tf.variable_scope()共享或重用变量
文章目录
- 一、接前一天
- 二、`tf.variable_scope()`共享或重用变量
- 1. 背景
- 2. 目的
- 3. `tf.variable_scope()`基本参数
- 3. `tf.variable_scope()`作用
- (1).命名空间
- (2).共享变量
- (3).控制变量重复定义
- 三、解释前天遗留问题以及文章最后抛出的问题
- 1. 解释前先明白共享的含义
- 2. 还有什么是作用域的重用策略
- 3. 解释之前的问题,为什么在同一作用域下同时使用 tf.Variable() 和 tf.get_variable() ,不设置reuse不开启共享变量,tf.get_variable() 可以继承同名的tf.Variable()变量。将reuse=True开启共享变量反而会报错
- 4. 为什么 tf.Variable() 和 tf.get_variable()创建的变量不共享
- 5. 解释 `这个当前作用域也有说法,等下说`
- 6. 重点注意:
一、接前一天
总结:到这里为止,基本掌握如何通过常量、操作、占位符、变量来定义张量。今天在学习一个重要函数
tf.variable_scope()来共享或重用变量。
一般获取已经定义的变量有利于复用,如果没有使用tf.variable_scope()就会抛出异常。
今天来一起讨论下该函数
二、tf.variable_scope()共享或重用变量
1. 背景
当我们使用 TensorFlow 构建神经网络时,通常会涉及到很多的变量。这些变量需要在训练期间不断地更新,同时在推理(inference)过程中也需要被重复使用。因此,在 TensorFlow 中,我们需要对变量进行管理和控制,使之易于调用、共享和可视化。
2. 目的
tf.variable_scope() 是一个用于定义变量的作用域的函数。它可以将同一种类型的变量放在同一个作用域下,方便进行管理和调用。每个变量都有相应的名称,以及所属的作用域的名称。
通过 tf.variable_scope() 函数,我们可以实现以下几个目的:
- 为变量命名
提供更高级别的结构化管理:在TensorFlow的计算图中使用的所有变量都将被分配到一个作用域(scope)中,这样可以更好地组织计算图,并且可以更容易地调试和可视化。 共享变量:在 TensorFlow 中,如果两个变量具有相同的名称和作用域,则它们将指向同一个变量。控制变量的可访问性:通过设置reuse参数,我们可以控制变量是否可以被重复使用或者共享
3. tf.variable_scope()基本参数
#来看下源码
def __init__(self,
name_or_scope,
default_name=None,
values=None,
initializer=None,
regularizer=None,
caching_device=None,
partitioner=None,
custom_getter=None,
reuse=None,
dtype=None,
use_resource=None,
constraint=None,
auxiliary_name_scope=True):
这里重点标记几个参数:
name_or_scope:作用域的名称或者作用域本身,是必填参数。default_name:默认的名称,如果没有指定具体的名称,则使用此名称。values:列表或字典类型的参数,其中每个元素对应一个变量。reuse:重用标志,表示是否共享变量。initializer:变量的初始化方式。默认值为None。如果不指定initializer,则会采用默认的随机初始化方式。具体的初始化方式可以在定义变量时进行设置。
3. tf.variable_scope()作用
(1).命名空间
假设现在有一个深度神经网络模型,模型中包含多个卷积层和全连接层。为了方便管理和调试,我们可以使用variable_scope来给每个变量添加前缀,按照功能或者含义进行分组
with tf.variable_scope('conv_1'):
weight = tf.get_variable('weight', shape=[3, 3, 3, 32], initializer=tf.truncated_normal_initializer(stddev=0.1))
bias = tf.get_variable('bias', shape=[32], initializer=tf.constant_initializer(0.0))
with tf.variable_scope('conv_2'):
weight = tf.get_variable('weight', shape=[3, 3, 32, 64], initializer=tf.truncated_normal_initializer(stddev=0.1))
bias = tf.get_variable('bias', shape=[64], initializer=tf.constant_initializer(0.0))
with tf.variable_scope('fc_1'):
weight = tf.get_variable('weight', shape=[7 * 7 * 64, 1024], initializer=tf.truncated_normal_initializer(stddev=0.1))
bias = tf.get_variable('bias', shape=[1024], initializer=tf.constant_initializer(0.0))
with tf.variable_scope('fc_2'):
weight = tf.get_variable('weight', shape=[1024, 10], initializer=tf.truncated_normal_initializer(stddev=0.1))
bias = tf.get_variable('bias', shape=[10], initializer=tf.constant_initializer(0.0))
(2).共享变量
假设现在有两个模型A和B,这两个模型需要共享某些变量。为了节省内存和方便调试,我们可以使用variable_scope来共享变量,
def model_A(input_data):
with tf.variable_scope('shared', reuse=tf.AUTO_REUSE):
weight = tf.get_variable('weight', shape=[input_dim, hidden_dim], initializer=tf.truncated_normal_initializer(stddev=0.1))
bias = tf.get_variable('bias', shape=[hidden_dim], initializer=tf.constant_initializer(0.0))
...
def model_B(input_data):
with tf.variable_scope('shared', reuse=tf.AUTO_REUSE):
weight = tf.get_variable('weight')
bias = tf.get_variable('bias')
...
