前言
人体姿态估计(Human Pose Estimation)是计算机视觉领域中的一个重要研究方向,也是计算机理解人类动作、行为必不可少的一步,人体姿态估计是指通过计算机算法在图像或视频中定位人体关键点,目前被广泛应用于动作检测、虚拟现实、人机交互、视频监控等诸多领域。
一、人体姿态估计的介绍
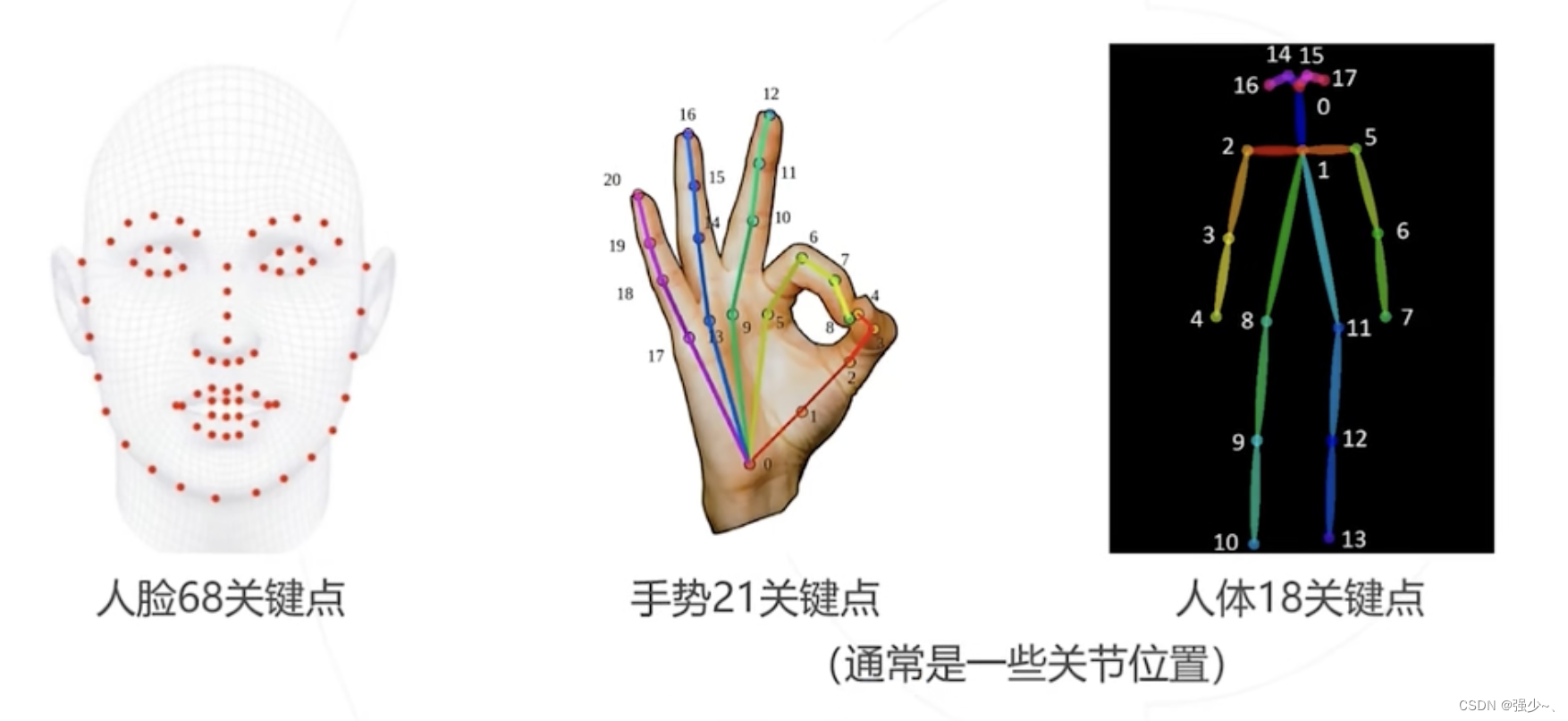
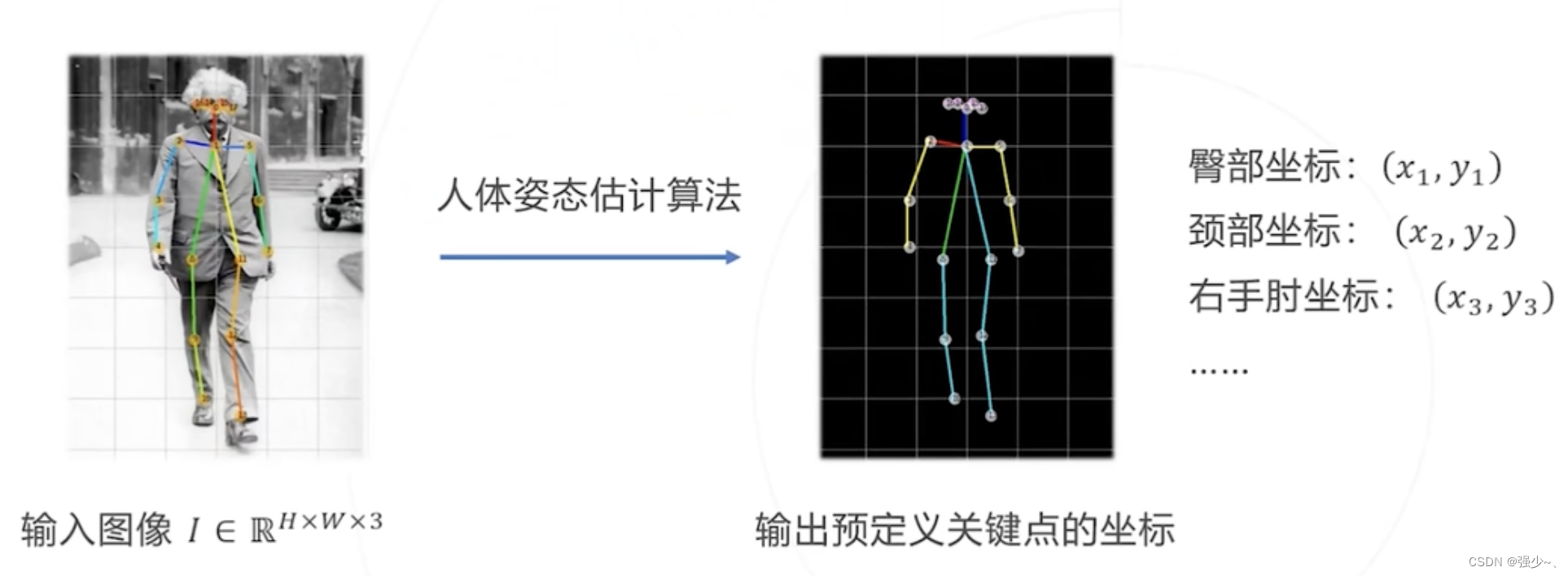
从给定图像中识别人脸、手部、身体等关键点
