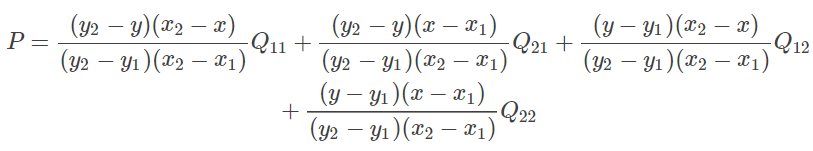目录
一.Bleu得分
二.注意力模型直观理解
三.注意力模型
四.语音识别
五.触发字检测
一.Bleu得分
先跳过,等回头用得到了再来补。
二.注意力模型直观理解
在本周大部分时间中,你都在使用这个编码解码的构架(a Encoder-Decoder architecture)来完成机器翻译。当你使用RNN读一个句子,于是另一个会输出一个句子。我们要对其做一些改变,称为注意力模型(the Attention Model),并且这会使它工作得更好。注意力模型或者说注意力这种思想(The attention algorithm, the attention idea)已经是深度学习中最重要的思想之一,我们看看它是怎么运作的。
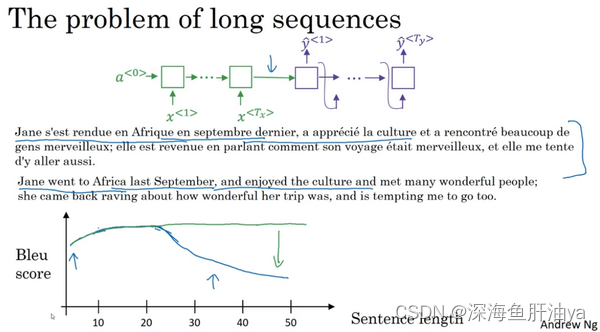
像这样给定一个很长的法语句子,在你的神经网络中,这个绿色的编码器要做的就是读整个句子,然后记忆整个句子,再在感知机中传递(to read in the whole sentence and then memorize the whole sentences and store it in the activations conveyed her)。而对于这个紫色的神经网络,即解码网络(the decoder network)将生成英文翻译,Jane去年九月去了非洲,非常享受非洲文化,遇到了很多奇妙的人,她回来就嚷嚷道,她经历了一个多棒的旅行,并邀请我也一起去。人工翻译并不会通过读整个法语句子,再记忆里面的东西,然后从零开始,机械式地翻译成一个英语句子。而人工翻译,首先会做的可能是先翻译出句子的部分,再看下一部分,并翻译这一部分。看一部分,翻译一部分,一直这样下去。你会通过句子,一点一点地翻译,因为记忆整个的像这样的的句子是非常困难的。你在下面这个编码解码结构中,会看到它对于短句子效果非常好,于是它会有一个相对高的Bleu分(Bleu score),但是对于长句子而言,比如说大于30或者40词的句子,它的表现就会变差。Bleu评分看起来就会像是这样,随着单词数量变化,短的句子会难以翻译,因为很难得到所有词。对于长的句子,效果也不好,因为在神经网络中,记忆非常长句子是非常困难的。在这个和下个视频中,你会见识到注意力模型,它翻译得很像人类,一次翻译句子的一部分。而且有了注意力模型,机器翻译系统的表现会像这个一样,因为翻译只会翻译句子的一部分,你不会看到这个有一个巨大的下倾(huge dip),这个下倾实际上衡量了神经网络记忆一个长句子的能力,这是我们不希望神经网络去做的事情。在这个视频中,我想要给你们注意力机制运行的一些直观的东西。然后在下个视频中,完善细节。
注意力模型源于Dimitri, Bahdanau, Camcrun Cho, Yoshe Bengio。(Bahdanau D, Cho K, Bengio Y. Neural Machine Translation by Jointly Learning to Align and Translate[J]. Computer Science,2014.)虽然这个模型源于机器翻译,但它也推广到了其他应用领域。我认为在深度学习领域,这个是个非常有影响力的,非常具有开创性的论文。
