C++线程 并发编程:std::thread、std::sync与std::packaged_task深度解析
- 1. C++并发编程概述(C++ Concurrency Overview)
- 1.1 并发与并行的区别(Difference between Concurrency and Parallelism)
- 1.2 C++中的线程模型(Thread Model in C++)
- 1.3 C++11/14/17/20中并发编程的发展(Development of Concurrency Programming in C++11/14/17/20)
- C++11
- C++14
- C++17
- C++20
- 2. std::thread详解(Detailed Explanation of std::thread)
- 2.1 std::thread的基本使用(Basic Usage of std::thread)
- 2.2 std::thread的性能分析(Performance Analysis of std::thread)
- 2.3 std::thread的适用场景(Applicable Scenarios of std::thread)
- 3. std::sync深度探讨(Deep Discussion on std::sync)
- 3.1 std::sync的基本概念与使用(Basic Concepts and Usage of std::sync)
- 3.1.1 同步与互斥(Synchronization and Mutual Exclusion)
- 3.1.2 std::sync的主要组件(Main Components of std::sync)
- 3.1.3 使用std::sync的基本步骤(Basic Steps of Using std::sync)
- 3.2 std::sync的性能权衡(Performance Trade-offs of std::sync)
- 3.2.1 锁的开销(Lock Overhead)
- 3.2.2 条件变量的开销(Condition Variable Overhead)
- 3.2.3 锁管理器的开销(Lock Manager Overhead)
- 3.3 std::sync的适用场景(Applicable Scenarios of std::sync)
- 3.3.1 保护共享数据(Protecting Shared Data)
- 3.3.2 线程间的同步(Synchronization Between Threads)
- 3.3.3 确保某个操作只执行一次(Ensuring an Operation is Performed Only Once)
- 4. std::packaged_task全面解析(Comprehensive Analysis of std::packaged_task)
- 4.1 std::packaged_task的基本使用(Basic Usage of std::packaged_task)
- 4.2 std::packaged_task的性能差异(Performance Differences of std::packaged_task)
- 4.3 std::packaged_task的适用场景(Applicable Scenarios of std::packaged_task)
- 5. std::thread、std::sync与std::packaged_task的比较
- 5.1 功能比较
- std::thread(线程)
- std::sync(同步)
- std::packaged_task(任务包)
- 5.2 性能比较
- std::thread(线程)
- std::sync(同步)
- std::packaged_task(任务包)
- 5.3 使用场景比较
- std::thread(线程)
- std::sync(同步)
- std::packaged_task(任务包)
- 6. 结论与展望(Conclusion and Outlook)
- 6.1 选择合适的并发编程工具(Choosing the Right Concurrency Programming Tool)
- 6.2 C++并发编程的未来发展(Future Development of C++ Concurrency Programming)
- 6.3 结语(Conclusion)
1. C++并发编程概述(C++ Concurrency Overview)
1.1 并发与并行的区别(Difference between Concurrency and Parallelism)
在我们深入探讨C++的并发编程之前,首先需要理解两个基本概念:并发(Concurrency)和并行(Parallelism)。这两个概念在日常语言中经常被混淆使用,但在计算机科学中,它们有着明确的定义和区别。
