1. CenterNet简介
CenterNet采用了一种新的检测思路,即以目标中心点为基础,直接回归出目标的位置和大小。而传统的目标检测算法通常会先产生大量候选框(Anchor),再通过分类器进行筛选,这种方法比较复杂。CenterNet在准确率上比传统算法更好。相对于传统算法,CenterNet有更快的速度,因为其采用端到端模型,没有二阶段修正,因此可以更快地进行目标检测。其AP精度相较YOLO与CornerNet均有明显提高,相对于R-CNN方法有较大优势。下图为CenterNet在COCO数据集中的表现。

2. 环境配置
训练环境Ubuntu20.04+Pytorch1.4+cuda10.4,笔者的训练硬件为RTX2080Ti(22G显存)。GPU驱动配置请参考:《环境感知算法——1.简介与GPU驱动、CUDA和cudnn配置》。
1)配置CenterNet虚拟环境
下面为在Anaconda虚拟环境中,配置运行CenterNet的环境。
conda create --name CenterNet python=3.6
conda activate CenterNet
conda install cudatoolkit=10.1
conda install --channel https://conda.anaconda.org/nvidia cudnn
conda install pytorch==1.4.0
pip install torchvision==0.5.0
pip install --upgrade jupyter_client测试torch是否调用了虚拟环境中的cuda(在conda虚拟环境中不可以使用nvcc -V查看cuda信息):
进入CenterNet虚拟环境后,使用下列代码查看虚拟环境中的cuda版本:
# 使用python进入,exit()退出
import torch
print(torch.version.cuda)
print(torch.backends.cudnn.version())测试显卡的算力:
AIscore = torch.cuda.get_device_capability()
AIscore = f'{AIscore[0]}{AIscore[1]}'
print(AIscore)2) 下载CenterNet代码包
CenterNet源工程在GitHub的链接如下:
https://github.com/xingyizhou/CenterNet![]() https://github.com/xingyizhou/CenterNet
https://github.com/xingyizhou/CenterNet
如果安装有git可以采用以下代码下载(或直接从Github页面下载压缩包文件后解压):
CenterNet_ROOT=/home/yaoyao/Documents/CenterNet # 视实际下载目录更改
git clone https://github.com/xingyizhou/CenterNet $CenterNet_ROOT注意上述代码的位置应根据实际情况更改,并且目标目录不得存在名称为CenterNet的文件夹(否则会报错)。笔者下载CenterNet源代码的位置如下,请视自己实际目录情况修改:
CenterNet_ROOT=/home/yaoyao/Documents/CenterNet 后续代码中CenterNet_ROOT请替换为对应CenterNet的目录。
3)替换DCNv2文件
源工程中的DCNv2并不适合于cuda10.0之后的版本,需要下载修改后的版本。下面链接给出了一个在本环境中经过测试可行的DCNv2版本。
https://github.com/CharlesShang/DCNv2![]() https://github.com/CharlesShang/DCNv2
https://github.com/CharlesShang/DCNv2
为了替换下载DCNv2,请逐步执行以下步骤:
# 切换至CenterNet中CenterNet所在目录
cd CenterNet_ROOT/src/lib/models/networks/
# 删除源程序中的DCNv2
rm -r DCNv2/
# 下载修改后、满足当前cuda版本的DCNv2
git clone https://github.com/CharlesShang/DCNv2.git4)编译并测试DCNv2
# 编译DCNv2
cd CenterNet_ROOT/src/lib/models/networks/DCNv2
python setup.py build develop
# 测试DCNv2
cd CenterNet_ROOT/src/lib/models/networks/DCNv2
python testcpu.py
python testcuda.pyDCNv2需要使用python setup.py build develop编译(如果没有编译器需要补充安装gcc与g++等编译器)。DCNv2文件夹内分别基于CPU与GPU给出测试程序testcpu.py和testcuda.py。
编译过程中会出现部分Warning,可以忽略。若编译安装完成会提示:
DCNv2 0.1 is already the active version in easy-install.pth
Installed /home/yaoyao/Documents/CenterNet/src/lib/models/networks/DCNv2
Processing dependencies for DCNv2==0.1
Finished processing dependencies for DCNv2==0.1
此时,可以分别运行python testcpu.py和python testcuda.py测试DCNv2是否编译成功。
如果编译成功会出现:
check_gradient_dpooling: True
check_gradient_dconv: True如果出现了以下RuntimeError报错,笔者认为是正常现象(这个DCNv2版本可能也存在小问题但是不影响使用),可以反复重新运行testcpu.py和testcuda.py直至出现上列没有RuntimeError报错的结果。
Zero offset passed
/home/yaoyao/anaconda3/envs/CenterNet/lib/python3.6/site-packages/torch/autograd/gradcheck.py:242: UserWarning: At least one of the inputs that requires gradient is not of double precision floating point. This check will likely fail if all the inputs are not of double precision floating point.
