0.GPT的模型结构
GPT是一个基于Transformer的生成式预训练模型。使用Transformer中的解码器部分
它由一系列的模块化的Transformer Blocks组成。每一个Block包含一个多头自注意力机制(Multi-Head Self-Attention mechanism)以及一个位置前馈网络(position-wise feedforward network)。所有的Block都共享同样的架构,但并不共享权重。
每一个Block的输入首先会通过多头自注意力机制进行处理。自注意力机制允许模型在生成当前词元(token)时考虑到输入序列中的所有其他词元,并为这些词元分配不同的注意力权重。
处理后的输出接着会经过一个前馈神经网络,这是一个逐位置(position-wise)操作,也就是说,它会独立地处理序列中的每一个位置的信息。
除了这些主要的部分,每一个Block还包含残差连接(residual connections)和层归一化(layer normalization)以提高训练稳定性和效果。
在GPT的训练过程中,模型会以自回归(auto-regressive)的方式处理输入的文本序列,即在生成每一个词元时,只考虑它前面的词元。然后,模型会尝试预测序列中下一个词元的概率分布。
总的来说,GPT模型的结构旨在充分利用输入序列中的全局信息,并通过自回归的方式生成文本。
1.什么是自回归语言模型
GPT系列模型(如GPT-3和GPT-4)就是典型的自回归语言模型
自回归语言模型(Autoregressive Language Model)是一种基于概率的自然语言处理(NLP)技术,其主要用途在于生成和解析文本。这种模型采用自回归的原理,即根据已知的历史数据来预测未来的值。在语言建模的背景下,这意味着模型会根据已观察到的单词序列来预测接下来的单词。
GPT系列模型(如GPT-3和GPT-4)就是自回归语言模型的经典例子。
2.比较GPT和BERT的不同
BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pretrained Transformer)都是自然语言处理中的前沿模型,但它们在建模语言时使用了不同的方法。
BERT采用了一种被称为“掩码语言模型”的方式,也就是通过随机屏蔽文本中的一部分单词,然后训练模型去预测这些被屏蔽的单词。BERT使用的是Transformer的编码器结构,并且是双向的,可以同时考虑上下文中前后的信息。
相比之下,GPT则采用了自回归的方式,也就是给定一系列的前文,预测后续的Token。GPT使用的是Transformer的解码器结构,只能从前往后预测,也就是说,它在预测某个单词时只考虑该单词前面的上下文。
两种模型使用的目标函数(损失函数)不同。GPT的目标函数相较BERT的目标函数更为复杂,因为它需要生成整个文本序列,而不仅仅是填充被遮挡的部分。另一方面,BERT的目标函数在某种程度上可以认为是有一个更高的“下限”,因为它的任务更简单——只需要预测遮挡的单词。然而,GPT的“上限”更高,因为它具有生成完整文本的能力。
