本博客主要讲解了Emotionally Enhanced Talking Face Generation(情感增强的谈话人脸生成)论文概括与项目实现,以及代码理解。
Emotionally Enhanced Talking Face Generation
Paper :https://arxiv.org/pdf/2303.11548.pdf
Code: GitHub - sahilg06/EmoGen: PyTorch Implementation for Paper "Emotionally Enhanced Talking Face Generation"
(克隆项目下载权重后,可直接进行推理)
目录
论文概括
项目实现
1.环境设置
2.数据处理及项目运行
3.开始训练
3.1.训练专家鉴别器
3.2.训练情绪鉴别器
3.3.训练最终模型
4.推理
过程中遇到的问题及解决(PS)
代码详解(按运行顺序)
论文概括
论文创新点
- 输入视频,任意人脸+情绪合成
- 提出了一个新的深度学习模型,可以生成照片般逼真的唇语人脸视频,其中包含了不同的情绪和相关表情。
- 引入了一个多模态框架,以生成与任何任意身份、语言和情感无关的唇语视频。
- 开发了一个基于网络的响应式界面,用于实时生成带有情绪的对话脸。
模型框架
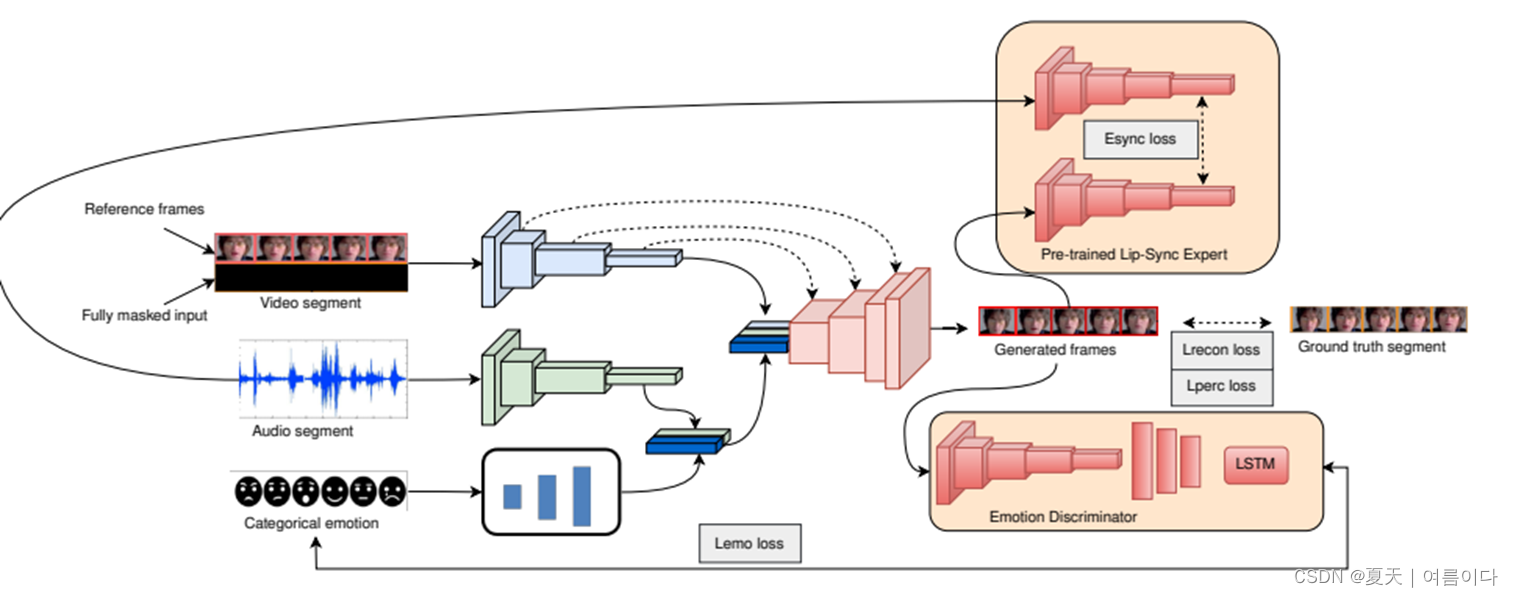

项目实现
1.环境设置
Ubuntu(docker 容器) ,torch-gpu,cuda11.7
克隆项目,
git clone https://github.com/sahilg06/EmoGen
cd EmoGen安装相关库
sudo apt-get install ffmpeg
pip install -r requirements.txt
#相关库
pip install albumentations配置下载命令工具,安装git lfs
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
apt-get install git-lfs
git lfs install下载CREMA-D数据集命令 (使用git clone会出错)
git lfs clone https://github.com/CheyneyComputerScience/CREMA-D.git
2.数据处理及项目运行
运行
python convertFPS.py -i /workspace/facegan/EmoGen/CREMA-D/VideoFlash -o /workspace/facegan/EmoGen/CREMA-D/flv-output
将视频文件(.flv)每25帧截图保存为flv-output文件夹。(文件夹名自己设置)
如果出错可参考【PS3】

(等大概25分钟左右)
接着处理MP4文件,截取数据集的人脸部分,且每个人,每个人的心情等划分为不同的文件夹:
运行
python preprocess_crema-d.py --data_root /workspace/facegan/EmoGen/CREMA-D/flv-output --preprocessed_root preprocessed_dataset/如果出错可参考【PS4/5】,运行过程如图

(大约运行3小时)
3.开始训练
主要分为三个步骤:
- 训练专家口型同步鉴别器
- 训练情绪鉴别器
- 训练 EmoGen 模型
3.1.训练专家鉴别器
(如果只有一个gpu,或者内存不大需要修改相关代码)
相关参数在hparams.py中,可修改batch_size和num_workers(默认为batch_size=16,num_workers=16)
python color_syncnet_train.py --data_root preprocessed_dataset/ --checkpoint_dir sync-checkpoint开始训练

运行16小时后epoch210,保存sync-chrakpoint文件夹下

这里产生的权重文件是SyncNet网络+残差跳跃连接 训练后的权重,
因为设置epoch数比较高,可按下快捷键Ctrl+C 停止训练。
3.2.训练情绪鉴别器
python emotion_disc_train.py -i preprocessed_dataset/ -o emo-checkpoint开始训练
因为设置epoch数比较高,可按下快捷键Ctrl+C 停止训练。
3.3.训练最终模型