输入:图像
输出:所有关键点的像素坐标(x1,y1),(x2,y2)... (xj,yj),这里j为关键点的总数,取决于具体的关键点模型
二、2D姿态估计
任务描述:在图像上定位人体关键点(通常为人体主要关节点)的坐标
多人姿态估计——自顶向下方法

- 整体精度受限于检测器的精度
- 速度和计算量会正比于人数
- 一些新工作 (如SPM)考虑将两个阶段聚合成一个阶段
多人姿态估计——自底向上方法

优点:推理速度与人数无关
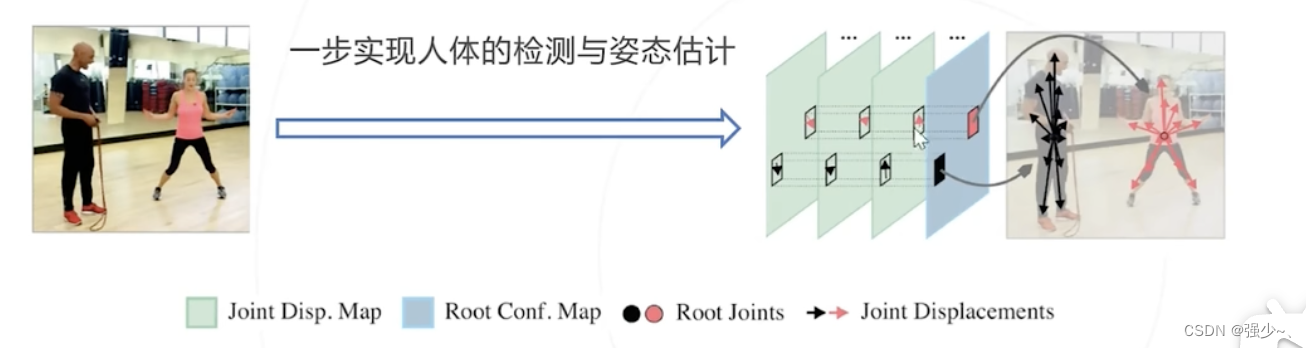
