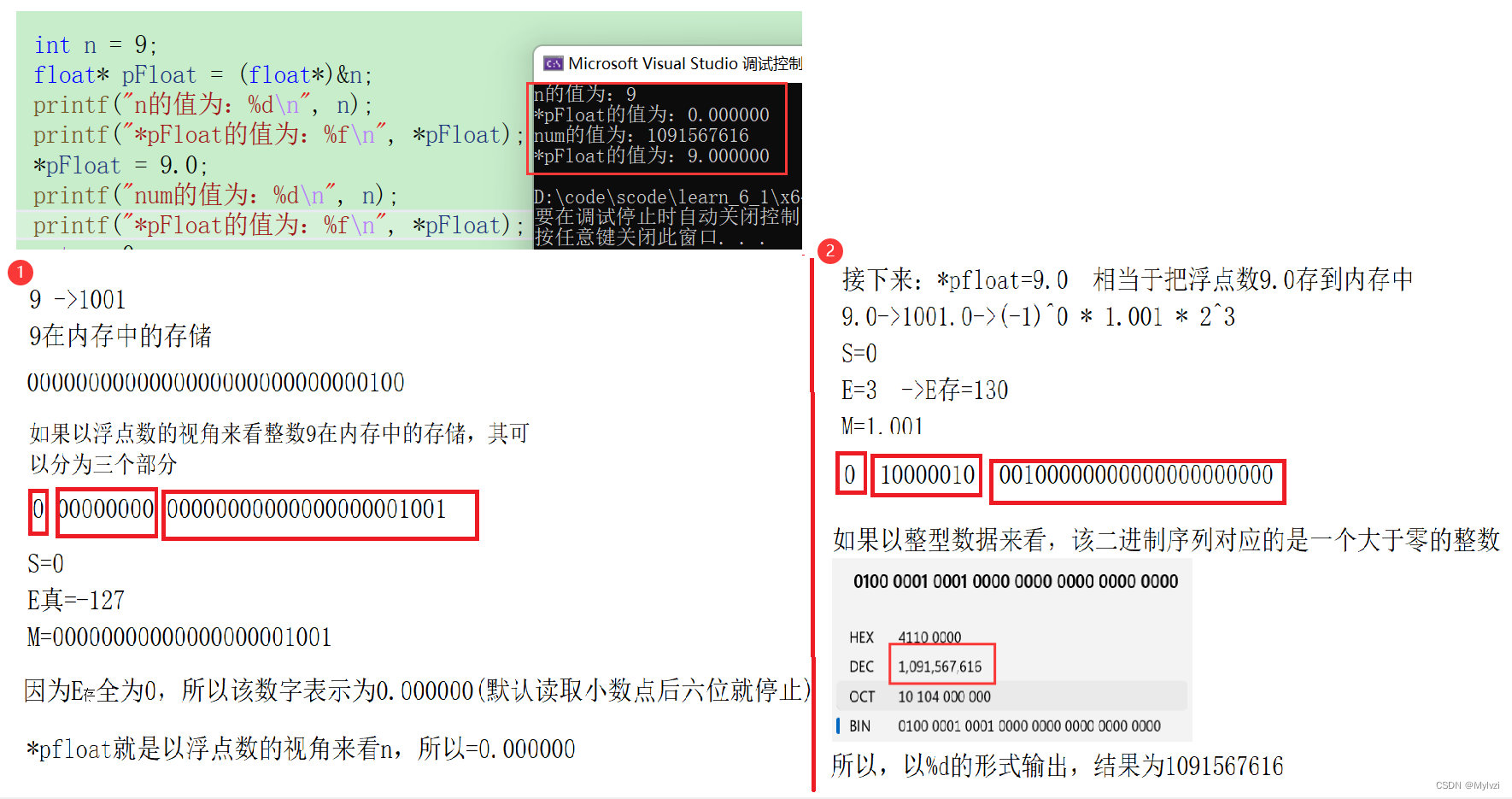
几年前,开始使用Rust编程,它逐渐改变了我使用其他编程语言(尤其是Python)设计程序的方式。在我开始使用Rust之前,我通常以一种非常动态和类型松散的方式编写Python代码,没有类型提示,到处传递和返回字典,偶尔回退到“字符串类型”接口。然而,在经历了Rust类型系统的严格性,并注意到它“通过构造”防止的所有问题之后,每当我回到Python并且没有得到相同的保证时,我突然变得非常焦虑。
需要明确的是,这里的“保证”并不是指内存安全(Python本身是合理的内存安全),而是“稳健性”——设计很难或完全不可能被滥用的API的概念,从而防止未定义的行为和各种错误。在Rust中,错误使用的接口通常会导致编译错误。在Python中,您仍然可以执行此类不正确的程序,但如果您使用类型检查器(如pyright)或带有类型分析器的IDE(如PyCharm),您仍然可以获得类似级别的有关可能问题的快速反馈。
最终,我开始在我的Python程序中采用Rust的一些概念。它基本上可以归结为两件事——尽可能多地使用类型提示,并坚持让非法状态无法表示的原则。我尝试对将维护一段时间的程序和 oneshot实用程序脚本都这样做。主要是因为根据我的经验,后者经常变成前者:)根据我的经验,这种方法导致程序更容易理解和更改。
在本文中,我将展示几个应用于Python程序的此类模式示例。这不是火箭科学,但我仍然觉得记录它们可能会有用。
注意:这篇文章包含了很多关于编写Python代码的观点。我不想在每句话中都加上“恕我直言”,所以将这篇文章中的所有内容仅作为我对此事的看法,而不是试图宣传一些普遍的真理:)另外,我并不是说所提出的想法是所有这些都是在Rust中发明的,当然,它们也被用于其他语言。
01
一 、Type hint
首要的是尽可能使用类型提示,特别是在函数签名和类属性中。当我读到一个像这样的函数签名时:
def find_item(records, check):我不知道签名本身发生了什么。是records列表、字典还是数据库连接?是check布尔值还是函数?这个函数返回什么?如果失败会发生什么,它会引发异常还是返回None?为了找到这些问题的答案,我要么必须去阅读函数体(并且经常递归地阅读它调用的其他函数的函数体——这很烦人),要么阅读它的文档(如果有的话)。虽然文档可能包含有关函数功能的有用信息,但没有必要将它也用于记录前面问题的答案。很多问题都可以通过内置机制——类型提示——来回答。
