数据清洗是量化的第一步,也是非常关键的一步。
- 检查数据的空值、重复值、异常值,并进行描述性数据分析,观察数据的分布情况。
缺失值:
return_all.info()
np.where(np.isnan(return_all))
np.where(np.isinf(return_all))
重复值:
return_all[return_all.duplicated()]
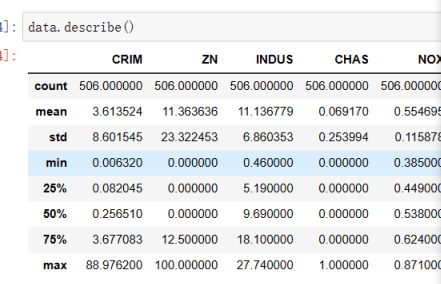
异常值:
return_all.describe()
2. 如果有的话,对相关的异常情况进行处理
缺失值删除:
df1 = df.dropna()
缺失值填补
return_all.当月.fillna(return_all.当月.median()) 用中位数填充
return_all.当月.fillna(return_all.当月.mean()) 用均值填充
df.ffill() 缺失值前向填补
df.bfill() 缺失值后向填补
重复值删除
df.drop_duplicates()
- 描述性数据分析
- 使用boston房价作为样例数据
from sklearn.datasets import load_boston
boston = load_boston()
data = pd.DataFrame(boston.data,columns = boston.feature_names)
data['price'] = pd.Series(boston.target)
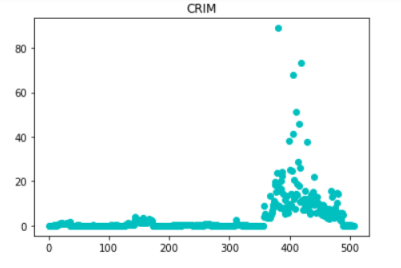
(2)比较单一因素的房价高低
columns = data.columns.values
nlist = [i for i in range(1,507)]
for i in columns:
plt.scatter(nlist,data[i],color='c')
plt.title(i)
plt.show()
print('*'*20)
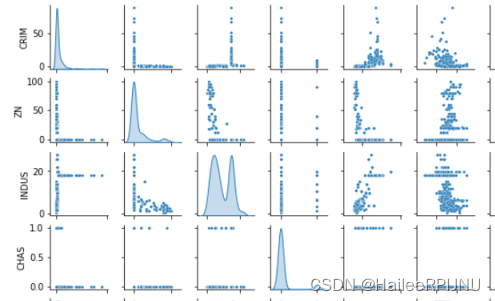
(3)观察房子分布状况是否接近于正态分布
data.price.plot(kind='kde')
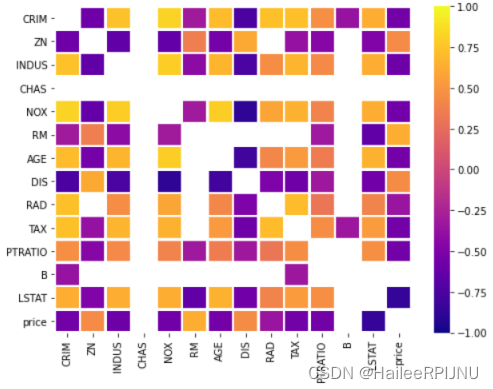
(4)features 之间的相关性,features 和price的相关性
spearman = data.corr('spearman')
pearson = data.corr('pearson')
f,size = plt.subplots(figsize = (8, 6))
seaborn.heatmap(data = spearman,cmap = plt.cm.plasma,linewidths=1.5,vmin = -1,vmax = 1,ax=size,mask=((spearman<0.3) & (spearman > -0.3)|(spearman == 1)))
f.savefig('sns_heatmap_normal.jpg', bbox_inches='tight')
- 探索性数据分析
EDA的内容一定是基于描述性数据分析的结果之上的;如果不对数据的结构有着深入理解,EDA是不会产出效果来的。在此,我们随便举个例子:
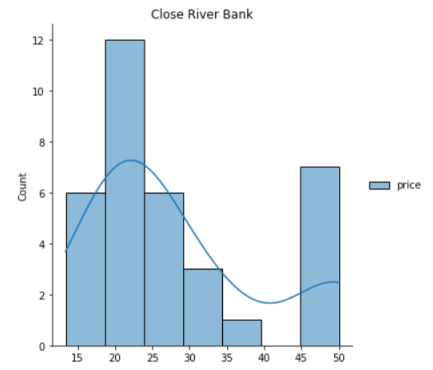
CHAS于price是否有显著关系
seaborn.displot(data[['price']][data.CHAS == 0.0],kde=True)
plt.title('Not Close River Bank')
plt.show()
seaborn.displot(data[['price']][data.CHAS == 1.0],kde=True)
plt.title('Close River Bank')
plt.show()