T5的整体介绍【代码实战】
- 0、前言
- 1.Header
- 2.summary
- 3 T5 model
- 3.1 forward
- 3.2 预训练任务
- 3.2.1 multi sentence pairs
- 3.3 完成 tasks
0、前言
本文是对T5预训练模型的一个介绍,以及能够用来做任务测试,完整的代码稍后挂上链接。
1.Header
import torch
from torch import nn
import torch.nn.functional as F
import transformers
# from transformers_utils import get_params
from transformers import pipeline
# ~/.cache/huggingface/hub
from transformers import AutoTokenizer, AutoConfig, AutoModel
# ~/.cache/huggingface/datasets
from datasets import load_dataset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
from IPython.display import Image
# trainable parameters of the model
def get_params(model):
model_parameters = filter(lambda p: p.requires_grad, model.parameters())# 用filter函数过滤掉那些不需要梯度更新的参数,只保留那些需要梯度更新的参数,然后把它们放在一个变量,叫做model_parameters。这个变量也是一个迭代器。
params = sum([np.prod(p.size()) for p in model_parameters])# 用一个列表推导式遍历model_parameters中的每个参数,然后用np.prod函数计算每个参数的元素个数。np.prod函数的作用是把一个序列中的所有元素相乘。例如,如果一个参数的形状是(2, 3),那么它的元素个数就是2 * 3 = 6。然后把所有参数的元素个数加起来,得到一个总和,放在一个变量,叫做params。
return params
# default: 100
mpl.rcParams['figure.dpi'] = 150
device = 'cuda' if torch.cuda.is_available() else 'cpu'
device
‘cuda’
2.summary
- t5: Text-To-Text Transfer Transformer
- https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
- https://huggingface.co/docs/transformers/model_doc/t5
Image('t5.png')
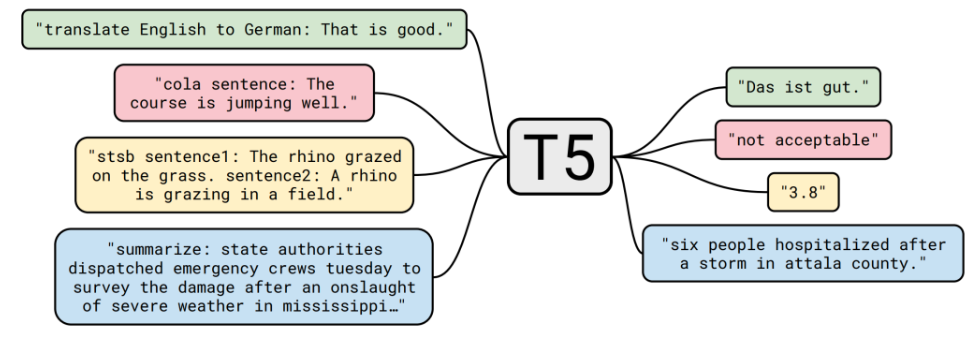
可见可以做的任务有1.翻译;2.是否接受一个句子;3.句子直接的相似度计算;4.摘要。
- CoLA: Linguistic Acceptability
-
CoLA,全称为The Corpus of Linguistic Acceptability,是一个英语语言的句子接受度数据集,由华盛顿大学计算机科学与工程系的一组研究人员于2018年创建。该数据集旨在提供一个用于评估自然语言处理模型所生成文本的语言接受度和流畅度的基准测试集。
-
CoLA数据集由10657个英语句子组成,这些句子来自各种不同的来源,包括核心新闻材料和审判文件等。每个句子都被标记为可接受或不可接受,可接受的句子应该具有语法正确性和常识性,相反,不可接受的句子可能会涉及句法错误、歧义、语义冲突等问题。
-
CoLA数据集是典型的二元分类问题,用于测试模型对自然语言句子的语法和语义的理解能力。同时,CoLA数据集还提供了一个挑战,即对于不可接受的句子,模型需要能够识别错误类型以及如何修复它们。
-
CoLA数据集被广泛应用于自然语言处理领域,特别是语言理解、句法分析、语义分析等方面的研究。该数据集已被众多研究人员用于评估自然语言处理模型的性能和对其改进。
-
- STSB: Semantic Textual Similarity Beachmark
-
STSB,全称为The Semantic Textual Similarity Benchmark,是一个用于评估自然语言处理模型对文本语义相似性的数据集和基准测试集。该数据集由华盛顿大学计算机科学与工程系的研究人员于2012年创建,主要用于评估模型在句子和文本相似性任务中的性能。
-
STSB数据集包含7,000对句子,这些句子来自各种不同的来源,例如自然语言文本、问题回答对、比较句等。每个句子对都被标记为0到5之间的相似度分数(0表示两个句子毫不相似,5表示两个句子非常相似)。
-
在STSB数据集中,模型需要对每对句子的相似度进行预测。这是一个连续值预测问题,需要模型预测一个浮点数作为句子对之间的相似性得分。
-
STSB数据集是测试模型在句子和文本相似性任务中的常用基准测试集之一。自该数据集发布以来,很多研究已经使用它来评估不同的自然语言处理模型和各种技术。它在一些实际应用领域,例如问答系统和文本匹配任务中具有重要实际意义。
-
3 T5 model
- vocabulary size:32128
| model | 参数量 | hidden dim | encoder/decoder layers |
|---|---|---|---|
| t5-small | 61M | 512 (64*8) -> 512 | 6 |
| t5-base | 223M | 768 (64*12) -> 768 | 12 |
| t5-large | 738M | 1024 (64*16) -> 1024 | 24 |
| t5-3b | 2.85B | 4096 (128*32) -> 1024 | 24 |
| t5-11b | 11B | 16384 (128*128) -> 1024 | 24 |
# t5-small
# t5-base
# t5-large
# t5-3b
# tb-11b
model_ckpt = 't5-3b'
