前言
上班以后用到的服务器大多数是centos的,很多命令会用一部分但稍微复杂一点的只能问度娘了。
时间长了,还是没积攒下什么本事,每次都需要百度查找。
终于有时间整理一篇关于linux三剑客的笔记,作为记录方便以后查看。
也希望能帮助到需要用到的朋友们。
grep
grep来自英文词组“global search regular expression and print out the line”的缩写,意思是用于全面搜索的正则表达式,并将结果输出。人们通常会将grep命令与正则表达式搭配使用,参数作为搜索过程中的补充或对输出结果的筛选,命令模式十分灵活。 与之容易混淆的是egrep命令和fgrep命令。如果把grep命令当作是标准搜索命令,那么egrep则是扩展搜索命令,等价于“grep -E”命令,支持扩展的正则表达式。而fgrep则是快速搜索命令,等价于“grep -F”命令,不支持正则表达式,直接按照字符串内容进行匹配。
语法格式:grep [参数] 文件名
常用参数
-b 显示匹配行距文件头部的偏移量
-c 只显示匹配的行数
-E 支持扩展正则表达式
-F 匹配固定字符串的内容
-h 搜索多文件时不显示文件名
-i 忽略关键词大小写
-l 只显示符合匹配条件的文件名
-n 显示所有匹配行及其行号
-o 显示匹配词距文件头部的偏移量
-q 静默执行模式
-r 递归搜索模式
-s 不显示没有匹配文本的错误信息
-v 显示不包含匹配文本的所有行
-w 精准匹配整词
-x 精准匹配整行
参考示例
搜索指定文件中包含某个关键词的内容行:
[root@bp-centos-0 study]# cat -n test.txt
1 1
2 12
3 123
4 1234
5 12345
[root@bp-centos-0 study]# grep 123 test.txt
123
1234
12345
搜索指定文件中以某个关键词开头的内容行:
[root@bp-centos-0 study]# grep ^1234 test.txt
1234
12345
显示指定文件中包含某个关键词行的数量:
[root@bp-centos-0 study]# grep -c 5 test.txt
1
搜索指定文件中包含某个关键词位置的行号及内容行:
[root@bp-centos-0 study]# grep -n network /root/anaconda-ks.cfg
4:# Use network installation
20:network --bootproto=dhcp --device=link --activate
21:network --hostname=localhost.localdomain
51: dracut-network e2fsprogs e2fsprogs-libs ebtables ethtool file \
86:rm -rf /etc/sysconfig/network-scripts/ifcfg-*
搜索当前目录中包含某个关键词内容的文件,未找到不提示:
[root@bp-centos-0 study]# grep -sl root *
[root@bp-centos-0 study]# grep -sl 123 *
test.txt
搜索指定目录及子目录中包含某个关键字的文件
[root@bp-centos-0 study]# grep -slr root /etc
/etc/aliases
/etc/bash_completion.d/yum-utils.bash
/etc/dbus-1/system.d/org.freedesktop.hostname1.conf
/etc/dbus-1/system.d/org.freedesktop.import1.conf
/etc/dbus-1/system.d/org.freedesktop.locale1.conf
/etc/dbus-1/system.d/org.freedesktop.login1.conf
/etc/dbus-1/system.d/org.freedesktop.machine1.conf
/etc/dbus-1/system.d/org.freedesktop.systemd1.conf
/etc/dbus-1/system.d/org.freedesktop.timedate1.conf
/etc/group
/etc/group-
/etc/gshadow
/etc/gshadow-
/etc/logrotate.d/yum
.....省略更多目录
搜索指定文件中精准匹配到某个关键字的内容行
[root@bp-centos-0 study]# grep -x 123 test.txt
123
[root@bp-centos-0 study]# grep -xn 123 test.txt
3:123
sed
