基本设置
让我们开始安装kafka。下载最新的 Kafka 版本并解压缩。打开终端并启动 kafka 和 zookeeper。
$ cd $HOME
$ tar -xzf kafka_<version>.tgz
$ cd kafka_<version>
$ bin/zookeeper-server-start.sh config/zookeeper.properties
# open another terminal session and start kafka
$ bin/kafka-server-start.sh config/server.properties
让我们在新的终端选项卡中创建一个主题。
# Open another terminal and create a topic.
$ bin/kafka-topics.sh --create --topic payments --partitions 10 --replication-factor 1 \
--bootstrap-server localhost:9092
如果您想知道上述命令是如何使用这些参数构造的,那非常简单。照做,
bin/kafka-topics.sh --help您将看到所有带有描述的参数。文件夹中存在的所有 shell 实用程序也是如此bin。
现在让我们看看幕后发生了什么。
转到/tmp/kafka-logs目录并执行ls我们将看到以下结果。
cleaner-offset-checkpoint payments-0 payments-3 payments-6 payments-9
log-start-offset-checkpoint payments-1 payments-4 payments-7 recovery-point-offset-checkpoint
meta.properties payments-2 payments-5 payments-8 replication-offset-checkpoint
/tmp/kafka-logs是kafka存储数据的默认目录。config/server.properties我们可以将它配置到kafka 和config/zookeeper.propertieszookeeper的不同目录。
恢复点偏移检查点
kafka 代理在内部使用此文件来跟踪刷新到磁盘的日志数量。文件的格式是这样的。
<version>
<total entries>
<topic name> <partition> offset
复制偏移检查点
该文件由 kafka 代理在内部使用,用于跟踪复制到集群中所有代理的日志数量。recovery-point-offset-checkpoint该文件的格式与上述文件相同。
主题和分区
正如我们从上面的结果中看到的,payments-0, payments-1…payments-10是文件系统中的目录分区。正如我在之前的博文中强调的那样,主题是 kafka 中的一个逻辑概念。它在物理上不存在,只有分区存在。主题是所有分区的逻辑分组。
Producer
现在,让我们使用以下命令为主题生成一些消息。
$ cd $HOME/kafka
$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic payments
> hello
> world
> hello world
> hey there!
我们就该主题制作了四条消息。让我们看看它们是如何存储在文件系统中的。很难找出消息去了哪个分区,因为 kafka 使用循环算法将数据分发到分区。简单的方法是找到所有分区(目录)的大小并选择最大的。
$ cd /tmp/kafka-logs
$ du -hs *
8.0K payments-0
8.0K payments-1
12K payments-2
8.0K payments-3
12K payments-4
8.0K payments-5
8.0K payments-6
12K payments-7
8.0K payments-8
12K payments-9
正如我们从上面的代码片段中看到的那样,我们的消息进入了分区 2、4、7 和 9。让我们看看每个分区中有什么。
$ ls payments-7
00000000000000000000.index 00000000000000000000.log
00000000000000000000.timeindex leader-epoch-checkpoint
partition.metadata
$ cat 00000000000000000000.log
=
��Mr���Mr����������������
world%
$ cat partition.metadata
version: 0
topic_id: tbuB6k_uRsuEE03FsechjA
$ cat leader-epoch-checkpoint
0
1
0 0
$ cat 00000000000000000000.index
$ cat 00000000000000000000.timeindex
分区元数据
partition.metadata文件包含一个version和一个topic_id。此主题 ID 对于所有分区都是相同的。
日志文件
这是生产者写入的数据以二进制格式存储的地方。下面我们尝试使用kafka提供的命令行工具来查看这些文件的内容。
$ bin/kafka-dump-log.sh --files data/kafka/payments-7/00000000000000000000.log,data/kafka/payments-7/00000000000000000000.index --print-data-log