多人姿态估计——单阶段方法
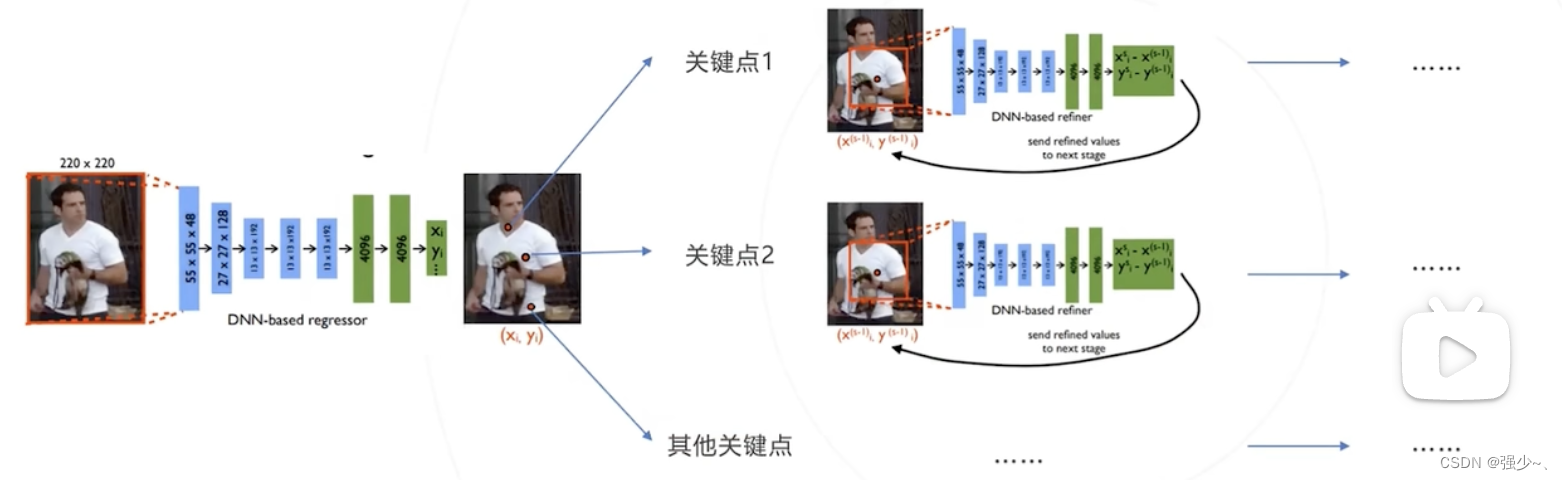
基于回顾的自顶向下方法:DeepPose、RLE
以分类网络为基础,将最后一层分类改为回归,一次性预测所有J个关键点的坐标:
P̂ =(x1,y1,x2,y2,...,xJ,yJ)=fθ(X)
然后通过最小平方误差训练网络:

通过级联提升精度:
第一级以全身图像为输入,预测所有关键点坐标,位置精度较低;
以每个预测点为中心,裁剪局部图像送入第二级网络,再次回归该点坐标,提升精度;
可级联多级