sed是一种流编辑器,它是文本处理中非常好的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件,可以将数据行进行替换、删除、新增、选取等特定工作,简化对文件的反复操作,编写转换程序等。
sed语法及常用参数
命令格式
sed的命令格式:sed [options] 'command' file(s);
sed的脚本格式:sed [options] -f scriptfile file(s);
选项
-e :直接在命令行模式上进行sed动作编辑,此为默认选项;
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作;
-i :直接修改文件内容;
-n :只打印模式匹配的行;
-r :支持扩展表达式;
-h或--help:显示帮助;
-V或--version:显示版本信息。
参数
文件:指定待处理的文本文件列表。
sed常用命令
a\ 在当前行下面插入文本;
i\ 在当前行上面插入文本;
c\ 把选定的行改为新的文本;
d 删除,删除选择的行;
D 删除模板块的第一行;
s 替换指定字符;
h 拷贝模板块的内容到内存中的缓冲区;
H 追加模板块的内容到内存中的缓冲区;
g 获得内存缓冲区的内容,并替代当前模板块中的文本;
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面;
l 列表不能打印字符的清单;
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令;
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码;
p 打印模板块的行。 P(大写) 打印模板块的第一行;
q 退出Sed;
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾;
r file 从file中读行;
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
w file 写并追加模板块到file末尾;
W file 写并追加模板块的第一行到file末尾;
! 表示后面的命令对所有没有被选定的行发生作用;
= 打印当前行号;
# 把注释扩展到下一个换行符以前;
sed替换标记
g 表示行内全面替换;
p 表示打印行;
w 表示把行写入一个文件;
x 表示互换模板块中的文本和缓冲区中的文本;
y 表示把一个字符翻译为另外的字符(但是不用于正则表达式);
\1 子串匹配标记;
& 已匹配字符串标记;
sed元字符集
^ 匹配行开始,如:/^sed/匹配所有以sed开头的行;
$ 匹配行结束,如:/sed$/匹配所有以sed结尾的行;
. 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d;
* 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行;
[] 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed;
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行;
\(..\) 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers;
& 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**;
\< 匹配单词的开始,如:/\
\> 匹配单词的结束,如/love\>/匹配包含以love结尾的单词的行;
x\{m\} 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行;
x\{m,\} 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行;
x\{m,n\} 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行;
sed参考示例
替换操作:s命令
替换文本中的字符串:
[root@bp-centos-0 study]# cat -n test.txt
1 1
2 12
3 123
4 1234
5 i12345
6 book
7 framework
8 textbook
9 notepadbook
10 springboot
11 springmvc
12
[root@bp-centos-0 study]# sed 's/book/Books/' test.txt
1
12
123
1234
i12345
Books
framework
textBooks
notepadBooks
springboot
springmvc
-n选项和p命令一起使用表示只打印那些发生替换的行:
[root@bp-centos-0 study]# sed -n 's/boot/Boot/p' test.txt
