2.4.0
- CUDA
飞桨
飞桨官网:https://www.paddlepaddle.org.cn/
官网介绍
今天的机器越来越“聪明”,正是源于 深度学习 的出现,作为最有影响的人工智能关键共性技术,其在 图像分类、语音识别 等方面展现出了强大实力。
这么神奇的功能,实现 起来一定很复杂吧?
的确如此!只不过…
现在可以借助 开源深度学习平台 的能力去解决啦!
- 开发者在开源深度学习平台上面,像搭积木一样构建自己的 AI 应用,极大地降低了研发门槛,提升了效率。
- 飞桨是 百度研发 的一款 技术领先,功能完备的产业级 深度学习 开源 开放平台。
- 它 集深度学习核心框架、基础模型库、端到端开发套件、工具组件和服务平台为一体,助力产业智能化,致力于让深度学习的创新与应用更简单。
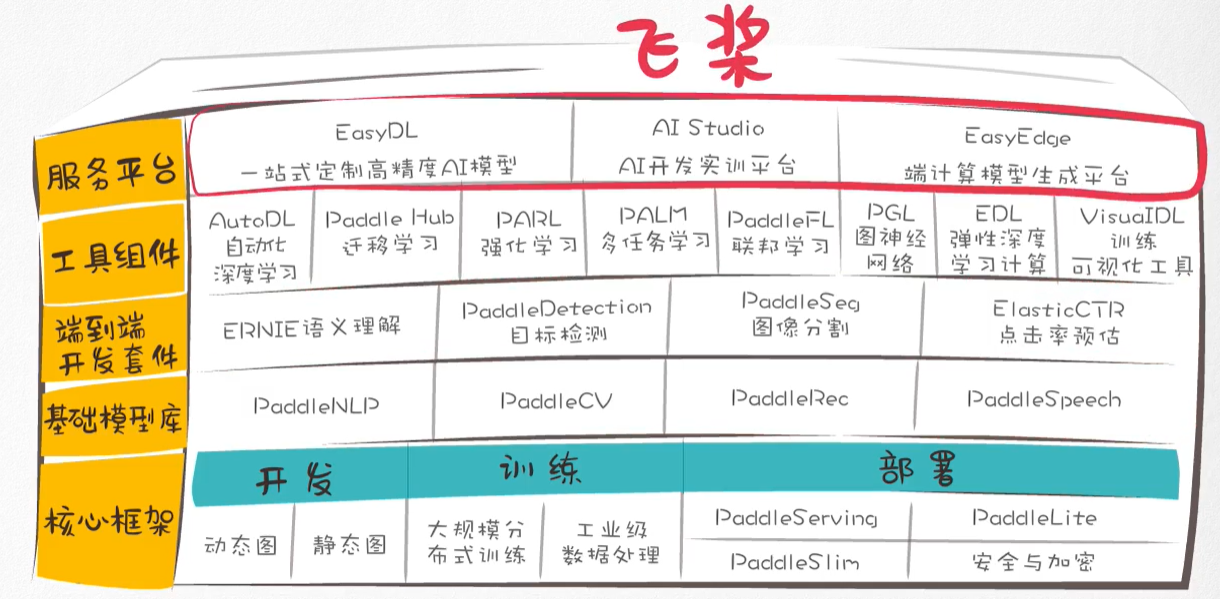
- 这些都基于飞桨的四大领先技术:
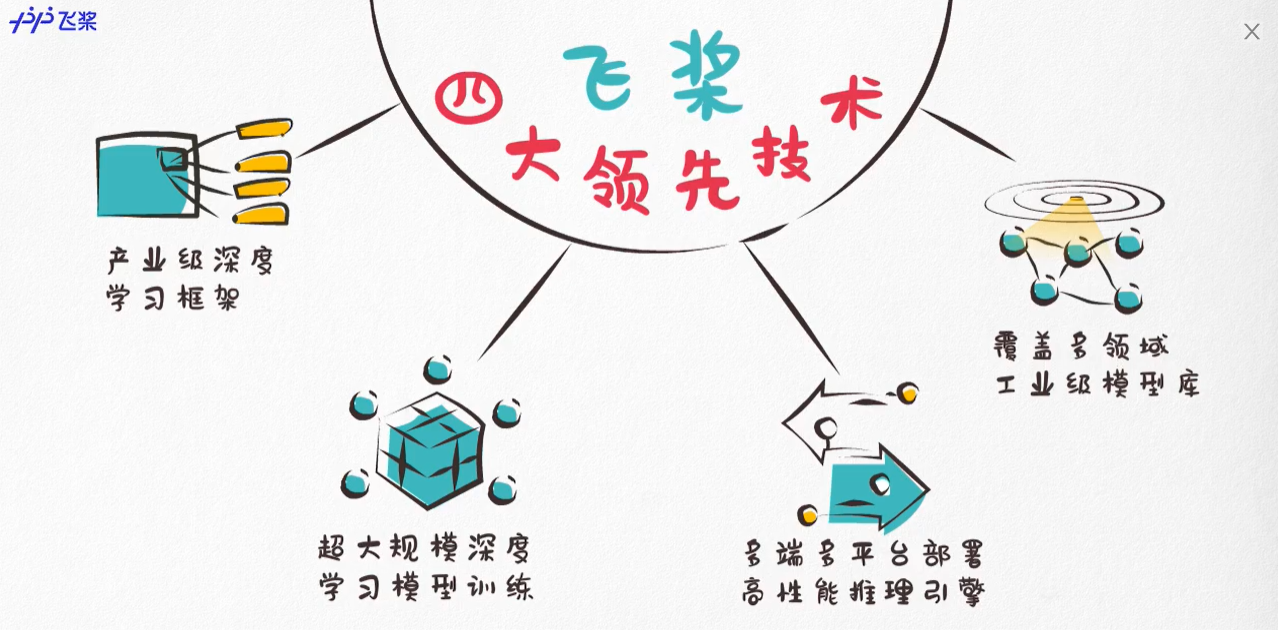
- 飞桨助力开发者快速实现 AI 想法,快速上线 AI 业务。帮助越来越多的行业 完成 AI 赋能,实现产业智能化升级。
- 随着飞桨 赋能行业 进程的加快,小到智能桃子分拣机、零件质检,大到城市规划、病虫害监视、无人驾驶、预防性医疗保健等,
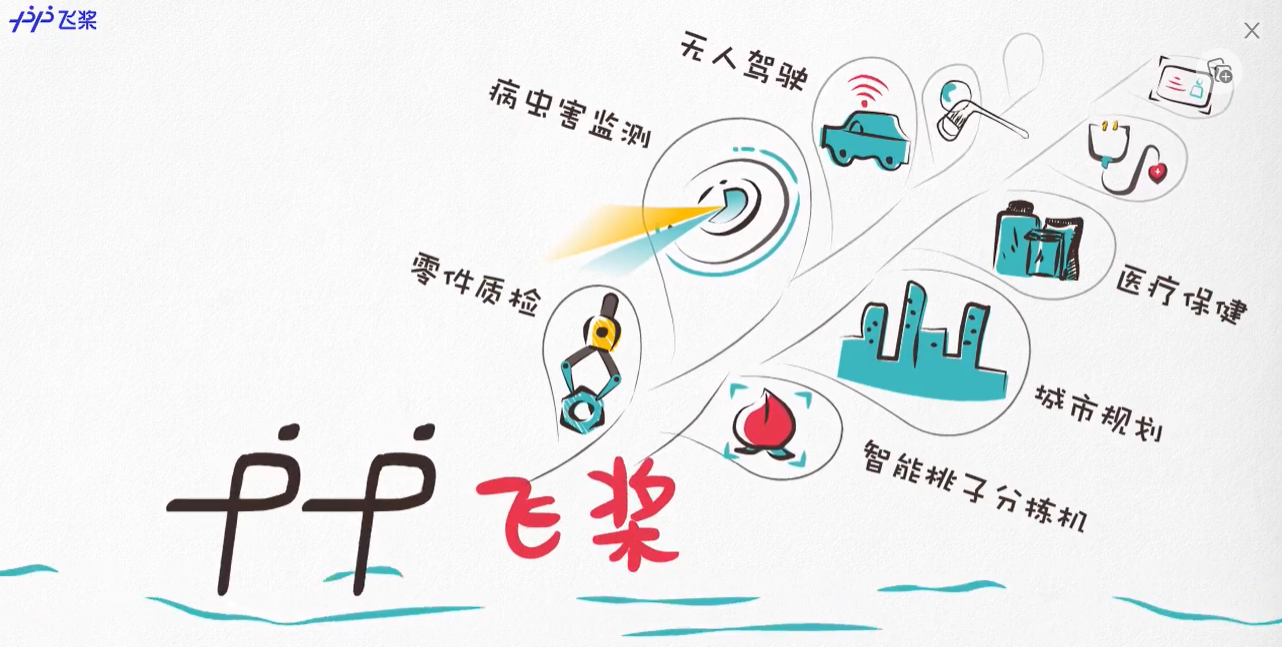
