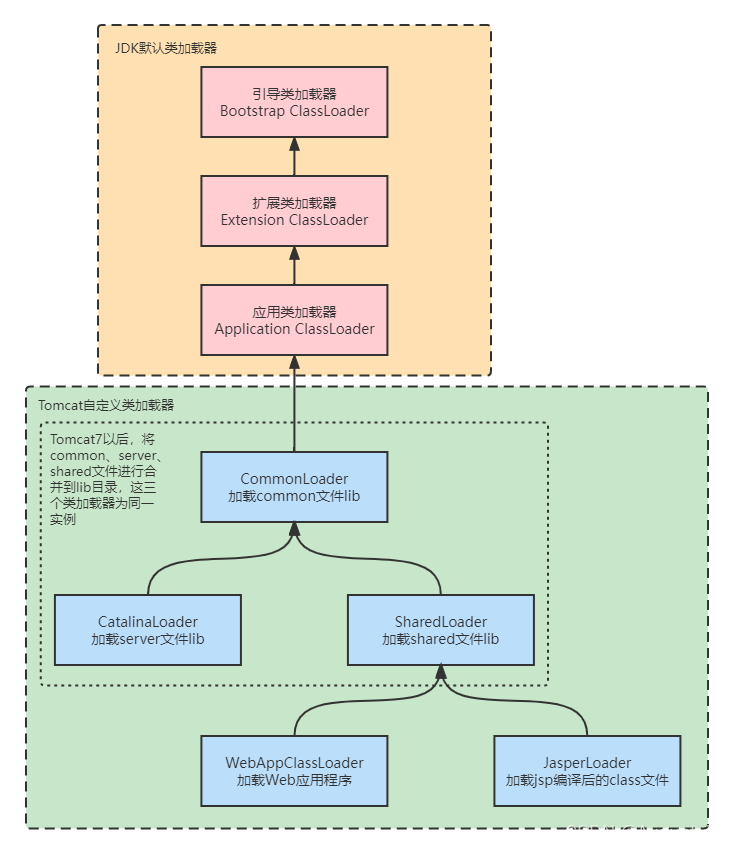
代码日记
- Project :Space
- 1、new_method.py
- new2.py
- new3.py
- new4.py
- new5.py
- new5.1.py
- new6.py
Project :Space
都是在D001289数据集上的测试
1、new_method.py
先划分训练集和测试集
通过稀疏自编码器进行降维至20维度
自编器参数:
# 训练自编码器模型
autoencoder = sparse_autoencoder(data_tensor, hidden_size=84, encoded_size=dim, num_epochs=100,