python train.py --data_root preprocessed_dataset/ --checkpoint_dir emogen-checkpoint --syncnet_checkpoint_path sync-checkpoint/checkpoint_step000011256.pth --emotion_disc_path emo-checkpoint/disc_emo_23000.pth- emogen-checkpoint 训练后的权重文件都保存在这个文件夹
- sync-checkpoint/checkpoint_step000011256.pth 训练鉴别器时的权重文件
- emo-checkpoint/disc_emo_23000.pth训练情绪鉴别器时的权重文件

4.推理
也可以不进行训练,直接下载checkpoint,下载地址:
python inference.py --checkpoint_path emo-checkpoint --face 自己的mp4文件 --audio 一个语音文件 --emotion 想要生成的情绪选择--checkpoint_path emo-checkpoint --face 自己的mp4文件 --audio 一个语音文件 : *.wav,*.mp3甚至是视频文件,代码会自动从中提取音频 --emotion 想要生成的情绪选择 :从列表中选择分类情绪:[HAP、SAD、FEA、ANG、DIS、NEU]
过程中遇到的问题及解决(PS)
[PS1]docker容器安装ffmpeg失败,出现Err:1 http://security.ubuntu.com/ubuntu focal-updates/main amd64 libwebp6 amd64 0.6.1-2ubuntu0.20.04.1
404 Not Found [IP: 185.125.190.39 80]
Err:2 http://security.ubuntu.com/ubuntu focal-updates/main amd64 libwebpmux3 amd64 0.6.1-2ubuntu0.20.04.1
404 Not Found [IP: 185.125.190.39 80]


原因分析
linux服务器上ffmpeg版本为4.2.7,且没问题
docker容器安装辅助项
apt-get install yasm
apt-get install libx264-dev
apt-get install libfdk-aac-dev
apt-get install libmp3lame-dev
apt-get install libopus-dev
apt-get install libvpx-dev
apt-get update
apt install ffmpeg成功后

数据集Flash 样本
【PS2】TypeError: makedirs() got an unexpected keyword argument 'exist_ok'
解决方法:删掉exist_ok=True
【PS3】/workspace/facegan/EmoGen/CREMA-D/VideoFlash/1018_MTI_DIS_XX.flv: Invalid data found when processing input
解决方法:是下载数据时,文件出现问题,重新下载数据后正常。
【PS4】AttributeError: partially initialized module 'cv2' has no attribute 'gapi_wip_gst_GStreamerPipeline' (most likely due to a circular import)
查看opencv_python的版本,是4.7.0.72
把版本降级
pip install opencv-python==4.3.0.36【PS5】ImportError: libSM.so.6: cannot open shared object file: No such file or directory
因为我是docker容器,所以要下载
pip install opencv-python-headless==4.3.0.36[PS6]RuntimeError: Sizes of tensors must match except in dimension 1. Expected size 64 but got size 320 for tensor number 1 in the list.
