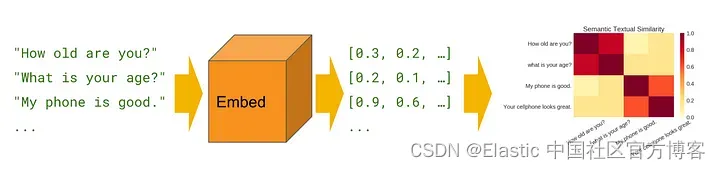
语义/矢量搜索是一种强大的技术,可以大大提高搜索结果的准确性和相关性。 与传统的基于关键字的搜索方法不同,语义搜索使用单词的含义和上下文来理解查询背后的意图并提供更准确的结果。 Elasticsearch 是实现语义搜索最流行的工具之一,它是一种高度可扩展且功能强大的搜索引擎,可用于索引和搜索大量数据。 在本文中,我们将探讨语义搜索的基础知识以及如何使用 Elasticsearch 实现它。 到本文结束时,你将深入了解语义搜索的工作原理以及在你自己的项目中实现它的实用技能。
在进行下面的讲解之前,我需要特别指出的是:Elastic 提供了 eland 帮助我们上传在 huggingface.co 上的模型。我们在摄入文档的时候,可以试验 inference processor 来方便地进行数据字段的矢量化。eland 上传及机器学习是 Elastic 的收费项目。本文章将使用 Tensorflow 来通过代码的方式来获得矢量,并上传到 Elasticsearch。更多关于使用 eland 及机器学习上传模型的方法,请详细阅读 “Elastic:开发者上手指南” 中的 “NLP - 自然语言处理及矢量搜索” 章节。
Elasticsearch
Elasticsearch 是一个基于 Lucene 库的强大且可扩展的免费及开发的搜索引擎。 它旨在处理大量非结构化数据并提供快速准确的搜索结果。 Elasticsearch 使用分布式架构,这意味着它可以横向扩展到多个服务器以处理大量数据和流量。
Elasticsearch 建立在 RESTful API 之上,这使得它可以轻松地与各种编程语言和工具集成。 它支持复杂的搜索查询,包括全文搜索、分面搜索和地理搜索。 Elasticsearch 还提供了一个强大的聚合框架,允许你对搜索结果进行复杂的数据分析。
Transformers
Transformers 是一种机器学习模型,它彻底改变了自然语言处理 (NLP) 任务,例如语言翻译、文本摘要和情感分析。 Vaswani 等人首先介绍了 transformer。 在 2017 年的一篇论文 “Attention Is All You Need” 中,此后已成为许多 NLP 任务的最先进模型。