并发(Concurrency)是指两个或更多的任务可以在重叠的时间段内启动、运行和完成。并发并不意味着这些任务真正地“同时”运行。在单核CPU系统中,虽然在任何给定的时间点只有一个任务在执行,但由于任务之间的切换快速进行,使得它们看起来像是同时运行。这种现象就是并发。
并行(Parallelism)则是指两个或更多的任务在同一时刻运行。在多核或多处理器的系统中,可以有多个任务在不同的处理器上同时执行。这就是真正的并行。
从心理学的角度来看,我们可以将并发和并行比作一个人同时处理多个任务。如果一个人在做饭的同时还在听音乐,那么这就是并发,因为他在同一段时间内进行了两个任务,但并不是真正的同时。他可能在切菜的时候听音乐,在翻炒的时候暂停音乐。而如果一个人在做饭的同时,他的朋友在旁边洗碗,那么这就是并行,因为两个任务在同一时刻真正地同时进行。
在C++并发编程中,理解并发和并行的区别是非常重要的,因为它们对应了不同的编程模型和技术。在接下来的章节中,我们将深入探讨C++中的并发编程工具,如std::thread、std::sync和std::packaged_task,并分析它们的性能和适用场景。
1.2 C++中的线程模型(Thread Model in C++)
在C++中,线程(Thread)是并发执行的基本单位。一个程序中可以有多个线程,每个线程有自己的执行路径,这些线程可以并发地执行。
在C++11之前,C++标准库并没有提供线程支持,开发者需要依赖于操作系统提供的API(如Windows的CreateThread函数或者POSIX的pthread_create函数)来创建和管理线程。这种方式的问题在于,不同的操作系统提供的线程API可能会有所不同,这就导致了代码的可移植性问题。
C++11标准引入了线程库,包括std::thread类,以及一系列与线程相关的函数和类,如std::mutex、std::lock_guard、std::unique_lock、std::condition_variable等。这些工具提供了一种跨平台的方式来创建和管理线程,大大提高了代码的可移植性。
在C++的线程模型中,每个线程都有一个唯一的标识符,可以通过std::thread::get_id()函数获取。线程可以被创建为可分离(detached)或非分离(joinable)的。一个可分离的线程在完成其任务后会自动清理其资源,而一个非分离的线程则需要在其他线程中通过调用std::thread::join()函数来等待其完成并清理其资源。
C++线程模型的一个重要特性是,线程之间的执行顺序是不确定的,这就引入了线程同步的问题。为了解决这个问题,C++提供了一系列同步工具,如互斥量(Mutex)、条件变量(Condition Variable)、future和promise等。在后续的章节中,我们将详细介绍这些工具的使用和性能分析。
1.3 C++11/14/17/20中并发编程的发展(Development of Concurrency Programming in C++11/14/17/20)
C++的并发编程在C++11/14/17/20的各个版本中都有所发展和改进。下面我们将分别介绍这些版本中并发编程的主要特性和改进。
C++11
C++11是C++并发编程的一个重要里程碑,它首次在标准库中引入了线程支持。C++11提供了std::thread类来创建和管理线程,提供了std::mutex和std::lock_guard等工具来进行线程同步,提供了std::future和std::promise等工具来进行异步编程。
C++14
C++14对C++11中的并发编程进行了一些改进和扩展。例如,它引入了std::shared_timed_mutex类,这是一个允许多个读者线程同时访问的互斥量,但只允许一个写者线程访问。
C++17
C++17进一步扩展了并发编程的功能。它引入了std::shared_mutex类,这是一个不带超时功能的共享互斥量,比std::shared_timed_mutex更简单。此外,C++17还引入了并行算法,这是一组可以利用多线程进行并行执行的STL算法。
C++20
C++20在并发编程方面的主要改进是引入了协程(Coroutine)。协程是一种可以在任何位置暂停和恢复执行的函数,它可以用于简化异步编程和生成器等复杂的控制流。
以上就是C++11/14/17/20中并发编程的主要发展和改进。在接下来的章节中,我们将深入探讨C++中的并发编程工具,如std::thread、std::sync和std::packaged_task,并分析它们的性能和适用场景。
2. std::thread详解(Detailed Explanation of std::thread)
2.1 std::thread的基本使用(Basic Usage of std::thread)
在C++中,std::thread(标准线程)是C++11引入的一个库,用于表示单个执行线程。它提供了一种面向对象的方式来处理线程,使得线程的创建和管理变得更加简单。
创建std::thread(标准线程)的基本方式如下:
#include <iostream>
#include <thread>
void thread_function()
{
std::cout << "Hello from thread\n";