代码详解(按运行顺序)
convertFPS.py
import argparse
import os
import subprocess
if __name__ == '__main__':
parser = argparse.ArgumentParser(description=__doc__)
#定义参数 -i 是 --input-folder的缩写,运行时添加数据集的路径
parser.add_argument("-i", "--input-folder", type=str, help='Path to folder that contains video files')
#定义参数 -fps 是指画面每秒传输帧数,即动画或视频每秒切换的图片张数,帧数越大,流畅度越高,
parser.add_argument("-fps", type=float, help='Target FPS', default=25.0)
#定义参数 -o 是 --output-folder的缩写,运行时添加数据处理后的路径
parser.add_argument("-o", "--output-folder", type=str, help='Path to output folder')
args = parser.parse_args()
#建立处理后的文件夹名
#os.makedirs(args.output_folder, exist_ok=True)
os.makedirs(args.output_folder)
fileList = []
#对于数据路径下的(文件格式为:MP4、mpg、mov、flv)的文件,循环切割提取文件名
for root, dirnames, filenames in os.walk(args.input_folder):
for filename in filenames:
if os.path.splitext(filename)[1] == '.mp4' or os.path.splitext(filename)[1] == '.mpg' or os.path.splitext(filename)[1] == '.mov' or os.path.splitext(filename)[1] == '.flv':
#对于所提取的文件进行展平
fileList.append(os.path.join(root, filename))
#对于所提取的文件利用ffmpeg库进行视频切片,并存为.MP4文件
for file in fileList:
subprocess.run("ffmpeg -i {} -r 25 -y {}".format(file, os.path.splitext(file.replace(args.input_folder, args.output_folder))[0]+".mp4"), shell=True)使用ffmpeg分割视频时,指定开始、结束时间。使用以下命令
ffmpeg -ss [start] -i [input] -to [end] -c copy [output]
参数
| 参数 | 作用 |
|---|---|
| -ss | 读取位置 |
| -i | ffmpeg的必要字段 |
| -t | 持续时间 |
| -to | 结束位置 |
| -c | 编解码器 |
| copy | 源文件编解码器 |
| [start] | 开始时间 |
| [end] | 结束时间 |
| [duration] | 持续时间 |
| [input] | 输入文件路径 |
| [output] | 输出文件路径 |
-r : 每秒帧数(指定帧率,这样达到视频压缩效果)
注意 :-ss 要放在 -i 之前
preprocess_crema-d.py
import sys
if sys.version_info[0] < 3 and sys.version_info[1] < 2:
raise Exception("Must be using >= Python 3.2")
from os import listdir, path
if not path.isfile('face_detection/detection/sfd/s3fd.pth'):
raise FileNotFoundError('Save the s3fd model to face_detection/detection/sfd/s3fd.pth \
before running this script!')