- 飞桨已在工业、农业、服务业、零售、通讯、地产、医疗、互联网等众多行业中实现落地应用。

使用流程
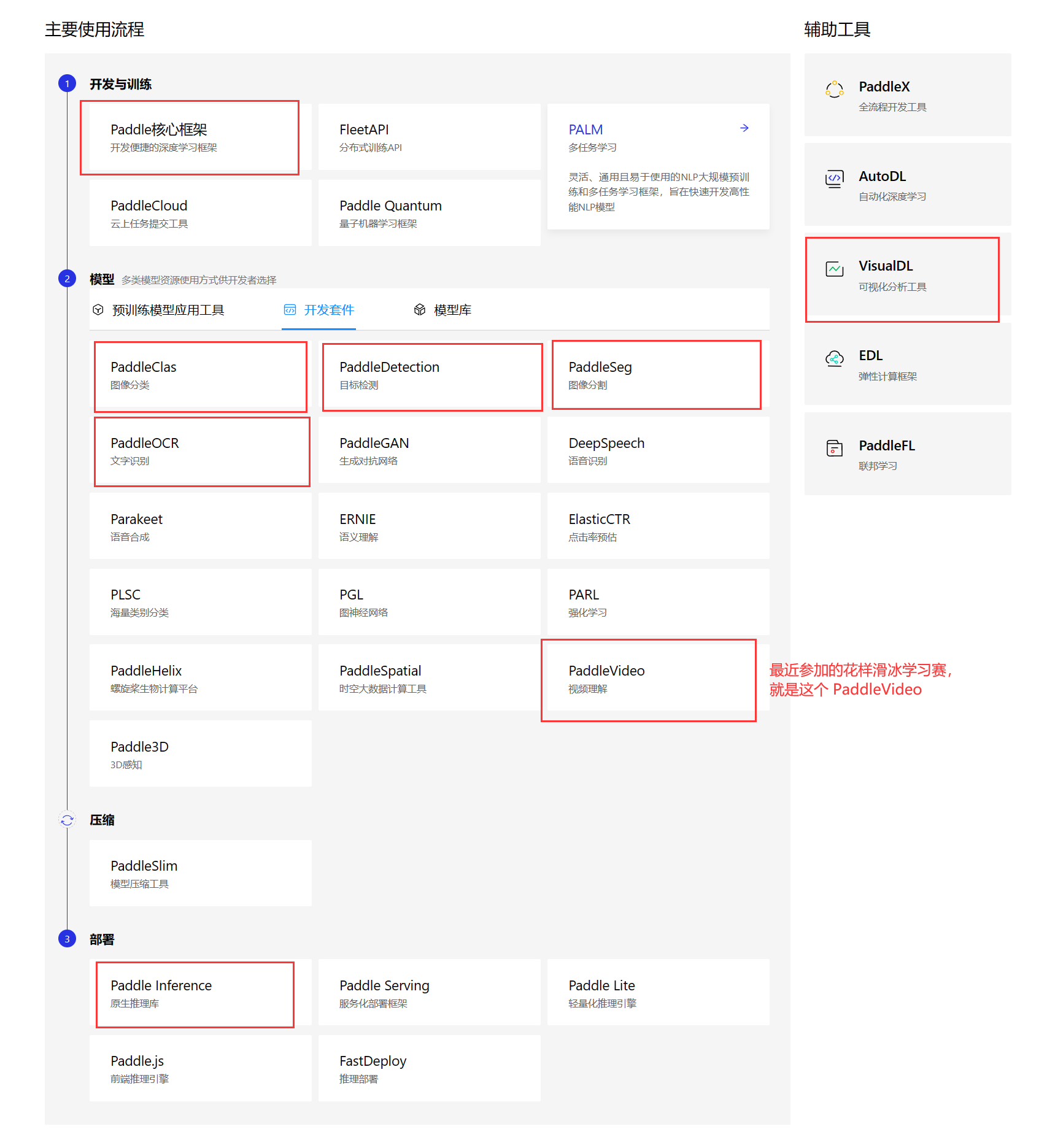
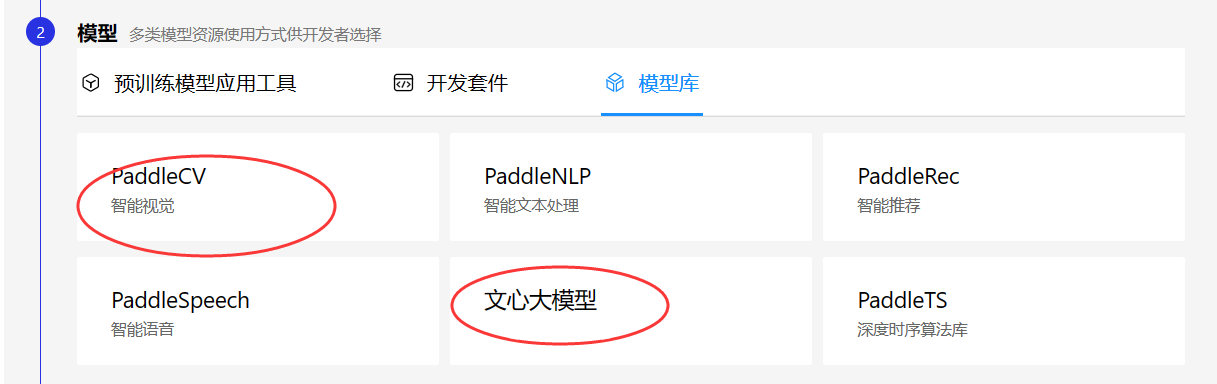
paddle —— 飞桨的深度学习核心框架
深度学习平台的 Paddle 是由百度开发的一个 开源深度学习框架,
- 它支持动态图和静态图两种模式,
- 提供了丰富的算法模型库、端到端开发套件和工具组件,
- 还具有超大规模并行深度学习能力。
本地 padddlepaddle 的安装和卸载
注意 !!!
