文章目录
- 一,接前一天
- (1).内容前先弄清楚 `sess.run()` 函数
- a. 该函数干嘛的
- b. 该函数有哪些参数
- c. 该函数的使用
- (2).由库函数创建张量
- (3).由库函数创建张量
- 二、变量`tf.Variable()`
- (1).啥是变量
- (2).什么情况下会用该变量函数
- (3).通过变量来创建张量
- 三、变量 `tf.Variable()` 与 `tf.placeholder()` 的区别
- 1.初始化
- 2. 数据类型和形状
- 3. 可训练性
- 4. 更新方式
- 总结:
- 四、`tf.get_variable()`获取变量
一,接前一天
(1).内容前先弄清楚 sess.run() 函数
a. 该函数干嘛的
sess.run() 函数是 TensorFlow 中最核心的执行函数之一,用于在会话中执行计算图上的操作和张量,并返回相应的结果。
看到了:该函数是用来创建一个会话对象。在这个会话中,我们可以执行模型中定义好的操作和张量
b. 该函数有哪些参数
sess.run()
#来看下源代码
run(self, feed_dict=None, session=None)
'''
fetches(必选)也就是:需要执行的操作或张量,可以是单个张量、操作,也可以是由它们组成的列表、元组或字典等形式。
feed_dict(可选):用于传递数据的占位符字典。该参数默认为空字典,如果图中存在占位符,则 feed_dict 必须提供相应的数值,否则会抛出异常。
session=None:指定我们的回话对象,在进行初始化的时候,这里就要显式的说明
例如:
# 创建一个会话
test = tf.Session()
tf.global_variables_initializer().run(session=test)
'''
下面分别对这两个参数进行详细解释:
fetches
fetches参数用于指定需要在会话中执行的操作或者张量,可以传入单个操作或者张量,也可以传入一个列表、元组或字典等形式。fetches 参数有以下几种常见的情况:
–传入单个张量或操作,返回该张量或操作的计算结果。
传入多个张量或操作的列表或元组,返回所有张量或操作的计算结果。
–传入字典,键为字符串,值为张量或操作,返回字典中所有张量或操作的计算结果。
例如,我们可以通过 sess.run() 函数来获取两个张量的值:
import tensorflow as tf
a = tf.constant(2)
b = tf.constant(3)
c = a + b
with tf.Session() as sess:
print(sess.run([a, b]))
feed_dict
feed_dict参数用于传递占位符的值,以便在会话中执行计算。在 TensorFlow 中,占位符是一种特殊的张量,它没有具体的数值,但在使用时必须提供相应的数据。feed_dict参数可以是一个字典,其中键为占位符张量,值为需要填充的数值。
例如,我们可以通过 feed_dict 参数来设置占位符变量的值:
import tensorflow as tf
x = tf.placeholder(tf.float32, shape=[None])
y = 2 * x
with tf.Session() as sess:
result = sess.run(y, feed_dict={x: [1, 2, 3]})
print(result)
c. 该函数的使用
我们来使用一下:
import tensorflow as tf
#创建占位符
x = tf.placeholder(tf.float32, shape=[None])
y = 2 * x
with tf.Session() as sess:
#创建一个会话对象,赋值给sess
result = sess.run(y, feed_dict={x: [1, 2, 3]})
#在该会话中执行定义好的操作 和 张量
print(result)
(2).由库函数创建张量
test3 = tf.zeros((2,3))
print('tensor test3:',test3)
print('run test3:',test.run(test3))

(3).由库函数创建张量
二、变量tf.Variable()
(1).啥是变量
在 TensorFlow 1.x 版本中,tf.Variable() 函数用于创建一个可训练的张量,也就是变量。变量在模型的训练过程中会被反复更新,用于存储和更新模型参数。与常规张量不同的是,变量在创建时需要初始化,并且可以持久化到磁盘上。通过变量,可以方便地定义和管理模型参数,从而加快模型训练的速度和效果。
(2).什么情况下会用该变量函数
在神经网络模型中,我们通常需要定义一些可训练的参数,例如:权重和偏置项等。这些参数会在模型的训练过程中被反复更新以优化模型性能。使用 tf.Variable() 函数可以方便地创建这些参数。
举个例子,假设我们要实现一个简单的线性回归模型 y = wx + b,其中 w 和 b 是待学习的参数。我们可以使用 tf.Variable() 函数来创建这两个变量:
import tensorflow as tf
# create w and b init 0.0
w = tf.Variable(0.0, name='weight')
b = tf.Variable(0.0, name='bias')
# create input and out
x = tf.placeholder(dtype=tf.float32, shape=[None])
out = tf.placeholder(dtype=tf.float32, shape=[None])
# create loss and opt
y = w * x + b
loss = tf.reduce_mean(tf.square(y - out))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.005)