import multiprocessing as mp
from concurrent.futures import ThreadPoolExecutor, as_completed
import numpy as np
import argparse, os, cv2, traceback, subprocess
from tqdm import tqdm
from glob import glob
import audio
from hparams import hparams as hp
import face_detection
parser = argparse.ArgumentParser()
# gpu的数量
parser.add_argument('--ngpu', help='Number of GPUs across which to run in parallel', default=1, type=int)
# 单一gpu人脸检测的批量大小,默认32
parser.add_argument('--batch_size', help='Single GPU Face detection batch size', default=32, type=int)
# 数据集地址
parser.add_argument("--data_root", help="Root folder of the LRS2 dataset", required=True)
# 处理后的数据集地址
parser.add_argument("--preprocessed_root", help="Root folder of the preprocessed dataset", required=True)
args = parser.parse_args()
#识别视频数据集中的人脸
fa = [face_detection.FaceAlignment(face_detection.LandmarksType._2D, flip_input=False,
device='cuda:{}'.format(id)) for id in range(args.ngpu)]
#识别人脸后利用ffmpeg库处理
template = 'ffmpeg -loglevel panic -y -i {} -strict -2 {}'
# template2 = 'ffmpeg -hide_banner -loglevel panic -threads 1 -y -i {} -async 1 -ac 1 -vn -acodec pcm_s16le -ar 16000 {}'
def process_video_file(vfile, args, gpu_id):
video_stream = cv2.VideoCapture(vfile)
frames = []
while 1:
still_reading, frame = video_stream.read()
if not still_reading:
video_stream.release()
break
frames.append(frame)
vidname = os.path.basename(vfile).split('.')[0]
#dirname = vfile.split('/')[-2]
fulldir = path.join(args.preprocessed_root, vidname)
os.makedirs(fulldir, exist_ok=True)
batches = [frames[i:i + args.batch_size] for i in range(0, len(frames), args.batch_size)]
i = -1
for fb in batches:
preds = fa[gpu_id].get_detections_for_batch(np.asarray(fb))
for j, f in enumerate(preds):
i += 1
if f is None:
continue
# 截取的人脸保存四点为一张照片
x1, y1, x2, y2 = f
cv2.imwrite(path.join(fulldir, '{}.jpg'.format(i)), fb[j][y1:y2, x1:x2])
def process_audio_file(vfile, args):
vidname = os.path.basename(vfile).split('.')[0]
#dirname = vfile.split('/')[-2]
fulldir = path.join(args.preprocessed_root, vidname)
os.makedirs(fulldir, exist_ok=True)
wavpath = path.join(fulldir, 'audio.wav')
command = template.format(vfile, wavpath)
subprocess.call(command, shell=True)
def mp_handler(job):
vfile, args, gpu_id = job
try:
process_video_file(vfile, args, gpu_id)
except KeyboardInterrupt:
exit(0)
except:
traceback.print_exc()
def main(args):
print('Started processing for {} with {} GPUs'.format(args.data_root, args.ngpu))
#
filelist = glob(path.join(args.data_root, '*.mp4'))
jobs = [(vfile, args, i%args.ngpu) for i, vfile in enumerate(filelist)]
p = ThreadPoolExecutor(args.ngpu)
futures = [p.submit(mp_handler, j) for j in jobs]
_ = [r.result() for r in tqdm(as_completed(futures), total=len(futures))]
print('Dumping audios...')
for vfile in tqdm(filelist):
try:
process_audio_file(vfile, args)
except KeyboardInterrupt:
exit(0)
except:
traceback.print_exc()
continue
if __name__ == '__main__':
main(args)color_syncnet_train.py
from os.path import dirname, join, basename, isfile, isdir
from tqdm import tqdm
from models import SyncNet_color as SyncNet
import audio
import torch
from torch import nn
from torch import optim
from torch.utils.tensorboard import SummaryWriter
import torch.backends.cudnn as cudnn
from torch.utils import data as data_utils
import numpy as np
from glob import glob
import os, random, cv2, argparse
import albumentations as A
from hparams import hparams, get_image_list
parser = argparse.ArgumentParser(description='Code to train the expert lip-sync discriminator')
# 数据集路径
parser.add_argument("--data_root", help="Root folder of the preprocessed LRS2 dataset", required=True)
parser.add_argument('--checkpoint_dir', help='Save checkpoints to this directory', required=True, type=str)
parser.add_argument('--checkpoint_path', help='Resumed from this checkpoint', default=None, type=str)
args = parser.parse_args()
global_step = 0
global_epoch = 0