}
int main()
{
std::thread t(thread_function);
t.join();
return 0;
}
在这个例子中,我们首先定义了一个函数thread_function,然后在main函数中创建了一个新的线程t,并将thread_function作为线程的入口点。最后,我们调用t.join()来等待线程完成执行。
这里有几个关键的概念需要理解:
-
线程入口点(Thread Entry Point):这是线程开始执行的函数。在上述例子中,
thread_function就是线程的入口点。 -
线程对象(Thread Object):
std::thread对象代表一个线程。在上述例子中,t就是一个线程对象。 -
线程的创建(Thread Creation):通过构造
std::thread对象并传入线程入口点,可以创建一个新的线程。 -
线程的等待(Thread Waiting):
std::thread::join函数用于等待线程完成执行。如果不等待线程完成,那么线程可能会在其生命周期未结束时被销毁,这可能会导致未定义的行为。
在理解了std::thread的基本使用后,我们可以开始探索其更深层次的功能,如线程的参数传递、线程的移动语义等。这些将在后续的小节中详细介绍。
2.2 std::thread的性能分析(Performance Analysis of std::thread)
在C++中,std::thread(标准线程)的性能主要受以下几个因素影响:
-
线程创建和销毁的开销(Overhead of Thread Creation and Destruction):每次创建或销毁线程都会带来一定的开销。这是因为操作系统需要为每个线程分配和回收资源,如栈空间、线程局部存储等。因此,频繁地创建和销毁线程可能会导致性能下降。
-
线程切换的开销(Overhead of Thread Switching):操作系统通过线程调度器来管理多个线程的执行。当一个线程的执行被暂停,另一个线程被唤醒时,就会发生线程切换。线程切换会带来一定的开销,因为需要保存和恢复线程的执行环境。
-
线程同步的开销(Overhead of Thread Synchronization):在多线程环境中,通常需要使用同步机制(如互斥锁、条件变量等)来协调线程的执行。这些同步操作也会带来一定的开销。
为了减少这些开销,我们可以采取以下策略:
-
线程池(Thread Pool):通过预先创建一定数量的线程,并重复使用这些线程,可以减少线程创建和销毁的开销。
-
减少线程切换(Reduce Thread Switching):通过合理地设计程序,减少不必要的线程切换,可以提高性能。
-
减少锁的使用(Reduce Lock Usage):通过使用无锁数据结构或者减少锁的粒度,可以减少线程同步的开销。
2.3 std::thread的适用场景(Applicable Scenarios of std::thread)
std::thread(标准线程)作为C++的基础线程库,其适用场景非常广泛。以下是一些常见的使用std::thread的场景:
-
计算密集型任务(Compute-intensive Tasks):对于需要大量计算的任务,我们可以使用多线程来并行执行计算,以提高程序的运行速度。例如,我们可以将一个大的数组分割成多个小的数组,然后创建多个线程,每个线程处理一个小数组的计算。
-
I/O密集型任务(I/O-intensive Tasks):对于I/O密集型任务,如网络请求、文件读写等,我们也可以使用多线程来提高效率。当一个线程在等待I/O操作完成时,其他线程可以继续执行,从而提高整体的运行速度。
-
图形用户界面(Graphical User Interface):在图形用户界面中,我们通常会使用一个单独的线程来处理用户的输入,而其他的线程则用于执行后台任务。这样可以保证用户界面的响应性,避免因后台任务的执行而导致界面卡顿。
-
服务器编程(Server Programming):在服务器编程中,我们通常会为每个客户端连接创建一个新的线程。这样可以保证服务器能够同时处理多个客户端的请求。
需要注意的是,虽然多线程可以提高程序的效率,但也会带来一些复杂性,如线程同步、数据竞争等问题。因此,在使用std::thread时,我们需要仔细设计程序,以确保线程的正确性和效率。
3. std::sync深度探讨(Deep Discussion on std::sync)
3.1 std::sync的基本概念与使用(Basic Concepts and Usage of std::sync)
在C++中,std::sync是一个非常重要的并发编程工具,它主要用于同步线程的执行。在深入了解std::sync的使用之前,我们首先需要理解一些基本的概念。
3.1.1 同步与互斥(Synchronization and Mutual Exclusion)
在并发编程中,同步(Synchronization)和互斥(Mutual Exclusion)是两个非常重要的概念。同步是指在程序中协调多个线程的执行顺序,而互斥则是确保同一时间只有一个线程能访问共享资源。std::sync提供了一系列的工具,如互斥锁(Mutex)、条件变量(Condition Variable)等,用于实现这些功能。