def find_item(
records: List[Item],
check: Callable[[Item], bool]
) -> Optional[Item]:我写签名花了更多时间吗?是的。那是问题吗?不,除非我的编码受到每分钟写入的字符数的瓶颈,而这并没有真正发生。明确地写出类型迫使我思考函数提供的实际接口是什么,以及如何使其尽可能严格,以使其调用者难以以错误的方式使用它。通过上面的签名,我可以很好地了解如何使用该函数、将什么作为参数传递给它以及我期望从中返回什么。此外,与代码更改时很容易过时的文档注释不同,当我更改类型并且不更新函数的调用者时,类型检查器会对我大喊大叫。如果我对什么是Item感兴趣,我可以直接使用Go to definition并立即查看该类型的外观。
在这方面,我不是一个绝对主义者,如果需要五个嵌套类型提示来描述单个参数,我通常会放弃并给它一个更简单但不精确的类型。根据我的经验,这种情况不会经常发生。如果它确实发生了,它实际上可能表明代码有问题——如果你的函数参数可以是一个数字、一个字符串元组或一个将字符串映射到整数的字典,这可能表明你可能想要重构和简化它。
02
二、数据类(dataclass)而不是元组(tuple)或字典(dictionary)
使用类型提示是一回事,但这仅仅描述了函数的接口是什么。第二步实际上是使这些接口尽可能精确和“锁定”。一个典型的例子是从一个函数返回多个值(或一个复杂的值)。懒惰而快速的方法是返回一个元组:
def find_person(...) -> Tuple[str, str, int]:太好了,我们知道我们要返回三个值。这些是什么?第一个字符串是人的名字吗?第二串姓氏?电话号码是多少?是年龄吗?在某些列表中的位置?社会安全号码?这种输入是不透明的,除非你查看函数体,否则你不知道这里发生了什么。
下一步“改进”这可能是返回一个字典:
def find_person(...) -> Dict[str, Any]:
...