优势:
回归模型理论上可以达到无限精度,热力图方法的精度受限于特征图的空间分辨率回归模型不需要维持高分辨率特征图,计算层面更高效,相比之下,热力图方法需要计算和存储高分辨率的热力图和特征图,计算成本更高
劣势:
图像到关键点坐标的映射高度非线性,导致回归坐标比回归热力图更难,回归方法的精度也弱于热力图方法,因此 DeepPose 提出之后的很长一段时间内,2D 关键点预测算法主要基于热力图
基于热力图的自顶向下方法:Hourglass、HRNet
设计思路:准确的姿态估计需要结合不同尺度的信息
- 局部信息 ->检测不同身体组件
- 全局信息 一建模组件之间的关系,在大尺度变形、遮挡时也可以准确推断出姿态

自底向上的方法
基本思路:基于图像同时预测关节位置和四肢走向,利用肢体走向辅助关键点的聚类:即,如果某两个关键点由某段肢体相连,则这两个关键点属于同一人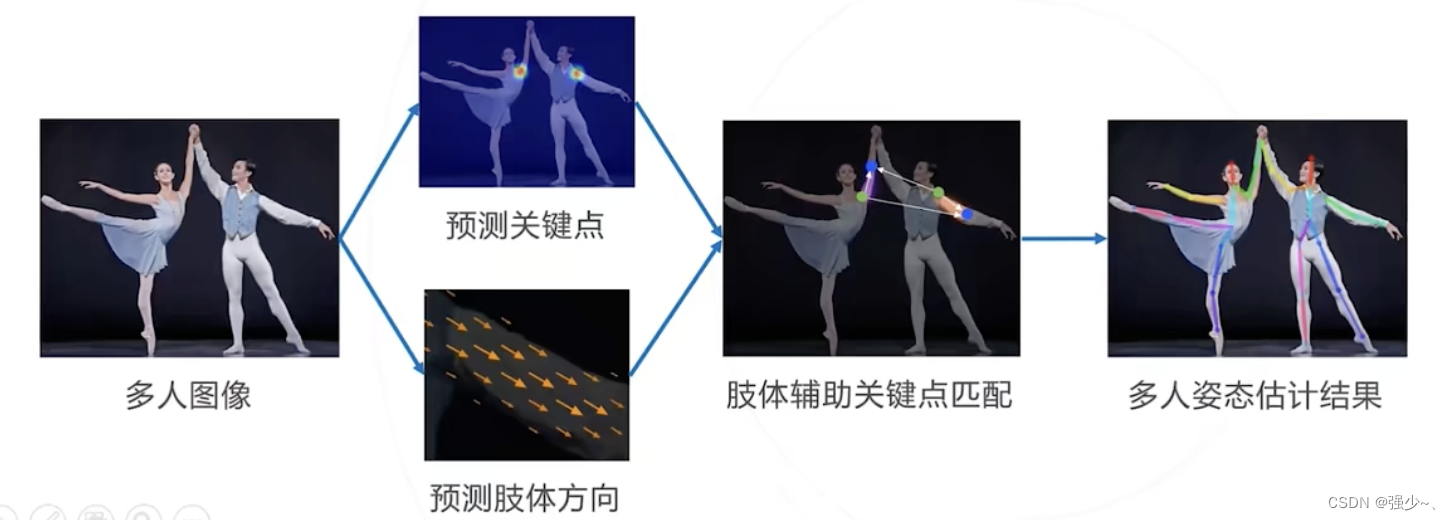
基于Transformer方法:PRTP、TokenPose
将视觉 token 和 关键点 token 一起送入 encoder 可以同时从图像中学习外观视觉表现和关键点间的约束关系