3.1.2 std::sync的主要组件(Main Components of std::sync)
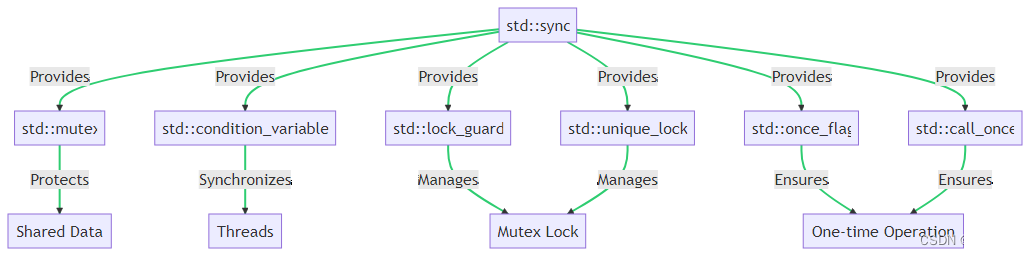
std::sync主要包括以下几个组件:
std::mutex:互斥锁,用于保护共享数据,防止多个线程同时访问。std::condition_variable:条件变量,用于实现线程间的同步。std::lock_guard和std::unique_lock:锁管理器,用于自动管理锁的生命周期。std::once_flag和std::call_once:用于保证某个操作只执行一次。
3.1.3 使用std::sync的基本步骤(Basic Steps of Using std::sync)
使用std::sync进行线程同步的基本步骤如下:
- 定义互斥锁和共享数据。
- 在需要访问共享数据的线程中,通过锁管理器获取锁。
- 访问共享数据。
- 锁管理器在作用域结束时自动释放锁。
下面我们通过一个简单的例子来说明std::sync的使用:
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mtx; // 全局互斥锁
int count = 0; // 共享数据
void increase() {
for (int i = 0; i < 10000; ++i) {
std::lock_guard<std::mutex> lock(mtx); // 获取锁
++count; // 访问共享数据
} // 锁在lock_guard析构时自动释放
}
int main() {
std::thread t1(increase);
std::thread t2(increase);
t1.join();
t2.join();
std::cout << "count = " << count << std::endl; // 输出:count = 20000
return 0;
}
在这个例子中,我们定义了一个全局互斥锁mtx和一个共享数据count。然后创建了两个线程t1和t2,它们都会调用increase函数,该函数会对count进行增加操作。为了保证在增加操作时不会发生数据竞争,我们在increase函数中使用了std::lock_guard来获取锁,然后进行增加操作。当increase函数执行完毕,std::lock_guard会自动析构,从而释放锁。
通过这个例子,我们可以看到std::sync提供的工具在实际使用中是非常方便的。它们不仅可以帮助我们实现线程同步,还可以自动管理锁的生命周期,避免了因忘记释放锁而导致的死锁问题。
然而,std::sync并不是万能的。在某些情况下,使用std::sync可能会带来一些性能开销。例如,频繁地获取和释放锁可能会导致线程频繁地进行上下文切换,从而降低程序的性能。因此,在使用std::sync时,我们需要根据实际情况进行权衡,选择最适合的工具和方法。
3.2 std::sync的性能权衡(Performance Trade-offs of std::sync)
在并发编程中,性能是一个非常重要的考量因素。虽然std::sync提供了一系列方便的工具来帮助我们实现线程同步,但在某些情况下,使用它们可能会带来一些性能开销。在这一节中,我们将深入探讨std::sync的性能权衡。
首先,让我们通过下面的图表来了解std::sync的主要组件及其功能:
3.2.1 锁的开销(Lock Overhead)
在std::sync中,std::mutex是一个非常基础且重要的工具,它用于保护共享数据,防止多个线程同时访问。然而,获取和释放锁是有开销的。当我们频繁地获取和释放锁时,可能会导致线程频繁地进行上下文切换,从而降低程序的性能。因此,我们需要尽量减少锁的使用,或者尽量减少锁的持有时间。
3.2.2 条件变量的开销(Condition Variable Overhead)
std::condition_variable是另一个重要的工具,它用于实现线程间的同步。然而,使用条件变量也是有开销的。当一个线程在等待条件变量时,它会被阻塞,直到另一个线程通知它。这会导致线程的上下文切换,从而降低程序的性能。因此,我们需要尽量减少条件变量的使用,或者尽量减少线程的等待时间。
3.2.3 锁管理器的开销(Lock Manager Overhead)
std::lock_guard和std::unique_lock是两个锁管理器,它们用于自动管理锁的生命周期。虽然这些工具可以帮助我们避免因忘记释放锁而导致的死锁问题,但它们也是有开销的。当我们频繁地创建和销毁锁管理器时,可能会导致内存的频繁分配和释放,从而降低程序的性能。因此,我们需要尽量减少锁管理器的使用,或者尽量减少锁管理器的创建和销毁次数。
在下一节中,我们将探讨std::sync的适用场景,以帮助我们更好地理解如何在实际编程中使用这些工具,并根据具体情况进行性能权衡。