os.environ['CUDA_VISIBLE_DEVICES']='2'
use_cuda = torch.cuda.is_available()
print('use_cuda: {}'.format(use_cuda))
syncnet_T = 5
emonet_T = 5
syncnet_mel_step_size = 16
class Dataset(object):
def __init__(self, split):
#self.all_videos = get_image_list(args.data_root, split)
self.all_videos = [join(args.data_root, f) for f in os.listdir(args.data_root) if isdir(join(args.data_root, f))]
print('Num files: ', len(self.all_videos))
# to apply same augmentation for all the frames
target = {}
for i in range(1, emonet_T):
target['image' + str(i)] = 'image'
self.augments = A.Compose([
A.RandomBrightnessContrast(p=0.2),
A.RandomGamma(p=0.2),
A.CLAHE(p=0.2),
A.HueSaturationValue(hue_shift_limit=20, sat_shift_limit=50, val_shift_limit=50, p=0.2),
A.ChannelShuffle(p=0.2),
A.RGBShift(p=0.2),
A.RandomBrightness(p=0.2),
A.RandomContrast(p=0.2),
A.GaussNoise(var_limit=(10.0, 50.0), p=0.25),
], additional_targets=target, p=0.8)
def augmentVideo(self, video):
args = {}
args['image'] = video[0, :, :, :]
for i in range(1, emonet_T):
args['image' + str(i)] = video[i, :, :, :]
result = self.augments(**args)
video[0, :, :, :] = result['image']
for i in range(1, emonet_T):
video[i, :, :, :] = result['image' + str(i)]
return video
def get_frame_id(self, frame):
return int(basename(frame).split('.')[0])
def get_window(self, start_frame):
start_id = self.get_frame_id(start_frame)
vidname = dirname(start_frame)
window_fnames = []
for frame_id in range(start_id, start_id + syncnet_T):
frame = join(vidname, '{}.jpg'.format(frame_id))
if not isfile(frame):
return None
window_fnames.append(frame)
return window_fnames
def crop_audio_window(self, spec, start_frame):
# num_frames = (T x hop_size * fps) / sample_rate
start_frame_num = self.get_frame_id(start_frame)
start_idx = int(80. * (start_frame_num / float(hparams.fps)))
end_idx = start_idx + syncnet_mel_step_size
return spec[start_idx : end_idx, :]
def __len__(self):
return len(self.all_videos)
def __getitem__(self, idx):
while 1:
idx = random.randint(0, len(self.all_videos) - 1)
vidname = self.all_videos[idx]
#print(vidname)
img_names = list(glob(join(vidname, '*.jpg')))
if len(img_names) <= 3 * syncnet_T:
continue
img_name = random.choice(img_names)
wrong_img_name = random.choice(img_names)
while wrong_img_name == img_name:
wrong_img_name = random.choice(img_names)
if random.choice([True, False]):
y = torch.ones(1).float()
chosen = img_name
else:
y = torch.zeros(1).float()
chosen = wrong_img_name
window_fnames = self.get_window(chosen)
if window_fnames is None:
continue
window = []
all_read = True
for fname in window_fnames:
img = cv2.imread(fname)
if img is None:
all_read = False
break
try:
img = cv2.resize(img, (hparams.img_size, hparams.img_size))
except Exception as e:
all_read = False
break
window.append(img)
if not all_read: continue
try:
wavpath = join(vidname, "audio.wav")
wav = audio.load_wav(wavpath, hparams.sample_rate)
orig_mel = audio.melspectrogram(wav).T
except Exception as e:
continue
mel = self.crop_audio_window(orig_mel.copy(), img_name)
if (mel.shape[0] != syncnet_mel_step_size):
continue
# H x W x 3 * T
window = np.asarray(window)
aug_results = self.augmentVideo(window)
window = np.split(aug_results, syncnet_T, axis=0)
x = np.concatenate(window, axis=3) / 255.
x = np.squeeze(x, axis=0).transpose(2, 0, 1)
# print(x.shape)
x = x[:, x.shape[1]//2:]
x = torch.FloatTensor(x)
mel = torch.FloatTensor(mel.T).unsqueeze(0)
return x, mel, y
logloss = nn.BCELoss()
def cosine_loss(a, v, y):
d = nn.functional.cosine_similarity(a, v)
loss = logloss(d.unsqueeze(1), y)
return loss
def train(device, model, train_data_loader, test_data_loader, optimizer,
checkpoint_dir=None, checkpoint_interval=None, nepochs=None):
#scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=6)
global global_step, global_epoch
resumed_step = global_step
num_batches = len(train_data_loader)
while global_epoch < nepochs:
print('Epoch: {}'.format(global_epoch))
running_loss = 0.