与循环循环神经网络 (RNN) 和卷积神经网络 (CNN) 的传统 NLP 模型不同,Transformer 使用 self-attention 机制来捕捉句子中单词之间的关系。 Self-attentiion 允许模型关注输入序列的不同部分,以确定单词之间最重要的关系。 这使得转换器比传统模型更有效地处理单词之间的远程依赖关系和上下文关系。
对于本文,我将使用 TensorFlow 的通用句子编码器对我的数据进行编码/矢量化。 你也可以选择任何其他形式的编码器。另外值得指出的是:tensorflow 在 Apple 的芯片上不能得到支持。你需要使用 x86 的机器来进行练习。
为了方便大家学习,我把代码放在地址:https://github.com/liu-xiao-guo/Semantic-Search-ElasticSearch
准备工作
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考文章:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在我们的本次练习中,我们将使用 Elastic Stack 8.8 版本。在 Elasticsearch 首次启动的时候,它会出现如下的屏幕:
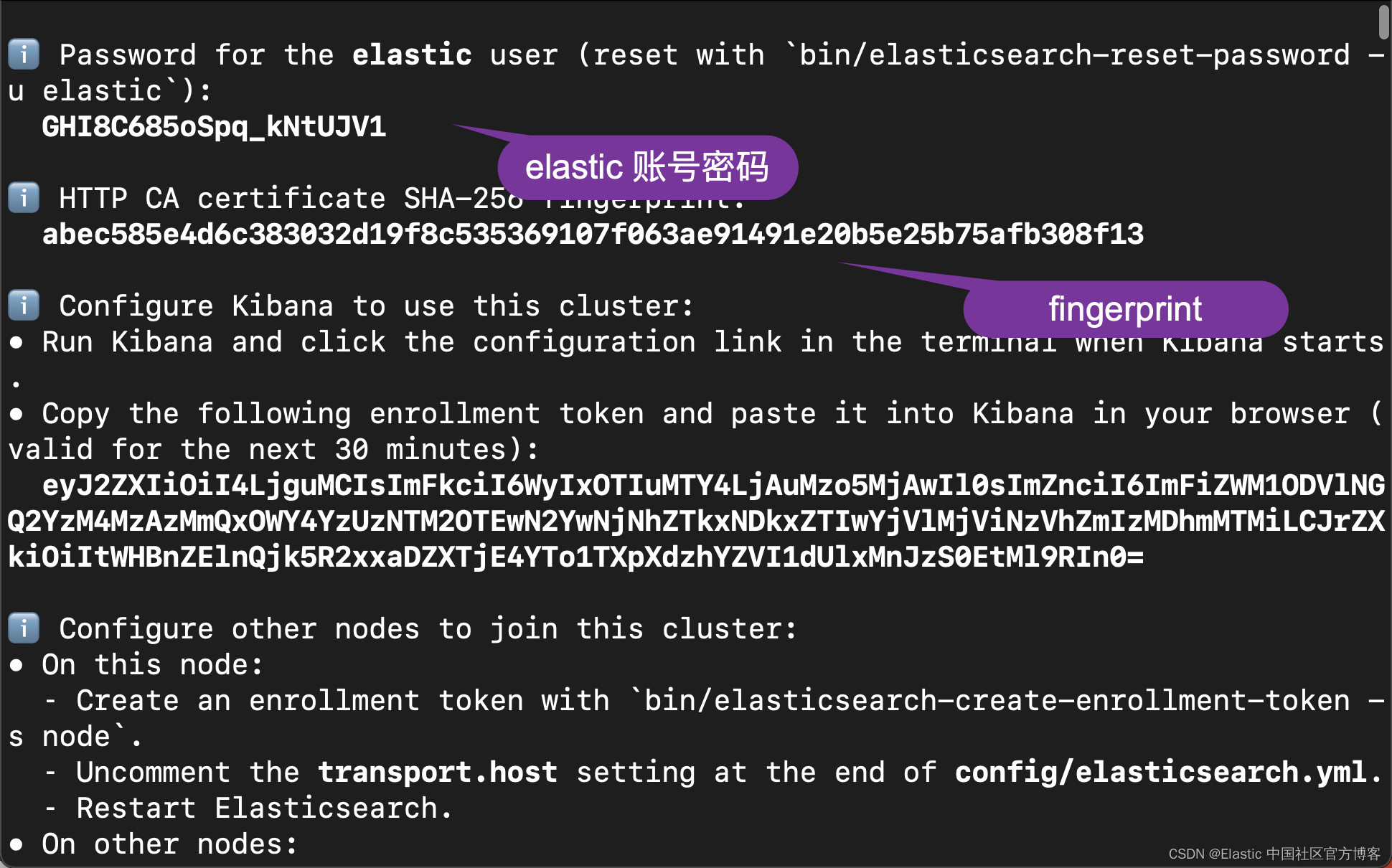
我们记下 elastic 用户的密码及 fingerprint。这些信息在一下的代码中进行使用。
Python
你需要在自己的电脑上安装 Python:
$ python --version
Python 3.10.6你同时需要安装如下的 Python 库:
pip3 install elasticsearch
pip3 install tensorflow_hub
pip3 install tensorflow
pip3 install pandas
pip3 install numpyTensorflow 模型
你需要去地址 https://tfhub.dev/google/universal-sentence-encoder/4 下载 universal-sentence-encoder 模型。下载完后,你把它置于代码根目录下的 model 子目录下:
$ pwd
/Users/liuxg/python/Semantic-Search-ElasticSearch
$ ls
README.md model
Semantic_Search_ElasticSearch.py sample.csv
$ tree -L 3
.