使用了相同的variable_scope ‘shared’ 来定义和共享模型A和B中的权重和偏置。通过设置reuse参数为tf.AUTO_REUSE,我们可以让模型B共享模型A的变量。这样可以节省内存,同时让模型更加可靠和易于理解。
(3).控制变量重复定义
假设现在有一个函数f(x)需要多次调用,其中包含一个变量v。我们希望在第一次调用时定义变量v,在后续调用时共享这个变量v。为了避免重复定义变量,我们可以使用variable_scope来控制变量是否可重用,
def f(x):
with tf.variable_scope('v', reuse=tf.AUTO_REUSE):
v = tf.get_variable('v', shape=[1], initializer=tf.constant_initializer(0.0))
return x * v
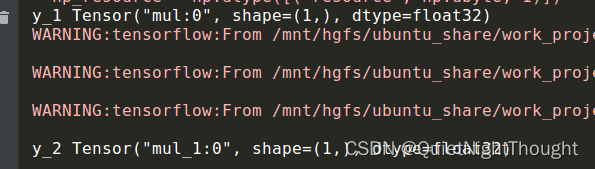
x_1 = tf.constant(1.0)
y_1 = f(x_1)
x_2 = tf.constant(2.0)
y_2 = f(x_2)
在比如结合tf.get_variable使用:
import tensorflow as tf
with tf.variable_scope("my_scope"):
a = tf.Variable([1, 2], name="var_a")
b = tf.get_variable(name="var_b", shape=[2])
c = tf.constant([3, 4], name="const_c")
with tf.variable_scope("my_scope", reuse=True):
d = tf.Variable([5, 6], name="var_d")
e = tf.get_variable(name="var_b")
print(a.name)
print(b.name)
print(c.name)
print(d.name)
print(e.name)
 可以看到:当我们开起了
可以看到:当我们开起了 reuse=True功能:说明开启了重复使用变量的功能。注意:这里说的是变量
当我们定义一个新的变量时候,如果,在同一个 variable_scope下已经有了同名的变量,就会抛出ValueError异常。(这里肯定有人说 可以使用 get_variable函数啊,这个等会说)。但是在某种情况下需要共享变量,也就是多个操作共用一个变量。这是就可以设置为True。
如果将reuse参数设置为True,则在当前作用域(这个当前作用域也有说法,等下说)下查找已经存在的同名变量,并返回这个变量。如果没有找到,则抛出异常。如果将reuse参数设置为None或False,则在当前作用域下创建该变量。
注意!!!:reuse参数只对当前variable_scope下的变量起作用,如果遇到嵌套的variable_scope,则每个variable_scope都可以单独控制reuse参数的取值。如果想在不同的作用域下共享变量,则需要将reuse参数设置为True,并且使用tf.variable_scope()的嵌套语法来指定每个变量作用域。
三、解释前天遗留问题以及文章最后抛出的问题
1. 解释前先明白共享的含义
在TensorFlow中,变量共享是指多个TensorFlow节点之间使用相同的变量。当多个TensorFlow节点共享相同的变量时,它们可以共同学习这个变量,并且每个节点对变量做出的更新都会影响到其他节点。
使用tf.get_variable()函数创建变量时,可以通过将reuse参数设置为True来启用变量共享。如果在同一作用域内调用tf.get_variable()多次,每次使用相同的名称和形状,则将返回现有的变量,而不是每次都创建一个新的变量。
在深度学习模型中,通常需要在不同的层之间共享变量,以便提高模型训练的效率和精度。例如,在卷积神经网络(CNN)中,卷积层的权重可以在整个模型中共享,以提高模型的可训练性和泛化能力。
总结一句话:一荣俱荣,一损俱损共享变量意味着多个节点共用相同的变量,因此任何一个对该变量的操作都会影响到其他节点。如果其中一个节点更新了变量的值,则所有使用相同变量的节点的输出也会随之改变。
2. 还有什么是作用域的重用策略
作用域的重用策略是指在创建一个新的变量作用域时,当前作用域下是否可以重用已经存在的变量。
在 TensorFlow 中,每个变量都会有一个唯一的名称,这个名称包含了所有定义该变量的作用域和变量名。当使用 tf.Variable() 或 tf.get_variable() 创建变量时,需要指定变量的名称,如果名称相同,则会在创建变量时发生命名空间冲突。
为了避免这种冲突,TensorFlow 提供了作用域(tf.variable_scope())来隔离变量的命名空间,并且可以设置作用域的重用策略。具体来说,作用域的重用策略有以下三种:
None:默认值,表示在创建作用域时不强制设置重用策略,由上下文环境自动确定是否可以重用变量。tf.AUTO_REUSE:表示在创建作用域时尝试重用已经存在的变量,如果不存在则创建新的变量。True:表示强制重用已经存在的变量,如果不存在则抛出异常。