在飞桨平台创建项目时会自动安装好相应版本的 paddlepaddle,这是 本地要自己手动安装 的教程。
详见:飞桨快速安装
安装
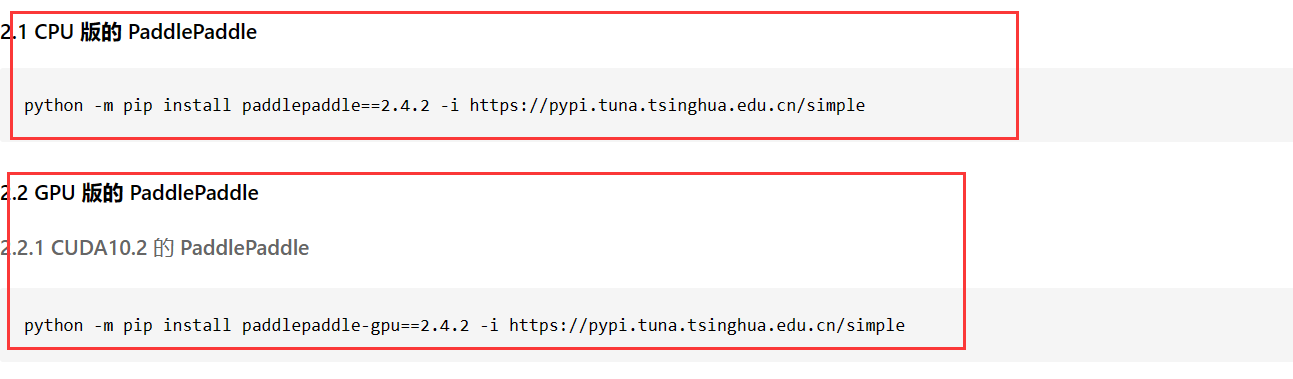
要安装最新稳定版本 paddlepaddle,可以直接如下命令:
# CPU:
# pip install paddlepaddle
# GPU:
pip install paddlepaddle-gpu
查看当前安装的版本
查看当前安装的 PaddlePaddle 版本:
import paddle
print(paddle.__version__)
卸载
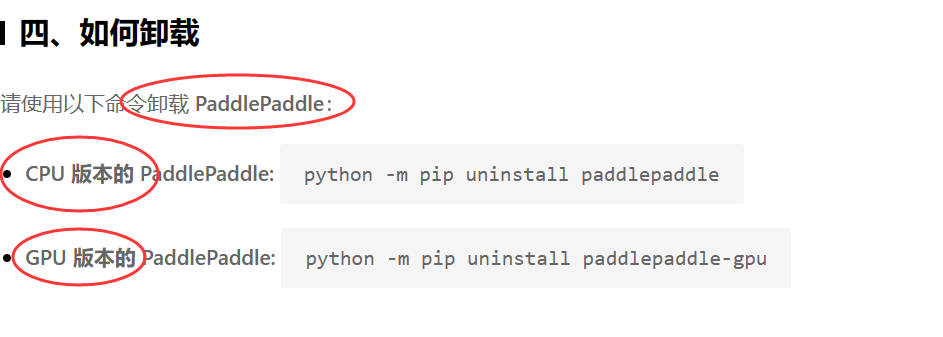
启动 GPU 训练
在 paddle 上用 GPU 训练,需要
- 先安装 GPU 版本的 paddlepaddle;
- 然后在代码中指定使用 GPU 设备,比如
paddle.device.set_device('gpu:0')。
指定 GPU
使用 paddle 的 device 的 get_device() 和 set_device() 来获取和设置 GPU。
import paddle
print(paddle.device.get_device())