train_op = optimizer.minimize(loss)
# train model
with tf.Session() as sess:
tf.global_variables_initializer().run(session=sess)
for i in range(1000):
_, loss_val, w_val, b_val = sess.run(
[train_op, loss, w, b],
feed_dict={x: [1, 23, 4, 5, 7, 5, 7], out: [3, 5, 7, 9, 11, 13, 15]}
) #注意 输入的数据 形状要一致,避免输出与预测值得形状不一致问题
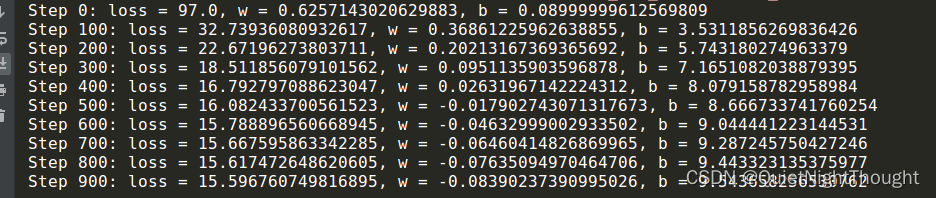
if i % 100 == 0:
print('Step {}: loss = {}, w = {}, b = {}'.format(i, loss_val, w_val, b_val))
(3).通过变量来创建张量
import tensorflow as tf
import numpy as np
from pprint import pprint
#TODO 创建一个会话
test = tf.Session()
w = tf.Variable([5.0],tf.float32)
b = tf.Variable([6.0],tf.float32)
x = tf.placeholder(tf.float32)
y = w * x + b
print('w:',w)
print('b:',b)
print('x:',x)
print('y:',y)
tf.global_variables_initializer().run(session = test)
print('run y:',test.run(y,feed_dict={x:[1,2,3,4]}))

使用tf.Variable()创建变量时,需要注意以下几点:
- 变量的初始值需要在创建时指定,可以是
常量,也可以是随机数等。 变量的类型需要与初始值相匹配,比如:创建一个整型变量时,初始值必须为整数。- 在使用变量前,需要通过调用
tf.global_variables_initializer()来初始化所有变量。 - 变量在计算图中有自己的
作用域,需要注意命名空间的规范,便于管理和调试。 - 变量的生命周期需要谨慎管理,避免内存泄漏或者过早释放。
三、变量 tf.Variable() 与 tf.placeholder() 的区别
在 TensorFlow 中,tf.Variable() 和 tf.placeholder() 都是非常重要的变量类型,它们有以下几个不同点:
1.初始化
tf.Variable() 变量在创建时需要进行初始化,并且可以持久化到磁盘上。我们通常使用 tf.global_variables_initializer() 函数来初始化所有变量。例如:
import tensorflow as tf
# 创建变量 w 和 b
w = tf.Variable(0.0, name='weight')
b = tf.Variable(0.0, name='bias')
with tf.Session() as sess:
# 初始化所有变量
sess.run(tf.global_variables_initializer())
而 tf.placeholder() 变量没有具体的值,只是一个占位符,因此也不需要进行初始化。它通常用于定义模型的输入和输出等信息。
2. 数据类型和形状
tf.Variable() 和 tf.placeholder() 变量都可以指定数据类型和形状。在使用 tf.Variable() 创建变量时,我们需要明确指定变量的形状和数据类型。例如:
import tensorflow as tf
# 创建一个形状为 [2, 3],数据类型为 float32 的变量
x = tf.Variable(tf.zeros([2, 3]), dtype=tf.float32)
而在使用 tf.placeholder() 时,我们可以通过 shape 参数来指定占位符的形状,数据类型则可以通过传入的数值来自动推断。例如:
import tensorflow as tf
# 定义一个形状为 [None, 3] 的占位符,数据类型自动推断
x = tf.placeholder(dtype=tf.float32, shape=[None, 3])
'''
自动推断的意思是:当我们使用占位符创建了指定数据类型,在给他传参的时候,无需一致,该函数会自动识别为 我们指定的数据类型
'''
3. 可训练性
tf.Variable() 变量是可训练的,它们在模型的训练过程中会被反复更新以优化模型性能。而 tf.placeholder() 变量没有训练参数,只是一个占位符,用于定义模型的输入和输出等信息。
4. 更新方式
对于 tf.Variable() 变量,我们可以使用 assign 或 assign_add 等方法来更新变量的值。例如:
import tensorflow as tf
# 创建变量 w 和 b,并初始化为0.0
w = tf.Variable(0.0, name='weight')
b = tf.Variable(0.0, name='bias')
# 使用 assign 方法更新 w 的值
sess.run(w.assign(2.0))

而对于 tf.placeholder() 变量,其值不能直接更新,需要通过传递新的数值来重新计算相应的张量或操作。
总结:
- 在 TensorFlow 中,
tf.placeholder()是一个占位符变量,它不是具体的数值,只是一个形状和数据类型都已经确定的张量。在计算图中使用tf.placeholder()可以定义模型的输入和输出等信息,然后通过feed_dict 参数来传递具体的数值.
