文章目录
- 页的概念
- 可执行文件的虚拟地址
- 二级页表的转换
- 二级页表的优点
页的概念
在聊文件系统时,我提到操作系统是以块为基本单位进行IO的,一个块的大小为4KB,在文件系统中它的名字叫做块,在内存系统中它的名字叫做页,page,假设内存系统大小为4GB,那么该系统中就有2的20次方(4GB/4KB)个页,Linux用struct page描述页的结构体,操作系统对内存系统的管理就变成了对一个大数组(假设数组是struct page mem[1024 * 1024])的管理,该数组含有2的20次方个元素,每个元素保存了页的相关消息。
可执行文件的虚拟地址
一份源代码被编译成为可执行文件时,编译器就已经对其中的数据进行了编址,所以可执行文件中的所有数据都有属于自己的地址,数据会被合理的分配到进程地址空间上。编译好可执行文件后,文件被存储在磁盘上,进入了文件系统,执行该文件时,操作系统将其从文件系统中以4KB为单位地加载到内存系统上,并为其分配对应的页,也就是说通过struct page mem数组 + 下标的方式,我们就可以访问该文件在内存系统中的数据。
现在的问题是,我们有了程序的虚拟地址,要怎么访问内存中的程序?也就是要怎么得到mem数组的下标?其中的转换就是通过页表+MMU共同实现的
二级页表的转换
一个32位的虚拟地址被划分成三份,高10位22-31为一份,我们称之为DIRECTORY;中间的10位12-22为一份,我们称之为TABLE;低12位0-11为一份,我们称之为OFFSET

一个进程始终拥有一级页表,一级页表被称为页目录,虚拟地址的高10位DIRECTORY可以表示1024个表项,所以页目录一共可以存储1K个表项,一级页表可以索引二级页表:DIRECTORY在一级页表中映射的数据是页表项,页表项是二级页表的地址。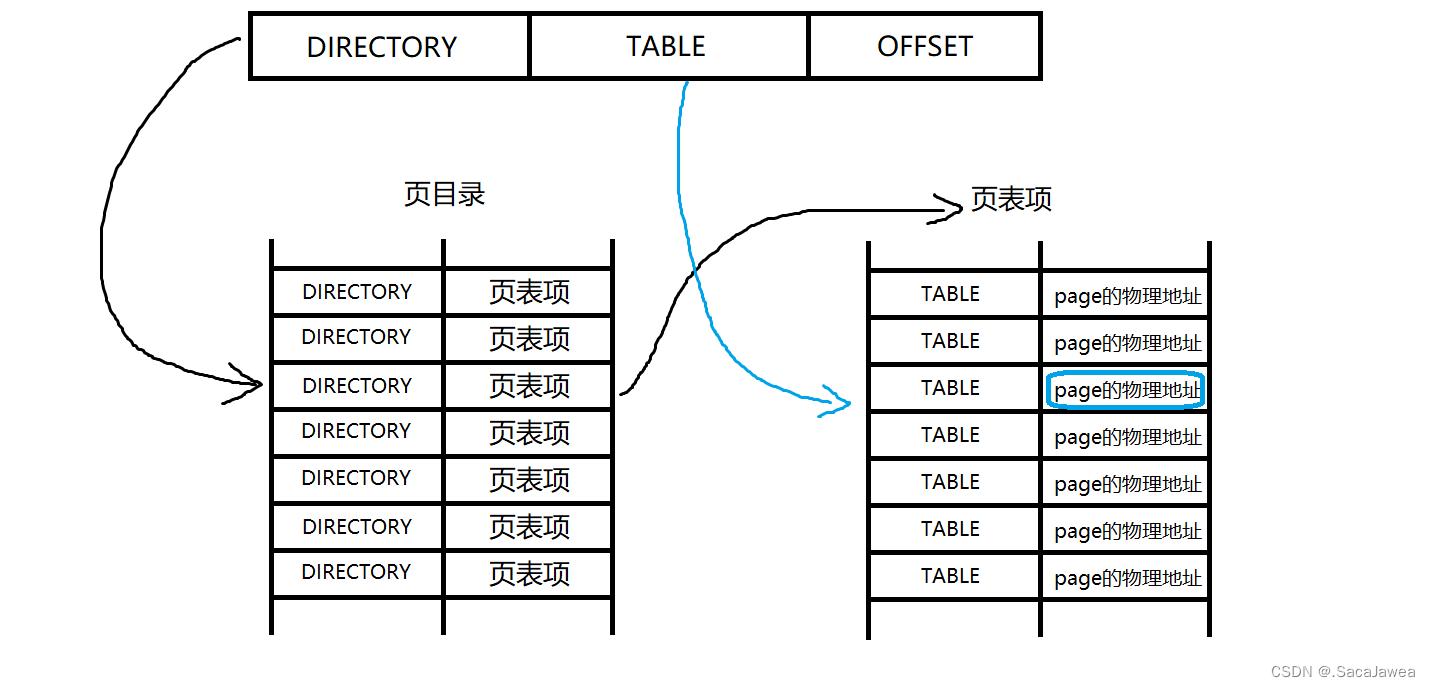
二级页表用来索引page的物理地址,也就是mem数组中的下标。二级页表也有1K个表项,因为TABLE有10位。系统由虚拟地址的TABLE在二级页表中查找page的物理地址。
找到page的物理地址后,就系统就能访问整块page,但page的大小为4K,系统要访问page的哪些数据?虚拟地址的低12位OFFSET覆盖了一个page的所有地址,所以用OFFSET就可以向系统表明要访问页的具体地址,OFFSET被称为页内偏移量,通过这个偏移量我们就能找到需要的地址。