'At least one of the inputs that requires gradient '
check_gradient_dpooling: True
Traceback (most recent call last):
File "testcuda.py", line 265, in <module>
check_gradient_dconv()
File "testcuda.py", line 97, in check_gradient_dconv
eps=1e-3, atol=1e-4, rtol=1e-2))
File "/home/yaoyao/anaconda3/envs/CenterNet/lib/python3.6/site-packages/torch/autograd/gradcheck.py", line 289, in gradcheck
'numerical:%s\nanalytical:%s\n' % (i, j, n, a))
File "/home/yaoyao/anaconda3/envs/CenterNet/lib/python3.6/site-packages/torch/autograd/gradcheck.py", line 227, in fail_test
raise RuntimeError(msg)
RuntimeError: Jacobian mismatch for output 0 with respect to input 1,
numerical:tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
analytical:tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
5)修改并编译NMS
在CenterNet\src\lib\external中找到set.py文件,修改set.py中的代码,在第10行处注释掉#extra_compile_args=["-Wno-cpp", "-Wno-unused-function"]。
编译NMS需要安装Cython,使用pip安装:
pip install Cython之后,使用以下代码进行编译:
cd CenterNet_ROOT/src/lib/external
python setup.py build_ext --inplace编译成功后,终端将输出:
gcc -pthread -shared -B /home/yaoyao/anaconda3/envs/CenterNet/compiler_compat -L/home/yaoyao/anaconda3/envs/CenterNet/lib -Wl,-rpath=/home/yaoyao/anaconda3/envs/CenterNet/lib -Wl,--no-as-needed -Wl,--sysroot=/ build/temp.linux-x86_64-3.6/nms.o -o /home/yaoyao/Documents/CenterNet/src/lib/external/nms.cpython-36m-x86_64-linux-gnu.so
此时,在.../CenterNet/src/lib/external文件夹内,将出现编译后的可执行文件nms.cpython-36m-x86_64-linux-gnu.so。
6)下载pth文件
CenterNet作者在Google Drive中放置了多个训练完成的.pth文件。
MODEL_ZOO.md![]() https://github.com/xingyizhou/CenterNet/blob/master/readme/MODEL_ZOO.md
https://github.com/xingyizhou/CenterNet/blob/master/readme/MODEL_ZOO.md
以下载ctdet_coco_dla_2x为例,将其放入.../CenterNet/models中,模型大小为80.9MB,训练自COCO train 2017训练集。
接下来,需要进入.../CenterNet/code/src/lib/models/networks文件夹,找到pose_dla_dcn.py,并注释掉约309行处dla34函数的if pretrained代码段:
def dla34(pretrained=True, **kwargs): # DLA-34
model = DLA([1, 1, 1, 2, 2, 1],
[16, 32, 64, 128, 256, 512],
block=BasicBlock, **kwargs)
# if pretrained:
# model.load_pretrained_model(data='imagenet', name='dla34', hash='ba72cf86')
return model7)安装必要的Python库
为了避免出现cvShowImage错误:
cv2.error: OpenCV(4.7.0) /tmp/pip-install-nqqlbtpw/opencv-contrib-python_7d60b527e6514716a754388095cd100d/opencv/modules/highgui/src/window.cpp:1272: error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Cocoa support. If you are on Ubuntu or Debian, install libgtk2.0-dev and pkg-config, then re-run cmake or configure script in function 'cvShowImage'
需要在安装OpenCV前,安装一些必要的系统程序:
sudo apt-get install libgtk2.0-dev pkg-config定位至.../CenterNet/src文件夹,安装所需Python包。
cd CenterNet_ROOT/src
conda install Cython numba progress matplotlib scipy
pip install opencv-contrib-python
pip install easydict如果希望重新下载和从源码编译安装opencv-contrib-python,可相应更改代码如下:
pip install --no-cache-dir --no-binary opencv-contrib-python opencv-contrib-python此外,还需要下载评估Kitti数据集所需的ddd_3dop模型:
KITTI 3DOP split model![]() https://github.com/xingyizhou/CenterNet/blob/master/experiments/ddd_3dop.sh
https://github.com/xingyizhou/CenterNet/blob/master/experiments/ddd_3dop.sh
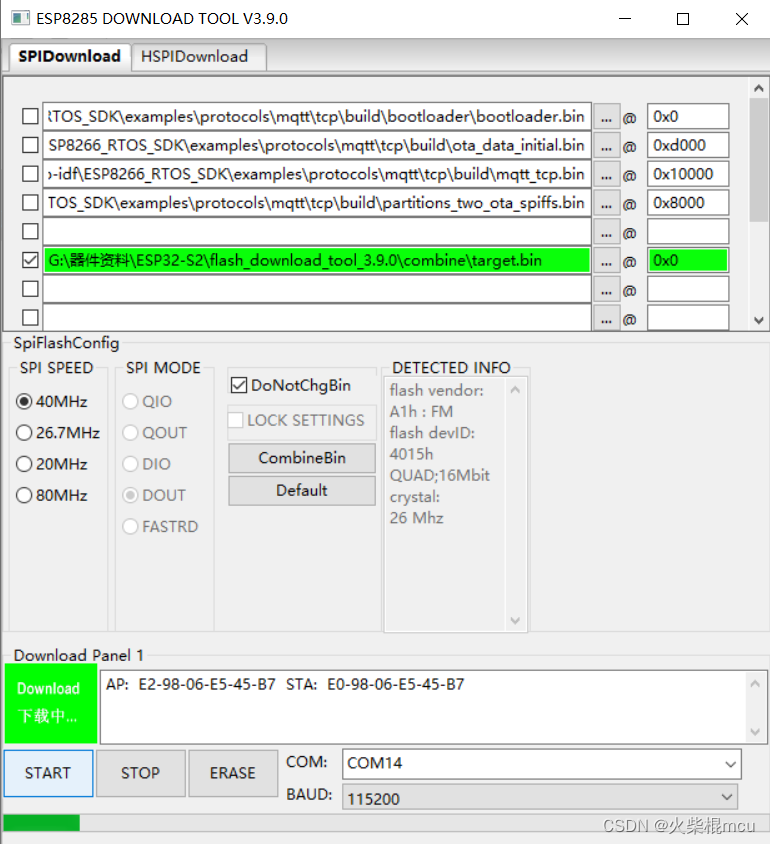
8)测试demo
在CenterNet/images文件夹内,有几个用于测试的图片文件。使用以下代码对于下载的.pth文件在demo图片上进行测试。
cd CenterNet_ROOT/src
python demo.py ctdet --demo ../images/16004479832_a748d55f21_k.jpg --load_model ../models/ctdet_coco_dla_2x.pth上述代码内,16004479832_a748d55f21_k.jpg为两只可爱的小狗,使用CenterNet识别这张demo图片的结果如下:

此步完成,证明各DCNv2、NMS、OpenCV等库安装正确,也可以直接使用该.pth文件进行目标定位与分类。
9)安装COCO API
COCO 数据集是一个大型图像数据集,主要用于目标检测、分割和字幕等计算机视觉任务。COCO API是一种用于处理和解析 COCO 数据集的库。COCO API 提供了一系列的函数和方法,使得用户能够有效地加载、解析和可视化 COCO 数据集。针对 COCO 数据集进行查询和分析、评估模型的性能、用于数据预处理和后处理等设计了API。
使用以下代码进行下载、编译与安装:
# 定位到CenterNet文件夹
cd CenterNet_ROOT
# git下载cocoapi
git clone https://github.com/cocodataset/cocoapi.git
# 进入PythonAPI
cd ./cocoapi/PythonAPI/
# 编译并安装
make
python setup.py install --user若安装完成,终端内会显示:
Using .../anaconda3/envs/CenterNet/lib/python3.6/site-packages
Finished processing dependencies for pycocotools==2.0
也可以在Python环境中测试coco API,使用以下代码,若COCO顺利导入则说明COCOAPI安装成功。
import torch
from pycocotools.coco import COCO10)准备KITTI数据集
CenterNet对于COCO、Pascal VOC、KITTI等预处理链接如下:
https://github.com/xingyizhou/CenterNet/blob/master/readme/DATA.md![]() https://github.com/xingyizhou/CenterNet/blob/master/readme/DATA.md以KITTI数据集为例,在CenterNet项目文件夹内,需要将KITTI数据集整理为如下格式:
https://github.com/xingyizhou/CenterNet/blob/master/readme/DATA.md以KITTI数据集为例,在CenterNet项目文件夹内,需要将KITTI数据集整理为如下格式:
${CenterNet_ROOT}
|-- data
`-- |-- kitti
`-- |-- training
| |-- image_2
| |-- label_2
| |-- calib