# 比 T5Model 多了一层 hidden_state -> vocab_size 的 mlp 的映射
model = AutoModel.from_pretrained(model_ckpt, )
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
config = AutoConfig.from_pretrained(model_ckpt)
config
T5Config {
“_name_or_path”: “t5-3b”,
“architectures”: [
“T5WithLMHeadModel”
],
“d_ff”: 16384,
“d_kv”: 128,
“d_model”: 1024,
“decoder_start_token_id”: 0,
“dense_act_fn”: “relu”,
“dropout_rate”: 0.1,
“eos_token_id”: 1,
“feed_forward_proj”: “relu”,
“initializer_factor”: 1.0,
“is_encoder_decoder”: true,
“is_gated_act”: false,
“layer_norm_epsilon”: 1e-06,
“model_type”: “t5”,
“n_positions”: 512,
“num_decoder_layers”: 24,
“num_heads”: 32,
“num_layers”: 24,
“output_past”: true,
“pad_token_id”: 0,
“relative_attention_max_distance”: 128,
“relative_attention_num_buckets”: 32,
“task_specific_params”: {
“summarization”: {
“early_stopping”: true,
“length_penalty”: 2.0,
“max_length”: 200,
“min_length”: 30,
“no_repeat_ngram_size”: 3,
“num_beams”: 4,
“prefix”: "summarize: "
},
“translation_en_to_de”: {
“early_stopping”: true,
“max_length”: 300,
“num_beams”: 4,
“prefix”: "translate English to German: "
},
“translation_en_to_fr”: {
“early_stopping”: true,
“max_length”: 300,
“num_beams”: 4,
“prefix”: "translate English to French: "
},
“translation_en_to_ro”: {
“early_stopping”: true,
“max_length”: 300,
“num_beams”: 4,
“prefix”: "translate English to Romanian: "
}
},
“transformers_version”: “4.28.0”,
“use_cache”: true,
“vocab_size”: 32128
}
可见相关任务是1. summarize: 2.translate English to German: 3.translate English to French:4. translate English to Romanian:。
model
T5Model(
(shared): Embedding(32128, 1024)
(encoder): T5Stack(
(embed_tokens): Embedding(32128, 1024)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
(relative_attention_bias): Embedding(32, 32)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=1024, out_features=16384, bias=False)
(wo): Linear(in_features=16384, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1-23): 23 x T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=1024, out_features=16384, bias=False)
(wo): Linear(in_features=16384, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(decoder): T5Stack(
(embed_tokens): Embedding(32128, 1024)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
(relative_attention_bias): Embedding(32, 32)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=1024, out_features=16384, bias=False)
(wo): Linear(in_features=16384, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1-23): 23 x T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=1024, out_features=16384, bias=False)
(wo): Linear(in_features=16384, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
format(get_params(model), ',')
‘2,851,598,336’
参数是2.85B
3.1 forward
input_ids = tokenizer(
"Studies have been shown that owning a dog is good for you", return_tensors="pt"
