简介
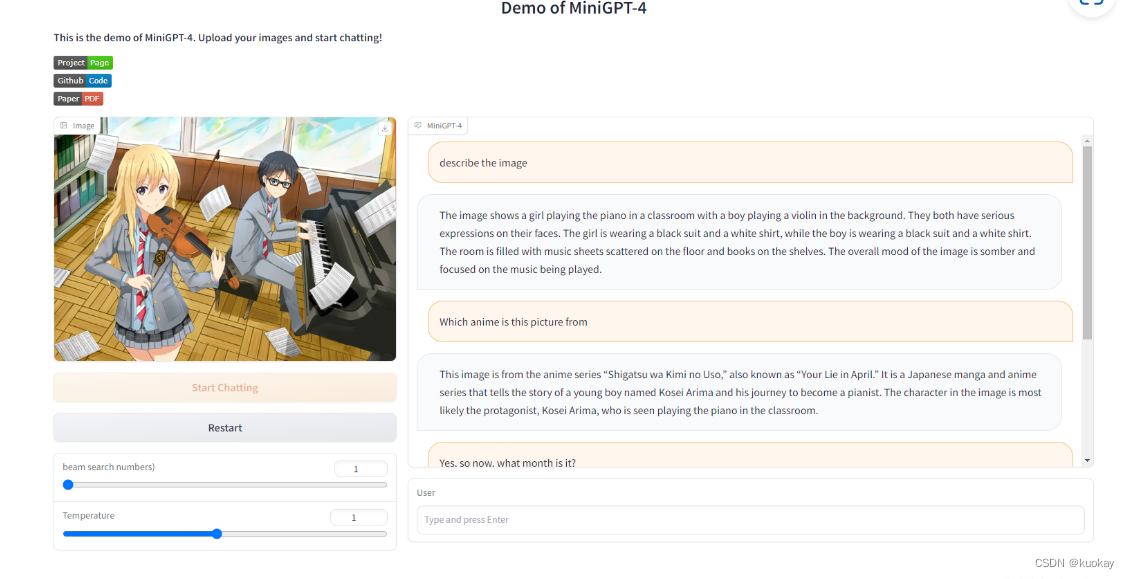
Minigpt4虽然放出了网页版但是使用后发现网页体验的话,由于并发量比较大,很容易突然卡顿的现象,所以下面我主要讲解一下如何进行本地部署。
之前文章已经介绍过Minigpt4了这里就不重复赘述了,不了解的可以去看看https://blog.csdn.net/qq_45066628/article/details/130231186?spm=1001.2014.3001.5501

由于经费有限我这里使用的是7B模型,按照文档中所说,7B模型大概需要12G左右,而13B需要24G。
搭建过程
1.环境搭建
-
我这里使用的是Conda环境,Conda搭建过程比较简单就不赘述了,有不会的可以自行搜一下,按照教程按照就行。
-
装好Conda后还需要安装Cuda和torch(安装官网教程操作就行)
Cuda:https://developer.nvidia.com/cuda-toolkit
Torch:https://pytorch.org/get-started/locally/
Cuda安装好后执行ncvv -V命令看到有输出表示cuda安装成功
Torch安装后执行以下代码检查是否安装成功import torch torch.cuda.is_available()
2.模型下载
1.下载相关模型
v0版和v1版这,里我更加推荐v1版本,相对来讲会bug少点,具体选择更具自己
第一种方法:
直接下载即可
7b地址(v1):https://huggingface.co/lmsys/vicuna-7b-delta-v1.1/tree/main
13b地址(v0):https://huggingface.co/lmsys/vicuna-13b-delta-v0/tree/main
第二种方法:
1.使用git拉取vicuna模型
v0版:
git clone https://huggingface.co/lmsys/vicuna-13b-delta-v0 # more powerful, need at least 24G gpu memory
# or
git clone https://huggingface.co/lmsys/vicuna-7b-delta-v0 # smaller, need 12G gpu memory
v1版:
git clone https://huggingface.co/lmsys/vicuna-13b-delta-v1 # more powerful, need at least 24G gpu memory
# or
git clone https://huggingface.co/lmsys/vicuna-7b-delta-v1 # smaller, need 12G gpu memory
2.使用git拉取llama模型
git clone https://huggingface.co/decapoda-research/llama-13b-hf
# or
git clone https://huggingface.co/decapoda-research/llama-7b-hf
3.关联vicuna和llama模型
拉取完成后,就可以将其关联起来,这里使用工具为官方为了适配两个模型装门开发的FastChat,如果没有梯子或者其它加速手段,建议源码编译安装。
git clone https://github.com/lm-sys/FastChat.git
cd FastChat/
pip3 install --upgrade pip # enable PEP 660 support
pip3 install -e .