在 TensorFlow 2.x 中,作用域的重用策略默认为 tf.compat.v1.AUTO_REUSE,即尝试重用已经存在的变量。而在 TensorFlow 1.x 中,默认的重用策略是 None,表示不强制设置重用策略,由上下文环境自动确定是否可以重用变量。
作用域的重用策略是在创建新作用域时设置的,可以使用 tf.variable_scope() 函数的 reuse 参数来指定
3. 解释之前的问题,为什么在同一作用域下同时使用 tf.Variable() 和 tf.get_variable() ,不设置reuse不开启共享变量,tf.get_variable() 可以继承同名的tf.Variable()变量。将reuse=True开启共享变量反而会报错
tf.get_variable()继承同名的tf.Variable()变量不等同于共享变量,它创建的是一个新变量。当您在同一作用域内同时使用tf.Variable()和tf.get_variable()函数来创建同名的变量时,这两个变量是不同的,它们的值和状态也是不同的,因此不能称之为共享变量。
因此:这也是为什么在同一作用域下同时使用 tf.Variable() 和 tf.get_variable() ,不设置reuse不开启共享变量,tf.get_variable() 可以继承同名的tf.Variable()变量。将reuse=True开启共享变量反而会报错。还有就是上边 (这里肯定有人说 可以使用 get_variable函数啊)这句话的解释。因为将reuse=True开启共享变量也就意味着同一个作用域下,的变量共享,然而事实是 这两者创建的变量并不是共享的。因此才会报错。
4. 为什么 tf.Variable() 和 tf.get_variable()创建的变量不共享
-
使用
tf.Variable()函数创建变量,则每次调用该函数时都会创建一个新的变量。而如果您使用tf.get_variable()函数创建变量,则会尝试重用具有相同名称的现有变量。 -
如果
未启用变量共享,则tf.Variable()和tf.get_variable()都可以创建同名的变量。但是,如果您想要启用变量共享,则必须在使用tf.get_variable()函数时将reuse参数设置为True,并且在使用相同名称的变量时,仅限于在同一作用域内进行共享。如果没有设置reuse=True,则不能在同一作用域内使用tf.get_variable()和tf.Variable()来创建具有相同名称的变量。
原理:
-
TensorFlow中的
变量是指在程序运行时可以进行修改的张量,它们通常用于存储模型参数和其他状态信息。在TensorFlow中,tf.Variable()和tf.get_variable()都可以用来创建变量。 -
tf.Variable()函数是通过调用TensorFlow的ops来创建一个变量节点,这个节点包含了一个初始值,并且允许在训练过程中更新这个值。每次调用tf.Variable()函数都会创建一个新的变量。 -
而
tf.get_variable()函数则是首先检查当前上下文中是否已经存在名字为指定名称的变量,如果已经存在,则返回现有变量;否则,就使用给定的名称和形状创建一个新的变量。因此,tf.get_variable()函数可以用于实现变量共享,并且在同一作用域内调用tf.get_variable()多次不会创建新的变量。 -
当在
同一作用域下同时使用tf.Variable()和tf.get_variable()函数来创建同名的变量时,由于tf.Variable()创建的变量和tf.get_variable()创建的变量并不是同一个变量,因此不能共享。但是,如果您想要启用变量共享,则必须在使用tf.get_variable()函数时将reuse参数设置为True,并且在使用相同名称的变量时,仅限于在同一作用域内进行共享。
5. 解释 这个当前作用域也有说法,等下说
在TensorFlow中,如果在一个variable_scope下定义了一个变量,那么这个变量的名称就会被加上该variable_scope的前缀
例如:
with tf.variable_scope('my_scope'):
x = tf.Variable(1.0, name='x')

我们在变量作用域’my_scope’下定义了一个名称为’x’的变量,实际的变量名为'my_scope/x'。
此时如果:我们再次尝试使用tf.get_variable()函数来获取名称为'x'的变量,并且不指定reuse=True参数,那么TensorFlow就会抛出一个ValueError异常,因为它会认为要创建一个新的变量,而已经存在同名的变量了。
with tf.variable_scope('my_scope'):
# 以下代码会抛出ValueError异常
y = tf.get_variable('x', shape=[2, 2], initializer=tf.constant_initializer(0.0))
6. 重点注意:
变量共享通常通过tf.get_variable()函数的reuse参数来实现,而tf.Variable()函数则用于创建不需要共享的独立变量。- 同一个作用域下,
不要同时出现tf.get_variable()和tf.Variable()