return {
"name": ...,
"city": ...,
"age": ...
}现在我们实际上知道各个返回的属性是什么,但我们必须再次检查函数体才能找出答案。从某种意义上说,类型变得更糟,因为现在我们甚至不知道各个属性的数量和类型。此外,当这个函数发生变化并且返回的字典中的键被重命名或删除时,没有简单的方法可以用类型检查器找出来,因此它的调用者通常必须用非常手动和烦人的运行-崩溃-修改代码来改变循环。
正确的解决方案是返回一个强类型对象,其命名参数具有附加类型。在Python中,这意味着我们必须创建一个类。我怀疑在这些情况下经常使用元组和字典,因为它比定义类(并为其命名)、创建带参数的构造函数、将参数存储到字段等容易得多。自Python 3.7 (并且更快地使用package polyfill),有一个更快的解决方案-dataclasses.
@dataclasses.dataclass
class City:
name: str
zip_code: int
@dataclasses.dataclass
class Person:
name: str
city: City
age: int
def find_person(...) -> Person:你仍然需要为创建的类考虑一个名称,但除此之外,它已经尽可能简洁了,并且你可以获得所有属性的类型注释。
有了这个数据类,我就有了函数返回内容的明确描述。当我调用此函数并处理返回值时,IDE自动完成功能将向我显示其属性的名称和类型。这听起来可能微不足道,但对我来说这是一个巨大的生产力优势。此外,当代码被重构并且属性发生变化时,我的IDE和类型检查器将对我大喊大叫并向我显示所有必须更改的位置,而我根本不必执行程序。对于一些简单的重构(例如属性重命名),IDE甚至可以为我进行这些更改。此外,通过明确命名的类型,我可以构建术语词汇表( Person,City),然后可以与其他函数和类共享。
03
三、代数数据类型
在大多数主流语言中,我可能最缺乏的Rust是代数数据类型(ADT)2。它是一个非常强大的工具,可以明确描述我的代码正在处理的数据的形状。例如,当我在Rust中处理数据包时,我可以显式枚举所有可以接收的各种数据包,并为它们中的每一个分配不同的数据(字段):
enum Packet {
Header {
protocol: Protocol,
size: usize
},
Payload {
data: Vec<u8>
},
Trailer {
data: Vec<u8>,
checksum: usize
}
}通过模式匹配,我可以对各个变体做出反应,编译器会检查我没有遗漏任何情况:
fn handle_packet(packet: Packet) {
match packet {
Packet::Header { protocol, size } => ...,
Packet::Payload { data } |
Packet::Trailer { data, ...} => println!("{data:?}")
}
}这对于确保无效状态不可表示并因此避免许多运行时错误是非常宝贵的。ADT在静态类型语言中特别有用,如果你想以统一的方式使用一组类型,你需要一个共享的“名称”来引用它们。如果没有ADT,这通常是使用OOP接口和/或继承来完成的。当使用的类型集是开放式的时,接口和虚方法有它们的位置,但是当类型集是封闭的,并且你想确保你处理所有可能的变体时,ADT和模式匹配更合适。
在动态类型语言(如Python)中,实际上不需要为一组类型共享名称,主要是因为您甚至不必一开始就为程序中使用的类型命名。但是,通过创建联合类型,使用类似于ADT的东西仍然有用:
@dataclass
class Header:
protocol: Protocol
size: int
@dataclass
class Payload:
data: str
@dataclass
class Trailer:
data: str
checksum: int
Packet = typing.Union[Header, Payload, Trailer]
# or `Packet = Header | Payload | Trailer` since Python 3.10Packet这里定义了一个新类型,它可以是报头、有效载荷或尾部数据包。当我想确保只有这三个类有效时,我现在可以在程序的其余部分中使用此类型(名称)。请注意,类没有附加明确的“标签”,因此当我们要区分它们时,我们必须使用eginstanceof或模式匹配:
def handle_is_instance(packet: Packet):