).input_ids # Batch size 1
decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids
# preprocess: Prepend decoder_input_ids with start token which is pad token for T5Model.
# This is not needed for torch's T5ForConditionalGeneration as it does this internally using labels arg.
decoder_input_ids = model._shift_right(decoder_input_ids)
input_ids
tensor([[6536, 43, 118, 2008, 24, 293, 53, 3, 9, 1782, 19, 207,
21, 25, 1]])
model.eval()
# forward pass
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
last_hidden_states = outputs.last_hidden_state
last_hidden_states
tensor([[[-0.1611, -0.0524, 0.2812, …, -0.0113, -0.5561, -0.1034],
[-0.0441, 0.0494, 0.0101, …, 0.2337, 0.1868, 0.0204],
[-0.1586, -0.0830, -0.0067, …, 0.1704, 0.0040, 0.1689],
[-0.0349, -0.0160, 0.0020, …, 0.1688, -0.0871, 0.1037]]],
grad_fn=< MulBackward0>)
def t5_forward(model, input_ids, decoder_input_ids):
encoder_outputs = model.encoder(input_ids=input_ids)
# print(encoder_outputs)
hidden_states = encoder_outputs[0]
decoder_outputs = model.decoder(input_ids=decoder_input_ids,
encoder_hidden_states=hidden_states,)
return decoder_outputs.last_hidden_state
t5_forward(model, input_ids, decoder_input_ids)
tensor([[[-0.1611, -0.0524, 0.2812, …, -0.0113, -0.5561, -0.1034],
[-0.0441, 0.0494, 0.0101, …, 0.2337, 0.1868, 0.0204],
[-0.1586, -0.0830, -0.0067, …, 0.1704, 0.0040, 0.1689],
[-0.0349, -0.0160, 0.0020, …, 0.1688, -0.0871, 0.1037]]],
grad_fn=< MulBackward0>)
可以看到两个结果是一样的。
3.2 预训练任务
- Unsupervised denoising training
- MLM(Mask Language Model)
- span mask
- Supervised training
- seq2seq
from transformers import T5ForConditionalGeneration
model = T5ForConditionalGeneration.from_pretrained(model_ckpt)
model
T5ForConditionalGeneration(
(shared): Embedding(32128, 1024)
(encoder): T5Stack(
(embed_tokens): Embedding(32128, 1024)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
(relative_attention_bias): Embedding(32, 32)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=1024, out_features=16384, bias=False)
(wo): Linear(in_features=16384, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1-23): 23 x T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=1024, out_features=16384, bias=False)
(wo): Linear(in_features=16384, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(decoder): T5Stack(
(embed_tokens): Embedding(32128, 1024)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
(relative_attention_bias): Embedding(32, 32)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=1024, out_features=16384, bias=False)
(wo): Linear(in_features=16384, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1-23): 23 x T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=1024, out_features=4096, bias=False)
(k): Linear(in_features=1024, out_features=4096, bias=False)
(v): Linear(in_features=1024, out_features=4096, bias=False)
(o): Linear(in_features=4096, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=1024, out_features=16384, bias=False)
(wo): Linear(in_features=16384, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(lm_head): Linear(in_features=1024, out_features=32128, bias=False)
)
可见T5ForConditionalGeneration多了最后一层,即(lm_head): Linear(in_features=1024, out_features=32128, bias=False),Language Model_head。
# Unsupervised denoising training
# mlm
input_ids = tokenizer("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
labels = tokenizer("<extra_id_0> cute dog <extra_id_1> the <extra_id_2>", return_tensors="pt").input_ids
# the forward function automatically creates the correct decoder_input_ids
loss = model(input_ids=input_ids, labels=labels).loss
loss.item()
1.9458732604980469
# Supervised training
# seq2seq
input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
labels = tokenizer("Das Haus ist wunderbar.", return_tensors="pt").input_ids
# the forward function automatically creates the correct decoder_input_ids
loss = model(input_ids=input_ids, labels=labels).loss
loss.item()
0.9009745717048645
3.2.1 multi sentence pairs
# the following 2 hyperparameters are task-specific
max_source_length = 512
max_target_length = 128
# Suppose we have the following 2 training examples:
input_sequence_1 = "Welcome to NYC"
output_sequence_1 = "Bienvenue à NYC"
input_sequence_2 = "HuggingFace is a company"
output_sequence_2 = "HuggingFace est une entreprise"
# encode the inputs
task_prefix = "translate English to French: "
input_sequences = [input_sequence_1, input_sequence_2]
encoding = tokenizer(
[task_prefix + sequence for sequence in input_sequences],
padding="longest",
max_length=max_source_length,
truncation=True,
return_tensors="pt",
)
input_ids, attention_mask = encoding.input_ids, encoding.attention_mask
# encode the targets
target_encoding = tokenizer(
[output_sequence_1, output_sequence_2],
padding="longest",
max_length=max_target_length,
truncation=True,
return_tensors="pt",
)
labels = target_encoding.input_ids
# replace padding token id's of the labels by -100 so it's ignored by the loss
labels[labels == tokenizer.pad_token_id] = -100
# forward pass
loss = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels).loss
loss.item()
0.19245588779449463
3.3 完成 tasks
input_ids = tokenizer.encode("translate English to German: Hello, my dog is cute", return_tensors="pt")
result = model.generate(input_ids)
tokenizer.decode(result[0])
‘ Hallo, mein Hund ist süß’
# inference
input_ids = tokenizer(
"summarize: Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pretraining objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.",
return_tensors="pt"
).input_ids # Batch size 1
outputs = model.generate(input_ids, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# studies have shown that owning a dog is good for you.
transfer learning has emerged as a powerful technique in natural language processing (NLP) in this paper, we explore the landscape of transfer learning techniques for NLP. we introduce a unified framework that converts every language problem into a text-to-text format.
参考:
https://github.com/chunhuizhang/bert_t5_gpt/blob/main/tutorials/09_t5_overall.ipynb