Dumping data/kafka/payments-7/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0
CreateTime: 1672041637310 size: 73 magic: 2 compresscodec: none crc: 456919687 isvalid: true | offset: 0
CreateTime: 1672041637310 keySize: -1 valueSize: 5 sequence: -1 headerKeys: [] payload: world
除了一些属性外,以上输出的解释是不言自明的。payload是推送到kafka的实际数据。offset告诉当前消息离零索引有多远。producerId并produerEpoch用于交付保证语义。我们将在以后的博文中讨论它们。我们将在下面了解.index和.timeindex文件。
分区键
我们了解到,kafka 以循环方式将数据分发到分区。但是,如果我们想发送按键分组的数据怎么办?这就是分区键的用武之地。当我们将数据与分区键一起发送时,kafka 将它们放在一个分区中。kafka是如何找到partition key的?它使用计算hash(partition_key) % number_of_partitions。如果不存在分区键,则它使用循环算法。
我们可能想知道,分区键的用例是什么?Kafka 只保证分区级别的消息排序,而不是主题级别。分区键的应用是为了确保消息跨所有分区的顺序。
让我们看看它是如何工作的。让我们生成一些消息。
$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic payments --property parse.key=true --property key.separator=|
> lokesh1729|{"message": "lokesh1729 : order placed"}
> lokesh1729|{"message": "lokeh1729 : logged in"}
> lokesh1729|{"message": "lokesh1729 : logged out"}
> lokesh1729|{"message": "lokesh1729 : payment success"}
parse.key告诉 kafka 通过分隔符解析密钥。默认情况下key.separator设置为选项卡,我们重写为管道。
让我们使用相同的命令查看数据kafka-dump-log。我们需要在所有 10 个分区中执行命令来找到分区,因为我们不知道它去了哪个分区。
$ $ bin/kafka-dump-log.sh --files data/kafka/payments-7/00000000000000000000.log,data/kafka/payments-7/00000000000000000000.index --print-data-log
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0
isTransactional: false isControl: false position: 147 CreateTime: 1672057287522 size: 118 magic: 2 compresscodec: none crc: 2961270358
isvalid: true | offset: 2 CreateTime: 1672057287522 keySize: 10 valueSize: 40 sequence: -1 headerKeys: [] key: lokesh1729
payload: {"message": "lokesh1729 : order placed"}
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0
isTransactional: false isControl: false position: 265 CreateTime: 1672057301944 size: 114 magic: 2 compresscodec: none crc: 204260463
isvalid: true | offset: 3 CreateTime: 1672057301944 keySize: 10 valueSize: 36 sequence: -1 headerKeys: [] key: lokesh1729
payload: {"message": "lokeh1729 : logged in"}
baseOffset: 4 lastOffset: 4 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0
isTransactional: false isControl: false position: 379 CreateTime: 1672057311110 size: 116 magic: 2 compresscodec: none crc: 419761401
isvalid: true | offset: 4 CreateTime: 1672057311110 keySize: 10 valueSize: 38 sequence: -1 headerKeys: [] key: lokesh1729 payload: {"message": "lokesh1729 : logged out"}
