文章目录
- 数据库和表的准备
- select
- select + order by
- select + where
- select + 高级过滤操作
- 使用通配符进行过滤
- 使用正则表达式进行搜索
数据库和表的准备
- 下载《mysql必知必会》提供的脚本用于创建样例表
cd /mnt/d/unix_dir
wget https://forta.com/wp-content/uploads/books/0672327120/mysql_scripts.zip
unzip mysql_scripts.zip
- 运行对应的脚本创建样例表
create database crashtest;
show databases;
use crashtest;
source /mnt/d/unix_dir/create.sql;
source /mnt/d/unix_dir/populate.sql;
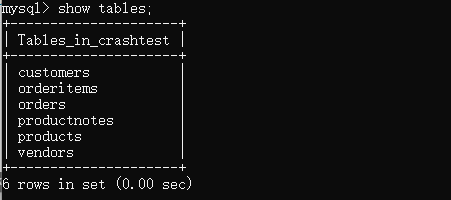
show tables;
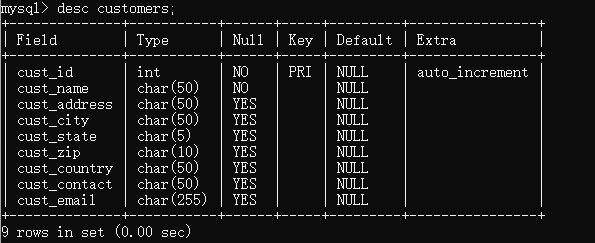
desc customers;
select
SQL语句是由简单的英语单词构成的。这些单词称为关键字,每个SQL语句都是由一个或多个关键字构成的。
大概,最经常使用的SQL语句就是SELECT语句了。它的用途是从一个或多个表中检索信息。
为了使用SELECT检索表数据,必须至少给出两条信息——想选择什么,以及从什么地方选择
SQL 语句不区分大小写,通常大家把关键字大写
在处理SQL语句时,其中所有空格都被忽略
# 从products表中检索一个名为 prod_name的列
select prod_name from products;
# 选择多列,列名之间逗号分隔,最后一个列名不需要加入逗号
select prod_id,prod_name,prod_price from products;
# 选择所有列,使用通配符可能会使检索输出的列位置和实际表中的位置不符
select * from products;
# 使用DISTINCT关键字 此关键字指示MySQL只返回不同的值,类似于 程序设计语言种的 unique
select distinct vend_id from products;
# LIMIT 5指示MySQL返回 不多于5行,检索位置靠前的行被返回
select * from products limit 5;
# LIMIT 5, 5指示MySQL返回从行5开始的5行
select * from products limit 5,5;
# or 从第四行检索,返回最多5行
select * from products limit 5 offset 4;
# 限定表名和数据库名
# products.prod_name 限定了那个表的哪一列
# crashtest.products 限定了哪个数据库的哪一个表
select products.prod_name from crashtest.products
select + order by
# 从products表中检索一个名为 prod_name的列并排序
select prod_name from products order by prod_name;
# 从products表中检索一个名为 prod_name的列并按照降序排序
select prod_name from products order by prod_name desc;
# 降序还可以这样用
# 先根据 prod_id降序,再根据prod_price升序
select prod_id,prod_name,prod_price from products order by prod_id desc,prod_price;
# 用非检索列排序,也是合法的
select prod_name from products order by prod_id;
# 选择多列,列名之间逗号分隔,最后一个列名不需要加入逗号
# 同时根据多列数据进行排序,列名之间需要逗号隔开
select prod_id,prod_name,prod_price from products order by prod_id,prod_name,prod_price;
# 多个子句的组合,先选再排最后输出
select prod_name from products order by prod_id limit 1;
select + where
NULL 无值(no value),它与字段包含0、空字符串或仅仅包含空格不同
因为未知具有 特殊的含义,数据库不知道它们是否匹配,所以在匹配过滤 或不匹配过滤时不返回它们
# 选择 prod_price列中等于2.5的数据
select prod_price from products where prod_price = 2.5;
# mysql> select prod_price from products where prod_price == 2.5; 将会报错
# 在同时使用ORDER BY和WHERE子句时,应该让ORDER BY位于WHERE之后, 否则将会产生错误
select prod_price from products where prod_price = 2.5 order by prod_name;
# MySQL在执行匹配时默认不区分大小写
select prod_price,prod_name from products where prod_name = "fuses";