分类模型 ViT 也使用类似方法,将一个分类 token 和visual token 一起做自注意力。

2D姿态估计小结

三、3D姿态估计
任务描述
通过给定的图像预测人体关键点在三维空间中的坐标,可以在三维空间中还原人体的姿态
输入: 图像
输出: 所有人的所有关键点的空间坐标。

直接预测:Coarsse-to-Fine、Simple Baseline 3D
利用视频信息:VideoPose3D
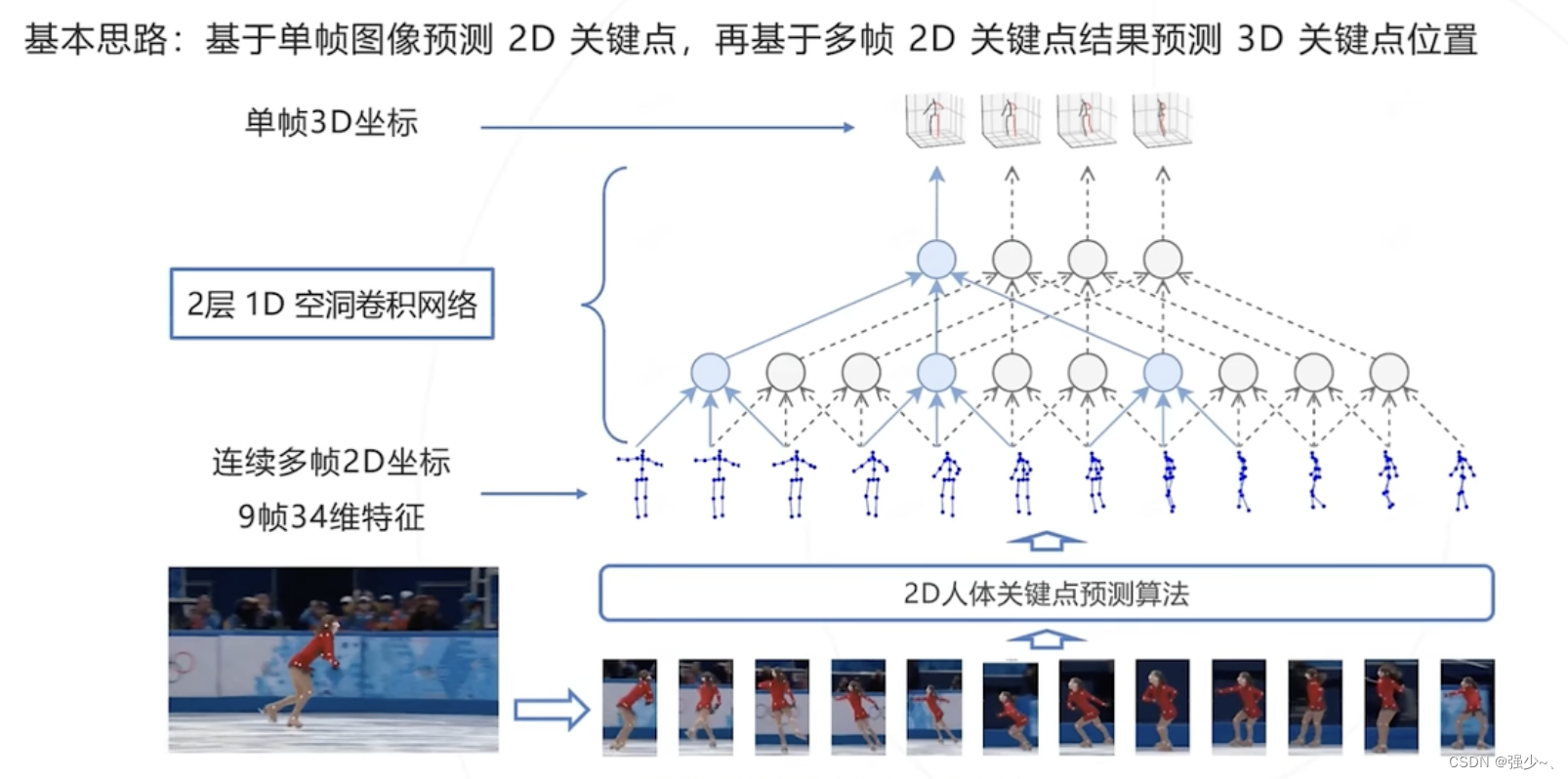