baseOffset: 5 lastOffset: 5 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0
isTransactional: false isControl: false position: 495 CreateTime: 1672057327354 size: 121 magic: 2 compresscodec: none crc: 177029556
isvalid: true | offset: 5 CreateTime: 1672057327354 keySize: 10 valueSize: 43 sequence: -1 headerKeys: [] key: lokesh1729 payload: {"message": "lokesh1729 : payment success"}
正如我们从上面的日志中看到的,所有带有键的消息都lokesh1729去了同一个分区,即分区 7。
索引和时间索引文件
让我们使用此脚本生成更多消息并使用上述命令转储数据。
$ bin/kafka-dump-log.sh --files data/kafka/payments-8/00000000000000000000.log,data/kafka/payments-8/00000000000000000000.index --print-data-log
Dumping data/kafka/payments-8/00000000000000000000.index
offset: 33 position: 4482
offset: 68 position: 9213
offset: 100 position: 13572
offset: 142 position: 18800
offset: 175 position: 23042
offset: 214 position: 27777
offset: 248 position: 32165
offset: 279 position: 36665
offset: 313 position: 40872
offset: 344 position: 45005
offset: 389 position: 49849
offset: 422 position: 54287
offset: 448 position: 58402
offset: 485 position: 62533
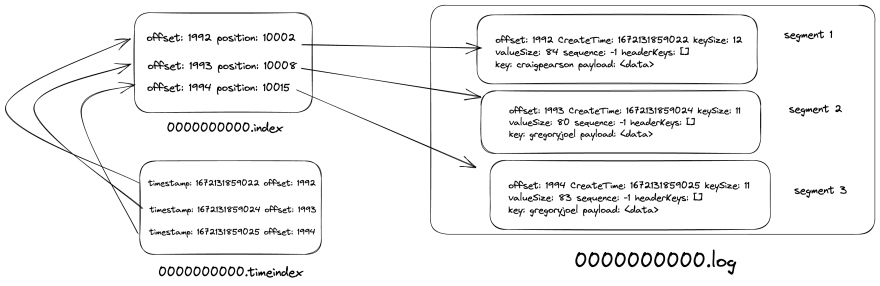
正如我们从上面的输出中看到的,索引文件存储了偏移量及其在文件中的位置.log。为什么需要它?我们知道消费者是顺序处理消息的。当消费者请求消息时,kafka 需要从日志中获取它,即它需要执行磁盘 I/O。想象一下,kafka 逐行读取每个日志文件以找到偏移量。它需要O(n)(其中 n 是文件中的行数)磁盘 I/O 的时间和延迟。当日志文件达到千兆字节大小时,它将成为瓶颈。因此,为了优化它,kafka 将偏移量存储到文件中的位置映射.index,这样如果消费者要求任意偏移量,它只需.index及时对文件进行二进制搜索O(log n),然后转到.log文件并再次执行二进制搜索。
让我们举个例子,假设消费者正在读取第 190 个偏移量。首先,kafka broker 读取索引文件(参考上面的日志)并进行二分查找,要么找到确切的偏移量,要么找到最接近的偏移量。在这种情况下,它发现偏移量为 175,其位置为 23042。然后,它转到文件.log并再次执行二进制搜索,因为该.log文件是按偏移量升序存储的仅追加数据结构。
现在,让我们看一下.timeindex文件。让我们使用以下命令转储文件。
$ bin/kafka-dump-log.sh --files data/kafka/payments-8/00000000000000000000.timeindex --print-data-log
Dumping data/kafka/payments-8/00000000000000000000.timeindex
timestamp: 1672131856604 offset: 33
timestamp: 1672131856661 offset: 68
timestamp: 1672131856701 offset: 100
timestamp: 1672131856738 offset: 142
timestamp: 1672131856772 offset: 175
timestamp: 1672131856816 offset: 213
timestamp: 1672131856862 offset: 247
timestamp: 1672131856901 offset: 279
timestamp: 1672131856930 offset: 312
timestamp: 1672131856981 offset: 344
timestamp: 1672131857029 offset: 388
timestamp: 1672131857076 offset: 419
timestamp: 1672131857102 offset: 448
timestamp: 1672131857147 offset: 484
timestamp: 1672131857185 offset: 517
timestamp: 1672131857239 offset: 547