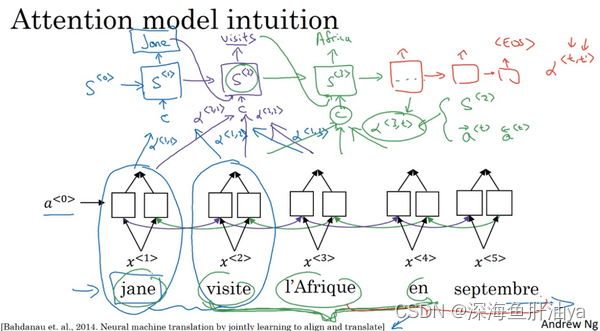
让我们用一个短句举例说明一下,即使这些思想可能是应用于更长的句子。但是用短句来举例说明,讲解这些思想会更简单。我们有一个很平常的句子:(法语)Jane visite l'Afrique en Septembre。假定我们使用RNN,在这个情况中,我们将使用一个双向的RNN(a bidirectional RNN),为了计算每个输入单词的的特征集(set of features),你必须要理解输出yhat^<1>
到yhat^<3>一直到yhat^<5>的双向RNN。但是我们并不是只翻译一个单词,让我们先去掉上面的Y,就用双向的RNN。我们要对单词做的就是,对于句子里的每五个单词,计算一个句子中单词的特征集,也有可能是周围的词,让我们试试,生成英文翻译。我们将使用另一个RNN生成英文翻译,这是我平时用的RNN记号。我不用A来表示感知机(the activation),这是为了避免和这里的感知机(the activations)混淆。我会用另一个不同的记号,我会用S来表示RNN的隐藏状态(the hidden state in this RNN),不用A^<1>,而是用S^<1>。我们希望在这个模型里第一个生成的单词将会是Jane,为了生成Jane visits Africa in September。于是等式就是,当你尝试生成第一个词,即输出,那么我们应该看输入的法语句子的哪个部分?似乎你应该先看第一个单词,或者它附近的词。但是你别看太远了,比如说看到句尾去了。所以注意力模型就会计算注意力权重(a set of attention weights),我们将用a^<1,1>来表示当你生成第一个词时你应该放多少注意力在这个第一块信息处。然后我们算第二个,这个叫注意力权重,a^<1,2>它告诉我们当你尝试去计算第一个词Jane时,我们应该花多少注意力在输入的第二个词上面。同理这里是a^<1,3>,接下去也同理。这些将会告诉我们,我们应该花多少注意力在记号为的内容上。这就是RNN的一个单元,如何尝试生成第一个词的,这是RNN的其中一步,我们将会在下个视频中讲解细节。对于RNN的第二步,我们将有一个新的隐藏状态S^<2>,我们也会用一个新的注意力权值集(a new set of the attention weights),我们将用a^<2,1>来告诉我们什么时候生成第二个词, 那么visits就会是第二个标签了(the ground trip label)。我们应该花多少注意力在输入的第一个法语词上。然后同理a^<2,2>,接下去也同理,我们应该花多少注意力在visite词上,我们应该花多少注意在词l'Afique上面。当然我们第一个生成的词Jane也会输入到这里,于是我们就有了需要花注意力的上下文。第二步,这也是个输入,然后会一起生成第二个词,这会让我们来到第三步S^<3>,这是输入,我们再有上下文C,它取决于在不同的时间集(time sets),上面的a^<3>。这个告诉了我们我们要花注意力在不同的法语的输入词上面。 然后同理。有些事情我还没说清楚,但是在下个视频中,我会讲解一些细节,比如如何准确定义上下文,还有第三个词的上下文,是否真的需要去注意句子中的周围的词。