prog_bar = tqdm(enumerate(train_data_loader))
for step, (x, mel, y) in prog_bar:
model.train()
optimizer.zero_grad()
# Transform data to CUDA device
x = x.to(device)
mel = mel.to(device)
a, v = model(mel, x)
y = y.to(device)
loss = cosine_loss(a, v, y)
loss.backward()
optimizer.step()
global_step += 1
cur_session_steps = global_step - resumed_step
running_loss += loss.item()
# if global_step == 1 or global_step % checkpoint_interval == 0:
# save_checkpoint(
# model, optimizer, global_step, checkpoint_dir, global_epoch)
# if global_step % hparams.syncnet_eval_interval == 0:
# with torch.no_grad():
# eval_loss = eval_model(test_data_loader, global_step, device, model, checkpoint_dir)
prog_bar.set_description('Loss: {}'.format(running_loss / (step + 1)))
writer.add_scalar("Loss/train", running_loss/num_batches, global_epoch)
with torch.no_grad():
eval_loss = eval_model(test_data_loader, global_step, device, model, checkpoint_dir)
if(global_epoch % 50 == 0):
save_checkpoint(model, optimizer, global_step, checkpoint_dir, global_epoch)
global_epoch += 1
def eval_model(test_data_loader, global_step, device, model, checkpoint_dir):
eval_steps = 1400
print('Evaluating for {} steps'.format(eval_steps))
losses = []
while 1:
for step, (x, mel, y) in enumerate(test_data_loader):
model.eval()
# Transform data to CUDA device
x = x.to(device)
mel = mel.to(device)
a, v = model(mel, x)
y = y.to(device)
loss = cosine_loss(a, v, y)
losses.append(loss.item())
if step > eval_steps: break
averaged_loss = sum(losses) / len(losses)
print(averaged_loss)
writer.add_scalar("Loss/val", averaged_loss, global_step)
return averaged_loss
def save_checkpoint(model, optimizer, step, checkpoint_dir, epoch):
checkpoint_path = join(
checkpoint_dir, "checkpoint_step{:09d}.pth".format(global_step))
optimizer_state = optimizer.state_dict() if hparams.save_optimizer_state else None
torch.save({
"state_dict": model.state_dict(),
"optimizer": optimizer_state,
"global_step": step,
"global_epoch": epoch,
}, checkpoint_path)
print("Saved checkpoint:", checkpoint_path)
def _load(checkpoint_path):
if use_cuda:
checkpoint = torch.load(checkpoint_path)
else:
checkpoint = torch.load(checkpoint_path,
map_location=lambda storage, loc: storage)
return checkpoint
def load_checkpoint(path, model, optimizer, reset_optimizer=False):
global global_step
global global_epoch
print("Load checkpoint from: {}".format(path))
checkpoint = _load(path)
model.load_state_dict(checkpoint["state_dict"])
if not reset_optimizer:
optimizer_state = checkpoint["optimizer"]
if optimizer_state is not None:
print("Load optimizer state from {}".format(path))
optimizer.load_state_dict(checkpoint["optimizer"])
global_step = checkpoint["global_step"]
global_epoch = checkpoint["global_epoch"]
return model
if __name__ == "__main__":
checkpoint_dir = args.checkpoint_dir
checkpoint_path = args.checkpoint_path
if not os.path.exists(checkpoint_dir): os.mkdir(checkpoint_dir)
# Dataset and Dataloader setup
#train_dataset = Dataset('train')
#test_dataset = Dataset('val')
full_dataset = Dataset('train')
train_size = int(0.95 * len(full_dataset))
test_size = len(full_dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size], generator=torch.Generator().manual_seed(42))
train_data_loader = data_utils.DataLoader(
train_dataset, batch_size=hparams.syncnet_batch_size, shuffle=True,
num_workers=hparams.num_workers)
test_data_loader = data_utils.DataLoader(
test_dataset, batch_size=hparams.syncnet_batch_size,
num_workers=8)
device = torch.device("cuda" if use_cuda else "cpu")
# Model
model = SyncNet().to(device)
#model = nn.DataParallel(SyncNet(), device_ids=[1,2]).to(device)
print('total trainable params {}'.format(sum(p.numel() for p in model.parameters() if p.requires_grad)))
optimizer = optim.Adam([p for p in model.parameters() if p.requires_grad],
lr=hparams.syncnet_lr,betas=(0.5,0.999))
if checkpoint_path is not None:
load_checkpoint(checkpoint_path, model, optimizer, reset_optimizer=False)
writer = SummaryWriter('runs/crema-d_disc_exp2_data_aug')