if isinstance(packet, Header):
print("header {packet.protocol} {packet.size}")
elif isinstance(packet, Payload):
print("payload {packet.data}")
elif isinstance(packet, Trailer):
print("trailer {packet.checksum} {packet.data}")
else:
assert False
def handle_pattern_matching(packet: Packet):
match packet:
case Header(protocol, size): print(f"header {protocol} {size}")
case Payload(data): print("payload {data}")
case Trailer(data, checksum): print(f"trailer {checksum} {data}")
case _: assert False可悲的是,在这里我们必须(或者更确切地说,应该)包括烦人的assert False分支,以便函数在接收到意外数据时崩溃。在Rust中,这将是一个编译时错误。
注意:Reddit上的几个人已经提醒我,assert False实际上在优化构建( ) 中完全优化掉了python -O ...。因此,直接引发异常会更安全。还有typing.assert_never来自Python 3.11 的,它明确地告诉类型检查器落到这个分支应该是一个“编译时”错误。
联合类型的一个很好的属性是它是在作为联合一部分的类之外定义的。因此该类不知道它被包含在联合中,这减少了代码中的耦合。您甚至可以使用相同的类型创建多个不同的联合:
Packet = Header | Payload | Trailer
PacketWithData = Payload | Trailer联合类型对于自动(反)序列化也非常有用。最近我发现了一个很棒的序列化库,叫做pyserde,它基于古老的Rustserde序列化框架。在许多其他很酷的功能中,它能够利用类型注释来序列化和反序列化联合类型,而无需任何额外代码:
import serde
...
Packet = Header | Payload | Trailer
@dataclass
class Data:
packet: Packet
serialized = serde.to_dict(Data(packet=Trailer(data="foo", checksum=42)))
# {'packet': {'Trailer': {'data': 'foo', 'checksum': 42}}}
deserialized = serde.from_dict(Data, serialized)
# Data(packet=Trailer(data='foo', checksum=42))你甚至可以选择联合标签的序列化方式,与serde.我一直在寻找类似的功能,因为它对(反)序列化联合类型非常有用。dataclasses_json但是,在我尝试过的大多数其他序列化库(例如或)中实现它非常烦人dacite。
例如,在使用机器学习模型时,我使用联合将各种类型的神经网络(例如分类或分段CNN模型)存储在单个配置文件格式中。我还发现对不同格式的数据(在我的例子中是配置文件)进行版本化很有用,如下所示:
Config = ConfigV1 | ConfigV2 | ConfigV3通过反序列化Config,我能够读取所有以前版本的配置格式,从而保持向后兼容性。
04
四、使用newtype
在Rust中,定义不添加任何新行为的数据类型是很常见的,但只是用于指定其他一些非常通用的数据类型(例如整数)的域和预期用途。这种模式被称为“newtype”3,它也可以用在Python中。这是一个激励人心的例子:
class Database:
def get_car_id(self, brand: str) -> int:
def get_driver_id(self, name: str) -> int:
def get_ride_info(self, car_id: int, driver_id: int) -> RideInfo:
db = Database()
car_id = db.get_car_id("Mazda")
driver_id = db.get_driver_id("Stig")
info = db.get_ride_info(driver_id, car_id)发现错误?