springBoot
直接编辑文件选项-i,会匹配file文件中每一行的第一个book替换为books
sed -i 's/book/books/g' file
全面替换标记g
使用后缀 /g 标记会替换每一行中的所有匹配:
sed 's/book/books/g' file
当需要从第N处匹配开始替换时,可以使用 /Ng:
echo sksksksksksk | sed 's/sk/SK/2g'
skSKSKSKSKSK
echo sksksksksksk | sed 's/sk/SK/3g'
skskSKSKSKSK
echo sksksksksksk | sed 's/sk/SK/4g'
skskskSKSKSK
定界符
以上命令中字符 / 在sed中作为定界符使用,也可以使用任意的定界符
sed 's:test:TEXT:g' file
sed 's|test|TEXT|g' file
定界符出现在样式内部时,需要进行转义:
sed 's/\/bin/\/usr\/local\/bin/g' file
删除操作:d命令
删除空白行:
sed '/^$/d' file
删除文件的第2行:
sed '2d' file
删除文件的第2行到末尾所有行:
sed '2,$d' file
删除文件最后一行:
sed '$d' file
删除文件中所有开头是test的行:
sed '/^test/'d file
已匹配字符串标记&
正则表达式 \w+ 匹配每一个单词,使用 [&] 替换它,& 对应于之前所匹配到的单词:
echo this is a test line | sed 's/\w\+/[&]/g'
[this] [is] [a] [test] [line]
所有以192.168.0.1开头的行都会被替换成它自已加localhost:
sed 's/^192.168.0.1/&localhost/' file
子串匹配标记\1
匹配给定样式的其中一部分:
echo this is digit 7 in a number | sed 's/digit \([0-9]\)/\1/'
this is 7 in a number
命令中 digit 7,被替换成了 7。样式匹配到的子串是 7,(…) 用于匹配子串,对于匹配到的第一个子串就标记为 \1,依此类推匹配到的第二个结果就是 \2,例如:
echo aaa BBB | sed 's/\([a-z]\+\) \([A-Z]\+\)/\2 \1/'
BBB aaa
love被标记为1,所有loveable会被替换成lovers,并打印出来:
sed -n 's/\(love\)able/\1rs/p' file
组合多个表达式
sed '表达式' | sed '表达式' 等价于:
sed '表达式; 表达式'
引用
sed表达式可以使用单引号来引用,但是如果表达式内部包含变量字符串,就需要使用双引号。
test=hello
echo hello WORLD | sed "s/$test/HELLO/"
HELLO WORLD
选定行的范围:,(逗号)
所有在模板test和check所确定的范围内的行都被打印:
sed -n '/test/,/check/p' file
打印从第5行开始到第一个包含以test开始的行之间的所有行:
sed -n '5,/^test/p' file
对于模板test和west之间的行,每行的末尾用字符串aaa bbb替换:
sed '/test/,/west/s/$/aaa bbb/' file
多点编辑:e命令
-e选项允许在同一行里执行多条命令:
sed -e '1,5d' -e 's/test/check/' file
上面sed表达式的第一条命令删除1至5行,第二条命令用check替换test。命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
和 -e 等价的命令是 --expression:
sed --expression='s/test/check/' --expression='/love/d' file
从文件读入:r命令
file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面:
sed '/test/r file' filename
写入文件:w命令
在example中所有包含test的行都被写入file里:
sed -n '/test/w file' example
追加(行下):a\命令
将 this is a test line 追加到 以test 开头的行后面:
sed '/^test/a\this is a test line' file
在 test.conf 文件第2行之后插入 this is a test line:
sed -i '2a\this is a test line' test.conf
插入(行上):