batch_size=32, learning_rate=0.001, sparsity_penalty=0.01)
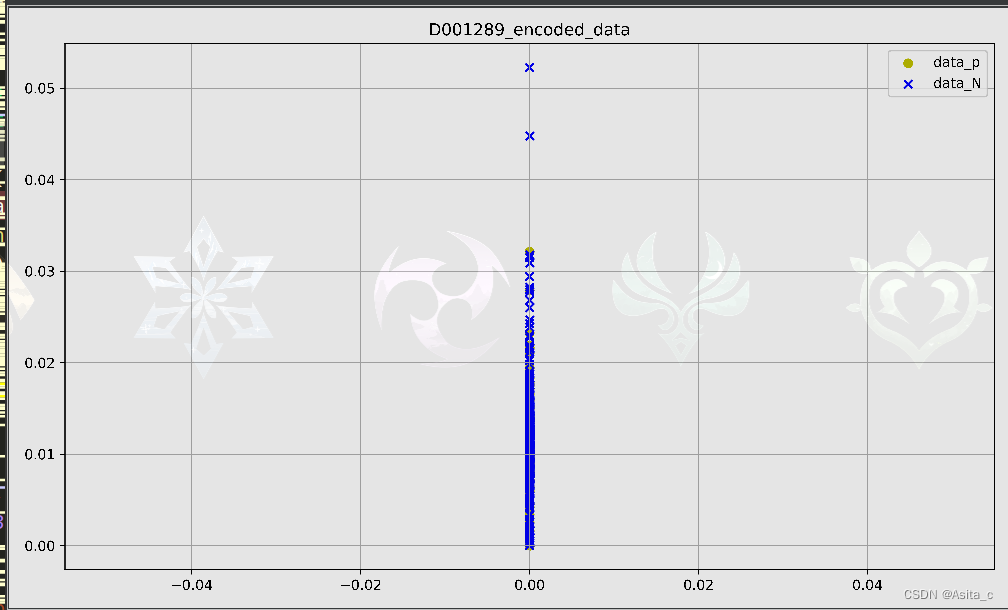
但是稀疏自编码器从散点图来看效果不是很好,呈现出一条线性形状,虽然最终的分类结果看起来还可以
数据降维前的显示: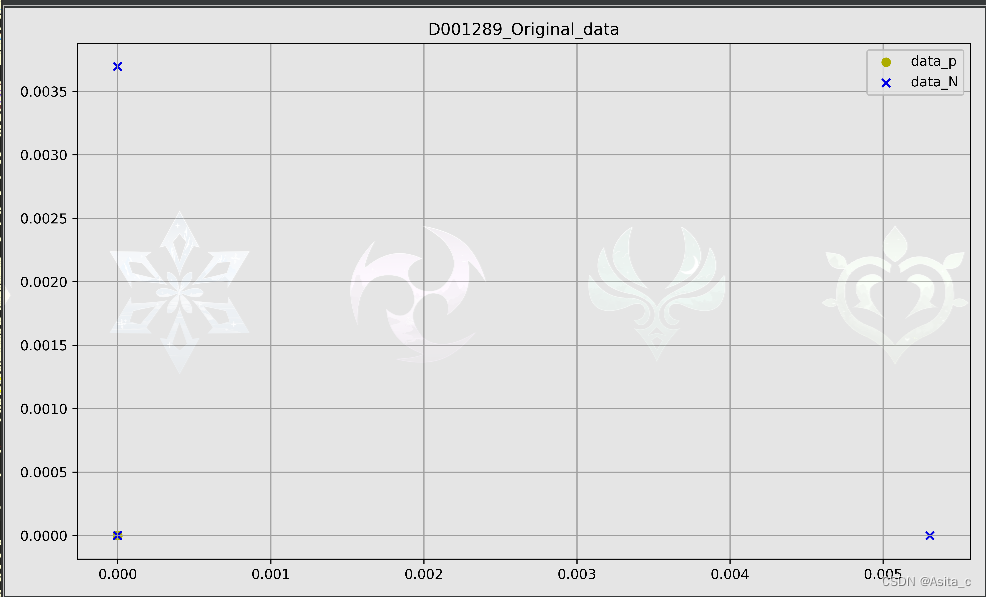
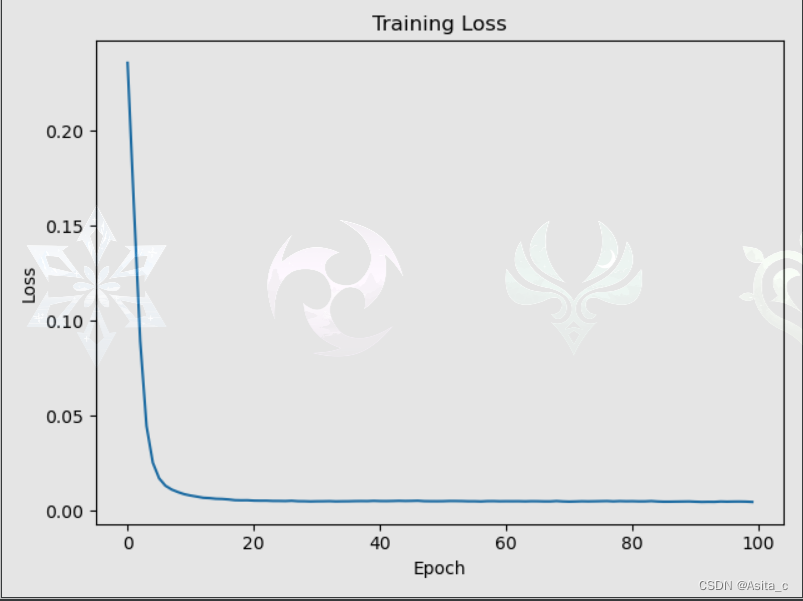
稀疏自编码器训练图像:
编码后数据(同时也降维到20维度)
其中子空间的某一子空间
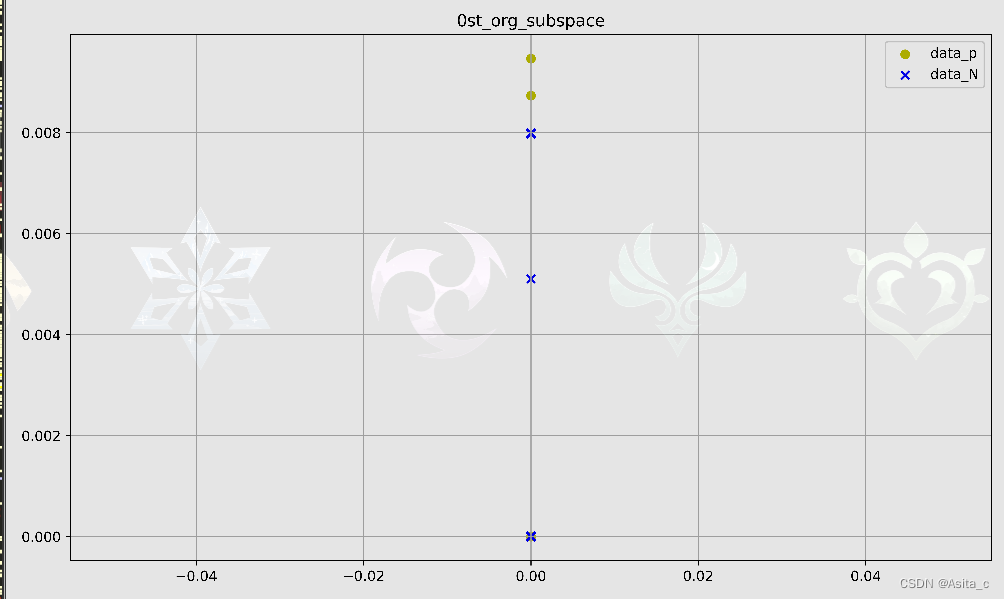
未采用LMNN和RENN数据变换和数据欠采样
采用改进版空间划分方法NewAnnoy