├── README.md
├── Semantic_Search_ElasticSearch.py
├── model
│ ├── assets
│ ├── saved_model.pb
│ ├── universal-sentence-encoder_4.tar.gz
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
└── sample.csv
我们在 model 子目录下,打入如下的命令来解压缩文件 universal-sentence-encoder_4.tar.gz:
tar xzf universal-sentence-encoder_4.tar.gz样本文件
如上所示,我准备了一个叫做 sample.csv 的文件。它的内容非常之简单:
sample.csv
Text,Price,Quantity
"The latest phone model",5000,10
"The best seller phone",2000,50也就是只有两个文档。你可以根据自己的情况修改这个文档。
代码
我先把代码贴出来:
Semantic_Search_ElasticSearch.py
from elasticsearch import Elasticsearch
import tensorflow_hub as hub
import tensorflow.compat.v1 as tf
import pandas as pd
import numpy as np
df = pd.read_csv('./sample.csv')
print(df['Text'][0])
model = hub.load("./model")
graph = tf.Graph()
with tf.Session(graph = graph) as session:
print("Loading pre-trained embeddings")
embed = hub.load("./model")
text_ph = tf.placeholder(tf.string)
embeddings = embed(text_ph)
print("Creating tensorflow session…")
session = tf.Session()
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
vectors = session.run(embeddings, feed_dict={text_ph: df['Text']})
print("vectors length: ", len(vectors))
print(vectors)
vector = []
for i in vectors:
vector.append(i)
df["Embeddings"] = vector
# Connect to the elastic cluster
# Password for the 'elastic' user generated by Elasticsearch
USERNAME = "elastic"
PASSWORD = "GHI8C685oSpq_kNtUJV1"
ELATICSEARCH_ENDPOINT = "https://localhost:9200"
CERT_FINGERPRINT = "abec585e4d6c383032d19f8c535369107f063ae91491e20b5e25b75afb308f13"
es = Elasticsearch(ELATICSEARCH_ENDPOINT,
ssl_assert_fingerprint = (CERT_FINGERPRINT),
basic_auth=(USERNAME, PASSWORD),
verify_certs = True)
resp = es.info()
print(resp)
configurations = {
"settings": {
"index": {"number_of_replicas": 2},
"analysis": {
"filter": {
"ngram_filter": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 15,
}
},
"analyzer": {
"ngram_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "ngram_filter"],
}
}
}
},
"mappings": {
"properties": {
"Embeddings": {
"type": "dense_vector",
"dims": 512,
"index": True,
"similarity": "cosine"
},
}
}
}
INDEX_NAME = "vectors"
if(es.indices.exists(index=INDEX_NAME)):
print("The index has already existed, going to remove it")
es.options(ignore_status=404).indices.delete(index=INDEX_NAME)
es.indices.create( index=INDEX_NAME,
settings=configurations["settings"],
mappings=configurations["mappings"]
)
actions = []
for index, row in df.iterrows():
action = {"index": {"_index": INDEX_NAME, "_id": index}}
doc = {
"id": index,
"Text": row["Text"],
"Price": row["Price"],
"Quantity": row["Quantity"],