3.3 std::sync的适用场景(Applicable Scenarios of std::sync)
std::sync提供的工具在多种场景下都能发挥重要作用。下面我们将探讨一些常见的适用场景。
3.3.1 保护共享数据(Protecting Shared Data)
当多个线程需要访问同一份共享数据时,我们需要确保在任何时刻只有一个线程能够访问这份数据,以防止数据竞争。在这种情况下,我们可以使用std::mutex来保护共享数据。通过获取互斥锁,线程可以安全地访问共享数据,而不用担心其他线程会同时修改这份数据。
3.3.2 线程间的同步(Synchronization Between Threads)
在某些情况下,我们可能需要让一个线程等待另一个线程完成某个操作。例如,我们可能有一个生产者线程和一个消费者线程,消费者线程需要等待生产者线程生产出数据后才能开始消费。在这种情况下,我们可以使用std::condition_variable来实现线程间的同步。
3.3.3 确保某个操作只执行一次(Ensuring an Operation is Performed Only Once)
在某些情况下,我们可能需要确保某个操作只执行一次。例如,我们可能需要初始化一个全局变量,但我们只希望这个初始化操作在程序运行过程中执行一次。在这种情况下,我们可以使用std::once_flag和std::call_once来确保操作只执行一次。
在实际编程中,我们可能会遇到更多的场景,需要根据具体情况选择合适的工具。在下一章节中,我们将详细介绍std::packaged_task的使用。
4. std::packaged_task全面解析(Comprehensive Analysis of std::packaged_task)
4.1 std::packaged_task的基本使用(Basic Usage of std::packaged_task)
std::packaged_task是C++11引入的一个非常有用的并发编程工具。它是一个通用的可调用对象包装器,这意味着它可以存储任何可以调用的目标——函数、lambda表达式、bind表达式,或者其他函数对象,只要它们的参数列表匹配,就可以被std::packaged_task包装。
std::packaged_task的主要作用是将任务(函数或可调用对象)与一个std::future关联起来。当packaged_task对象被调用时,它内部存储的任务就会被执行,并且结果(如果有的话)会存储为与之关联的std::future对象的共享状态。这样,其他线程就可以通过这个std::future对象来获取任务的结果。
下面是一个简单的std::packaged_task的使用例子:
#include <iostream>
#include <future>
#include <thread>
int calculate() { return 2 * 2; }
int main() {
std::packaged_task<int()> task(calculate);
std::future<int> result = task.get_future();
std::thread task_td(std::move(task));
task_td.join();
std::cout << "calculated: " << result.get() << '\n';
return 0;
}
在这个例子中,我们创建了一个std::packaged_task对象,它包装了一个名为calculate的函数。然后,我们从packaged_task对象中获取一个std::future对象,这个future对象将在将来用于获取calculate函数的结果。然后,我们创建一个新的线程,将packaged_task对象移动到新线程中,并在新线程中执行它。最后,我们通过调用future对象的get()方法来获取calculate函数的结果。
这个例子展示了std::packaged_task的基本使用方法,但实际上,std::packaged_task的用途远不止于此。在接下来的部分,我们将深入探讨std::packaged_task的更多功能和性能特性。
4.2 std::packaged_task的性能差异(Performance Differences of std::packaged_task)
在C++并发编程中,性能是一个重要的考量因素。std::packaged_task作为一个强大的工具,其性能特性值得我们深入探讨。
首先,我们需要明白,std::packaged_task的性能主要受到两个因素的影响:任务的执行时间和线程管理的开销。
任务的执行时间是由我们包装到std::packaged_task中的函数或可调用对象决定的。这个时间取决于我们的代码的效率,以及我们的硬件资源(如CPU速度)。这部分的性能优化主要依赖于我们的编程技巧和硬件配置,与std::packaged_task本身关系不大。