从上面的结果我们可以看出,.timeindex文件中存储了纪元时间戳和文件中偏移量的映射关系.index。当消费者想要根据时间戳重放事件时,kafka首先通过对文件进行二分查找找到偏移量.timeindex,找到偏移量,通过对文件进行二分查找找到位置.index。
消费者
让我们使用以下命令启动消费者
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic payments --group payments-consumer --from-beginning
{"message": "lokesh1729 : order placed"}
{"message": "lokeh1729 : logged in"}
{"message": "lokesh1729 : logged out"}
{"message": "lokesh1729 : payment success"}
请注意,
--from-beginning参数用于从头开始读取。如果不使用,消费者读取最新的消息,即消费者启动后产生的消息。
现在,让我们看一下文件系统。我们可以观察到将创建名称为 … 的新__consumer_offsets-0文件__consumer_offsets-1夹__consumer_offsets-49。Kafka 将每个消费者偏移量的状态存储在一个名为__consumer_offsets默认分区大小为 50 的主题中。如果我们查看文件夹中的内容,将会出现与payments我们在上面看到的主题中相同的文件。
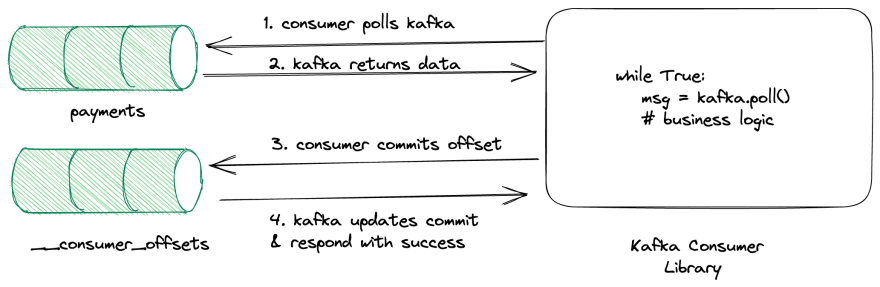
正如我们从上图中看到的,消费者轮询记录并在处理完成时提交偏移量。Kafka 非常灵活,我们可以配置在单个轮询中获取多少条记录、自动提交间隔等…我们将在单独的博客文章中讨论所有这些配置。
当消费者提交偏移量时,它会发送主题名称、分区和偏移量信息。然后,代理使用它来构造键 as<consumer_group_name>, <topic>, <partition>和值 as<offset>,<partition_leader_epoch>,<metadata>,<timestamp>并将其存储在__consumer_offsets主题中。
当消费者崩溃或重启时,它向kafka broker发送请求,broker__consumer_offsets通过doing找到分区hash(<consumer_group_name>, <topic>, <partition> ) % 50并获取最新的偏移量并将其返回给消费者。
[磁盘 I/O 优化
Kafka 使用硬盘作为其主要数据存储。我们知道磁盘 I/O 比主存慢。因此,我们可能想知道 kafka 是如何在高吞吐量下实现低延迟的。让我们深入研究它。
- 顺序磁盘读取比随机内存访问更快。现代操作系统提供以多个块的形式从磁盘读取数据的功能。
- 现代操作系统使用空闲主内存进行磁盘缓存,并通过此缓存转移磁盘 I/O。
- 依赖磁盘缓存比主内存更优化,因为即使服务崩溃或重新启动,磁盘缓存也会保持温暖。
- Kafka 使用索引文件来加快访问速度。我们已经在上面讨论过它们。
- Kafka 批处理磁盘写入。
以下是文件中的示例日志.log。让我们剖析一下。
baseOffset- 开始的起始偏移量
lastOffset- 不言自明
count- 批次中的消息总数
CreateTime- 创建日期的纪元时间戳
size- 批处理中消息的总大小(以字节为单位)
baseOffset: 1992 lastOffset: 1995 count: 4 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 260309 CreateTime: 1672131859025 size: 474 magic: 2 compresscodec: none crc: 36982599 isvalid: true
| offset: 1992 CreateTime: 1672131859022 keySize: 12 valueSize: 84 sequence: -1 headerKeys: [] key: craigpearson payload: {"username": "craigpearson", "address": "0414 Fischer Rest\nZacharyshire, MN 38196"}
| offset: 1993 CreateTime: 1672131859024 keySize: 11 valueSize: 80 sequence: -1 headerKeys: [] key: gregoryjoel payload: {"username": "gregoryjoel", "address": "827 Nelson Burg\nSherrimouth, OK 49255"}
| offset: 1994 CreateTime: 1672131859025 keySize: 11 valueSize: 83 sequence: -1 headerKeys: [] key: gregoryjoel payload: {"username": "gregoryjoel", "address": "8306 Reed Trail\nFitzgeraldstad, PA 18715"}
| offset: 1995 CreateTime: 1672131859025 keySize: 12 valueSize: 84 sequence