"Embeddings": row["Embeddings"]
}
actions.append(action)
actions.append(doc)
es.bulk(index=INDEX_NAME, operations=actions, refresh=True)
query = "Which is the latest phone available in your shop"
def embed_text(text):
vectors = session.run(embeddings, feed_dict={text_ph: text})
return [vector.tolist() for vector in vectors]
query_vector = embed_text([query])[0]
print(query_vector)
query = {
"field": "Embeddings",
"query_vector": query_vector,
"k": 10,
"num_candidates": 100
}
source_fields = ["Text", "Price", "Quantity"]
response = es.search(
index="vectors",
fields=source_fields,
knn=query,
source=False)
print(response)这是整个代码。虽然看起来简单,但是在调试的时候还是出现了一些状况。
安装 Python 依赖项后,你将需要文本数据作为开始。 获取文本数据后,在你喜欢的 IDE 中使用 python 读取它。
from elasticsearch import Elasticsearch
import tensorflow_hub as hub
import tensorflow.compat.v1 as tf
import pandas as pd
import numpy as np
df = pd.read_csv('./sample.csv')
print(df['Text'][0])读取文本数据后,第一个任务是将其转换为向量或嵌入。 在这里,正如我之前提到的,我使用的是 TensorFlow 的通用句子编码器,它在提供字符串后输出 “512” 维度的向量/嵌入。
这对于其他转换器/矢量化器会有所不同,你需要记住这一点以便进一步执行步骤。
model = hub.load("./model")成功加载模型后,现在我们的下一个任务是将数据集中的文本转换为向量/嵌入,并将其存储在名为 “Embeddings” 的新字段/列中。
graph = tf.Graph()
with tf.Session(graph = graph) as session:
print("Loading pre-trained embeddings")
embed = hub.load("./model")
text_ph = tf.placeholder(tf.string)
embeddings = embed(text_ph)
print("Creating tensorflow session…")
session = tf.Session()
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
vectors = session.run(embeddings, feed_dict={text_ph: df['Text']})
print("vectors length: ", len(vectors))
print(vectors)
vector = []
for i in vectors:
vector.append(i)
df["Embeddings"] = vector注意:在我的数据集中,我有一个名为 “Text” 的字段/列。 根据你的数据集将其更改为字段名称。
一旦嵌入完成并存储在新字段中,就可以将此数据插入我们系统中的 Elasticsearch,你应该已经在本教程开始时安装了它。
要插入数据,我们首先必须连接到 Elasticsearch,所有这一切都将使用 python 进行。
USERNAME = "elastic"
PASSWORD = "GHI8C685oSpq_kNtUJV1"
ELATICSEARCH_ENDPOINT = "https://localhost:9200"
CERT_FINGERPRINT = "abec585e4d6c383032d19f8c535369107f063ae91491e20b5e25b75afb308f13"
es = Elasticsearch(ELATICSEARCH_ENDPOINT,
ssl_assert_fingerprint = (CERT_FINGERPRINT),
basic_auth=(USERNAME, PASSWORD),
verify_certs = True)
resp = es.info()
print(resp)有关这个部分的描述,请详细阅读我之前的文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”。
要验证连接是否已建立,你可以在首选浏览器上打开 https://localhost:9200 并检查。 你还可以通过运行 es.ping() 从你的 IDE 检查连接。 对于成功的连接,输出应该是 True。
现在我们已经建立了与 Elasticsearch 的连接,让我们继续配置 Elasticsearch 索引。
configurations = {
"settings": {
"index": {"number_of_replicas": 2},
"analysis": {
"filter": {
"ngram_filter": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 15,
}
},
"analyzer": {