二级页表的优点
假设页表不采用分级的方式设计,将进程地址空间上的虚拟page地址与物理空间的真实page地址直接进行映射,那么这个页表将占用非常大的内存,创建一个进程的代价也就随之升高,甚至会出现内存不够使用的情况。
采用分级的方式设计页表,此时每个进程只需要有一张一级页表,即页目录,页目录占用较少的内存(1K个表项,总大小也不会过大)。当需要访问内存上的数据时,系统先通过页目录索引到页表项,再通过页表项找到page页。
但是一个页目录映射了1K个页表项,操作系统根本没有必要将所有的页表项映射,如果将所有的页表项映射,那么这些页表占用的空间也是十分大的。一个页表项映射了1K个page页,操作系统也没有必要映射所有的页,当操作系统一开始加载程序时,就没有必要加载所有的页表,当需要使用页表时在建立页表,这样使得页表的创建与销毁的代价减少,提高了系统的性能。
比如现在有一个进程需要访问数据,操作系统通过虚拟地址的DIRECTORY知道了页表项的地址,但是页表项还没有被创建,此时操作系统才会访问磁盘中的数据,重新建立页表项。同理,对于page地址也是如此,操作系统不会把所有的page加载到内存中,只有在进程需要访问时才会进行加载
所以使用分级页表可以实现按需创建页表, 每个进程只有页目录,第二级页表与page没有必要全部加载,只需要加载一部分的页表,当需要访问的页表没有被创建时再创建,这样的做法有效的减少了进程的内存消耗。
节省空间是分级页表的一大优点,除此之外分级页表还有一优点:将进程的虚拟地址管理与内存物理地址的管理进行解耦,怎么理解呢?操作系统只需要关心页表中的表项是否存在,是否需要加载,如果表项为NULL,即出现越界访问,MMU硬件异常,产生中断,操作系统接收中断后终止非法访问内存的进程。如果表项存在,操作系统只需要继续索引得到page地址,所以,虽然是虚拟地址与物理地址之间的转换,但操作系统只需要关心虚拟地址在页表中的映射关系,两个地址间的转换就这样被页表这个软件结构解耦了。

![[附源码]计算机毕业设计基于SpringBoot的校园报修平台](https://img-blog.csdnimg.cn/4db374525d9f4ba593911464638dc7e7.png)
![[附源码]Python计算机毕业设计Django人员信息管理](https://img-blog.csdnimg.cn/e965403684be41da973c2f2958a79c77.png)