……
……
的参数get_ride_info被交换。没有类型错误,因为汽车ID 和司机ID都是简单的整数,因此类型是正确的,即使在语义上函数调用是错误的。
我们可以通过使用“NewType”为不同类型的ID定义单独的类型来解决这个问题:
from typing import NewType
# Define a new type called "CarId", which is internally an `int`
CarId = NewType("CarId", int)
# Ditto for "DriverId"
DriverId = NewType("DriverId", int)
class Database:
def get_car_id(self, brand: str) -> CarId:
def get_driver_id(self, name: str) -> DriverId:
def get_ride_info(self, car_id: CarId, driver_id: DriverId) -> RideInfo:
db = Database()
car_id = db.get_car_id("Mazda")
driver_id = db.get_driver_id("Stig")
# Type error here -> DriverId used instead of CarId and vice-versa
info = db.get_ride_info(<error>driver_id</error>, <error>car_id</error>)这是一个非常简单的模式,可以帮助捕获难以发现的错误。它特别有用,例如,如果你正在处理许多不同类型的ID (CarId vs DriverId)或某些不应混合在一起的指标(Speed vs Lengthvs等)。Temperature
05
五、使用构造函数
我非常喜欢Rust的一件事是它本身没有构造函数。相反,人们倾向于使用普通函数来创建(理想情况下正确初始化)结构实例。在Python中,没有构造函数重载,因此如果您需要以多种方式构造一个对象,有人会导致一个__init__方法有很多参数,这些参数以不同的方式用于初始化,并且不能真正一起使用。
相反,我喜欢创建具有明确名称的“构造”函数,这使得如何构造对象以及从哪些数据构造对象变得显而易见:
class Rectangle:
@staticmethod
def from_x1x2y1y2(x1: float, ...) -> "Rectangle":
@staticmethod
def from_tl_and_size(top: float, left: float, width: float, height: float) -> "Rectangle":这使得构造对象变得更加清晰,并且不允许类的用户在构造对象时传递无效数据(例如通过组合y1和width)。
06
六、使用类型编码不变量
使用类型系统本身来编码只能在运行时跟踪的不变量是一个非常通用和强大的概念。在Python(以及其他主流语言)中,我经常看到类是可变状态的毛茸茸的大球。这种混乱的根源之一是试图在运行时跟踪对象不变量的代码。它必须考虑理论上可能发生的许多情况,因为类型系统并没有使它们成为不可能(“如果客户端已被要求断开连接,现在有人试图向它发送消息,但套接字仍然是连接”等)。
![]()
Client
这是一个典型的例子:
class Client:
"""
Rules:
- Do not call `send_message` before calling `connect` and then `authenticate`.
- Do not call `connect` or `authenticate` multiple times.
- Do not call `close` without calling `connect`.
- Do not call any method after calling `close`.
"""
def __init__(self, address: str):
def connect(self):
def authenticate(self, password: str):
def send_message(self, msg: str):
def close(self):……容易吧?你只需要仔细阅读文档,并确保你永远不会违反上述规则(以免调用未定义的行为或崩溃)。另一种方法是用各种断言填充类,这些断言会在运行时检查所有提到的规则,这会导致代码混乱、遗漏边缘情况以及出现错误时反馈速度较慢(编译时与运行时)。问题的核心是客户端可以存在于各种(互斥的)状态中,但不是单独对这些状态进行建模,而是将它们全部合并为一个类型。
让我们看看是否可以通过将各种状态拆分为单独的类型4来改进这一点。
首先,拥有一个Client不与任何东西相连的东西是否有意义?好像不是这样。这样一个未连接的客户端在您无论如何调用之前无法执行任何操作connect 。那么为什么要允许这种状态存在呢?我们可以创建一个调用的构造函数 connect,它将返回一个连接的客户端:
def connect(address: str) -> Optional[ConnectedClient]:
pass
class ConnectedClient:
def authenticate(...):
def send_message(...):
def close(...):如果该函数成功,它将返回一个支持“已连接”不变量的客户端,并且你不能connect再次调用它来搞砸事情。如果连接失败,该函数可以引发异常或返回None或一些显式错误。