|-- ImageSets_3dop
| |-- test.txt
| |-- train.txt
| |-- val.txt
| |-- trainval.txt
`-- ImageSets_subcnn
|-- test.txt
|-- train.txt
|-- val.txt
|-- trainval.txt下面为CenterNet/data/kitti文件夹内的training、ImageSets_3dop、ImageSets_subcnn等文件夹分别传入图像与标签数据。
a)training文件夹
涉及文件的源下载链接分别为 images, annotations, calibrations ,需要首先登记邮箱后通过邮件收到下载地址后下载。或者,使用以下网盘链接:
Kitti数据集提取码:yao1![]() https://pan.baidu.com/s/1xJLKJQYGpc3PsdvSPZV8ag?pwd=yao1
https://pan.baidu.com/s/1xJLKJQYGpc3PsdvSPZV8ag?pwd=yao1
下载其中data_object_label_2.zip、data_object_image_2.zip、data_object_calib.zip及对应的.z01与.z02文件,并按照training文件夹格式,(分卷)解压 image_2、label_2、calib至相应位置。
b)ImageSets_3dop文件夹
从以下链接下载获得imagesets.tar.gz,解压后重命名为ImageSets_3dop。3DOP![]() https://xiaozhichen.github.io/files/mv3d/imagesets.tar.gz
https://xiaozhichen.github.io/files/mv3d/imagesets.tar.gz
c)ImageSets_subcnn文件夹
从以下链接获取 SubCNN-master,并提取subcnn/fast-rcnn/data/KITTI/内的test.txt、train.txt、val.txt、trainval.txt至ImageSets_subcnn文件夹内。SubCNN![]() https://github.com/tanshen/SubCNN/tree/master/fast-rcnn/data/KITTI
https://github.com/tanshen/SubCNN/tree/master/fast-rcnn/data/KITTI
获取各个图像与标签文件后,还需要在CenterNet/data/kitti文件夹内新建两个文件夹annotations与images。
cd CenterNet_ROOT/data/kitti
# 新建annotations与images文件夹
mkdir images
mkdir annotations再在tools目录下运行convert_kitti_to_coco.py脚本,用于将KITTI格式的注释转换为COCO格式。
cd CenterNet_ROOT/src/tools
python convert_kitti_to_coco.py链接文件
cd CenterNet_ROOT/data/kitti
ln -s CenterNet_ROOT/data/kitti/training/image_2/ CenterNet_ROOT/data/kitti/images/trainval
整理后的data/kitti文件夹配置如下:
${CenterNet_ROOT}
|-- data
`-- |-- kitti
`-- |-- annotations
| |-- kitti_3dop_train.json
| |-- kitti_3dop_val.json
| |-- kitti_subcnn_train.json
| |-- kitti_subcnn_val.json
`-- images
|-- trainval
|-- test (CenterNet的原作者标注了此行,但实际不会生成本test行)11)编译kitti_eval
编译kitti-eval前首先需要安装Boost 库:
sudo apt upgrade
sudo apt-get install libboost-all-dev使用下列代码编译kitti-eval:
cd CenterNet_ROOT/src/tools/kitti_eval
g++ -o evaluate_object_3d_offline evaluate_object_3d_offline.cpp -O312)安装可视化结果文件所需的gnuplot与pdfcrop
sudo apt upgrade
sudo apt install gnuplot
sudo apt-get install texlive-extra-utils13)评估预训练模型3dop
根据预训练模型评估KITTI数据集(不是训练,而是直接使用预训练模型进行评估)。经过此步骤,可以了解不同.pth的识别精确度,便于与自己的训练结果进行对比。
为了避免以下错误:
ERROR: Couldn't read: 000212.txt of ground truth. Please write me an email!