其他参数:leaf_size=60, radius=3,(p / n) <= 0.2,divided_num = 4
扩增方案是WGAN
从图像上看但是似乎扩增的样本跟原始数据似乎不在一个空间
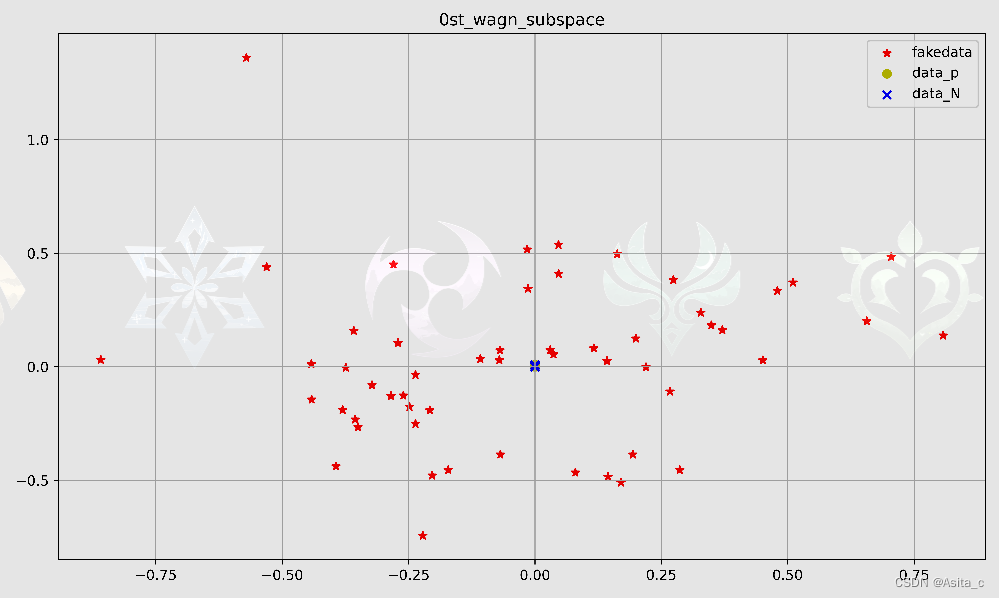
数据筛选后的:
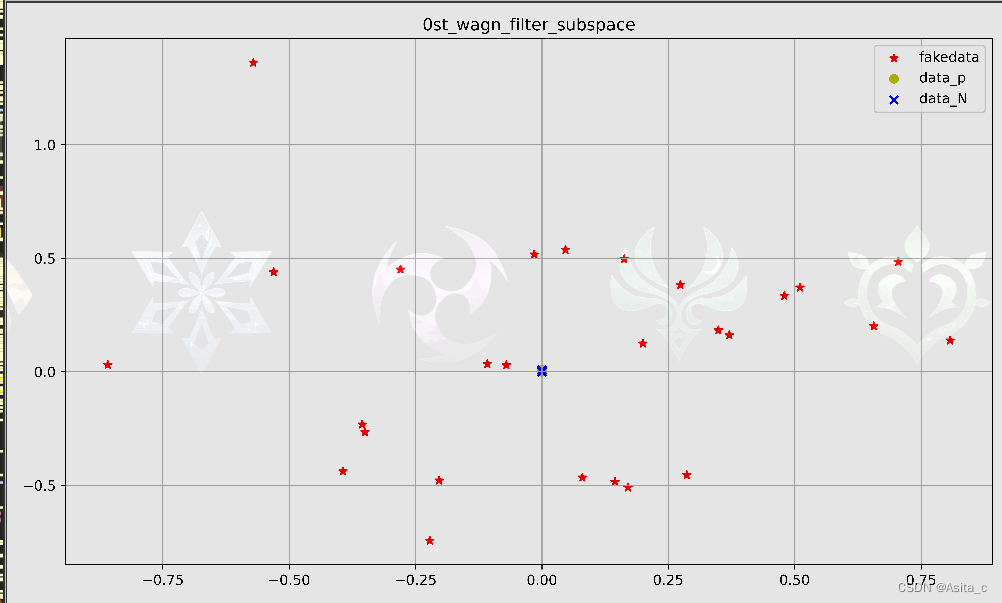
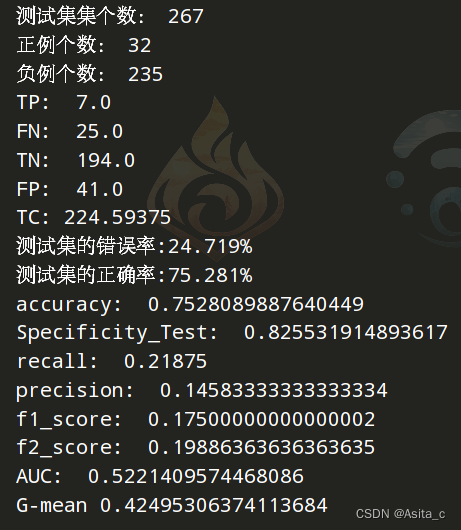
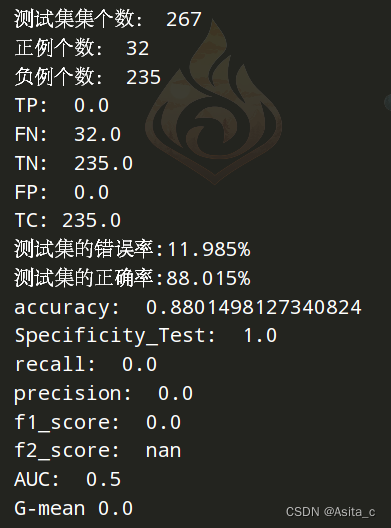
目前最好结果:
采用之前的训练好的WGAN:
wgan_GeneratorNfake('WGAN_pt\D001289Big_20dim_datap.pt',
(np.shape(SubDataArr_p)[0]) * 2)