利用多角度图像:VoxelPose
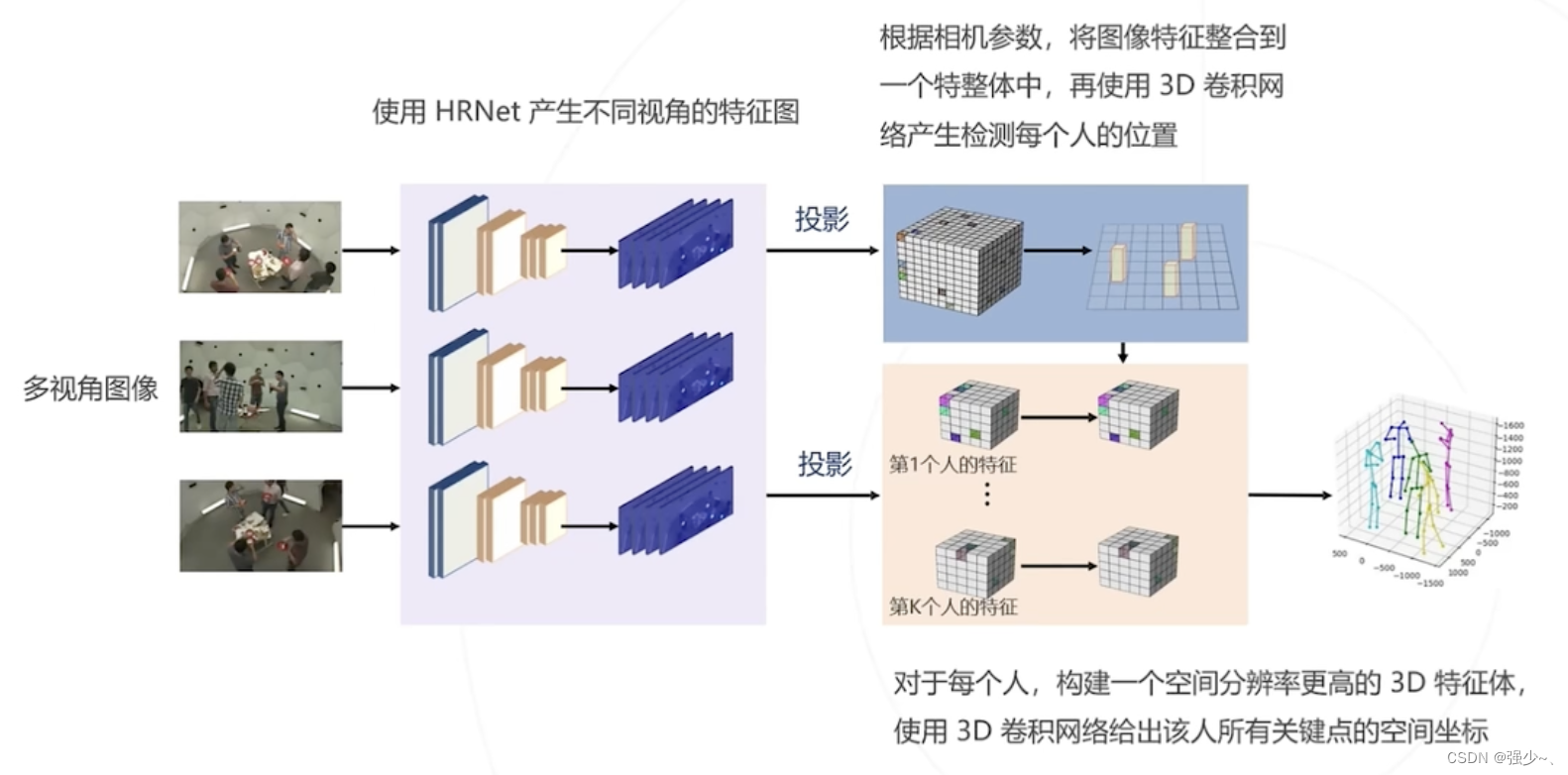
预测人体在三维空间中的坐标,可以在三维空间中还原人体的姿态

下游任务可以进行行为识别任务:基于人体姿态估计的人体行为识别
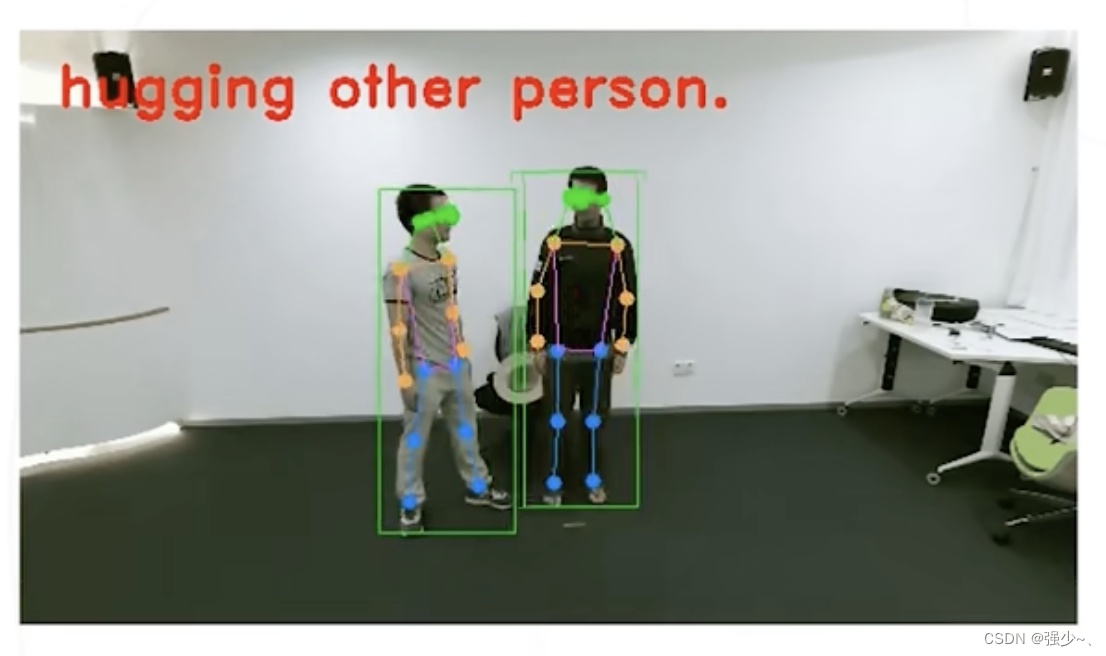
四、人体姿态估计的评估方法
- PCP:肢体的检出率作
- PDJ:关节点的位置精度
- PCK:关键点的检测精度
- OKS based mAP:以关键点相似度OKS作为评价指标计算mAP