i\命令 将 this is a test line 追加到以test开头的行前面:
sed '/^test/i\this is a test line' file
在test.conf文件第5行之前插入this is a test line:
sed -i '5i\this is a test line' test.conf
下一个:n命令
如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续:
sed '/test/{ n; s/aa/bb/; }' file
变形:y命令
把1~10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令:
sed '1,10y/abcde/ABCDE/' file
退出:q命令
打印完第10行后,退出sed sed ‘10q’ file 保持和获取:h命令和G命令 在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。
sed -e '/test/h' -e '$G' file
在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。
保持和互换:h命令和x命令
互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换:
sed -e '/test/h' -e '/check/x' file
脚本scriptfile
sed脚本是一个sed的命令清单,启动Sed时以-f选项引导脚本文件名。Sed对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本,如果在一行中有多个命令,要用分号分隔。以#开头的行为注释行,且不能跨行。
sed [options] -f scriptfile file(s)
打印奇数行或偶数行
方法1:
sed -n 'p;n' test.txt #奇数行 sed -n 'n;p' test.txt #偶数行
方法2:
sed -n '1~2p' test.txt #奇数行 sed -n '2~2p' test.txt #偶数行
打印匹配字符串的下一行
grep -A 1 SCC URFILE
sed -n '/SCC/{n;p}' URFILE
awk '/SCC/{getline; print}' URFILE
awk
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
awk 是一种很棒的语言,它适合文本处理和报表生成,其语法较为常见,借鉴了某些语言的一些精华,如 C 语言等。在 linux 系统日常处理工作中,发挥很重要的作用,掌握了 awk将会使你的工作变的高大上。 awk 是三剑客的老大,利剑出鞘,必会不同凡响。
语法:
awk '{pattern + action}' {filenames}
尽管操作可能会很复杂,但语法总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
awk 的原理
通过一个简短的命令,我们来了解其工作原理。
[root@hecs-75552 ~]# pwd | awk '{print $0}'
/root
[root@hecs-75552 ~]# echo hhh | awk '{print $0}'
hhh
[root@hecs-75552 ~]# echo hhh | awk '{print "hello,world"}'
hello,world
[root@hecs-75552 ~]# awk '{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
你将会见到/etc/passwd 文件的内容出现在眼前。现在,解释 awk 做了些什么。调用 awk时,我们指定/etc/passwd 作为输入文件。执行 awk 时,它依次对/etc/passwd 中的每一行执行 print 命令。
所有输出都发送到 stdout,所得到的结果与执行 cat /etc/passwd 完全相同。
现在,解释{ print }代码块。在 awk 中,花括号用于将几块代码组合到一起,这一点类似于 C 语言。在代码块中只有一条 print 命令。在 awk 中,如果只出现 print 命令,那么将打印当前行的全部内容。
再次说明, awk 对输入文件中的每一行都执行这个脚本。

$ awk -F":" '{ print $1 }' /etc/passwd
$ awk -F":" '{ print $1 $3 }' /etc/passwd
$ awk -F":" '{ print $1 " " $3 }' /etc/passwd
$ awk -F":" '{ print "username: " $1 "uid:" $3 }' /etc/passwd
-F参数:指定分隔符,可指定一个或多个