train(device, model, train_data_loader, test_data_loader, optimizer,
checkpoint_dir=checkpoint_dir,
checkpoint_interval=hparams.syncnet_checkpoint_interval,
nepochs=hparams.nepochs)
writer.flush()
以Syncnet网络为基础,训练一个鉴别器,关于Syncnet,详细可查看
emotion_disc_train.py
import argparse
import json
import os
from tqdm import tqdm
import random as rn
import shutil
import numpy as np
import torch
import torch.nn as nn
from sklearn.metrics import accuracy_score
from torch.utils.tensorboard import SummaryWriter
from models import emo_disc
from datagen_aug import Dataset
def initParams():
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument("-i", "--in-path", type=str, help="Input folder containing train data", default=None, required=True)
# parser.add_argument("-v", "--val-path", type=str, help="Input folder containing validation data", default=None, required=True)
parser.add_argument("-o", "--out-path", type=str, help="output folder", default='../models/def', required=True)
parser.add_argument('--num_epochs', type=int, default=10000)
parser.add_argument("--batch-size", type=int, default=64)
parser.add_argument('--lr_emo', type=float, default=1e-06)
parser.add_argument("--gpu-no", type=str, help="select gpu", default='1')
parser.add_argument('--seed', type=int, default=9)
args = parser.parse_args()
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu_no
args.batch_size = args.batch_size * max(int(torch.cuda.device_count()), 1)
args.steplr = 200
args.filters = [64, 128, 256, 512, 512]
#-----------------------------------------#
# Reproducible results #
#-----------------------------------------#
os.environ['PYTHONHASHSEED'] = str(args.seed)
np.random.seed(args.seed)
rn.seed(args.seed)
torch.manual_seed(args.seed)
#-----------------------------------------#
if not os.path.exists(args.out_path):
os.makedirs(args.out_path)
else:
shutil.rmtree(args.out_path)
os.mkdir(args.out_path)
with open(os.path.join(args.out_path, 'args.txt'), 'w') as f:
json.dump(args.__dict__, f, indent=2)
args.cuda = torch.cuda.is_available()
print('Cuda device available: ', args.cuda)
args.device = torch.device("cuda" if args.cuda else "cpu")
args.kwargs = {'num_workers': 0, 'pin_memory': True} if args.cuda else {}
return args
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d or type(m) == nn.Conv1d:
torch.nn.init.xavier_uniform_(m.weight)
def enableGrad(model, requires_grad):
for p in model.parameters():
p.requires_grad_(requires_grad)
def train():
args = initParams()
trainDset = Dataset(args)
train_loader = torch.utils.data.DataLoader(trainDset,
batch_size=args.batch_size,
shuffle=True,
drop_last=True,
**args.kwargs)
device_ids = list(range(torch.cuda.device_count()))
disc_emo = emo_disc.DISCEMO().to(args.device)
disc_emo.apply(init_weights)
#disc_emo = nn.DataParallel(disc_emo, device_ids)
emo_loss_disc = nn.CrossEntropyLoss()
num_batches = len(train_loader)
print(args.batch_size, num_batches)
global_step = 0
for epoch in range(args.num_epochs):
print('Epoch: {}'.format(epoch))
prog_bar = tqdm(enumerate(train_loader))
running_loss = 0.
for step, (x, y) in prog_bar:
video, emotion = x.to(args.device), y.to(args.device)
disc_emo.train()
disc_emo.opt.zero_grad() # .module is because of nn.DataParallel
class_real = disc_emo(video)
loss = emo_loss_disc(class_real, torch.argmax(emotion, dim=1))
running_loss += loss.item()
loss.backward()
disc_emo.opt.step() # .module is because of nn.DataParallel
#每隔1000打印并保存权重文件
if global_step % 1000 == 0:
print('Saving the network')
torch.save(disc_emo.state_dict(), os.path.join(args.out_path, f'disc_emo_{global_step}.pth'))
print('Network has been saved')
prog_bar.set_description('classification Loss: {}'.format(running_loss / (step + 1)))
global_step += 1
writer.add_scalar("classification Loss", running_loss/num_batches, epoch)
disc_emo.scheduler.step() # .module is because of nn.DataParallel
if __name__ == "__main__":
writer = SummaryWriter('runs/emo_disc_exp4')
train()下载CREMA-D数据集命令
git clone https://github.com/CheyneyComputerScience/CREMA-D
#文件会出错,MP3文件,wav文件,flv文件等克隆后为二进制文件