An error occured while processing your results.需要在CenterNet/src/lib/datasets/dataset/kitti.py中,第87行将label_val修改为label_2,即有
def run_eval(self, results, save_dir):
self.save_results(results, save_dir)
os.system('./tools/kitti_eval/evaluate_object_3d_offline ' + \
'../data/kitti/training/label_2 ' + \ #修改此处Line87
'{}/results/'.format(save_dir))针对第(7)步下载的ddd_3dop.pth进行评估,目标数据集为kitti 3dop。
cd CenterNet_ROOT/src/
python test.py ddd --exp_id 3dop --dataset kitti --kitti_split 3dop --load_model ../models/ddd_3dop.pth
评估过程如下图所示:
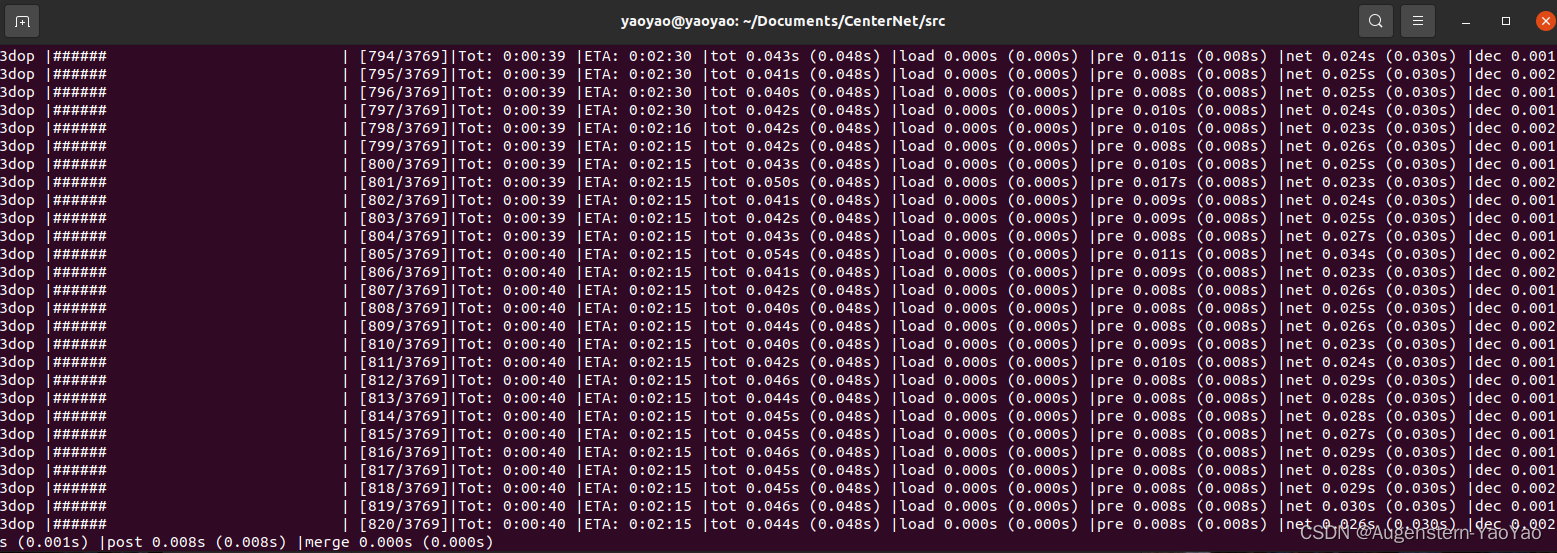
评估完成后,在CenterNet/exp/ddd/3dop/plot文件夹内,可以获得Kitti数据集不同类别(包括Car、Cyclist、Pedestrian等)的识别精度,以P-R(Precision-Recall)表征,每个种类根据困难程度均分为Easy、Moderate、Hard三个难度。
预训练模型的识别结果:
a)二维定位(XXX_detection)
 |  |  |
b)三维定位(XXX_detection_3d)
 |  |  |
3. 训练模型
终于做完了全部准备工作,可以训练模型了!