print 后面做字符串的拼接
参考示例
下面通过几实例来了解下awk的工作原理:
实例一
只查看test.txt文件(100行)内第20到第30行的内容(企业面试)
[root@hecs-75552 ~]# awk '{if(NR>=5 && NR<=10) print $1}' test.txt
5
6
7
8
10
9
实例二
已知test.txt文件内容为:
[root@hecs-75552 ~]# cat test1.txt
I am Zjtx,my qq is 1654088754
请从该文件中过滤出’Zjtx’字符串与1654088754,最后输出的结果为:Zjtx 1654088754
[root@hecs-75552 ~]# awk -F '[ ,]+' '{print $3" "$7}' test1.txt
Zjtx 1654088754
BEGIN 和 END 模块
通常,对于每个输入行, awk 都会执行每个脚本代码块一次。然而,在许多编程情况中,可能需要在 awk 开始处理输入文件中的文本之前执行初始化代码。对于这种情况, awk 允许您定义一个 BEGIN 块。
因为 awk 在开始处理输入文件之前会执行 BEGIN 块,因此它是初始化 FS(字段分隔符)变量、打印页眉或初始化其它在程序中以后会引用的全局变量的极佳位置。
awk 还提供了另一个特殊块,叫作 END 块。 awk 在处理了输入文件中的所有行之后执行这个块。通常, END 块用于执行最终计算或打印应该出现在输出流结尾的摘要信息。
实例一
统计/etc/passwd的账户人数
[root@Gin scripts]``# awk '{count++;print $0;} END{print "user count is ",count}' passwd``root:x:0:0:root:``/root``:``/bin/bash``..............................................``user count is 27
count是自定义变量。之前的action{}里都是只有一个print,其实print只是一个语句,而action{}可以有多个语句,以;号隔开。这里没有初始化count,虽然默认是0,但是妥当的做法还是初始化为0:
[root@hecs-75552 ~]# awk '{count++;} END{print "user count is ",count}' /etc/passwd
user count is 29
实例二
统计某个文件夹下的文件占用的字节数
[root@hecs-75552 ~]# ll |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ",size}'
[end]size is 8643
如果以M为单位显示:
[root@hecs-75552 ~]# ll |awk 'BEGIN{size=0;} {size=size+$5;} END{print "[end]size is ",size/1024/1024,"M"}'
[end]size is 0.00824261 M
awk运算符
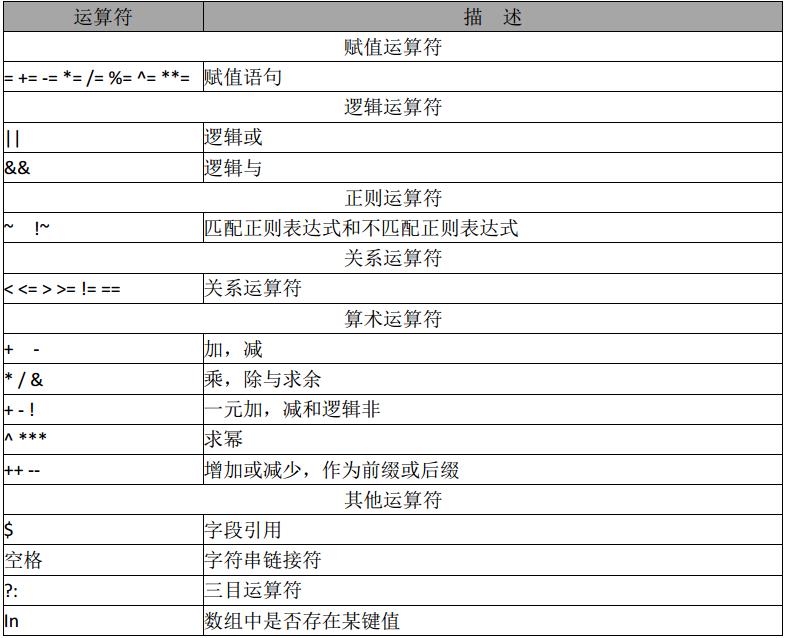
awk 赋值运算符
a+5;等价于: a=a+5;其他同类
[root@hecs-75552 ~]# awk 'BEGIN{a=5;a+=5;print a}'
10
awk逻辑运算符:
[root@hecs-75552 ~]# awk 'BEGIN{a=1;b=2;print (a>2&&b>1,a=1||b>1)}'
0 1
判断表达式 a>2&&b>1为真还是为假,后面的表达式同理
awk正则运算符
[root@hecs-75552 ~]# awk 'BEGIN{a="100testaa";if(a~/100/) {print "ok"}}'
ok
awk关系运算符
如: > < 可以作为字符串比较,也可以用作数值比较,关键看操作数如果是字符串就会转换为字符串比较。两个都为数字 才转为数值比较。字符串比较:按照ascii码顺序比较。如果是字符串和数字就不输出结果。
[root@hecs-75552 ~]# awk 'BEGIN{a="20";if(a>='14'){print "ok"}}'
ok
[root@Gin scripts]# awk 'BEGIN{a=11;if(a>=9){print "ok"}}'
ok
awk 算术运算符
说明,所有用作算术运算符进行操作,操作数自动转为数值,所有非数值都变为0。
[root@hecs-75552 ~]# awk 'BEGIN{a="b";print a++,a,++a}'
0 1 2
[root@hecs-75552 ~]# awk 'BEGIN{a="20b4";print a++,++a}'
20 22