类似的方法可以用于状态authenticated。我们可以引入另一种类型,它保持客户端已连接并已通过身份验证的不变性:
class ConnectedClient:
def authenticate(...) -> Optional["AuthenticatedClient"]:
class AuthenticatedClient:
def send_message(...):
def close(...):只有当我们真正拥有an的实例后AuthenticatedClient,我们才能真正开始发送消息。
最后一个问题是方法close。在 Rust 中(由于 破坏性移动语义),我们能够表达这样一个事实,即当close调用方法时,您不能再使用客户端。这在 Python 中是不可能的,所以我们必须使用一些变通方法。一种解决方案可能是回退到运行时跟踪,在客户端中引入布尔属性,并断言close它send_message尚未关闭。另一种方法可能是close完全删除该方法并仅将客户端用作上下文管理器:
with connect(...) as client:
client.send_message("foo")
# Here the client is closed没有close可用的方法,你不能意外关闭客户端两次。
![]()
强类型边界框
对象检测是我有时从事的一项计算机视觉任务,其中程序必须检测图像中的一组边界框。边界框基本上是带有一些附加数据的美化矩形,当你实现对象检测时,它们无处不在。关于它们的一个恼人的事情是有时它们被规范化(矩形的坐标和大小在interval中[0.0, 1.0]),但有时它们被非规范化(坐标和大小受它们所附图像的尺寸限制)。当你通过许多处理数据预处理或后处理的函数发送边界框时,很容易把它搞砸,例如两次规范化边界框,这会导致调试起来非常烦人的错误。
这在我身上发生过几次,所以有一次我决定通过将这两种类型的bbox分成两种不同的类型来彻底解决这个问题:
@dataclass
class NormalizedBBox:
left: float
top: float
width: float
height: float
@dataclass
class DenormalizedBBox:
left: float
top: float
width: float
height: float通过这种分离,规范化和非规范化的边界框不再容易混合在一起,这主要解决了问题。但是,我们可以进行一些改进以使代码更符合人体工程学:
通过组合或继承减少重复:
@dataclass
class BBoxBase:
left: float
top: float
width: float
height: float
# Composition
class NormalizedBBox:
bbox: BBoxBase
class DenormalizedBBox:
bbox: BBoxBase
Bbox = Union[NormalizedBBox, DenormalizedBBox]
# Inheritance
class NormalizedBBox(BBoxBase):
class DenormalizedBBox(BBoxBase):添加运行时检查以确保规范化的边界框实际上是规范化的:
class NormalizedBBox(BboxBase):
def __post_init__(self):
assert 0.0 <= self.left <= 1.0
...添加一种在两种表示之间进行转换的方法。在某些地方,我们可能想知道显式表示,但在其他地方,我们想使用通用接口(“任何类型的 BBox”)。在那种情况下,我们应该能够将“任何 BBox”转换为以下两种表示之一:
class BBoxBase:
def as_normalized(self, size: Size) -> "NormalizeBBox":
def as_denormalized(self, size: Size) -> "DenormalizedBBox":
class NormalizedBBox(BBoxBase):
def as_normalized(self, size: Size) -> "NormalizedBBox":
return self
def as_denormalized(self, size: Size) -> "DenormalizedBBox":
return self.denormalize(size)
class DenormalizedBBox(BBoxBase):
def as_normalized(self, size: Size) -> "NormalizedBBox":
return self.normalize(size)
def as_denormalized(self, size: Size) -> "DenormalizedBBox":
return self有了这个界面,我可以两全其美——为了正确性而分开的类型,以及为了人体工程学而使用统一的界面。
注意:如果你想向返回相应类实例的父类/基类添加一些共享方法,你可以typing.Self从Python 3.11 开始使用:
class BBoxBase:
def move(self, x: float, y: float) -> typing.Self: ...
class NormalizedBBox(BBoxBase):
...
bbox = NormalizedBBox(...)