例如:
import tensorflow as tf
# 创建一个形状为 [None, 3] 的占位符,数据类型为 float32
x = tf.placeholder(dtype=tf.float32, shape=[None, 3])
# 定义一个操作 y,将 x 向量与常量向量相加
y = x + tf.constant([1.0, 2.0, 3.0])
with tf.Session() as sess:
# 将 [4, 5, 6] 作为 x 的值,计算 y 的结果
result = sess.run(y, feed_dict={x: [[1, 2, 3], [4, 5, 6]]})
print(result)
tf.Variable()则是一个具体的数值,它可以被更新和持久化到磁盘上。在使用tf.Variable()创建变量时,我们需要指定变量的初始值和数据类型
import tensorflow as tf
# 创建一个训练变量 w,初始值为 0.0
w = tf.Variable(0.0, dtype=tf.float32)
# 定义一个操作 loss,将 w 的平方与常量 2 相加
loss = tf.square(w) + 2
with tf.Session() as sess:
# 初始化所有变量
sess.run(tf.global_variables_initializer())
# 计算 loss 的结果
result = sess.run(loss)
print(result)
- 在使用 tf.Variable() 变量时,需要给它传递一个初始值,并在计算前进行初始化才能保证正常计算。
注意:在 TensorFlow 中,使用 tf.Variable() 创建变量时需要为其指定一个初始值。如果在创建变量时给定了初始值,那么在计算前进行初始化之后,变量的值就会被更新。
那么为什么既然会被初始化更新掉还要给与初始值呢?
在 TensorFlow 中,给变量指定一个初始值的目的是为了在计算图中建立变量节点,并确定它的数据类型、形状和初值等属性。这样做有以下几个好处:
原因二:确定变量的数据类型、形状和初值等属性,使得我们能够更方便地使用变量进行计算。
原因三:在计算图中明确地标记变量节点,使得我们能够更方便地对其进行操作和管理。
原因四:变量的初值可以作为一种默认值,在初始化时如果没有手动赋值,就会自动使用默认值进行初始化。
原因五:在实际的工作中,我们通常会需要手动给变量赋初值,并在计算前对变量进行初始化。这样做主要是为了保证变量的初值和计算结果符合预期。
四、tf.get_variable()获取变量
tf.get_variable()的好处:
一般来说:如果我们定义的变量名称在之前已经定义过,再次定义的时候那么TensorFlow就会报错。若果此时我们使用tf.get_variable()函数来替代tf.variable()函数,就会避免这种情况。使用tf.get_variable()后,如果变量已经定义过,该函数就会直接返回变量,若果变量之前未被定义,则该函数就会从新定义。
例如:
import tensorflow as tf
# 定义一个变量 x
x = tf.Variable(tf.random_normal([10]), name='x')
# 使用 x 的名称来创建一个新变量 y,并共享 x 的值
y = tf.get_variable(name='x', shape=[10], dtype=tf.float32, initializer=tf.constant_initializer(0.0))
with tf.Session() as sess:
# 初始化所有变量
sess.run(tf.global_variables_initializer())
# 输出变量 x 和 y 的数值
print('x:', sess.run(x))
print('y:', sess.run(y))
注意:由于我们使用了 tf.get_variable() 方法,因此在创建变量时需要指定变量的名称、形状、数据类型以及初始化器等参数
另外:
如果要通过 tf.get_variable() 方法继承已经定义的变量,那么必须要在创建计算图时指定 reuse=True 参数,以告知 TensorFlow 允许共享变量。如果没有指定 reuse=True,那么 TensorFlow 将会默认禁止变量共享,从而导致错误。
在分布式TensorFlow中, tf.get_variable() 获取得到全局变量,若要得到局部变量,则使用:tf.get_local_variable()