取训练参数如下表:
| batch_size | lr | master_batch | num_epochs |
| 6 | 3.125e-5 | 5 | 70 |
训练模型调用代码如下:
cd CenterNet_ROOT/src
python main.py ddd --exp_id 3dop --dataset kitti --kitti_split 3dop --batch_size 6 --lr 3.125e-5 --master_batch 5 --num_epochs 70 --lr_step 45,60 --gpus 0训练过程中,终端如下所示:

可在另一个终端中使用以下代码查看GPU占用率(5s刷新一次显存占用与GPU情况):
watch -n 5 nvidia-smi Tips: batch_size为6时,GPU显存约占用7.4GB。
4. 训练结果分析
在CenterNet对于Kitti数据集完成了70epochs的训练后,/3dop文件夹内出现了model_45、model_60与model_best、model_best等pth模型文件(45/60因各人的训练代码设置而异)。
使用以下代码评估模型(Kitti数据集3000+图片上验证):
python test.py ddd --exp_id 3dop --dataset kitti --kitti_split 3dop --load_model ../exp/ddd/3dop/model_last.pth 评估训练获得的.pth模型文件,其结果除上述CenterNet/exp/ddd/3dop/plot的P-R图外,识别结果还以txt文本储存于.../exp/ddd/3dop/results内。
下图为740号图片的识别结果,两辆Car均能识别。
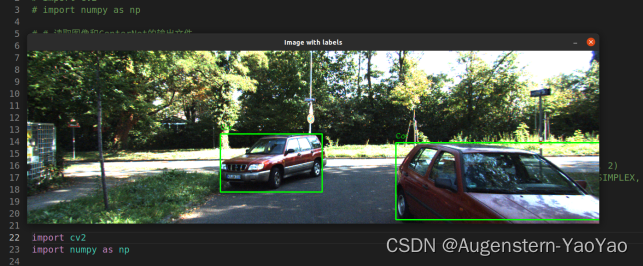
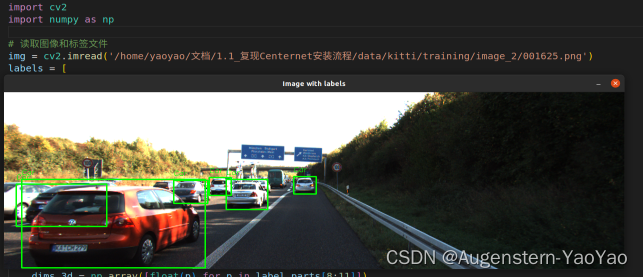
下图为1625号图片的识别结果,在高速上堵车的工况下进行识别。
测试223号图片,元数据为Car / Car / Van / Misc / Person_sitting / DontCare ,但训练后检测为三个Car(如下图标记),错误地将Van(厢式货车)识别为了Car,由于Van和Car在较远、较小的情况下很难区别,因此发生了误识别。
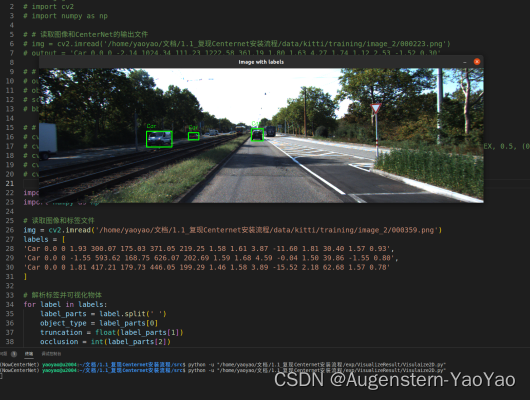
可视化代码如下(注意修改对应的png目录与labels框数据)。
import cv2
import numpy as np
# 读取图像和标签文件
img = cv2.imread('.../data/kitti/training/image_2/000740.png')
labels = [
'Car 0.0 0 -1.69 800.94 199.48 1244.19 366.32 1.41 1.61 3.87 2.93 1.50 5.22 -1.17 0.96',
'Car 0.0 0 2.06 419.74 180.67 640.23 306.54 1.55 1.62 4.07 -1.31 1.89 11.32 1.95 0.95',
]
# 解析标签并可视化物体
for label in labels:
label_parts = label.split(' ')
object_type = label_parts[0]
truncation = float(label_parts[1])
occlusion = int(label_parts[2])
alpha = float(label_parts[3])
bbox_2d = np.array([float(p) for p in label_parts[4:8]])
dims_3d = np.array([float(p) for p in label_parts[8:11]])
location_3d = np.array([float(p) for p in label_parts[11:14]])
rotation_y = float(label_parts[14])
# 可视化标签
cv2.rectangle(img, (int(bbox_2d[0]), int(bbox_2d[1])), (int(bbox_2d[2]), int(bbox_2d[3])), (0, 255, 0), 2)
cv2.putText(img, object_type, (int(bbox_2d[0]), int(bbox_2d[1]) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
# 显示图像
cv2.imshow('Image with labels', img)
cv2.waitKey(0)
cv2.destroyAllWindows()