# The type of `bbox2` is `NormalizedBBox`, not just `BBoxBase`
bbox2 = bbox.move(1, 2)![]()
更安全的互斥锁
Rust中的互斥锁和锁通常在一个非常漂亮的接口后面提供,有两个好处:
当你锁定互斥量时,你会得到一个保护对象,它会在互斥量被销毁时自动解锁,利用古老的RAII机制:
{
let guard = mutex.lock(); // locked here
...
} // automatically unlocked here这意味着你不会意外地忘记解锁互斥体。C++ 中也常用非常相似的机制,尽管不带保护对象的显式lock/unlock接口也可用于std::mutex,这意味着它们仍然可以被错误使用。
受互斥量保护的数据直接存储在互斥量(结构)中。使用这种设计,如果不实际锁定互斥体就不可能访问受保护的数据。您必须先锁定互斥量才能获得守卫,然后使用守卫本身访问数据:
let lock = Mutex::new(41); // Create a mutex that stores the data inside
let guard = lock.lock().unwrap(); // Acquire guard
*guard += 1; // Modify the data using the guard这与主流语言(包括Python)中常见的互斥锁API形成鲜明对比,其中互斥锁和它保护的数据是分开的,因此你很容易忘记在访问数据之前实际锁定互斥锁:
mutex = Lock()
def thread_fn(data):
# Acquire mutex. There is no link to the protected variable.
mutex.acquire()
data.append(1)
mutex.release()
data = []
t = Thread(target=thread_fn, args=(data,))
t.start()
# Here we can access the data without locking the mutex.
data.append(2) # Oops虽然我们无法在Python中获得与在Rust中获得的完全相同的好处,但并非全部都失去了。Python锁实现了上下文管理器接口,这意味着你可以在块中使用它们with以确保它们在作用域结束时自动解锁。通过一点努力,我们可以走得更远:
import contextlib
from threading import Lock
from typing import ContextManager, Generic, TypeVar
T = TypeVar("T")
# Make the Mutex generic over the value it stores.
# In this way we can get proper typing from the `lock` method.
class Mutex(Generic[T]):
# Store the protected value inside the mutex
def __init__(self, value: T):
# Name it with two underscores to make it a bit harder to accidentally
# access the value from the outside.
self.__value = value
self.__lock = Lock()
# Provide a context manager `lock` method, which locks the mutex,
# provides the protected value, and then unlocks the mutex when the
# context manager ends.
@contextlib.contextmanager
def lock(self) -> ContextManager[T]:
self.__lock.acquire()
try:
yield self.__value
finally:
self.__lock.release()
# Create a mutex wrapping the data
mutex = Mutex([])
# Lock the mutex for the scope of the `with` block
with mutex.lock() as value:
# value is typed as `list` here
value.append(1)使用这种设计,你只能在实际锁定互斥锁后才能访问受保护的数据。显然,这仍然是Python,因此你仍然可以打破不变量——例如,通过在互斥量之外存储另一个指向受保护数据的指针。但是除非你的行为是敌对的,否则这会使Python中的互斥接口使用起来更安全。
不管怎样,我确信我在我的Python代码中使用了更多的“稳健模式”,但目前我能想到的就是这些。如果你有类似想法的一些示例或任何其他评论,请告诉我。
公平地说,如果你使用某种结构化格式(如 reStructuredText),文档注释中的参数类型描述可能也是如此。在那种情况下,类型检查器可能会使用它并在类型不匹配时警告你。但是,如果你无论如何都使用类型检查器,我认为最好利用“本机”机制来指定类型——类型提示。
aka discriminated/tagged unions, sum types, sealed classes, etc.
是的,除了这里描述的,新类型还有其他用例,别再对我大喊大叫了。
这被称为typestate 模式。
除非你努力尝试,例如手动调用魔术__exit__方法。
码字不易,欢迎大家点赞转发收藏,感谢!
<END>