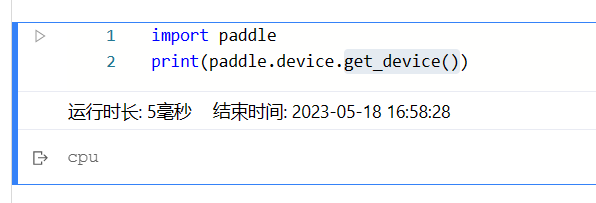
paddle.device.set_device('gpu:0')
print(paddle.device.get_device())
注意!!!如果出现了以下错误,
ValueError: The device should not be 'gpu', since PaddlePaddle is not compiled with CUDA
此时,看一下 Cuda 版本。
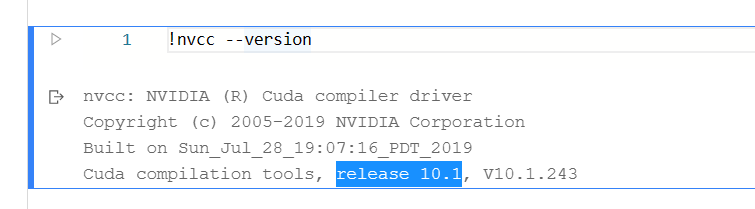
错误的原因:
- 这个错误提示是指在使用 PaddlePaddle 进行深度学习任务时,指定了 GPU 在线性层上的计算,但是 PaddlePaddle 没有编译 CUDA,因此无法使用 GPU 进行计算。如果 没有在 PaddlePaddle 中启用 GPU 计算,并且尝试在使用 GPU 时进行训练或推断操作,就会导致出现这个错误。
- 安装的
paddlepaddle是 CPU 版本的,不支持 GPU 训练。
解决方法:
- 需要先卸载 CPU 版本的
paddlepaddle, - 然后安装 GPU 版本的
paddlepaddle, - 安装成功后,你就可以用