这里的a++ , ++a与javascript语言一样:a++是先赋值加++;++a是先++再赋值
awk三目运算符 ?:
[root@hecs-75552 ~]# awk 'BEGIN{a="b";print a=="b"?"ok":"err"}'
ok
[root@hecs-75552 ~]# awk 'BEGIN{a="b";print a=="c"?"ok":"err"}'
err
常用 awk 内置变量
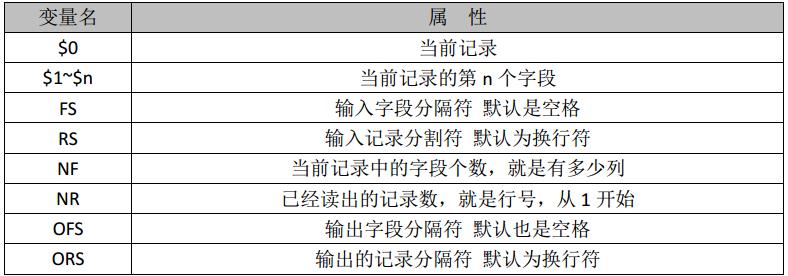
注:内置变量很多,参阅相关资料
字段分隔符 FS
[root@Gin scripts]``# cat tab.txt``ww CC IDD``[root@Gin scripts]``# awk 'BEGIN{FS="\t+"}{print $1,$2,$3}' tab.txt``ww CC IDD
FS=“\t” 表示一个或多个 Tab 分隔
FS=“[[:space:]+]” 表示一个或多个空白空格,默认的
FS=“[” “:]+” 表示以一个或多个空格或:分隔
记录数量 NR
[root@hecs-75552 ~]# ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.170 netmask 255.255.255.0 broadcast 192.168.0.255
inet6 fe80::f816:3eff:feae:6b0 prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:ae:06:b0 txqueuelen 1000 (Ethernet)
RX packets 10396292 bytes 9048227232 (8.4 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 6277671 bytes 1529686917 (1.4 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@hecs-75552 ~]# ifconfig eth0|awk -F [" ":]+ 'NR==3{print $0}'
inet6 fe80::f816:3eff:feae:6b0 prefixlen 64 scopeid 0x20<link>
RS 记录分隔符变量
将 FS 设置成"\n"告诉 awk 每个字段都占据一行。通过将 RS 设置成"",还会告诉 awk每个地址记录都由空白行分隔。
awk 正则
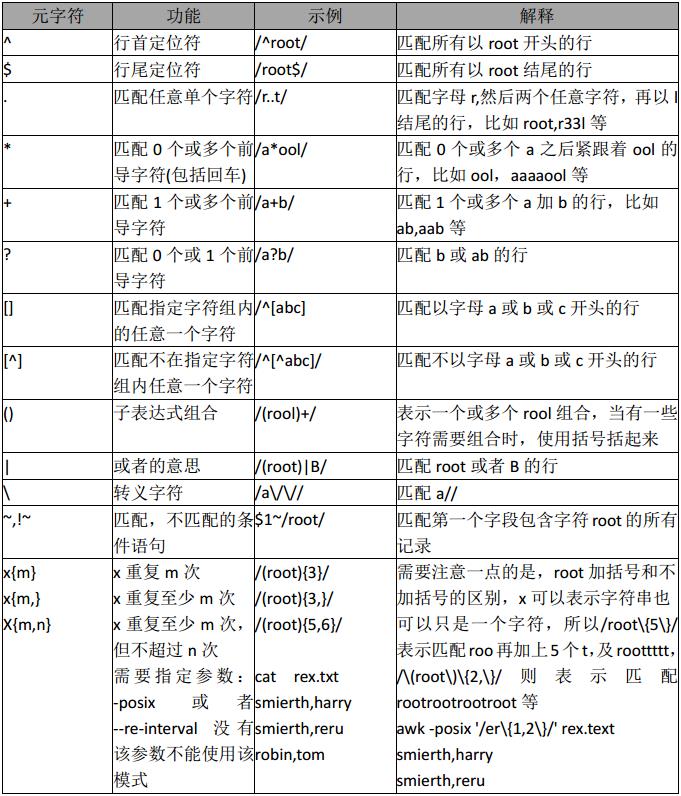
正则应用
规则表达式
语法格式:
awk '/REG/{action} ' file
其中 /REG/为正则表达式,可以将$0 中,满足条件的记录送入到action 进行处理
## 匹配所有包含root的行
[root@hecs-75552 ~]# awk '/root/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@Gin scripts]# awk -F: '$5~/root/{print $0}' passwd ## 以冒号作为分隔符,匹配第5个字段是root的行
root:x:0:0:root:/root:/bin/bash
布尔表达式
语法格式
awk '布尔表达式{action}' file
仅当对前面的布尔表达式求值为真时, awk 才执行代码块。
[root@hecs-75552 ~]# awk -F: '$1=="root"{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
awk 的 if、循环和数组
条件语句
awk 提供了非常好的类似于 C 语言的 if 语句。
{
if ($1=="foo"){
if($2=="foo"){
print "uno"
}else{
print "one"
}
}elseif($1=="bar"){
print "two"
}else{
print "three"
}
}
使用 if 语句还可以将代码:
/matchme/ { print $1 $3 $4 }
转换成:
{
if ( $0 !~ /matchme/ ) {
print $1 $3 $4
}
}
循环结构
我们已经看到了 awk 的 while 循环结构,它等同于相应的 C 语言 while 循环。 awk 还有"do…while"循环,它在代码块结尾处对条件求值,而不像标准 while 循环那样在开始处求值。
它类似于其它语言中的"repeat…until"循环。以下是一个示例:
do…while 示例
{
count=1do {
print "I get printed at least once no matter what"
} while ( count !=1 )
}