线程管理的开销则是std::packaged_task的性能的一个重要部分。当我们创建一个std::packaged_task,并将其放入一个新的线程中执行时,我们需要为这个新线程付出一定的开销。这个开销包括创建线程、切换线程和销毁线程的时间。在大多数情况下,这个开销是相对较小的,但是在一些高性能的应用场景中,这个开销可能会成为一个瓶颈。
为了减少线程管理的开销,我们可以使用线程池来管理我们的线程。线程池可以复用已经创建的线程,避免频繁地创建和销毁线程。当我们有一个新的std::packaged_task需要执行时,我们可以直接将其放入线程池中,而不是每次都创建一个新的线程。
此外,我们还可以通过合理地设计我们的并发模型,来进一步提高std::packaged_task的性能。例如,我们可以尽量减少线程间的同步操作,避免线程间的数据竞争,以及合理地分配任务,使得各个线程的负载均衡。
总的来说,std::packaged_task的性能优化是一个涉及到多个方面的问题,需要我们从任务的执行时间、线程管理的开销、并发模型设计等多个角度来考虑。
4.3 std::packaged_task的适用场景(Applicable Scenarios of std::packaged_task)
std::packaged_task作为C++并发编程中的一个重要工具,其适用场景非常广泛。以下是一些常见的使用std::packaged_task的场景:
-
异步任务执行(Asynchronous Task Execution):std::packaged_task最常见的用途就是执行异步任务。我们可以将一个函数或可调用对象包装到std::packaged_task中,然后将其放入一个新的线程中执行。这样,我们就可以在不阻塞主线程的情况下执行这个任务。
-
结果获取(Result Retrieval):std::packaged_task的另一个重要特性是它可以将任务的结果与一个std::future对象关联起来。这样,我们就可以在任务完成后,通过这个std::future对象来获取任务的结果。这对于那些需要获取异步任务结果的场景非常有用。
-
任务分发(Task Distribution):在一些复杂的并发应用中,我们可能需要将任务分发到多个线程中执行。在这种情况下,我们可以创建多个std::packaged_task对象,每个对象包装一个子任务,然后将这些packaged_task对象分发到不同的线程中执行。
-
并行计算(Parallel Computing):在一些需要大量计算的应用中,我们可以使用std::packaged_task来实现并行计算。我们可以将计算任务分解为多个子任务,然后使用std::packaged_task将这些子任务分发到多个线程中并行执行。
-
线程池(Thread Pool):在一些需要频繁创建和销毁线程的应用中,我们可以使用线程池来管理我们的线程。我们可以创建一个包含多个线程的线程池,然后将std::packaged_task对象放入线程池中执行。这样,我们就可以复用已经创建的线程,避免频繁地创建和销毁线程。
总的来说,std::packaged_task是一个非常强大的工具,它可以应用于各种需要并发执行任务的场景。在实际的编程中,我们可以根据我们的具体需求,灵活地使用std::packaged_task来提高我们的代码的并发性能。
5. std::thread、std::sync与std::packaged_task的比较
5.1 功能比较
在C++的并发编程中,std::thread、std::sync和std::packaged_task是三个常用的工具,它们各自有着不同的功能和特性。下面我们将从功能的角度对这三者进行详细的比较。
std::thread(线程)
std::thread是C++11引入的一个线程库,它提供了一种面向对象的线程模型。使用std::thread,我们可以创建一个新的执行线程,并且可以控制这个线程的执行。std::thread的主要功能是提供线程的创建、管理和同步。
- 创建线程:std::thread构造函数可以接受一个函数或者一个可调用对象,这个函数或者对象就是新创建的线程需要执行的任务。
- 管理线程:std::thread提供了一些方法来管理线程,比如join()方法可以等待线程结束,detach()方法可以让线程在后台运行。
- 同步线程:虽然std::thread本身并没有提供同步机制,但是C++标准库提供了一些同步工具,比如std::mutex和std::condition_variable,这些工具可以和std::thread一起使用,实现线程间的同步。
std::sync(同步)
std::sync是C++中用于同步的工具,它包括一些同步原语,比如互斥锁(mutex)、条件变量(condition variable)和future等。std::sync的主要功能是提供线程间的同步机制。
- 互斥锁:std::mutex是一个互斥锁,它可以保证在同一时间只有一个线程可以访问某个资源。
- 条件变量:std::condition_variable可以让一个线程等待某个条件成立。
- future:std::future可以获取异步操作的结果,它通常和std::async、std::packaged_task等一起使用。