这里要用到的公式以及如何计算这些注意力权重(these attention weights),将会在下个视频中讲解到。在下个视频中你会看到a^<3,t>,即当你尝试去生成第三个词,应该是l'Afique,就得到了右边这个输出,这个RNN步骤应该要花注意力在t时的法语词上,这取决于在t时的双向RNN的激活值。那么它应该是取决于第四个激活值,它会取决于上一步的状态,它会取决于S^<2>。然后这些一起影响你应该花多少注意在输入的法语句子的某个词上面。我们会在下个视频中讲解这些细节。但是直观来想就是RNN向前进一次生成一个词,在每一步直到最终生成可能是<EOS>。这些是注意力权重,即a^<t,t>告诉你,当你尝试生成第t个英文词,它应该花多少注意力在第t个法语词上面。当生成一个特定的英文词时,这允许它在每个时间步去看周围词距内的法语词要花多少注意力。
我希望这个视频传递了关于注意力模型的一些直观的东西。我们现在可能对算法的运行有了大概的感觉,让我们进入到下个视频中,看看具体的细节。
三.注意力模型
在上个视频中你已经见到了,注意力模型如何让一个神经网络只注意到一部分的输入句子。当它在生成句子的时候,更像人类翻译。让我们把这些想法转化成确切的式子,来实现注意力模型。
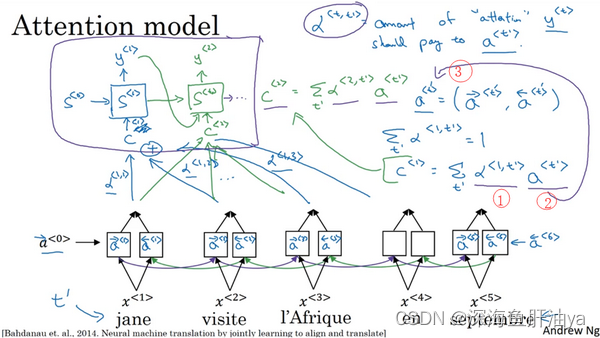


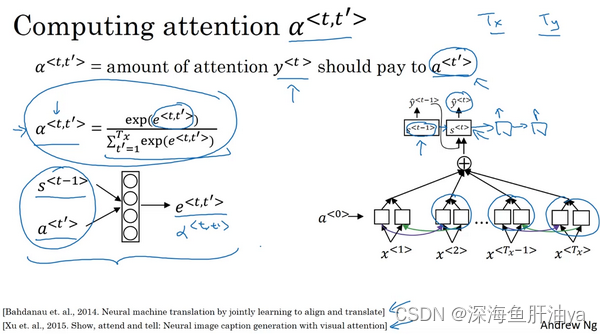


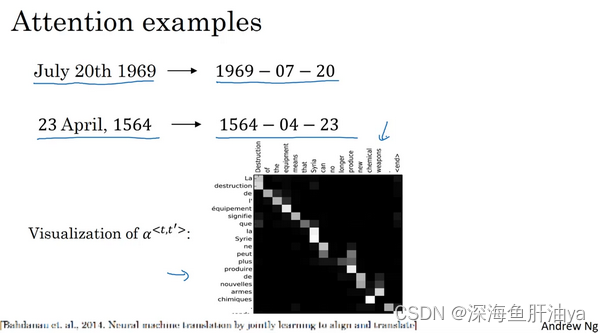
因为机器翻译是一个非常复杂的问题,在之前的练习中,你应用了注意力,在日期标准化的问题(the date normalization problem)上面,问题输入了像这样的一个日期,这个日期实际上是阿波罗登月的日期,把它标准化成标准的形式,或者这样的日期。用一个序列的神经网络,即序列模型去标准化到这样的形式,这个日期实际上是威廉·莎士比亚的生日。一般认为是这个日期正如你之前联系中见到的,你可以训练一个神经网络,输入任何形式的日期,生成标准化的日期形式。其他可以做的有意思的事情是看看可视化的注意力权重(the visualizations of the attention weights)。这个一个机器翻译的例子,这里被画上了不同的颜色,不同注意力权重的大小,我不想在这上面花太多时间,但是你可以发现,对应的输入输出词,你会发现注意力权重,会变高,因此这显示了当它生成特定的输出词时通常会花注意力在输入的正确的词上面,包括学习花注意在哪。 在注意力模型中,使用反向传播时, 什么时候学习完成。
这就是注意力模型,在深度学习中真的是个非常强大的想法。在本周的编程练习中,我希望你可以享受自己应用它的过程。
四.语音识别
五.触发字检测
这俩部分也先跳过吧,用得到再来学。
![[附源码]计算机毕业设计基于SpringBoot的校园报修平台](https://img-blog.csdnimg.cn/4db374525d9f4ba593911464638dc7e7.png)
![[附源码]Python计算机毕业设计Django人员信息管理](https://img-blog.csdnimg.cn/e965403684be41da973c2f2958a79c77.png)