安装没问题执行
python -m fastchat.model.apply_delta --base /path/to/llama-13bOR7b-hf/ --target /path/to/save/working/vicuna/weight/ --delta /path/to/vicuna-13bOR7b-delta-v0/
2.预训练模型下载
|–|—
| name | download |
|---|---|
| Checkpoint Aligned with Vicuna 7B | https://drive.google.com/file/d/1RY9jV0dyqLX-o38LrumkKRh6Jtaop58R/view?usp=sharing |
| Checkpoint Aligned with Vicuna 13B | https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view?usp=share_link |
3.配置文件修改
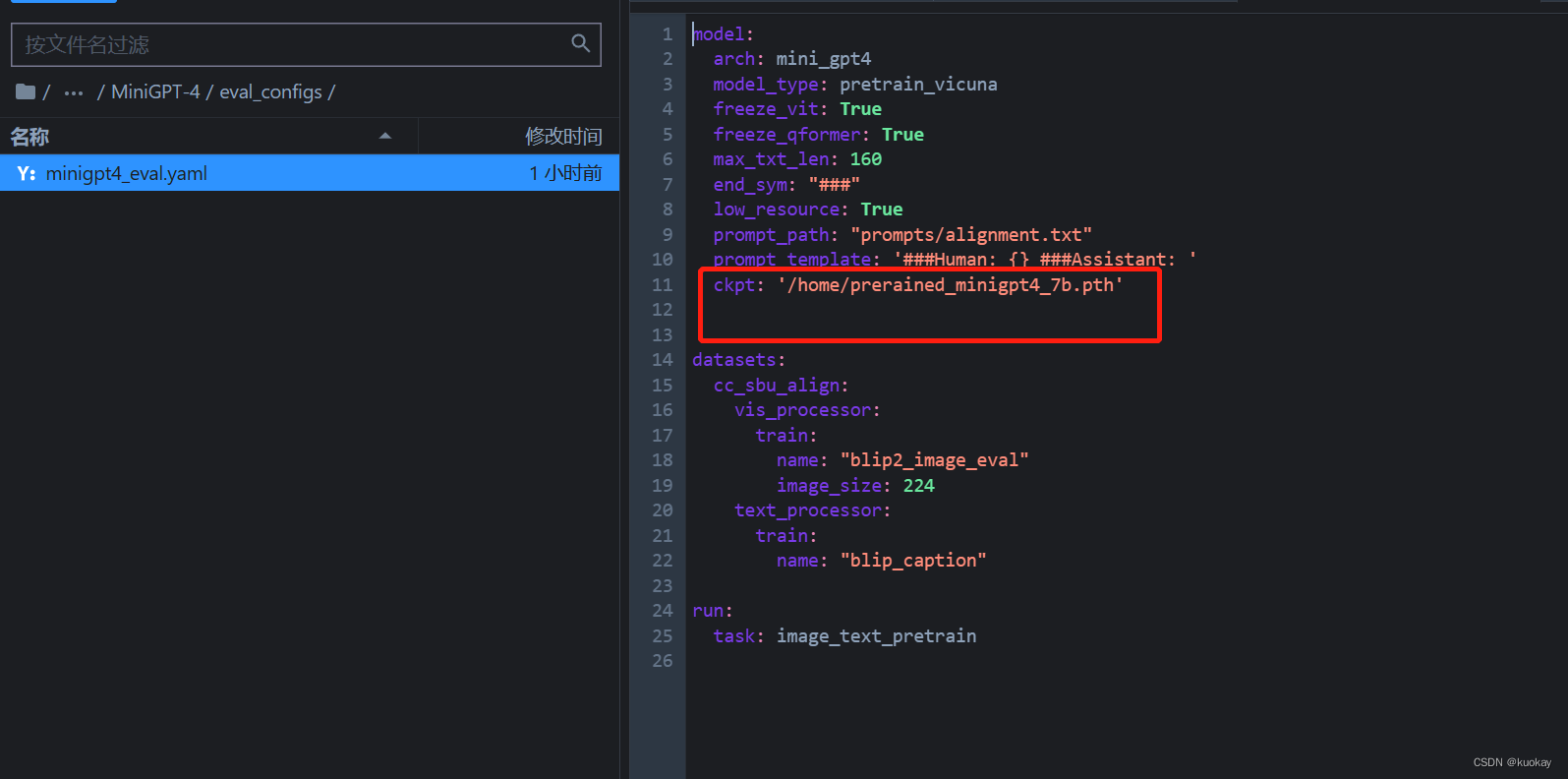
1.修改eval_configs/minigpt4_eval.yaml下的ckpt对应的value,改为下载的预训练模型路径
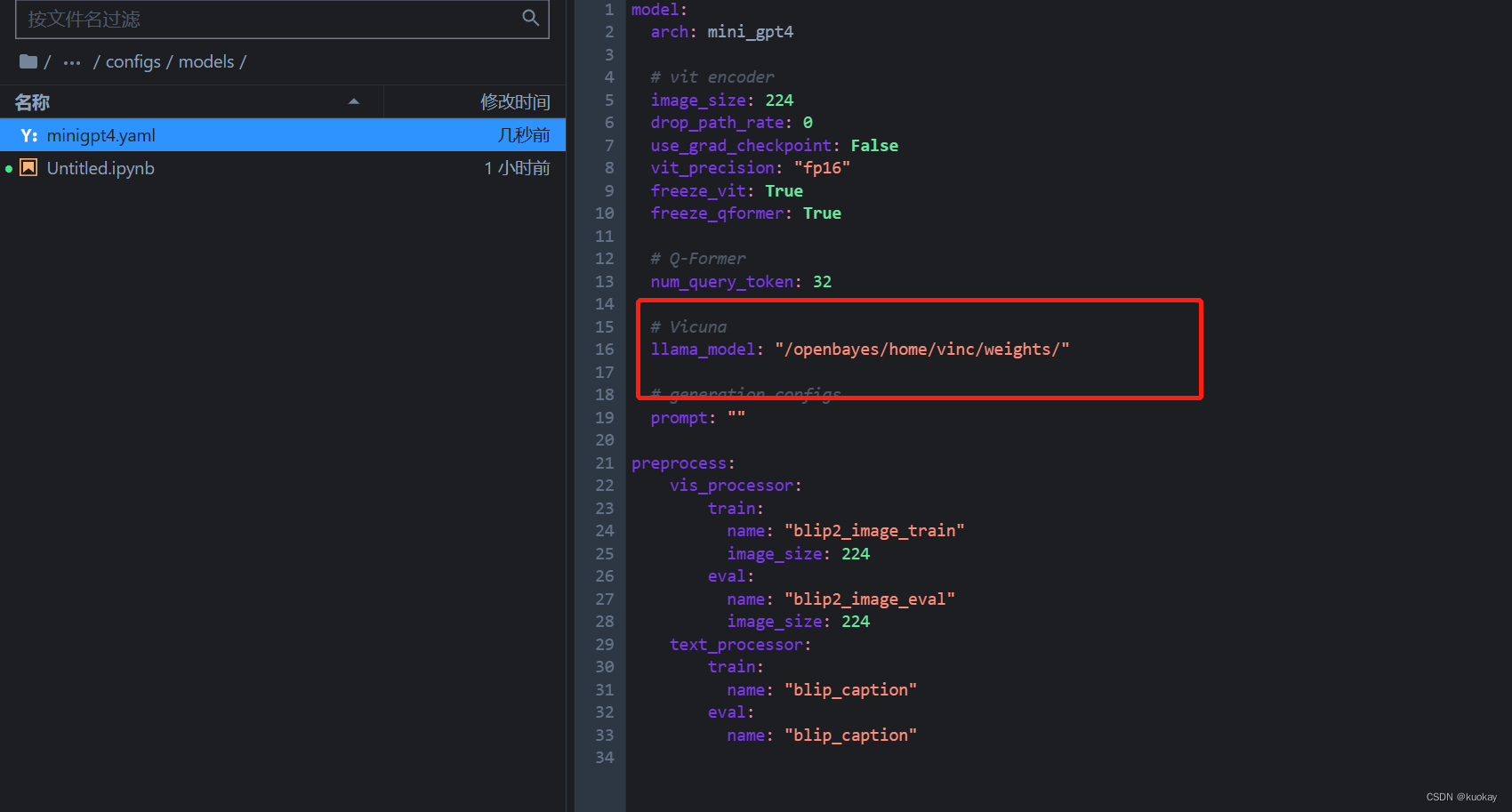
2.修改minigpt4/configs/models/minigpt4.yaml下的llana_model,改为下载的vicuna和llama模型的路径
4.运行项目
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
运行后在浏览器输入localhost:7860