"ngram_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "ngram_filter"],
}
}
}
},
"mappings": {
"properties": {
"Embeddings": {
"type": "dense_vector",
"dims": 512,
"index": True,
"similarity": "cosine"
},
}
}
}
INDEX_NAME = "vectors"
if(es.indices.exists(index=INDEX_NAME)):
print("The index has already existed, going to remove it")
es.options(ignore_status=404).indices.delete(index=INDEX_NAME)
es.indices.create( index=INDEX_NAME,
settings=configurations["settings"],
mappings=configurations["mappings"]
)在上述配置的帮助下,我们能够配置插入数据的索引。 也就是说,让我们仔细看看一些重要的参数。
- “type”:类型必须始终设置为 “dense_vector”。 这样做是为了让 ElasticSearch 知道这些是向量,并且不会自行将浮动类型分配给该字段。
- “dims”:也即维度。 就像我之前提到的,Universal Sentence Encoder 产生和输出 512 维度,这就是我们在参数中提供 512 的原因。
- “index”:Index 必须设置为 True,以便创建该字段并在 ElasticSearch 中具有 dense_vector 类型。
- “similarity”:我们正在寻找余弦相似性并已经提到了它。 你也可以选择其他选项。具体可以参考链接。
配置索引后,现在让我们继续创建这个索引。在我们的应用中,我们选择 index 的名字为 vectors。
在这里,我将索引命名为 vectors。 有了这个,我们的索引已经用我们的配置创建了,最后我们准备好将我们的数据插入到 Elasticsearch 上的这个索引中。
actions = []
for index, row in df.iterrows():
action = {"index": {"_index": INDEX_NAME, "_id": index}}
doc = {
"id": index,
"Text": row["Text"],
"Price": row["Price"],
"Quantity": row["Quantity"],
"Embeddings": row["Embeddings"]
}
actions.append(action)
actions.append(doc)
es.bulk(index=INDEX_NAME, operations=actions, refresh=True)在上面的代码中,我们必须注意的是 refresh 必须设置为 True,否则在下面立马进行搜索的时候,我们可能得不到任何的结果,这是因为在通常的情况下,需要 1 分钟的时间才能使得刚写入的文档变为可以搜索的。借助以上代码,你将能够将数据插入 Elasticsearch。
搜索数据
插入数据后,我们现在可以搜索此数据并提出一些相关问题。 为此,让我们从一个我们想要获得答案的问题开始。
query = "Which is the latest phone available in your shop?"现在,由于我们需要在 Elasticsearch 上进行语义搜索,我们需要将此文本转换为嵌入/向量。
query = "Which is the latest phone available in your shop"
def embed_text(text):
vectors = session.run(embeddings, feed_dict={text_ph: text})
return [vector.tolist() for vector in vectors]
query_vector = embed_text([query])[0]
print(query_vector)现在 query_vector 含有 “Which is the latest phone available in your shop” 所转换而来的向量。
将文本转换为嵌入/向量后,我们就可以根据 Elasticsearch 中的现有数据搜索此文本。 为此,我们首先必须构建一个查询以从 Elasticsearch 获取数据。
query = {
"field": "Embeddings",
"query_vector": query_vector,
"k": 10,
"num_candidates": 100
}
source_fields = ["Text", "Price", "Quantity"]
response = es.search(
index="vectors",
fields=source_fields,
knn=query,
source=False)
print(response)使用上面提供的代码,我们可以从 Elasticsearch 进行查询。 但在我们看下一步之前,让我们仔细看看这个查询并理解它。
- “knn”:Elasticsearch 支持 K-Nearest Neighbors a.k.a kNN 算法并且已经在 Elasticsearch 中可用。 你不需要单独训练它。
- “field”:你的嵌入/向量存储在 Elasticsearch 中的字段。
- “query_vector”:你以向量/嵌入形式输入。
- “k”:你需要的输出/搜索结果数。
- “num_candidates”:earch API finds a
num_candidatesnumber of approximate nearest neighbor candidates on each shard.