std::packaged_task(任务包)
std::packaged_task是C++11引入的一个工具,它可以将一个可调用对象包装起来,然后在另一个线程中执行这个对象。std::packaged_task的主要功能是提供一种异步执行任务的机制。
- 包装任务:std::packaged_task构造函数可以接受一个函数或者一个可调用对象,这个函数或者对象就是需要异步执行的任务。
- 获取结果:std::packaged_task提供了一个get_future()方法,这个方法返回一个std::future对象,我们可以通过这个对象获取任务的结果。
- 执行任务:std::packaged_task对象可以像函数一样被调用,调用它就会执行包装的任务。
下面是一个使用markdown
下面是一个使用markdown表格对比这三者功能的表格:
| 功能/工具 | std::thread | std::sync | std::packaged_task |
|---|---|---|---|
| 创建线程 | √ | ||
| 管理线程 | √ | ||
| 同步线程 | √ | √ | |
| 互斥锁 | √ | ||
| 条件变量 | √ | ||
| future | √ | √ | |
| 包装任务 | √ | ||
| 获取结果 | √ | ||
| 执行任务 | √ |
通过上述的比较,我们可以看出,std::thread、std::sync和std::packaged_task各有其特点和优势,选择使用哪一个,需要根据具体的应用场景和需求来决定。

在接下来的章节中,我们将深入探讨这三个工具的性能比较和使用场景比较,以帮助你更好地理解和选择合适的工具。
5.2 性能比较
在并发编程中,性能是一个非常重要的考量因素。下面我们将从性能的角度对std::thread、std::sync和std::packaged_task进行比较。
std::thread(线程)
std::thread的性能主要取决于线程的创建和销毁的开销、线程切换的开销以及线程间的同步开销。
- 线程创建和销毁的开销:创建一个线程需要操作系统分配资源,销毁一个线程需要回收这些资源,这个过程是有开销的。如果频繁地创建和销毁线程,这个开销可能会成为性能瓶颈。
- 线程切换的开销:当操作系统从一个线程切换到另一个线程时,需要保存当前线程的状态,然后恢复另一个线程的状态,这个过程也是有开销的。如果线程切换非常频繁,这个开销也可能会影响性能。
- 线程间的同步开销:线程间的同步通常需要使用互斥锁、条件变量等同步原语,这些原语的使用也是有开销的。如果线程间的同步非常频繁,这个开销也可能会影响性能。
std::sync(同步)
std::sync的性能主要取决于同步原语的使用开销。
- 互斥锁的开销:互斥锁是一种重量级的同步原语,它需要操作系统的支持。获取和释放互斥锁都是有开销的,如果互斥锁的使用非常频繁,这个开销可能会影响性能。
- 条件变量的开销:条件变量也是一种重量级的同步原语,它需要操作系统的支持。等待和唤醒条件变量都是有开销的,如果条件变量的使用非常频繁,这个开销可能会影响性能。
- future的开销:future是一种轻量级的同步原语,它不需要操作系统的支持。但是,future的使用也是有开销的,如果future的使用非常频繁,这个开销可能会影响性能。
std::packaged_task(任务包)
std::packaged_task的性能主要取决于任务的创建和执行的开销。
- 任务创建的开销:创建一个任务需要分配资源,这个过程是有开销的。如果频繁地创建任务,这个开销可能会成为性能瓶颈。
- 任务执行的开销:执行一个任务需要调度资源,这个过程也是有开销的。如果任务的执行非常频繁,这个开销也可能会影响性能。
总的来说,std::thread、std::sync和std::packaged_task在性能上各有优劣,选择使用哪一个,需要根据具体的应用场景和性能需求来决定。

在接下来的章节中,我们将深入探讨这三个工具的使用场景比较,以帮助你更好地理解和选择合适的工具。
5.3 使用场景比较
在并发编程中,选择合适的工具需要考虑具体的使用场景。下面我们将从使用场景的角度对std::thread、std::sync和std::packaged_task进行比较。
std::thread(线程)
std::thread适用于需要创建新线程执行任务的场景。例如,如果你需要在后台执行一些耗时的操作,比如文件读写、网络请求等,那么std::thread是一个很好的选择。
std::sync(同步)
std::sync适用于需要同步多个线程的场景。例如,如果你有多个线程需要访问共享资源,你需要保证在同一时间只有一个线程可以访问这个资源,那么你可以使用std::sync中的互斥锁。如果你有一个线程需要等待另一个线程完成某个操作,那么你可以使用std::sync中的条件变量。
std::packaged_task(任务包)
std::packaged_task适用于需要异步执行任务并获取任务结果的场景。例如,如果你需要在一个线程中执行一个任务,然后在另一个线程中获取这个任务的结果,那么std::packaged_task是一个很好的选择。