paddle.device.set_device(‘gpu’)来指定使用 GPU 了(如果是在本地,必须有 GPU;如果在飞桨创建项目,必须要用 GPU 算力资源)。
飞桨创建项目
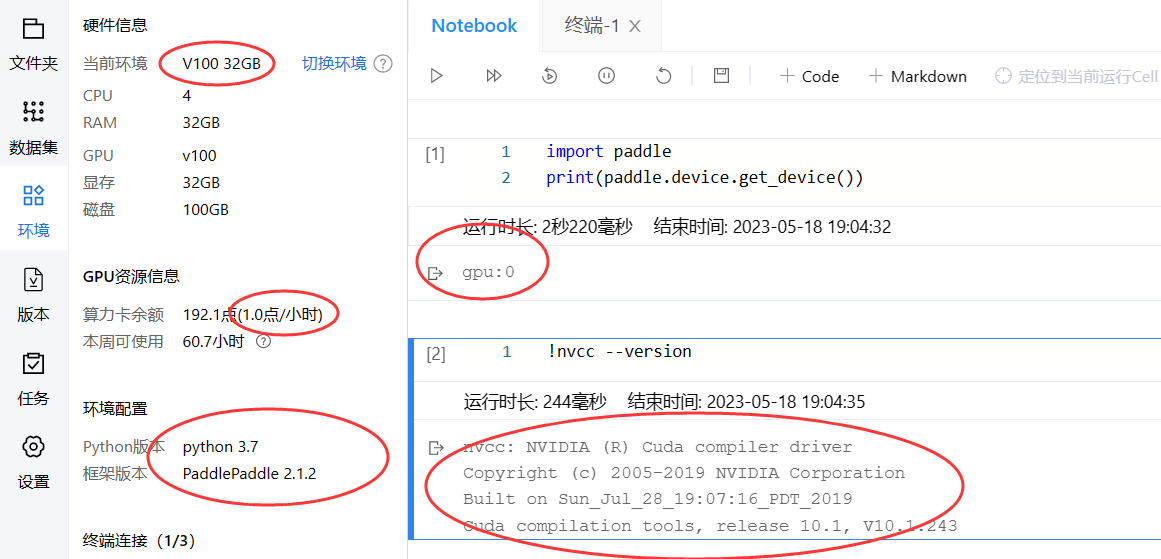
以下创建一个 pyhon3.7,PaddlePaddle 2.4.0 版本的环境,使用的是 0.5点/小时 的算力资源:
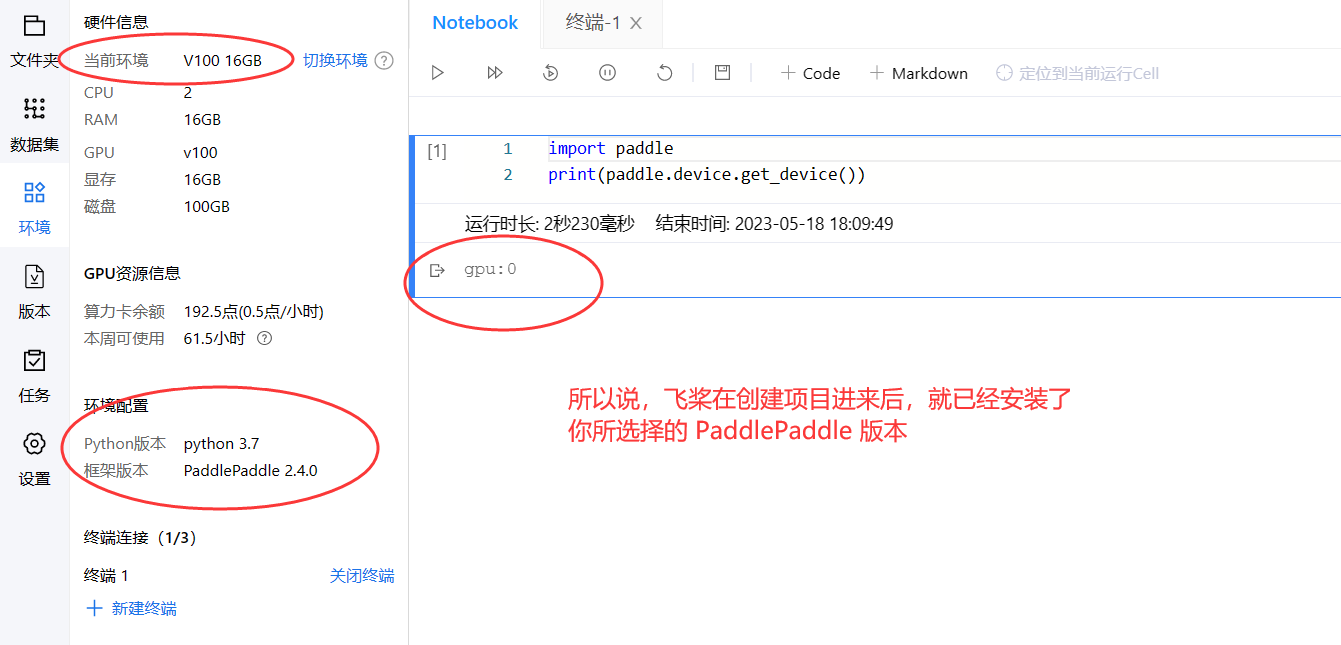
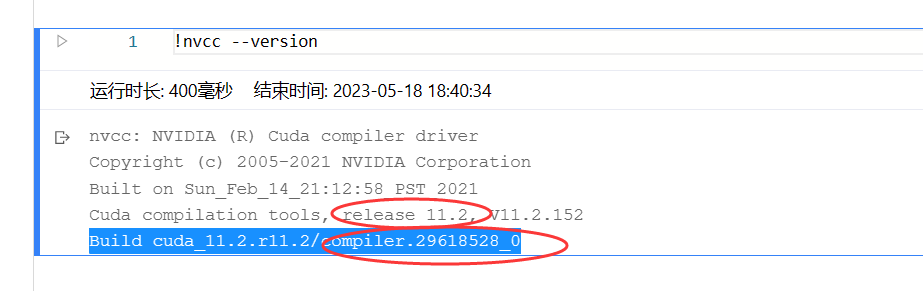
nvcc是 NVIDIA CUDA 编译器,它是 NVIDIA 公司提供的用于GPU并行计算的编译器。- 在使用 CUDA 进行
GPU编程时,需要使用nvcc对 CUDA 代码进行编译,以生成可以在GPU上运行的二进制可执行文件。
PaddlePaddle 2.1.2 下的对比
以下通过在 pyhon3.7,PaddlePaddle 2.1.2 版本的环境下,对比不同的算力资源,看一下区别。
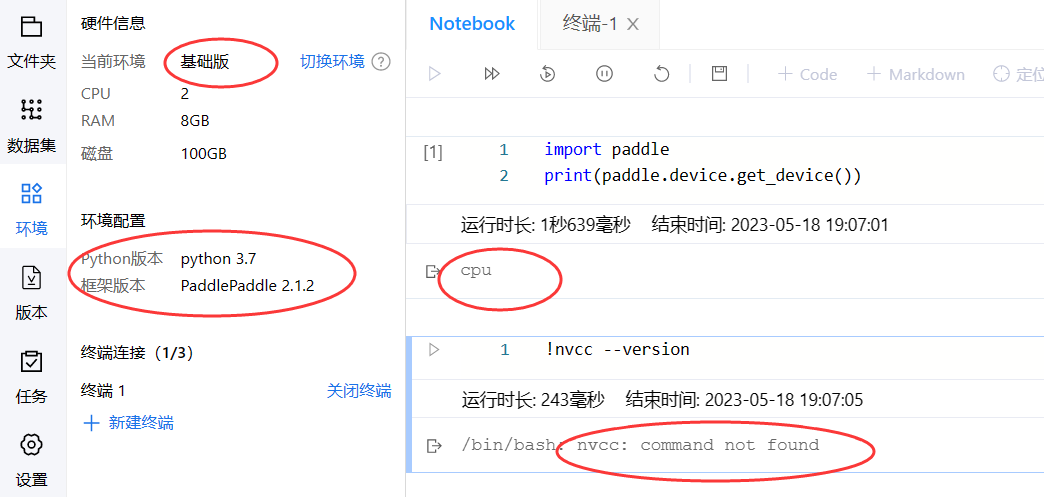
- 以下是创建了一个
pyhon3.7,PaddlePaddle 2.1.2版本的环境,使用的是基础版 CPU(未使用 GPU)的算力资源:
- 以下是创建了一个
pyhon3.7,PaddlePaddle 2.1.2版本的环境,使用的是0.5点/小时的算力资源:
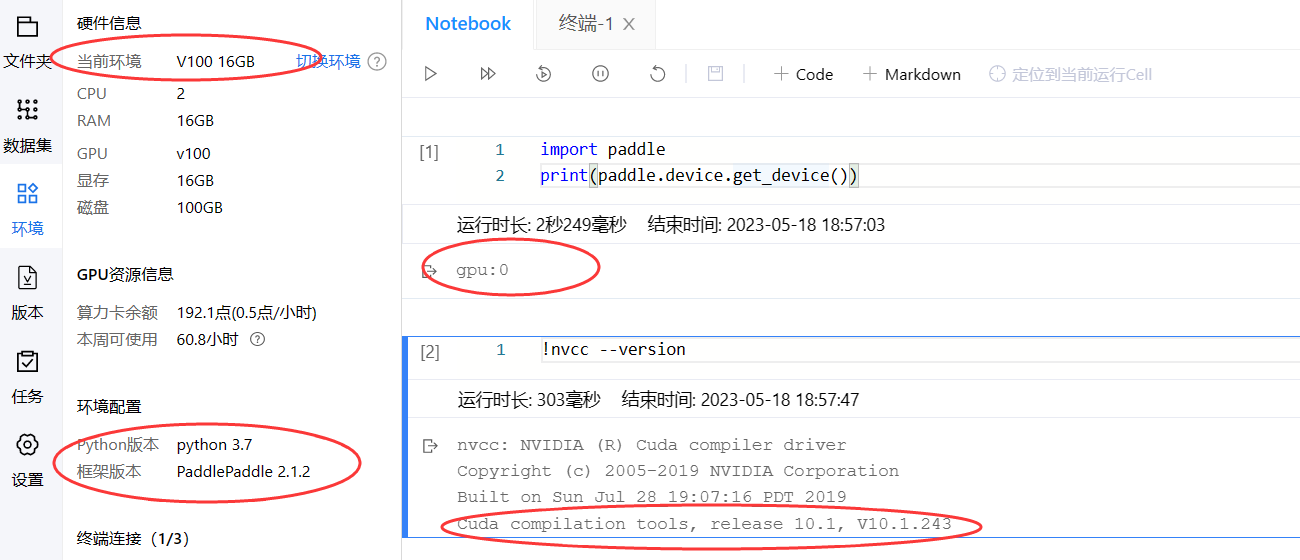
- 以下是创建了一个
pyhon3.7,PaddlePaddle 2.1.2版本的环境,使用的是1.0点/小时的算力资源:
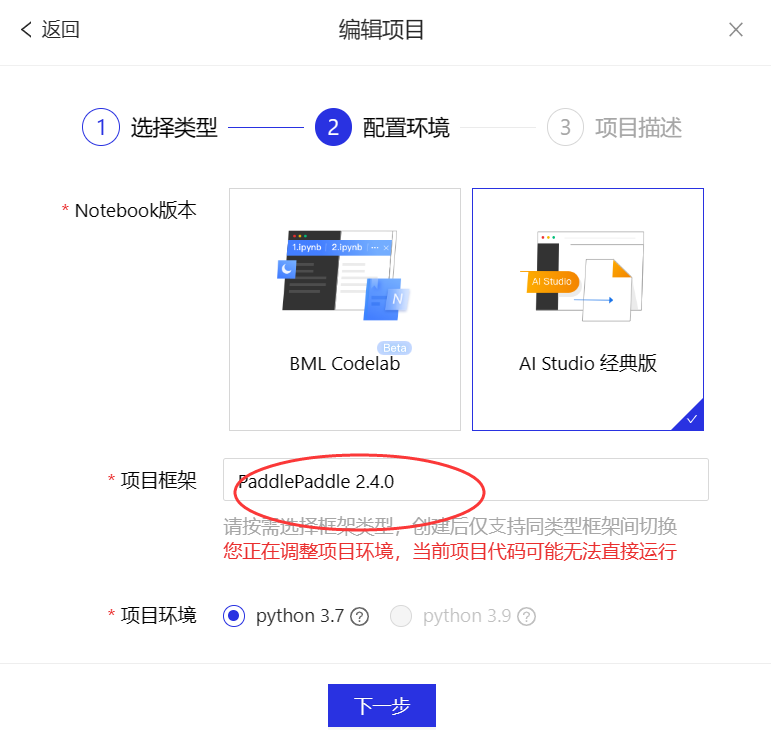
修改为 paddlepaddle2.4.0
现在,把 paddlepaddle2.1.2 改成 paddlepaddle2.4.0 再来看看区别。
这是同一个项目,仅仅修改了 PaddlePaddle 框架版本,使用 0.5点/小时 的算力资源进入环境。
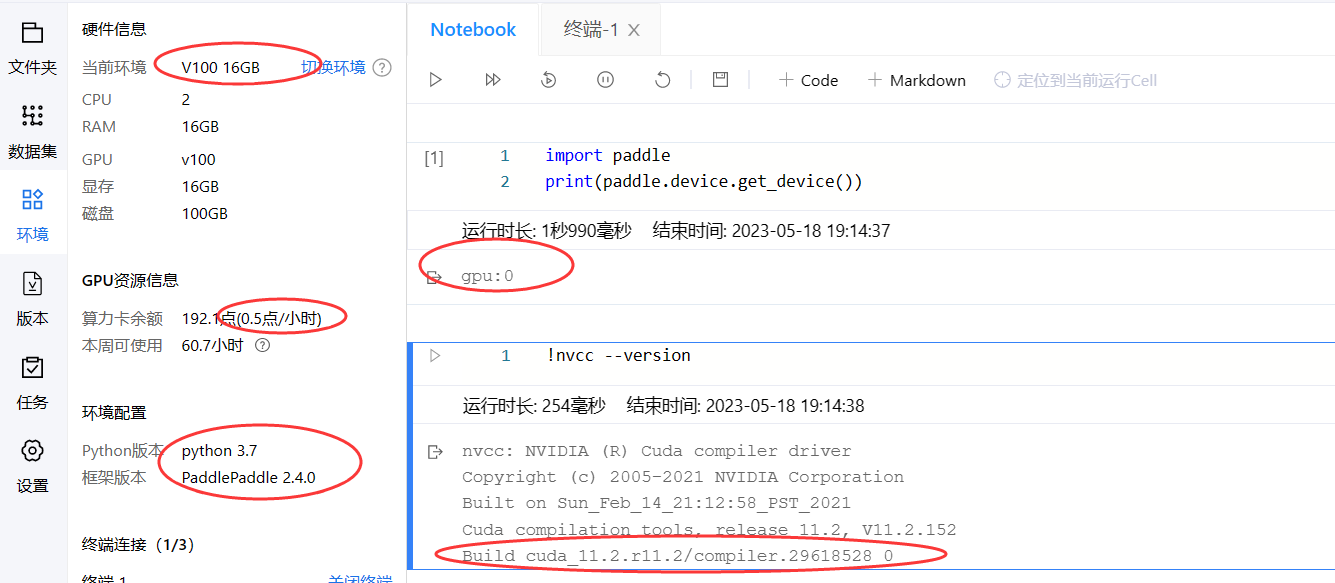
注意到这里新增了一句输出:Build cuda_11.2.r11.2/compiler.29618528_0。
- 这段文字描述了正在构建的 CUDA 工具包版本号,
cuda_11.2.r11.2/compiler.29618528_0。cuda_11.2.r11.2表示 CUDA 工具包的版本号,其中11.2代表主版本号,r11.2代表次版本号,compiler.29618528_0则表示构建的编译器版本。- 安装适当版本的 CUDA 工具包非常重要,可以确保代码与所运行的计算机上的 CUDA 版本兼容,并且可以获得最佳的性能和功能。
CUDA
CUDA(Compute Unified Device Architecture)是 NVIDIA 公司开发的用于进行并行计算的平台和编程模型。CUDA 平台基于 GPU(Graphics Processing Unit,图形处理器),利用 GPU 强大的并行计算能力来加速计算密集型应用程序,包括科学计算、机器学习、深度学习、计算机视觉、自然语言处理等领域。
CUDA 平台提供了一系列软硬件工具,帮助开发人员使用 C/C++、Python 等编程语言编写 GPU 加速的应用程序。它的 核心部分是 CUDA Toolkit,其中包含了 CUDA 编译器、标准数学库、调试器和性能分析器等工具,可以帮助开发人员构建高效的并行应用程序。
CUDA 特别适合具有大规模数据并行性质的应用,例如矩阵乘法、卷积神经网络(CNN)、循环神经网络(RNN)等。由于 GPU 具有高度并行处理能力和内存带宽,相对于传统的 CPU 计算,使用 CUDA 可以显著提高这些应用程序的性能,缩短运行时间,为科学和工程计算等领域提供了重要的支持。