借助上述查询,你将能够从之前存储数据的索引中获取搜索结果。
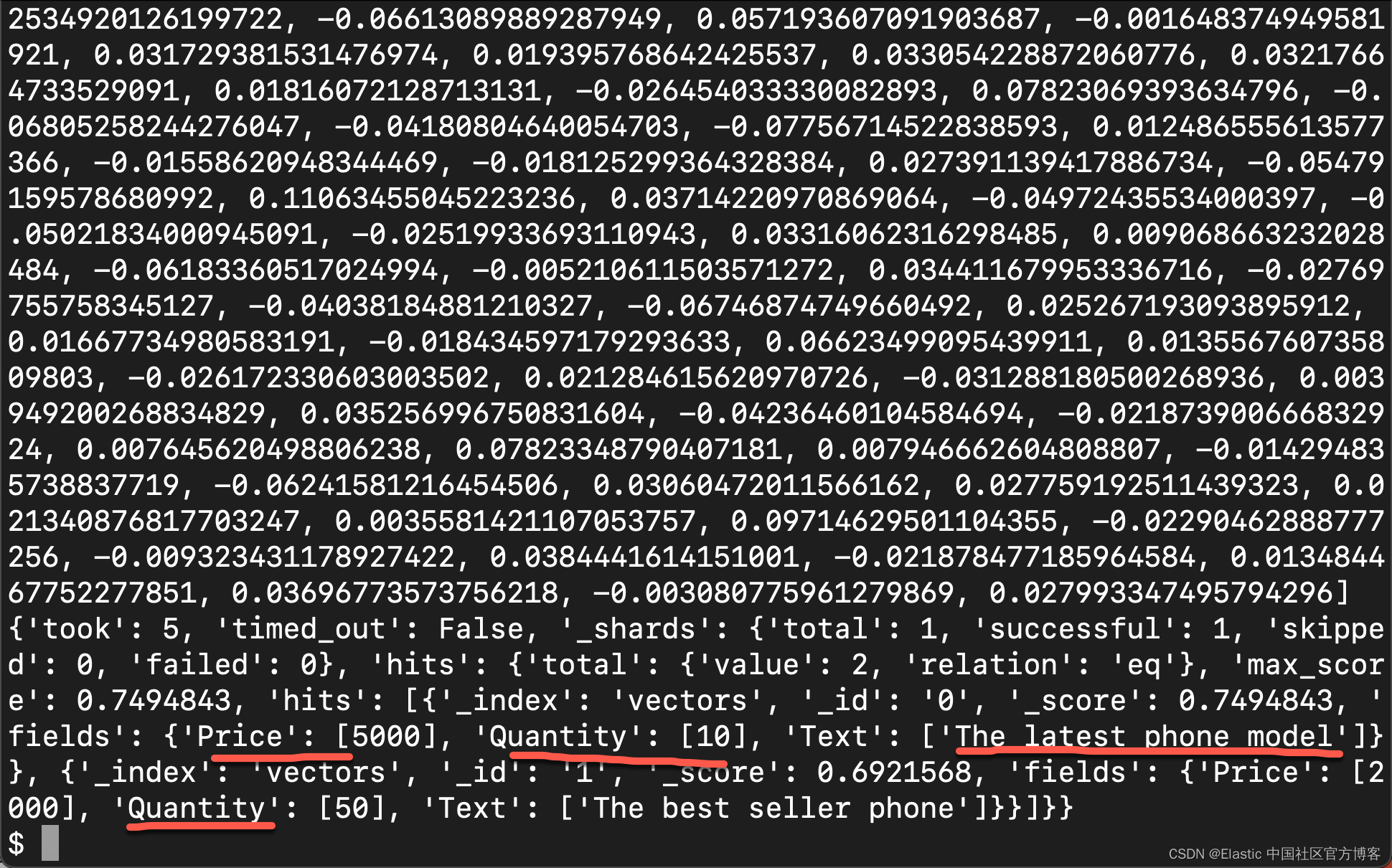
请记住,你只能对具有配置字段的索引执行语义搜索,该字段包含嵌入/向量作为 "type": "dense_vector" 并且向量维度必须与你的查询/问题和存储在 Elasticsearch 中的数据完全相同 . 例如,在上面的教程中,我们在 Elasticsearch 中的数据是 512 维度,在我们继续搜索操作之前,query/question 也被转换为 512 维度。
结论
总之,语义搜索是一种强大的工具,可以通过理解单词的含义和上下文来大大提高搜索结果的准确性和相关性。 Elasticsearch 是一个高度可扩展且灵活的搜索引擎,可用于为从电子商务到医疗保健的各种应用程序实现语义搜索。 通过利用 Elasticsearch 强大的搜索和索引功能,以及查询扩展、同义词检测和实体识别等技术,你可以构建一个提供快速准确结果的语义搜索系统。 无论你是开发人员、数据科学家还是企业主,使用 Elasticsearch 掌握语义搜索都可以帮助你从数据中获得新的见解和机会。 那为什么还要等? 立即开始使用 Elasticsearch 探索语义搜索的强大功能!