总的来说,std::thread、std::sync和std::packaged_task在使用场景上各有优势,选择使用哪一个,需要根据具体的应用场景来决定。在接下来的章节中,我们将总结这三个工具的优缺点,以帮助你更好地理解和选择合适的工具。
6. 结论与展望(Conclusion and Outlook)
6.1 选择合适的并发编程工具(Choosing the Right Concurrency Programming Tool)
在C++并发编程中,选择合适的工具是至关重要的。这需要我们根据具体的应用场景和需求,对std::thread、std::sync和std::packaged_task等工具进行深入理解和比较。
首先,我们需要明确每种工具的基本功能和特性。std::thread(线程)是C++中最基础的并发编程工具,它可以创建一个新的线程并执行指定的任务。std::sync(同步)则提供了一种机制,使得多个线程可以协同工作,共享资源而不产生冲突。std::packaged_task(打包任务)则是一种更高级的工具,它可以将任务和结果关联起来,使得我们可以在一个线程中执行任务,并在另一个线程中获取结果。
其次,我们需要考虑性能的问题。在大多数情况下,使用std::thread会有较好的性能,因为它直接操作系统级的线程,没有额外的开销。然而,当我们需要进行复杂的同步操作时,使用std::sync可能会更加高效,因为它提供了一种高级的同步机制,可以避免一些低级的错误。对于需要将任务和结果关联起来的场景,使用std::packaged_task则可能会有更好的性能,因为它可以避免一些不必要的同步操作。
最后,我们需要考虑适用的场景。std::thread适合于需要创建新线程的场景,std::sync适合于需要进行复杂同步操作的场景,而std::packaged_task则适合于需要将任务和结果关联起来的场景。
在实际的编程中,我们可能需要根据具体的需求,灵活地使用这些工具。例如,我们可以使用std::thread来创建新的线程,然后使用std::sync来同步这些线程的工作,最后使用std::packaged_task来获取结果。这样,我们就可以充分利用C++的并发编程特性,编写出高效、稳定的程序。
在选择并发编程工具时,我们还需要考虑到一些其他的因素,例如编程的复杂性、代码的可读性和可维护性等。在一些情况下,我们可能需要牺牲一些性能,以换取更好的编程体验和代码质量。
总的来说,选择合适的并发编程工具,需要我们对这些工具有深入的理解,同时也需要我们根据具体
的应用场景和需求,进行全面的权衡。希望这篇文章能够帮助你在C++并发编程中,做出更好的选择。
接下来,我们将会探讨C++并发编程的未来发展,以及如何进一步提高我们的编程技能。
6.2 C++并发编程的未来发展(Future Development of C++ Concurrency Programming)
C++并发编程的未来发展前景广阔,随着硬件技术的进步和软件需求的增长,对并发编程的需求也在不断增加。以下是一些可能的发展趋势:
-
更高级的同步机制(Advanced Synchronization Mechanisms):随着并发编程的复杂性增加,我们可能需要更高级的同步机制来管理线程之间的交互。例如,我们可能需要一种能够处理更复杂的依赖关系,或者能够更有效地处理资源争用的同步机制。
-
更强大的任务调度(Powerful Task Scheduling):在并发编程中,如何有效地调度任务是一个重要的问题。未来,我们可能会看到更强大的任务调度算法,这些算法能够更好地利用硬件资源,提高程序的性能。
-
更好的错误处理(Better Error Handling):在并发编程中,错误处理是一个重要的问题。由于线程之间的交互,错误可能会在多个线程之间传播,这使得错误处理变得更加复杂。未来,我们可能会看到更好的错误处理机制,这些机制能够更有效地处理并发错误。
-
更丰富的并发编程模型(Richer Concurrency Programming Models):目前,C++支持的并发编程模型主要是基于线程的模型。未来,我们可能会看到更丰富的并发编程模型,例如基于任务的模型,或者基于数据流的模型。
以上只是一些可能的发展趋势,实际的发展可能会有所不同。但无论如何,我们都可以期待C++并发编程的未来会更加强大和灵活。
6.3 结语(Conclusion)
在本文中,我们深入探讨了C++并发编程中的std::thread、std::sync和std::packaged_task等工具。我们从基础的使用方法,到性能分析,再到适用场景,进行了全面的介绍和比较。我们希望这些内容能够帮助你更好地理解和使用这些工具。
并发编程是一个复杂而重要的主题,它涉及到许多深入的概念和技术。虽然C++提供了一些强大的工具来支持并发编程,但是要真正掌握这些工具,还需要大量的学习和实践。我们希望这篇文章能够为你的学习之旅提供一些帮助。
最后,我们期待C++并发编程的未来发展,我们相信随着技术的进步,我们将能够编写出更高效、更稳定的并发程序。让我们一起期待这个美好的未来吧!