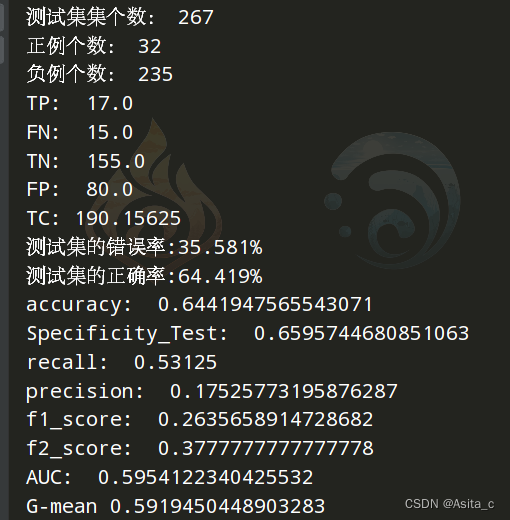
但是用新的实验结果没眼看
new2.py
与new_method.py不同的是:
未采用稀疏自编器进行降维,而是只做数据变换或者数据表示
然后采用KPCA进行降维后,散点图看起来没有那么难受了:
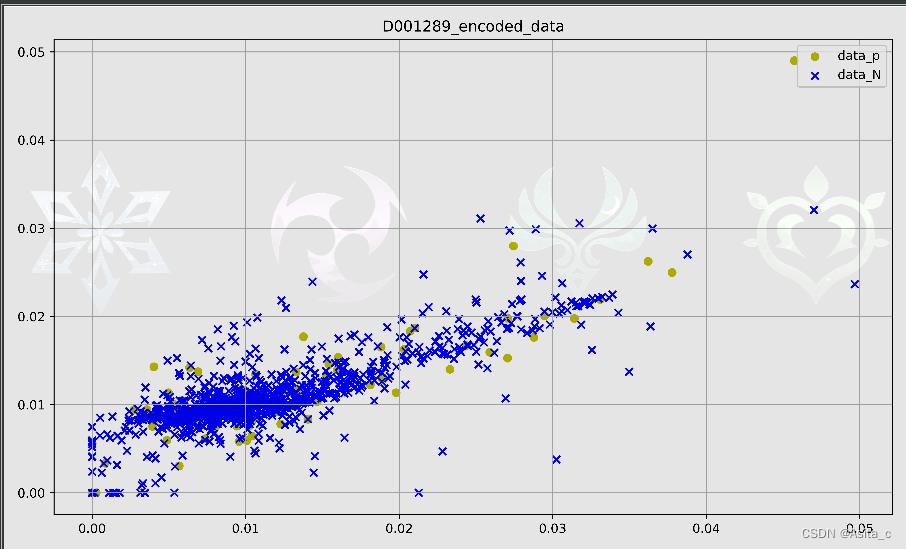
用老版训练好的WGAN:WGAN_pt\D001289Big_20dim_datap.pt
用新训练的:G1289_20.pt

new3.py
将随机森林与稀疏自编码器相结合,为每棵子树单独训练了一个稀疏自编码器,将随机森林的每棵子树进行特征选择后的结果输入到对应的每个稀疏自编器中,然后再把返回训练森林
实验结果:
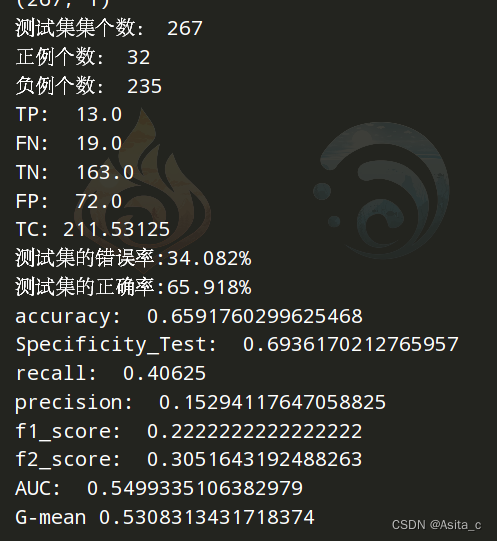
new4.py
想用神经网络,但是失败了(代码一直报错)
new5.py
采用稀疏自编器做为获取数据的表示,然后用ge3来做扩增
仅在1289数据集上效果不错(只试了1289、1714)
稀疏自编码参数:
# 训练自编码器模型
autoencoder = sparse_autoencoder(data_tensor, hidden_size=84, encoded_size=dim, num_epochs=100,
batch_size=32, learning_rate=0.001, sparsity_penalty=0.01)
GBDT参数:
GradientBoostingClassifier(learning_rate=0.1, n_estimators=500, min_samples_leaf=21, max_features='sqrt',
subsample=0.8, random_state=10)
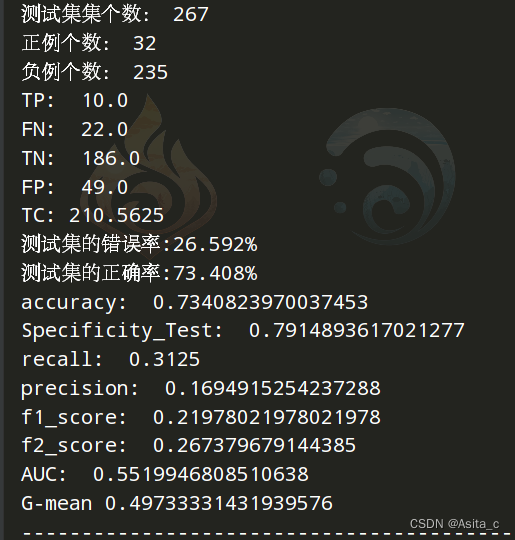
实验结果:
略超英文(几乎齐平仅在1289)
new5.1.py
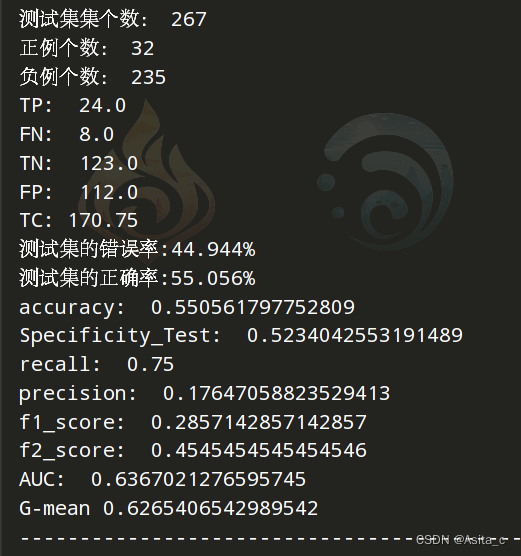
在5的基础上,但是不降维,保持原有维度,但是图像上会好看一点,结果差一些
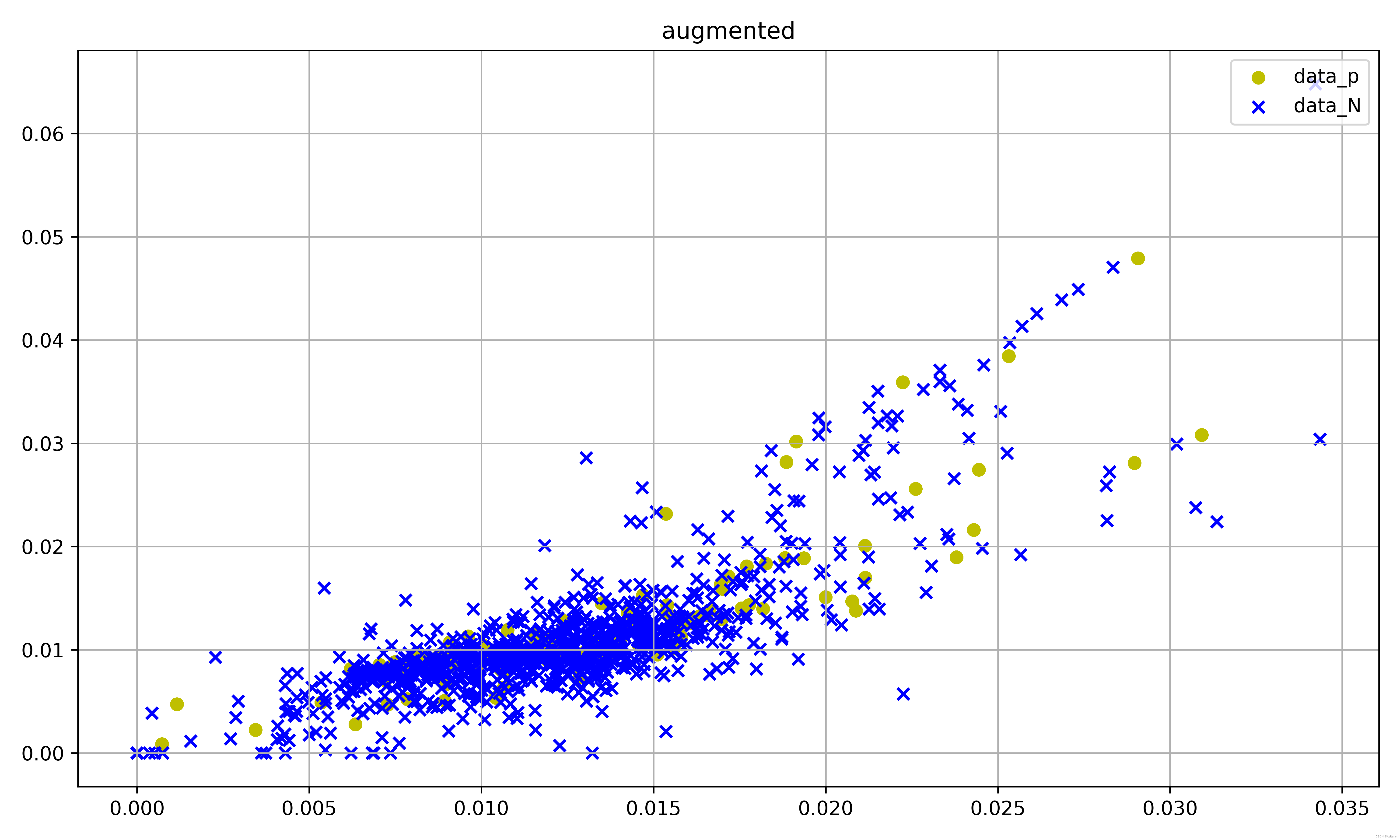
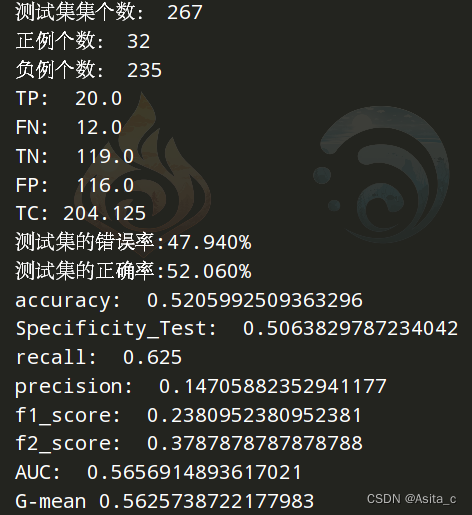
参数:
autoencoder = sparse_autoencoder(data_tensor, hidden_size=42, encoded_size=np.shape(dataArr)[1], num_epochs=100,
batch_size=32, learning_rate=0.001, sparsity_penalty=0.01)
M = GradientBoostingClassifier(learning_rate=0.1, n_estimators=200, min_samples_leaf=20, max_features='sqrt',
subsample=0.8, random_state=10)
new6.py
在5的基础上加入改进版的空间划分,即在空间划分后每个子空间内用ge3进行扩增,但效果不是很理想