# between and 关键字实现区间选取
select prod_price,prod_name from products where prod_price between 5 and 10 ;
# 检查空值 NULL需要特殊的语句
select prod_price,prod_name from products where prod_price IS NULL ;
select + 高级过滤操作
AND 用在WHERE子句中的关键字,用来指示检索满足所有给定 条件的行
OR操作符与AND操作符不同,它指示MySQL检索匹配任一条件的行
AND / OR操作符可以任意次数的组合但是 AND的计算次序优先级更高 <== 结合序问题 <== 使用圆括号括起来解决
# AND / OR 连接组合where 子句
select prod_price,prod_name from products where prod_price IS NULL AND prod_name = "fuses";
select prod_price,prod_name from products where prod_price IS NULL OR prod_name = "fuses";
select prod_price,prod_name from products where (prod_price IS NULL OR prod_name = "fuses") AND prod_id >= 1000;
# 区别与betwenn and ,IN操 作符后跟由逗号分隔的合法值清单,整个清单必须括在圆括号中。
SELECT prod_name,prod_price FROM products WHERE vend_id IN (1002,1004) ORDER BY prod_name;
# WHERE子句中的NOT操作符有且只有一个功能,那就是否定它之后所跟的任何条件 ⇐ == 取反操作
SELECT prod_name,prod_price FROM products WHERE vend_id NOT IN (1002,1004) ORDER BY prod_name;
使用通配符进行过滤
为在搜索子句中使用通配符,必须使用LIKE操作符。
LIKE指示MySQL,后跟的搜索模式利用通配符匹配而不是直接相等匹配进行比较。
最后需要注意的是,通配符并不是完全意义上的通配,至少它不匹配 NULL。
# 通配符是百分号(%),表示任何字符出现 任意次数 <== 和unix中的正则表达式有区别呀
# 找出所有以词jet起头的产品,%告诉MySQL接受jet之后的任意字符
SELECT prod_name,prod_price FROM products WHERE prod_name LIKE "jet%";
# 匹配任何位置包含文本jet的值,而不论它之前或之后出现什么字符
SELECT prod_name,prod_price FROM products WHERE prod_name LIKE "%jet%";
# 通配符也可以出现在搜索模式的中间
SELECT prod_name,prod_price FROM products WHERE prod_name LIKE "je%t";
# 下划线(_)。下划线的用途与%一样,但下划线只匹配单个字符而不是多个字符
SELECT prod_name,prod_price FROM products WHERE prod_name LIKE "_jet";
- 正如所见, MySQL的通配符很有用。但这种功能是有代价的:通配符搜索的处理一般要比前面讨论的其他搜索所花时间更长
- 不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符
- 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的
- 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据
使用正则表达式进行搜索
个人认为 LIKE 进行的通配符检索和正则很像,
主要区别是 LIKE 后面接的是 ^pattern$ 这种形式,却写作 pattern <= 隐式表达
正则的pattern 则需要手动指定 定位符 ^ pattern $ <= 显示表达
# 下面的语句检索列prod_name包含 文本1000的所有行
SELECT prod_name,prod_price FROM products WHERE prod_name REGEXP "1000" ORDER BY prod_name;
# 正则表达式中的特殊字符,比如 . 表示任意且切实存在的一位字符
SELECT prod_name,prod_price FROM products WHERE prod_name REGEXP ".000" ORDER BY prod_name;
# 正则表达式中的 OR,它表示匹配其中之一,因此1000和2000都匹配并返回
SELECT prod_name,prod_price FROM products WHERE prod_name REGEXP "1000|2000";
# 只想匹配特定的字符,可通过指定一组用[和]括起来的字符来完成
# [123]定义一组字符,它的意思是匹配1或2或3
SELECT prod_name,prod_price FROM products WHERE prod_name REGEXP "[12]000";
# 字符集合的取反操作
SELECT prod_name,prod_price FROM products WHERE prod_name REGEXP "[^12]000";