BERT更擅长理解文本(因为它同时考虑了上下文的前后信息),而GPT则更擅长生成文本(因为它从前往后生成整个文本)。
3.使用GPT进行微调
GPT是可以根据不同下游任务进行微调
GPT2可以微调,也可以用类似prompt的方式进行Few-shot和Zero-shot 的推理
GPT3在处理子任务的时候不做任何梯度更新和微调,主要原因是模型过大,微调成本过高。主要使用下面的方法进行Few-shot,Zero-shot 的推理。
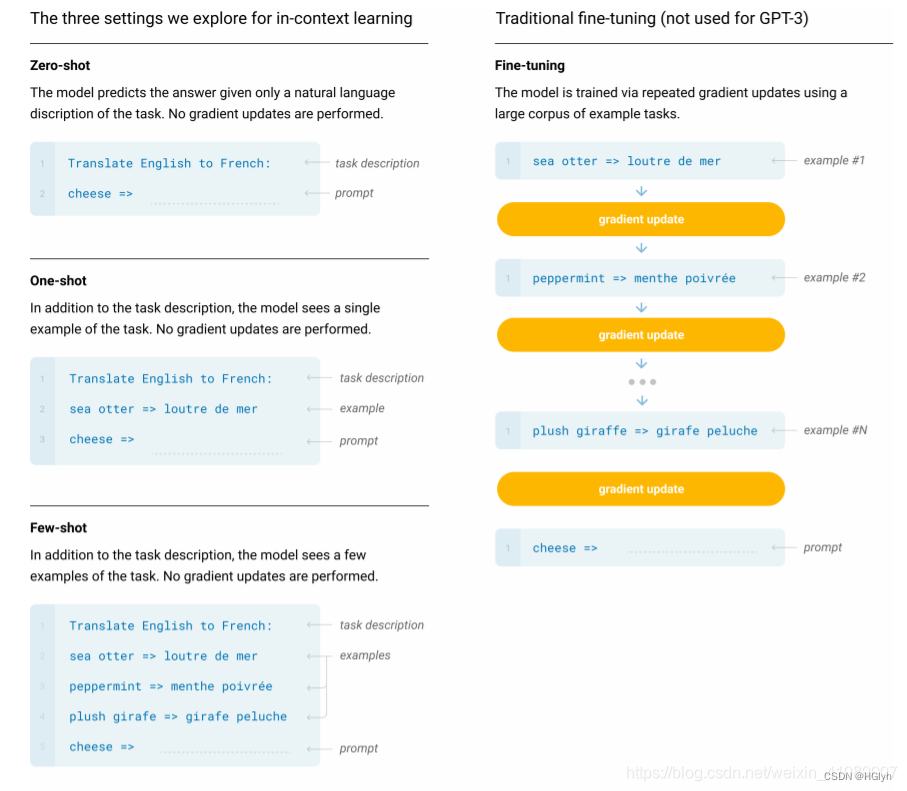
Zero-shot是指我们给模型提供一个包含任务信息的输入,然后让模型直接预测答案。
Few-shot是在零次学习的基础上给模型提供少量的示例来指导其理解任务。
4.GPT局限性
(下面这段话都是GPT自己生成的。。。)
虽然GPT(包括其后续版本如GPT-2、GPT-3等)在许多自然语言处理任务中表现出卓越的性能,但它们仍存在一些局限性:
-
过度生成: GPT模型有时可能会生成与输入不相关或者没有根据的内容。这是因为它们是在大量文本数据上训练的,它们的主要目标是生成看似语法正确、连贯的文本,而不一定是逻辑上严谨或事实上准确的内容。
-
缺乏常识和深度理解: 虽然GPT可以通过训练数据学习到大量的语言模式,但它并不真正理解语言的含义。这意味着它可能会做出一些明显违反常识的错误。同样,对于需要深度理解或专门知识的问题,GPT的表现可能不佳。
-
易于产生偏见: GPT模型在训练过程中可能会学习到数据中的偏见,包括性别、种族、宗教等各种形式的偏见。如果这些偏见在生成的内容中得到体现,可能会引发问题。
-
难以控制生成内容: 控制GPT模型生成的具体内容是一项挑战。虽然我们可以通过调整参数和使用特定的输入提示来影响输出,但这通常需要大量的试错和微调。
-
知识更新的问题: GPT模型在训练后的知识是固定的,它不能获取或理解训练数据后发生的事件或新的知识。
-
计算资源消耗大: 训练GPT这样的大型模型需要大量的计算资源,这在一定程度上限制了其可接受性和普及性。
-
安全性和滥用的问题: 高质量的文本生成能力可能被用于不良目的,如产生虚假新闻、恶意评论等。
5 自回归模型的解码方式
Beam Search是一种在每一步保留几个最有可能的候选序列的策略,十分常见
这种采样虽然会找到语法上最通顺的句子,但是不一定是人类期待最佳答案。对于一个充分训练的生成模型,使用Beam Search找到的Top10会非常的雷同。
这时候可以采用Top-k Sampling或者Top-p Sampling 想了解更多可以看下面的链接
Nucleus Sampling与不同解码策略简介 - 知乎 (zhihu.com)
6 instructGPT
ChatGPT/InstructGPT详解 - 知乎 (zhihu.com)







![[unity]如何并行for循环](https://img-blog.csdnimg.cn/3afe1518f47b43a29eb8fca8a06f40e9.png)