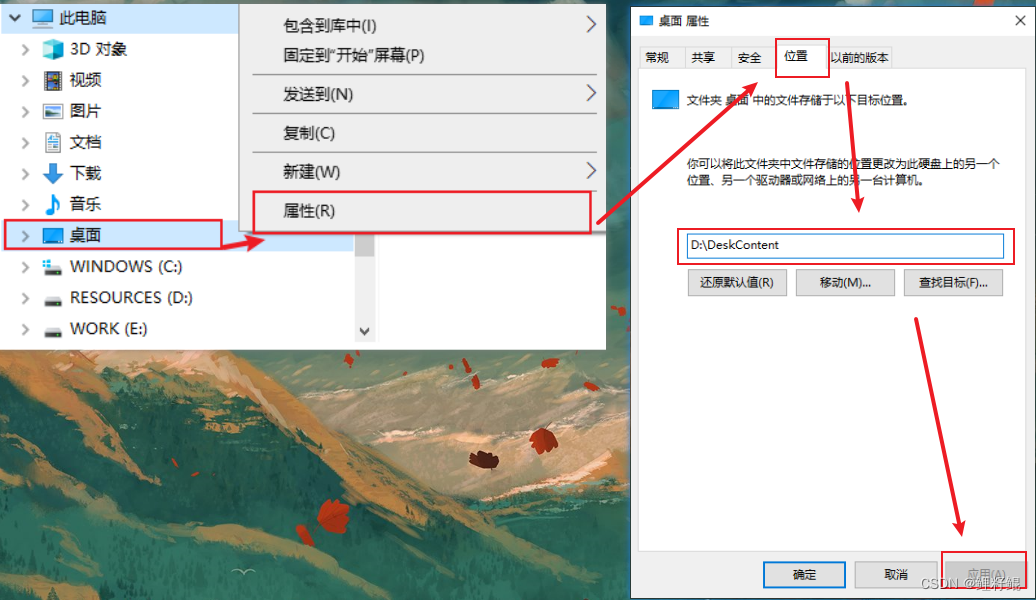
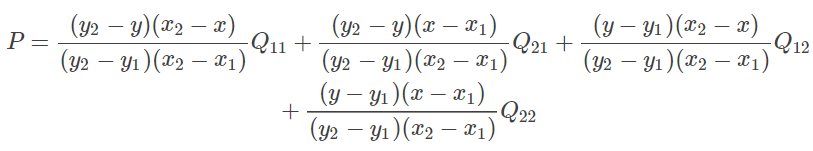觉得有帮助请点赞关注收藏~~~
1.1 自然语言处理
1.1.1 自然语言处理主要研究对象 自然语言处理(Natural Language Processing:NLP)是以人类社会的语言信息(比如语音和文本)为主要研究对象,利用计算机技术来理解、分析和处理语言的一门新兴综合性学科,最终目标是突破人类与计算机的交流瓶颈,提升人机沟通的速度和效率。
1.1.2 自然语言处理分类
广义:
自然语言理解(Natural Language Understanding:NLU)
自然语言生成(Natural Language Generation:NLG)
狭义:
分词(Tokenization)
词性标注(Part of Speech)
句法分析(Syntax Parsing)
文本挖掘(Text Mining)
语音识别(Speech Recognition)
手写字体识别(Handwriting Text Recognition)
舆情分析(Public Opinion Analysis)
问答系统(Question-and-Answer System)等等
1.1.3 自然语言处理面临的挑战
迄今为止研究多聚焦于分析简单孤立的句子和短语,缺乏对上下文复杂语境和前后关联语境的系统性研究,对多义性、词语省略等问题,尚未形成规律性、普适性应用成果。 人们理解语言时不限于语法结构和词语的字面涵义,无法简单整合形成统一标准并直接统一应用于实际自然语言分析处理中
1.1.4 自然语言处理重要术语
词向量
词是自然语言处理的对象之一,也是语义表达的基本单位,词向量是将词语进行数值化或者向量化表达的简称,目前词向量表达方式有离散式和分布式两种
相关度
即计算文本信息与文本信息间的距离,距离通过数值体现,主要用于反映语义之间的相关度
1:余弦相关度
公式如下
计算出来越接近1则文本越相近,反之差别越大
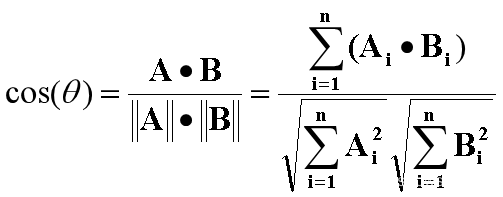
2:欧几里得距离
欧几里得距离越小,则两个向量之间的相关度越高

语义消歧
信息抽取
无监督学习
有监督学习
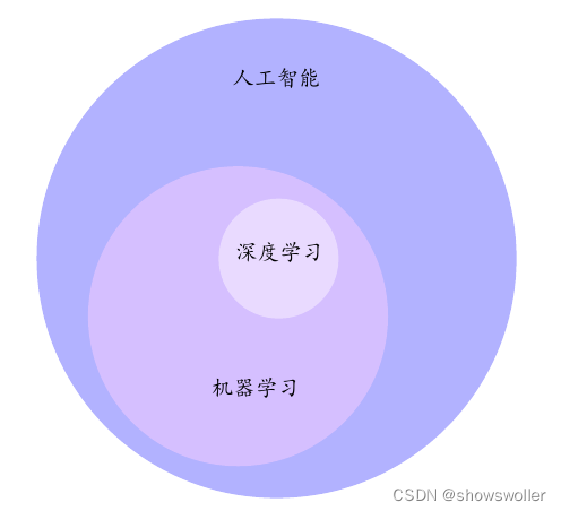
人工智能
机器学习
深度学习
不同概念之间包含关系如下图
创作不易 觉得有帮助请点赞关注收藏~~~