与一般的 while 循环不同,由于在代码块之后对条件求值, "do…while"循环永远都至少执行一次。换句话说,当第一次遇到普通 while 循环时,如果条件为假,将永远不执行该循环。
for 循环
awk 允许创建 for 循环,它就象 while 循环,也等同于 C 语言的 for 循环:
for ( initial assignment; comparison; increment ) {
code block
}
以下是一个简短示例:
for ( x=1;x<=4;x++ ) {
print "iteration", x
}
此段代码将打印:
for ( x=1;x<=4;x++ ) {
print "iteration", x
}
break 和 continue
此外,如同 C 语言一样, awk 提供了 break 和 continue 语句。
可以通过break跳出当前循环,通过continue进行到下一轮循环。
数组
AWK 中的数组都是关联数组,数字索引也会转变为字符串索引
{
cities[1]=”beijing”
cities[2]=”shanghai”
cities[“three”]=”guangzhou”
for( c in cities) {
print cities[c]
}
print cities[1]
print cities[“1”]
print cities[“three”]
}
for…in 输出,因为数组是关联数组,默认是无序的。所以通过 for…in 得到是无序的数组。如果需要得到有序数组,需要通过下标获得。
数组的典型应用
用 awk 中查看服务器连接状态并汇总
[root@hecs-75552 ~]# netstat -an|awk '/^tcp/{++s[$NF]}END{for(a in s)print a,s[a]}'
LISTEN 8
ESTABLISHED 5
TIME_WAIT 39
统计 web 日志访问流量,要求输出访问次数,请求页面或图片,每个请求的总大小,总访问流量的大小汇总
awk '{a[$7]+=$10;++b[$7];total+=$10}END{for(x in a)print b[x],x,a[x]|"sort -rn -k1";print
"total size is :"total}' /app/log/access_log
total size is :172230
21 /icons/poweredby.png 83076
14 / 70546
8 /icons/apache_pb.gif 18608
a[$7]+=$10 表示以第 7 列为下标的数组( $10 列为$7 列的大小),把他们大小累加得到
$7 每次访问的大小,后面的 for 循环有个取巧的地方, a 和 b 数组的下标相同,所以一
条 for 语句足矣
常用字符串函数
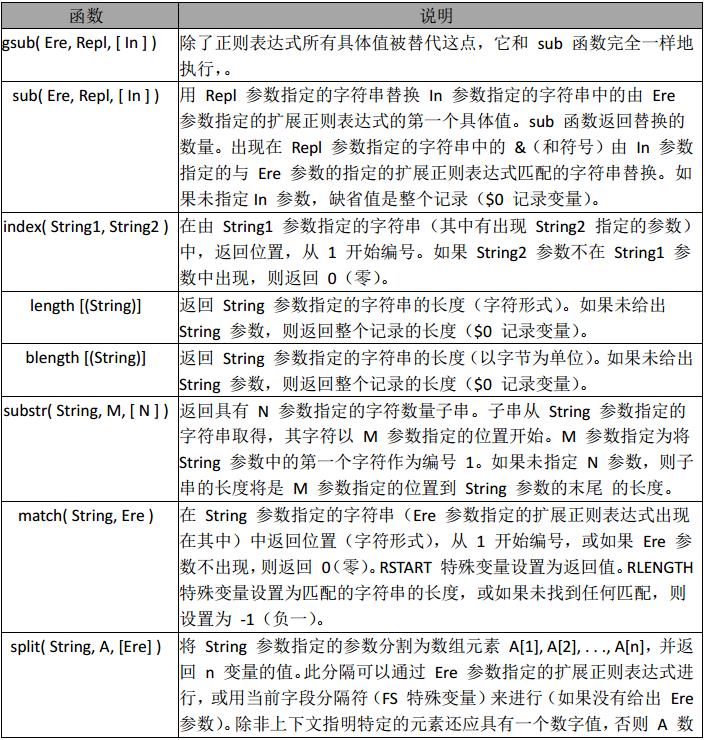
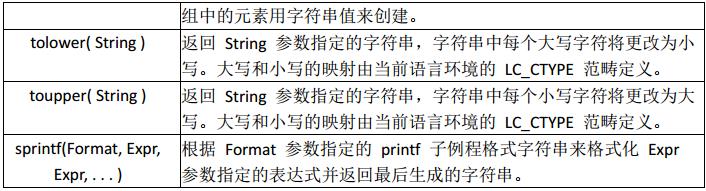
字符串函数的应用
替换
awk 'BEGIN{info="this is a test2010test!";gsub(/[0-9]+/,"!",info);print info}' this is a test!test!
在 info 中查找满足正则表达式, /[0-9]+/ 用”!”替换,并且替换后的值,赋值给 info 未
给 info 值,默认是$0
查找
awk 'BEGIN{info="this is a test2010test!";print index(info,"test")?"ok":"no found";}'
ok #未找到,返回 0
匹配查找
awk 'BEGIN{info="this is a test2010test!";print match(info,/[0-9]+/)?"ok":"no found";}'
ok #如果查找到数字则匹配成功返回 ok,否则失败,返回未找到
截取
awk 'BEGIN{info="this is a test2010test!";print substr(info,4,10);}'
s is a tes #从第 4 个 字符开始,截取 10 个长度字符串
分割
awk 'BEGIN{info="this is a test";split(info,tA," ");print length(tA);for(k in tA){print k,tA[k];}}' 4
4 test 1 this 2 is 3 a
#分割 info,动态创建数组 tA,awk for …in 循环,是一个无序的循环。 并不是从数组下标
1…n 开始
总结
本文主要介绍了关于linux下awk、grep、sed三个常用命令的使用及常见场景下的用法。
本文也是参考了一些网上的文章并结合在服务器上的操作完成的,文中涉及到的命令都是在服务器上验证过的。
针对以上内容有任何疑问或者建议欢迎评论区留言指出~~~
创作不易,欢迎一键三连~~~~